Translation not up to date
Tento výukový program demonstruje použití produktu Federated Learning s cílem školení školicího modelu počítače s daty od různých uživatelů, aniž by uživatelé sdíleli svá data. Kroky se provádějí v prostředí s nízkým kódem s uživatelským rozhraním a s rámcem XGBoost.
V tomto výukovém programu se naučíte:
Poznámky:
- Jedná se o výukový program step-by-step pro spuštění experimentu sdruženého výukového programu řízeného UI. Chcete-li zobrazit ukázku kódu pro přístup řízený rozhraním API, přejděte na volbu Ukázky produktu Federated Learning XGBoost.
- V tomto výukovém programu se admin odkazuje na uživatele, který spouští federovaný výukový experiment, a strana odkazuje na jednoho nebo více uživatelů, kteří odesílají výsledky svého modelu poté, co administrátor zahájí pokus o provedení testu. Zatímco výukový program může být proveden administrátorem a více stranami, jeden uživatel může také dokončit plné spuštění jako admin a strana. Pro jednodušší demonstrační účel, v následujícím výukovém programu, jedna strana předkládá pouze jednu datovou sadu. Další informace o admin a party naleznete v tématu Terminologie.
Krok 1: Spuštění sdruženého učení
V této sekci se naučíte spustit produkt Federated Learning Experiment.
Než začnete
Přihlaste se do produktu IBM Cloud. Pokud nemáte účet, vytvořte jej s libovolným e-mailem.
Vytvořit instanci služby Watson Machine Learning , pokud ji nemáte nastaven ve svém prostředí.
Přihlaste se do watsonx.
Použijte existující projekt nebo vytvořte nový. Musíte mít alespoň oprávnění administrátora.
Přidružte službu Watson Machine Learning k vašemu projektu.
- Ve svém projektu klepněte na volbu Spravovat > Integrace služeb a integrace.
- Klepněte na tlačítko Přidružit službu.
- Ze seznamu vyberte instanci produktu Watson Machine Learning a klepněte na volbu Přidružit; nebo klepněte na volbu Nová služba , pokud ji nemáte k nastavení instance.

Spustit agregátor
Vytvořte aktivum produktu Federated learning Experiment:
Ve svém projektu klepněte na kartu Aktiva .
Klepněte na volbu Nová úloha > Modely vlaků na distribuovaných datech.
Zadejte Název pro váš experiment a volitelně také popis.
Ověřte přidruženou instanci produktu Watson Machine Learning pod položkou Select a machine learning instance. Pokud jste nezobrazili přidruženou instanci produktu Watson Machine Learning , postupujte takto:
Klepněte na volbu Přidružit instanci služby Machine Learning.
Vyberte existující instanci a klepněte na tlačítko Přidružit, nebo vytvořte Nová služba.
Chcete-li zobrazit přidruženou službu, klepněte na tlačítko Znovu načíst .
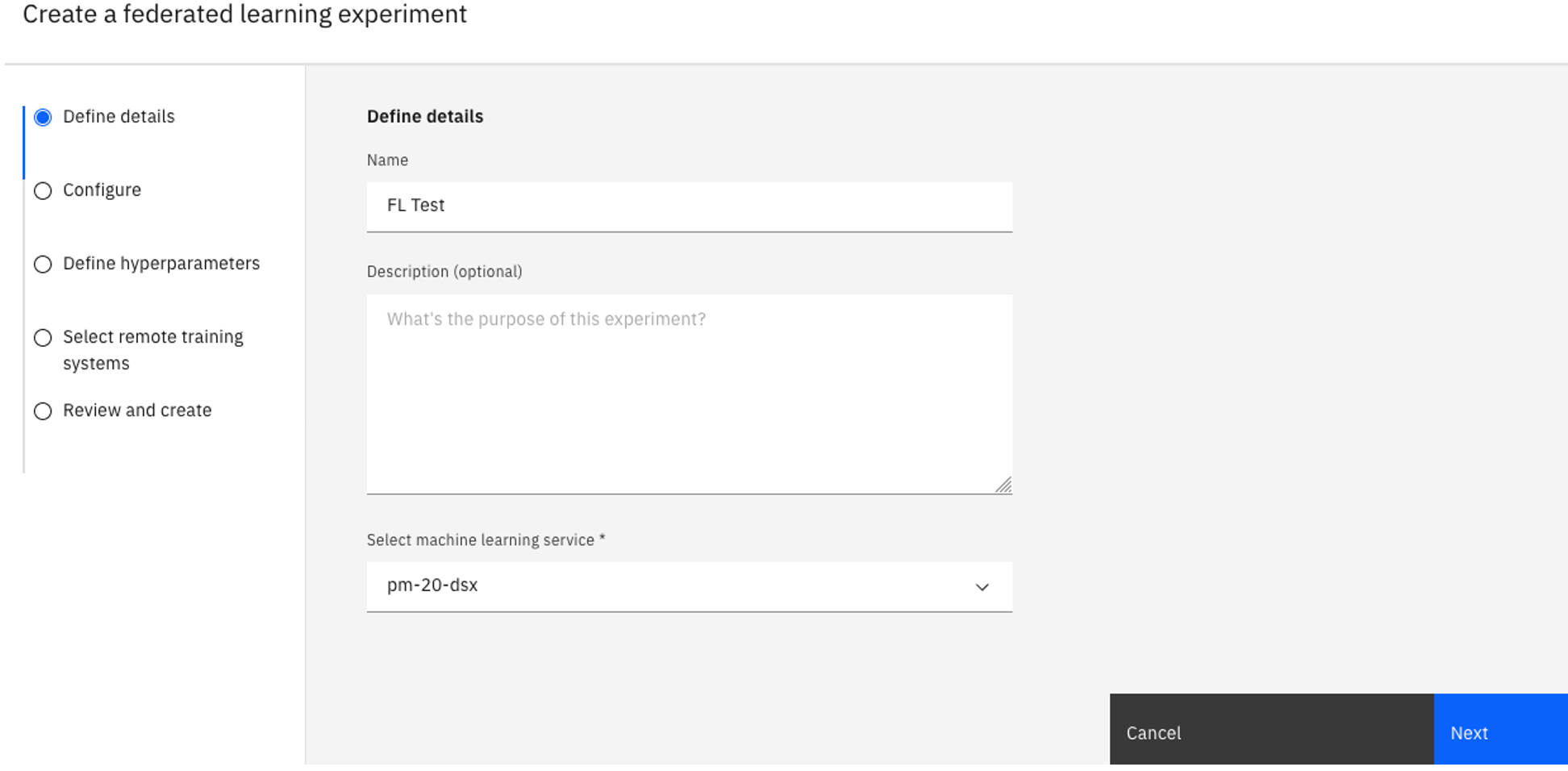
Klepněte na tlačítko Další.
Nakonfigurujte experiment.
Na stránce Konfigurace vyberte volbu Hardwarová specifikace.
Pod rozevírací nabídkou Rámec výuky počítačů vyberte volbu scikit-learn.
Pro volbu Typ modeluvyberte volbu XGBoost.
Pro Metodu sloučení XGBoostvyberte volbu Zmatenost klasifikace XGBoost .

Definujte hyperparametry.
Nastavte hodnotu v poli Cykly na hodnotu
5.Přijměte výchozí hodnoty pro zbývající pole.
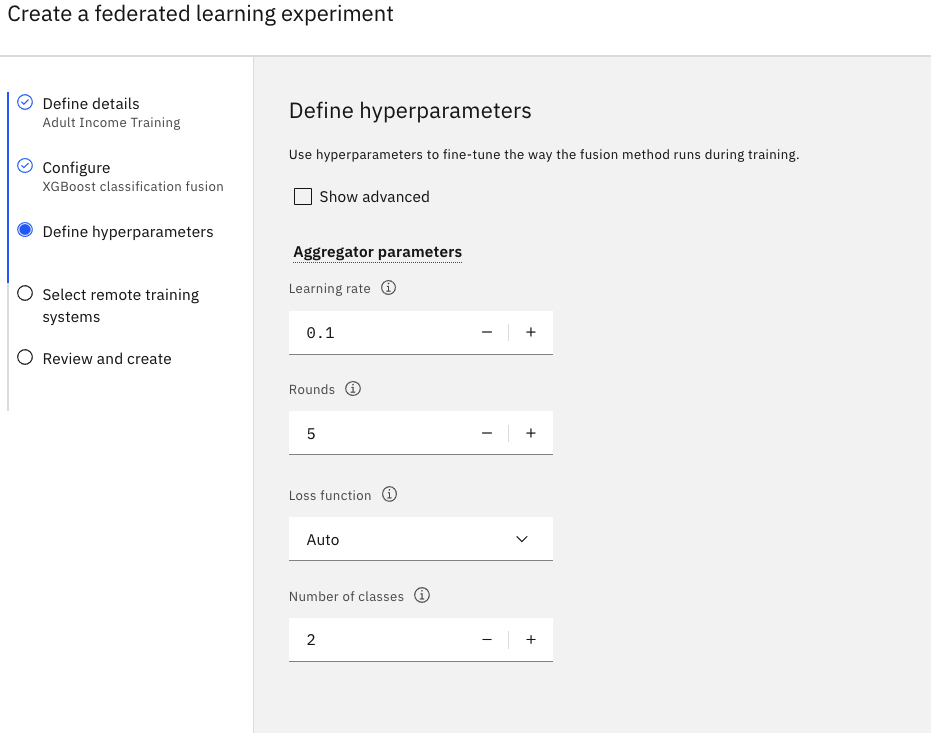
Klepněte na tlačítko Další.
Vyberte vzdálené systémy školení.
- Klepněte na volbu Přidat nové systémy.
Pojmenujte svůj vzdálený tréninkový systém.
Pod položkou Povolené identityvyberte uživatele, který se bude podílet na experimentu, a poté klepněte na tlačítko Přidat. Jako účastníci v této instanci Experimentování sdruženého experimentu můžete přidat tolik povolených identit jako účastníky. Pro tento výukový program vyberte pouze sebe.
Všechny povolené identity musí být součástí projektu a mít alespoň oprávněníAdmin .Až budete hotovi, klepněte na tlačítko Přidat systémy.

Vraťte se na stránku Vybrat vzdálené systémy školení , ověřte, zda je váš systém vybrán, a poté klepněte na tlačítko Další.

Zkontrolujte svá nastavení a poté klepněte na tlačítko Vytvořit.
Sledujte stav. Stav experimentu sdruženého učení je Nevyřízený , když se spustí. Je-li váš experiment připraven pro připojení účastníků, stav se změní na Nastavení-Čeká na vzdálené systémy. Tato akce může trvat několik minut.
Krok 2: Train model as a party
Ujistěte se, že používáte stejnou verzi Python jako administrátor. Použití odlišné verze Python může způsobit problémy s kompatibilitou. Chcete-li zobrazit verze Python kompatibilní s různými frameworky, přečtěte si téma Kompatibilita rámců a kompatibilita verze Python.
Vytvoří nový lokální adresář.
Stáhněte datovou sadu Adult do adresáře pomocí tohoto příkazu:
wget https://api.dataplatform.cloud.ibm.com/v2/gallery-assets/entries/5fcc01b02d8f0e50af8972dc8963f98e/data -O adult.csv.Stáhněte popisovač dat spuštěním produktu
wget https://raw.githubusercontent.com/IBMDataScience/sample-notebooks/master/Files/adult_sklearn_data_handler.py -O adult_sklearn_data_handler.py.Nainstalujte produkt Watson Machine Learning.
- Používáte-li systém Linux, spusťte příkaz
pip install 'ibm-watson-machine-learning[fl-rt22.2-py3.10]'. - Pokud používáte Mac OS s M-series CPU a Conda, stáhněte instalační skript a pak spusťte
./install_fl_rt22.2_macos.sh <name for new conda environment>.
Nyní máte skript konektoru strany,mnist_keras_data_handler.py,mnist-keras-test.pklamnist-keras-train.pkl, popisovač dat ve stejném adresáři.
- Používáte-li systém Linux, spusťte příkaz
Přejděte zpět na stránku Federovaný výukový test, kde je agregátor spuštěný. Klepněte na View Setup Information.
Klepněte na ikonu stažení vedle vzdáleného vzdělávacího systému a vyberte Skript konektoru strany.
Ujistěte se, že máte skript konektoru strany, datovou sadu Adult a popisovač dat ve stejném adresáři. Pokud spustíte příkaz
ls -l, měli byste vidět:adult.csv adult_sklearn_data_handler.py rts_<RTS Name>_<RTS ID>.pyVe skriptu konektoru strany:
Proveďte ověření pomocí libovolné metody.
Vložte tyto parametry do sekce
"data":"data": { "name": "AdultSklearnDataHandler", "path": "./adult_sklearn_data_handler.py", "info": { "txt_file": "./adult.csv" }, },kde:
name: Název třídy definovaný pro popisovač dat.path: Cesta, kde se nachází popisovač dat.info: Vytvořte dvojici klíčových hodnot pro typ souboru lokálních datových sad nebo cestu k datové sadě.
Spusťte skript konektoru strany:
python3 rts_<RTS Name>_<RTS ID>.py.Když se všechny zúčastněné strany připojí k agregátoru, agregátor usnadňuje lokální školení modelu a aktualizaci globálního modelu. Jeho stav je Školení. Můžete sledovat stav experimentu sdruženého učení z uživatelského rozhraní.
Jakmile je školení dokončeno, strana obdrží na straně
Received STOP message.Nyní můžete vycvičený model uložit a implementovat jej do prostoru.
Krok 3: Uložit a implementovat model online
V této části se naučíte, jak ukládat a implementovat model, který jste vycvičili.
Uložte model.
- Ve svém dokončeném experimentu sdruženého učení klepněte na volbu Uložit model do projektu.
- Zadejte název modelu a klepněte na tlačítko Uložit.
- Přejděte na svůj projekt domů.
Vytvořte prostor implementace, pokud jej nemáte.
V nabídce navigace
 klepněte na volbu Implementace.
klepněte na volbu Implementace.Klepněte na volbu Nový prostor implementace.
Vyplňte pole a klepněte na tlačítko Vytvořit.

Povýšit model na prostor.
- Vraťte se do svého projektu a klepněte na kartu Aktiva .
- V sekci Modely klepněte na model, abyste zobrazili jeho stránku podrobností.
- Klepněte na volbu Povýšit na prostor.
- Vyberte prostor implementace pro váš proškolený model.
- Vyberte volbu Přejít na model v prostoru po povýšení .
- Klepněte na tlačítko Povýšit
Když se model zobrazí uvnitř prostoru implementace, klepněte na volbu Nová implementace.
- Vyberte volbu Online jako Typ implementace.
- Zadejte název implementace.
- Klepněte na volbu Vytvořit.
Krok 4: Ohodnocení modelu
V této sekci se naučíte vytvořit funkci Python , abyste zpracoval data hodnocení, abyste se ujistili, že je ve stejném formátu, který byl použit během školení. Pro porovnání můžete také skórovat prvotní datovou sadu voláním funkce Python , kterou jsme vytvořili.
Definujte funkci Python následujícím způsobem. Tato funkce načte data hodnocení v prvotním formátu a zpracuje data přesně tak, jak byla provedena během školení. Poté setržíte zpracovaná data.
def adult_scoring_function(): import pandas as pd from ibm_watson_machine_learning import APIClient wml_credentials = { "url": "https://us-south.ml.cloud.ibm.com", "apikey": "<API KEY>" } client = APIClient(wml_credentials) client.set.default_space('<SPACE ID>') # converts scoring input data format to pandas dataframe def create_dataframe(raw_dataset): fields = raw_dataset.get("input_data")[0].get("fields") values = raw_dataset.get("input_data")[0].get("values") raw_dataframe = pd.DataFrame( columns = fields, data = values ) return raw_dataframe # reuse preprocess definition from training data handler def preprocess(training_data): """ Performs the following preprocessing on adult training and testing data: * Drop following features: 'workclass', 'fnlwgt', 'education', 'marital-status', 'occupation', 'relationship', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country' * Map 'race', 'sex' and 'class' values to 0/1 * ' White': 1, ' Amer-Indian-Eskimo': 0, ' Asian-Pac-Islander': 0, ' Black': 0, ' Other': 0 * ' Male': 1, ' Female': 0 * Further details in Kamiran, F. and Calders, T. Data preprocessing techniques for classification without discrimination * Split 'age' and 'education' columns into multiple columns based on value :param training_data: Raw training data :type training_data: `pandas.core.frame.DataFrame :return: Preprocessed training data :rtype: `pandas.core.frame.DataFrame` """ if len(training_data.columns)==15: # drop 'fnlwgt' column training_data = training_data.drop(training_data.columns[2], axis='columns') training_data.columns = ['age', 'workclass', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'class'] # filter out columns unused in training, and reorder columns training_dataset = training_data[['race', 'sex', 'age', 'education-num', 'class']] # map 'sex' and 'race' feature values based on sensitive attribute privileged/unpriveleged groups training_dataset['sex'] = training_dataset['sex'].map({' Female': 0, ' Male': 1}) training_dataset['race'] = training_dataset['race'].map({' Asian-Pac-Islander': 0, ' Amer-Indian-Eskimo': 0, ' Other': 0, ' Black': 0, ' White': 1}) # map 'class' values to 0/1 based on positive and negative classification training_dataset['class'] = training_dataset['class'].map({' <=50K': 0, ' >50K': 1}) training_dataset['age'] = training_dataset['age'].astype(int) training_dataset['education-num'] = training_dataset['education-num'].astype(int) # split age column into category columns for i in range(8): if i != 0: training_dataset['age' + str(i)] = 0 for index, row in training_dataset.iterrows(): if row['age'] < 20: training_dataset.loc[index, 'age1'] = 1 elif ((row['age'] < 30) & (row['age'] >= 20)): training_dataset.loc[index, 'age2'] = 1 elif ((row['age'] < 40) & (row['age'] >= 30)): training_dataset.loc[index, 'age3'] = 1 elif ((row['age'] < 50) & (row['age'] >= 40)): training_dataset.loc[index, 'age4'] = 1 elif ((row['age'] < 60) & (row['age'] >= 50)): training_dataset.loc[index, 'age5'] = 1 elif ((row['age'] < 70) & (row['age'] >= 60)): training_dataset.loc[index, 'age6'] = 1 elif row['age'] >= 70: training_dataset.loc[index, 'age7'] = 1 # split age column into multiple columns training_dataset['ed6less'] = 0 for i in range(13): if i >= 6: training_dataset['ed' + str(i)] = 0 training_dataset['ed12more'] = 0 for index, row in training_dataset.iterrows(): if row['education-num'] < 6: training_dataset.loc[index, 'ed6less'] = 1 elif row['education-num'] == 6: training_dataset.loc[index, 'ed6'] = 1 elif row['education-num'] == 7: training_dataset.loc[index, 'ed7'] = 1 elif row['education-num'] == 8: training_dataset.loc[index, 'ed8'] = 1 elif row['education-num'] == 9: training_dataset.loc[index, 'ed9'] = 1 elif row['education-num'] == 10: training_dataset.loc[index, 'ed10'] = 1 elif row['education-num'] == 11: training_dataset.loc[index, 'ed11'] = 1 elif row['education-num'] == 12: training_dataset.loc[index, 'ed12'] = 1 elif row['education-num'] > 12: training_dataset.loc[index, 'ed12more'] = 1 training_dataset.drop(['age', 'education-num'], axis=1, inplace=True) # move class column to be last column label = training_dataset['class'] training_dataset.drop('class', axis=1, inplace=True) training_dataset['class'] = label return training_dataset def score(raw_dataset): try: # create pandas dataframe from input raw_dataframe = create_dataframe(raw_dataset) # reuse preprocess from training data handler processed_dataset = preprocess(raw_dataframe) # drop class column processed_dataset.drop('class', inplace=True, axis='columns') # create data payload for scoring fields = processed_dataset.columns.values.tolist() values = processed_dataset.values.tolist() scoring_dataset = {client.deployments.ScoringMetaNames.INPUT_DATA: [{'fields': fields, 'values': values}]} print(scoring_dataset) # score data prediction = client.deployments.score('<MODEL DEPLOYMENT ID>', scoring_dataset) return prediction except Exception as e: return {'error': repr(e)} return scoreNahraďte proměnné v předchozí funkci Python :
API KEY: Klíč rozhraní API IAM. Chcete-li vytvořit nový klíč rozhraní API, přejděte na web IBM Clouda klepněte na volbu Vytvořit klíč rozhraní API IBM Cloud pod volbou Spravovat > Access (IAM) > Klíče rozhraní API.SPACE ID: ID prostoru implementace, kde je spuštěna implementace pro dospělé příjmy. Chcete-li zobrazit ID prostoru, přejděte na volbu Prostory implementace >YOUR SPACE NAME> Spravovat. Zkopírujte GUID prostoru.MODEL DEPLOYMENT ID: ID implementace online pro model příjmů dospělých. Chcete-li vidět své ID modelu, můžete jej zobrazit klepnutím na model ve svém projektu. Nachází se v adresním řádku i v informačním podokně.
Získejte ID softwarové specifikace pro Python 3.9. Pro seznam jiných prostředí spusťte soubor client.software_specifications.list().
software_spec_id = client.software_specifications.get_id_by_name('default_py3.9')Uložte funkci Python do svého prostoru Watson Studio .
# stores python function in space meta_props = { client.repository.FunctionMetaNames.NAME: 'Adult Income Scoring Function', client.repository.FunctionMetaNames.SOFTWARE_SPEC_ID: software_spec_id } stored_function = client.repository.store_function(meta_props=meta_props, function=adult_scoring_function) function_id = stored_function['metadata']['id']Vytvořte online nasazení pomocí funkce Python .
# create online deployment for fucntion meta_props = { client.deployments.ConfigurationMetaNames.NAME: "Adult Income Online Scoring Function", client.deployments.ConfigurationMetaNames.ONLINE: {} } online_deployment = client.deployments.create(function_id, meta_props=meta_props) function_deployment_id = online_deployment['metadata']['id']Stáhněte datovou sadu Income Income. Tato hodnota se znovu použije jako data přidělení skóre.
import pandas as pd # read adult csv dataset adult_csv = pd.read_csv('./adult.csv', dtype='category') # use 10 random rows for scoring sample_dataset = adult_csv.sample(n=10) fields = sample_dataset.columns.values.tolist() values = sample_dataset.values.tolist()Relevantnost dat o příjmu pro dospělé pomocí vytvořené funkce Python .
raw_dataset = {client.deployments.ScoringMetaNames.INPUT_DATA: [{'fields': fields, 'values': values}]} prediction = client.deployments.score(function_deployment_id, raw_dataset) print(prediction)
Další kroky
Vytvoření produktu Federated Learning Experiment.
Nadřízené téma: Výukový program sdruženého učení a ukázky