Tutoriel de l'apprentissage fédéré XGBoost pour l'interface utilisateur
Ce tutoriel présente l'utilisation de l'apprentissage fédéré dans le but d'entraîner un modèle d'apprentissage automatique avec des données provenant de différents utilisateurs sans que ces derniers aient à partager leurs données. Les étapes sont réalisées dans un environnement low-code avec l'interface utilisateur et avec une infrastructure XGBoost. En utilisant l'ensemble de données UCI : Adult - Predict income, le modèle entraîné prédit si le revenu dépasse $50K/yr sur la base des données de recensement. L'ensemble de données est également connu sous le nom de "Census Income".
Dans ce tutoriel, vous exécutez les tâches suivantes :
- Tâche 1 : Démarrer Federated Learning en tant qu'administrateur
- Tâche 2 : Former le modèle en tant que parti
- Tâche 3 : Enregistrer et déployer le modèle en ligne
- Tâche 4 : Noter le modèle
Remarques :
- Il s'agit d'un tutoriel étape par étape pour réaliser une expérience d'apprentissage fédéré pilotée par l'interface utilisateur. Pour voir un exemple de code pour une approche basée sur l'API, rendez-vous sur Federated Learning XGBoost samples.
- Dans ce tutoriel, admin fait référence à l'utilisateur qui démarre l'expérience d'apprentissage fédéré, et party fait référence à un ou plusieurs utilisateurs qui envoient les résultats de leur modèle après que l'expérience a été démarrée par l'admin. Si le tutoriel peut être suivi par l'administrateur et plusieurs parties, un seul utilisateur peut également effectuer un parcours complet en tant qu'administrateur et partie. Pour faciliter la démonstration dans le tutoriel suivant, un seul jeu de données est soumis par une seule partie. Pour plus d'informations sur l'administrateur et le parti, voir Terminologie.
Prérequis
Vérifier la version de Python
Vérifiez que vous utilisez la même version de Python que l'administrateur. L'utilisation d'une version Python différente peut entraîner des problèmes de compatibilité. Pour voir les versions de Python compatibles avec différentes infrastructures, voir infrastructures et compatibilité de version Python.
Ouvrir un projet
Utilisez un projet existant ou créez-en un nouveau. Vous devez avoir au moins le droit d'administrateur.
Associez le service watsonx.ai Runtime à votre projet.
- Dans votre projet, cliquez sur Manage > Service & integrations.
- Cliquez sur Associer un service.
- Sélectionnez votre instance watsonx.ai Runtime dans la liste, et cliquez sur Associer; ou cliquez sur Nouveau service si vous n'en avez pas pour configurer une instance.

Tâche 1 : Démarrer l'apprentissage fédéré
Dans cette section, vous créez, configurez et démarrez une expérience d'apprentissage fédéré.
Tâche 1a: Créer l'actif de l'expérience d'apprentissage fédéré
Dans votre projet, cliquez sur l'onglet Assets.
Cliquez sur Nouvelle ressource > Former des modèles sur des données distribuées pour créer la ressource Expérience d'apprentissage fédéré.
Saisissez un nom pour votre expérience et éventuellement une description.
Vérifiez l'instance watsonx.ai Runtime associée sous Select a machine learning instance. Si vous ne voyez pas d'instance de Runtime watsonx.ai associée, suivez les étapes suivantes :
Cliquez sur Associer une instance de service d'Machine Learning.
Sélectionnez une instance existante et cliquez sur Associer, ou créez un nouveau service.
Cliquez sur Recharger pour afficher le service associé.
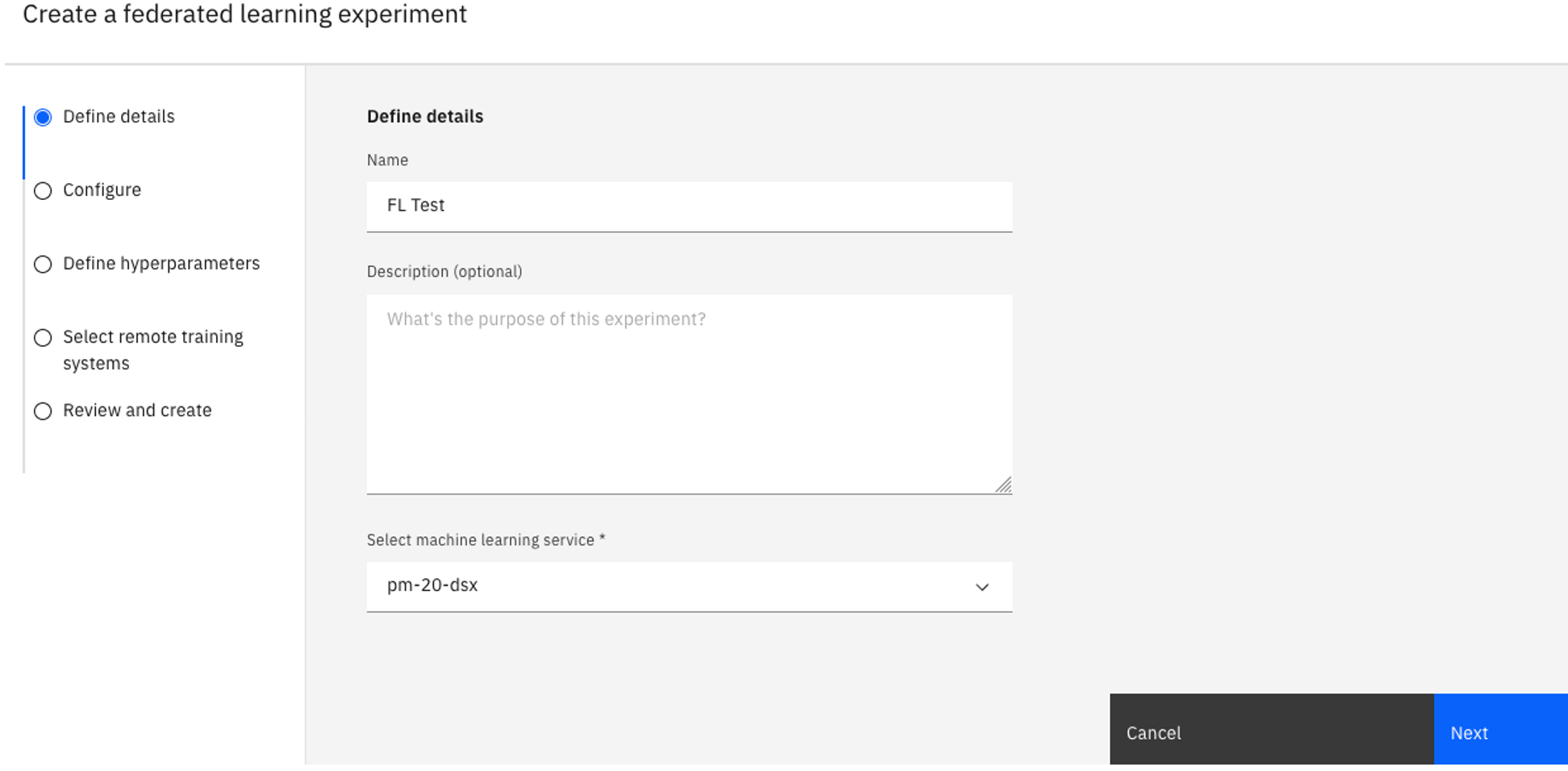
Cliquez sur Suivant.
Tâche 1b: Configurer l'expérience
Sur la page Configurer, sélectionnez une spécification matérielle.
Dans la liste déroulante Machine learning framework, sélectionnez scikit-learn.
Pour le type de modèle, sélectionnez XGBoost.
Pour la méthode de fusion, sélectionnez la fusion de classification XGBoost.
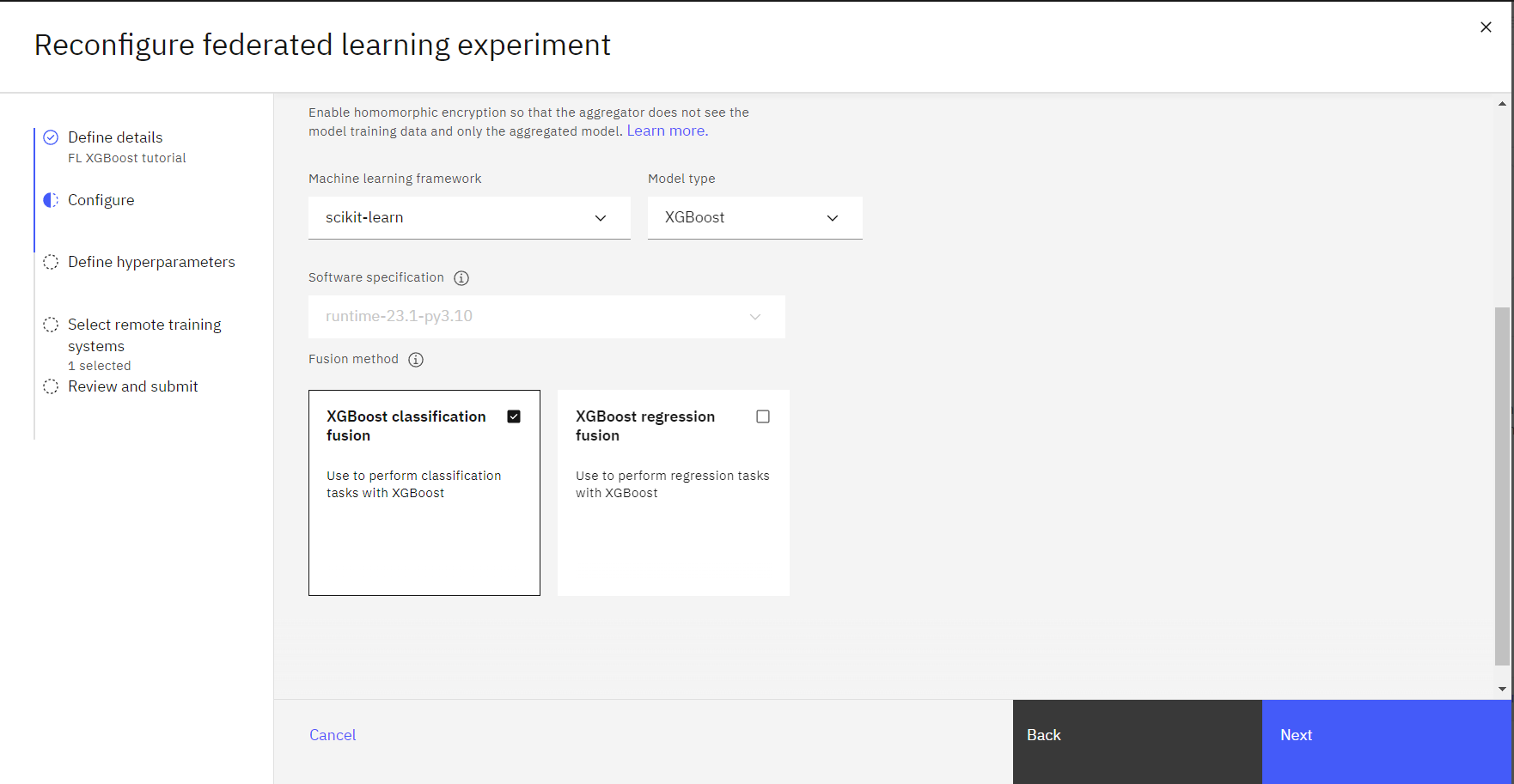
Cliquez sur Suivant.
Tâche 1c: Définir les hyperparamètres
Attribuez la valeur "
5Acceptez les valeurs par défaut pour les autres champs.

Cliquez sur Suivant.
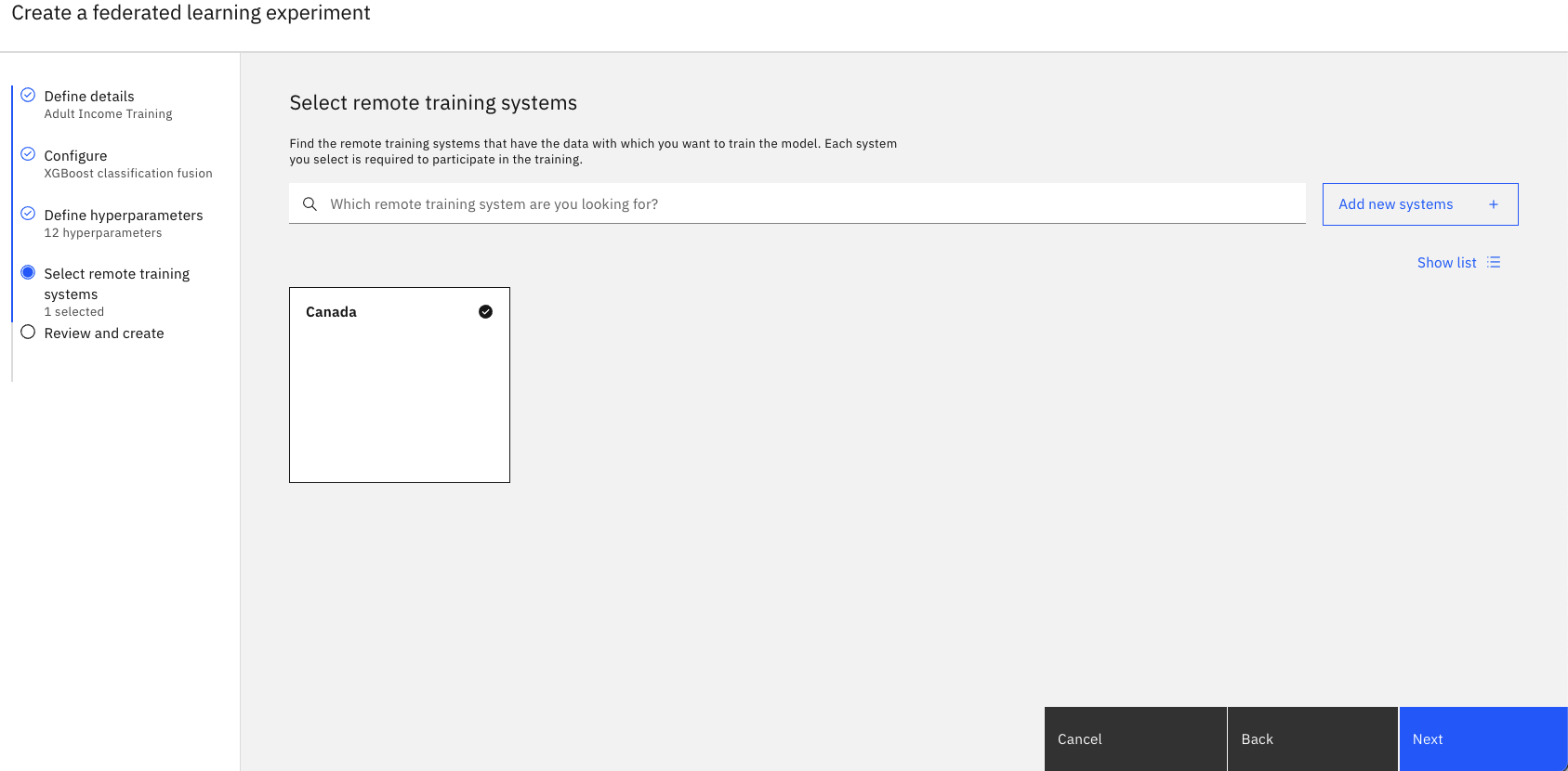
Tâche 1d: Sélectionner les systèmes de formation à distance
Cliquez sur Ajouter de nouveaux systèmes.
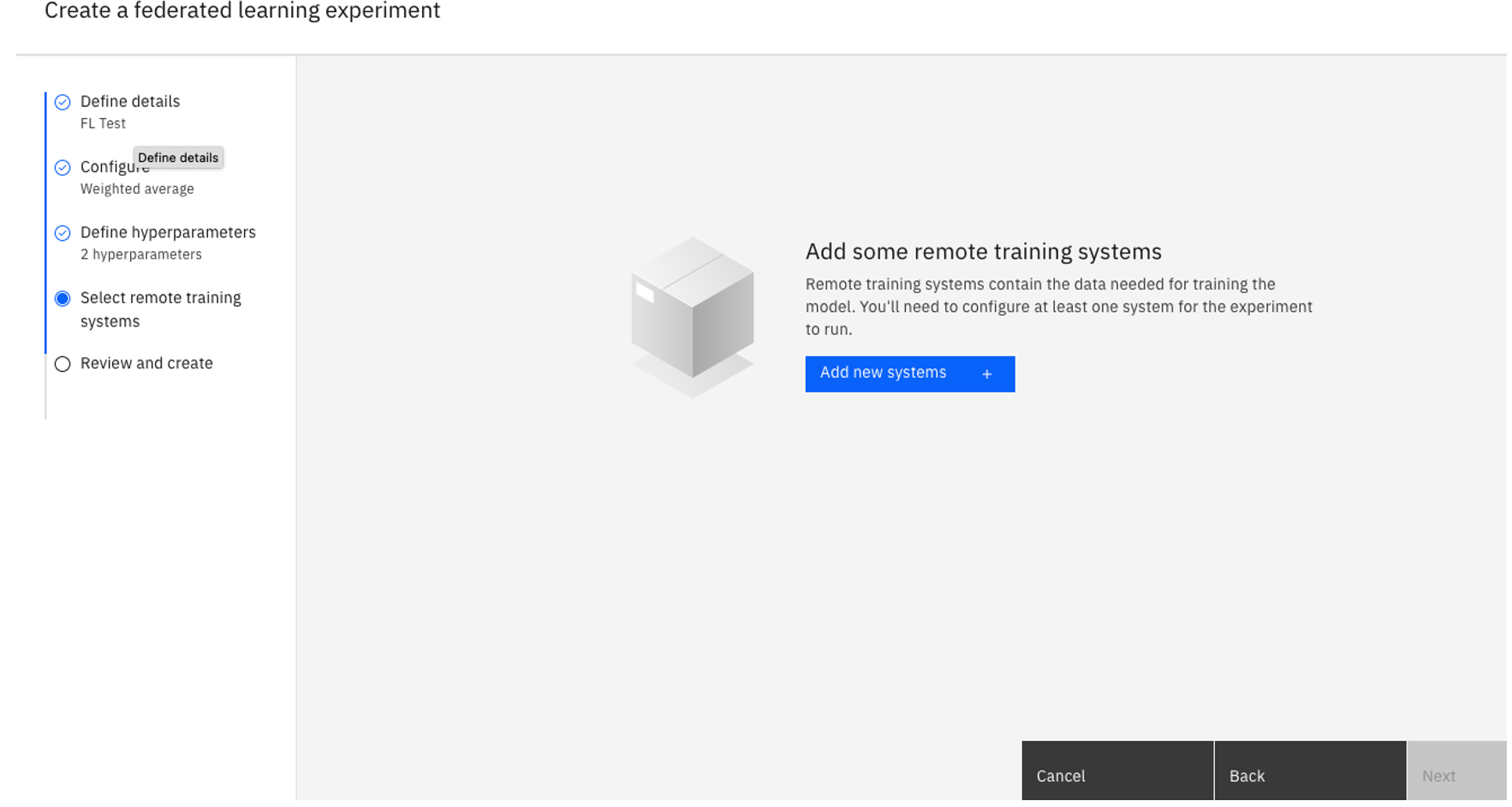
Saisissez un nom pour votre système de formation à distance.
Sous Identités autorisées, sélectionnez l'utilisateur qui participera à l'expérience, puis cliquez sur Ajouter. Vous pouvez ajouter autant d'identités autorisées que les participants à cette instance d'entraînement d'expérimentation fédérée. Pour ce tutoriel, choisissez uniquement vous-même.
Toute identité autorisée doit être un collaborateur du projet et avoir au moins l'autorisation de 'Administrateur Ajoutez des systèmes supplémentaires en répétant cette étape pour chaque partie distante que vous prévoyez d'utiliser.Lorsque vous avez terminé, cliquez sur Ajouter des systèmes.
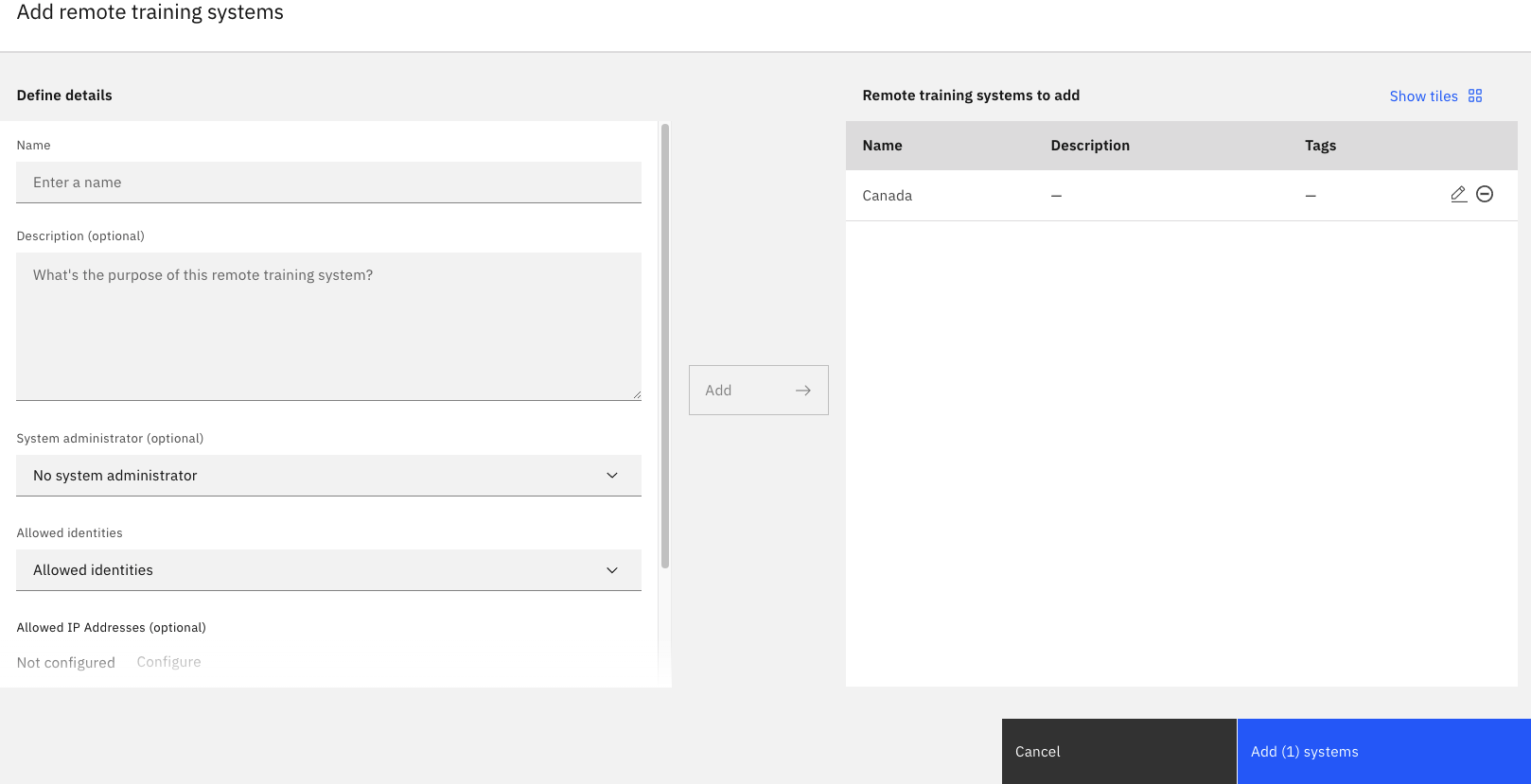
Revenez à la page Sélectionner les systèmes de formation à distance, vérifiez que votre système est sélectionné, puis cliquez sur Suivant.
Tâche 1e: Examiner les paramètres
Vérifiez vos paramètres, puis cliquez sur Créer.
Voir le statut. Le statut de votre expérimentation d'apprentissage fédéré est En attente quand elle démarre. Lorsque votre expérimentation est prête pour que les parties prenantes s'y connectent, le statut devient Configuration - En attente de systèmes distants. Cette opération peut prendre quelques minutes.
Cliquez sur Afficher les informations de configuration pour télécharger la configuration du parti et le script du connecteur de parti que vous pouvez exécuter sur le parti distant.
Cliquez sur l'icône Download config '
 à côté de chacun des systèmes de formation à distance que vous avez créés. Enregistrez le script du connecteur de parti dans un répertoire de votre machine sous le nom :
à côté de chacun des systèmes de formation à distance que vous avez créés. Enregistrez le script du connecteur de parti dans un répertoire de votre machine sous le nom :remote-test-system-configuration.py
Cliquez sur Terminé.
 Vérifier votre progression
Vérifier votre progression
L'image suivante montre l'expérience avec le statut "en attente de systèmes distants".

Tâche 2 : Former le modèle en tant que parti
Pour entraîner le modèle, vous devez télécharger les ensembles de données, puis éditer et exécuter des scripts python. Suivez les étapes suivantes pour former le modèle en tant que parti :
Tâche 2a: Télécharger les ensembles de données et les scripts
Créez un nouveau répertoire local et placez-y le script du connecteur de parti que vous avez téléchargé à la tâche 1e.
Téléchargez les fichiers suivants en faisant un clic droit sur le nom du fichier, puis en cliquant sur Enregistrer le lien sous. Sauvegardez-le dans le même répertoire que le script connecteur de parties.
Vérifiez que le script du connecteur de parti, l'ensemble de données Adult, le gestionnaire de données et le fichier de configuration du journal se trouvent dans le même répertoire. Si vous dressez la liste des fichiers du répertoire, vous devriez voir ces fichiers :
adult.csv adult_sklearn_data_handler.py remote-test-system-configuration.py log_config.yaml
Tâche 2b: Installer le moteur d'exécution watsonx.ai
Si vous utilisez Windows ou Linux, exécutez '
pip install 'ibm_watsonx_ai[fl-rt23.1-py3.10]'Si vous utilisez Mac OS avec un processeur de la série M et Conda, téléchargez le script d'installation et exécutez '
./install_fl_rt23.1_macos.sh <name for new conda environment>
Tâche 2c: Modifier et exécuter le script du connecteur de parti
Modifiez le fichier du connecteur de parti, " remote-test-systm-configuration.py
Ajoutez le code suivant à la deuxième ligne du fichier python.
log_config_path = "log_config.yaml"Fournissez vos informations d'identification : Collez la clé API de l'utilisateur défini dans le système de formation à distance. Si vous n'avez pas de clé API, accédez à la page Clés API d'IBM Cloud, puis cliquez sur Créer une clé API, remplissez les champs et cliquez sur Créer.
Pour le champ party_metadata, indiquez le nom, le chemin et les informations, qui doivent être similaires au texte JSON suivant.
party_metadata = { wml_client.remote_training_systems.ConfigurationMetaNames.DATA_HANDLER: { "info": {"txt_file": "./adult.csv"}, "name": "AdultSklearnDataHandler", "path": "./adult_sklearn_data_handler.py" } }où :
namepathinfo
Enregistrez le script du connecteur de fête.
Exécutez le script du connecteur de parti en utilisant '
pythonpython3python remote-test-system-configuration.py
A partir de l'interface utilisateur, vous pouvez surveiller le statut de votre expérimentation d'apprentissage fédéré. Lorsque toutes les parties participantes se connectent à l'agrégateur, celui-ci facilite l'apprentissage du modèle local et la mise à jour du modèle global. Son statut est en formation. Vous pouvez contrôler l'état de votre expérience Federated Learning à partir de l'interface utilisateur. Lorsque la formation est terminée, le parti reçoit un " Received STOP message
Vérifier votre progression
L'image suivante montre l'expérience réalisée.
'

Tâche 3 : Enregistrer et déployer le modèle en ligne
Dans cette section, vous apprendrez à enregistrer et à déployer le modèle que vous avez formé.
Tâche 3a: Enregistrez votre modèle
- Dans votre expérience d'apprentissage fédéré, cliquez sur Enregistrer l'agrégat.
- Dans l'écran Enregistrer le modèle agrégé dans le projet, saisissez un nom pour le modèle. et cliquez sur Créer.
- Lorsque la notification de création du modèle s'affiche, cliquez sur Afficher dans le projet. Si vous manquez la notification, cliquez sur le nom du projet pour revenir à l'onglet Actifs et cliquez sur le nom du modèle pour l'afficher.
Tâche 3b: Promouvoir le modèle dans un espace
- Dans la section Modèles, cliquez sur le modèle pour afficher sa page de détails.
- Cliquez sur Promouvoir pour l'espace de déploiement "
 .
. - Choisissez un espace cible dans la liste ou créez un nouvel espace de déploiement.
Sélectionnez Créer un nouvel espace de déploiement.
Saisissez un nom pour l'espace de déploiement.
Sélectionnez votre service de stockage.
Sélectionnez votre service d'apprentissage automatique.
Cliquez sur Créer.
Lorsque l'espace de déploiement est créé, fermez la fenêtre.
- Sélectionnez l'option Aller au modèle dans l'espace après l'avoir promu.
- Cliquez sur Promouvoir.
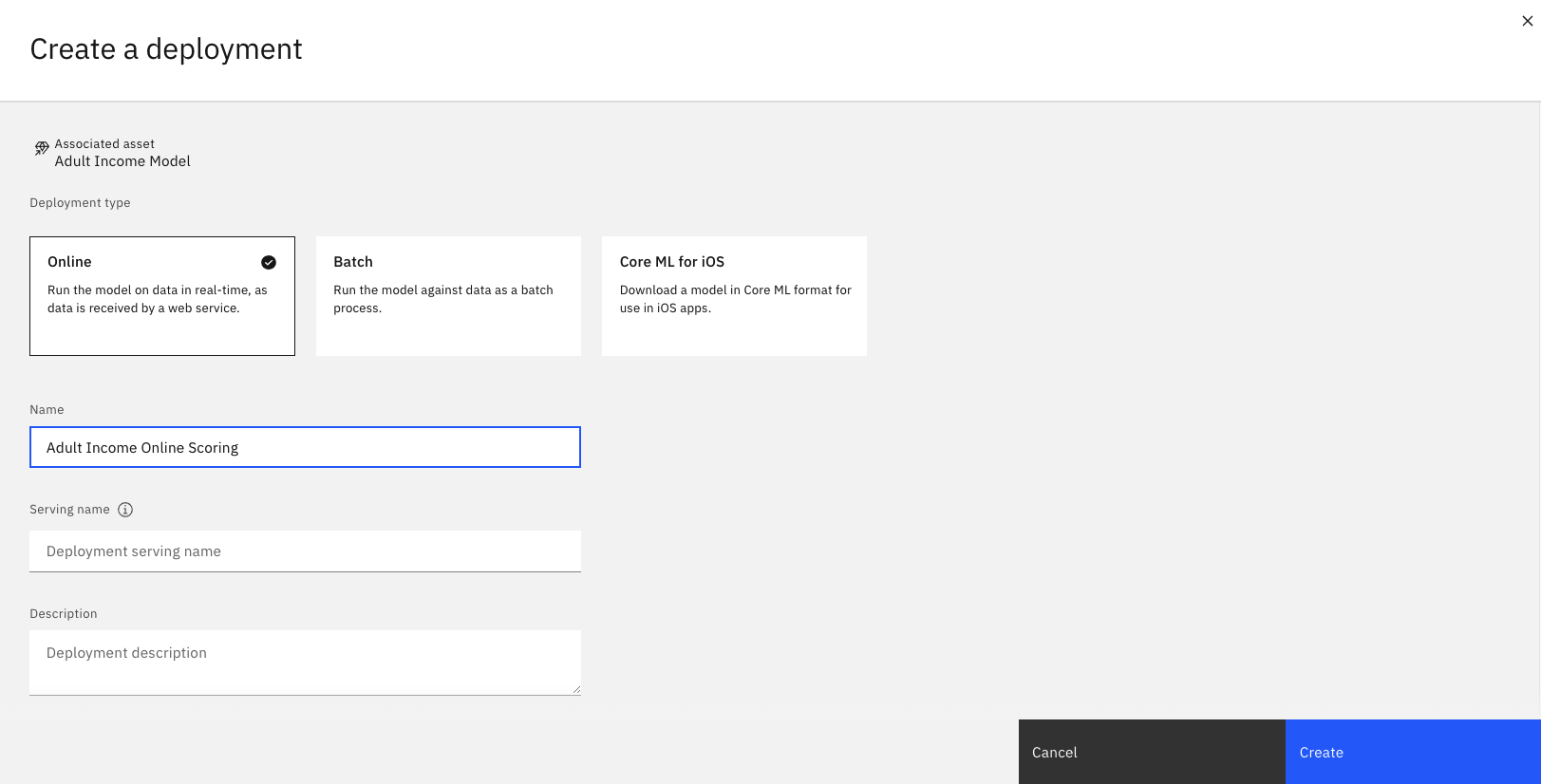
Tâche 3c: Créer et visualiser le déploiement en ligne
- Lorsque le modèle s'affiche dans l'espace de déploiement, cliquez sur Nouveau déploiement.
- Sélectionnez En ligne comme Type de déploiement.
- Indiquez un nom pour le déploiement.
- Cliquez sur Créer.
- Attendez que l'état de la répartition devienne Déployé, puis cliquez sur le nom de la répartition.
- Consultez les points de terminaison et les extraits de code pour utiliser ce déploiement dans votre application.
Vérifier votre progression
L'image suivante montre le déploiement en ligne,
"
Tâche 4 : Noter le modèle
Dans cette section, vous apprendrez à créer une fonction Python pour traiter les données de notation afin de s'assurer qu'elles sont dans le même format que celui utilisé lors de la formation. À titre de comparaison, vous obtiendrez également un score pour l'ensemble des données brutes en appelant la fonction Python que nous avons créée.
Vous pouvez créer un script Python et l'exécuter localement, ou créer un bloc-notes Jupyter et exécuter le code dans le bloc-notes.
Configuration de l'environnement
Ce code importe la bibliothèque et le paquetage nécessaires et définit les informations d'identification pour accéder au client de l'API d'apprentissage automatique.
# import the library and package and set the credentials
from ibm_watsonx_ai import APIClient
wml_credentials = {
"url": "https://us-south.ml.cloud.ibm.com",
"apikey": "<insert-api-key-here>"
}
client = APIClient(wml_credentials)
client.set.default_space('<insert-deployment-space-id-here>')
software_spec_id = client.software_specifications.get_id_by_name('default_py3.10')
- Collez votre clé API IBM Cloud dans le champ '
apikey - Collez votre ID d'espace de déploiement. Procédez comme suit pour trouver l'ID de l'espace de déploiement.
- Accédez à vos espaces de déploiement.
- Ouvrez votre espace de déploiement.
- Cliquez sur l'onglet Gérer.
- Copiez le " GUID de l'espace et collez-le à la place du "
<insert-deployment-space-id-here>
Charger l'ensemble des données
Ce code lit l'ensemble des données stockées dans le concentrateur de ressources.
# read the data set
import pandas as pd
import io
import requests
url = "https://api.dataplatform.cloud.ibm.com/v2/gallery-assets/entries/5fcc01b02d8f0e50af8972dc8963f98e/data"
s = requests.get(url).content
adult_csv = pd.read_csv(io.StringIO(s.decode('utf-8')))
adult_csv.head(5)
Créer l'ensemble de données d'apprentissage
Ce code choisit 10 lignes aléatoires dans l'ensemble de données pour la notation.
# choose 10 random rows for the test data set
training_data = adult_csv.sample(n=10)
training_data.head(10)
Définir la fonction de préparation des données de formation
Ce code définit une fonction permettant de charger les données de notation dans leur format brut et de traiter les données exactement comme elles l'ont été pendant la formation. Ensuite, il faut noter les données traitées
Le code effectue le prétraitement suivant sur les données d'entraînement et de test des adultes :
Supprimer les caractéristiques suivantes : "classe ouvrière", "fnlwgt", "éducation", "état civil", "profession", "relation", "gain en capital", "perte en capital", "heures par semaine", "pays d'origine"
Carte :
- les valeurs "race", "sexe" et "classe" à 0/1
- blanc" : 1, "Amérindien-Esquimau" : 0, "Asiatique-Pacifique-Islandais" : 0, ' Noir' : 0, ' Autre' : 0
- homme' : 1, ' Femme' : 0
Pour plus de détails, voir Kamiran, F. et Calders, T. Data preprocessing techniques for classification without discrimination
Diviser les colonnes "âge" et "éducation" en plusieurs colonnes en fonction de la valeur
# define the preprocess function to prepare the data for scoring
def preprocess(training_data):
if len(training_data.columns)==15:
# drop 'fnlwgt' column
training_data = training_data.drop(training_data.columns[2], axis='columns')
training_data.columns = ['age',
'workclass',
'education',
'education-num',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'capital-gain',
'capital-loss',
'hours-per-week',
'native-country',
'class']
# filter out columns unused in training, and reorder columns
training_dataset = training_data[['race', 'sex', 'age', 'education-num', 'class']]
# map 'sex' and 'race' feature values based on sensitive attribute privileged/unpriveleged groups
training_dataset['sex'] = training_dataset['sex'].map({
' Female': 0,
' Male': 1
})
training_dataset['race'] = training_dataset['race'].map({
' Asian-Pac-Islander': 0,
' Amer-Indian-Eskimo': 0,
' Other': 0,
' Black': 0,
' White': 1
})
# map 'class' values to 0/1 based on positive and negative classification
training_dataset['class'] = training_dataset['class'].map({' <=50K': 0, ' >50K': 1})
training_dataset['age'] = training_dataset['age'].astype(int)
training_dataset['education-num'] = training_dataset['education-num'].astype(int)
# split age column into category columns
for i in range(8):
if i != 0:
training_dataset['age' + str(i)] = 0
for index, row in training_dataset.iterrows():
if row['age'] < 20:
training_dataset.loc[index, 'age1'] = 1
elif ((row['age'] < 30) & (row['age'] >= 20)):
training_dataset.loc[index, 'age2'] = 1
elif ((row['age'] < 40) & (row['age'] >= 30)):
training_dataset.loc[index, 'age3'] = 1
elif ((row['age'] < 50) & (row['age'] >= 40)):
training_dataset.loc[index, 'age4'] = 1
elif ((row['age'] < 60) & (row['age'] >= 50)):
training_dataset.loc[index, 'age5'] = 1
elif ((row['age'] < 70) & (row['age'] >= 60)):
training_dataset.loc[index, 'age6'] = 1
elif row['age'] >= 70:
training_dataset.loc[index, 'age7'] = 1
# split age column into multiple columns
training_dataset['ed6less'] = 0
for i in range(13):
if i >= 6:
training_dataset['ed' + str(i)] = 0
training_dataset['ed12more'] = 0
for index, row in training_dataset.iterrows():
if row['education-num'] < 6:
training_dataset.loc[index, 'ed6less'] = 1
elif row['education-num'] == 6:
training_dataset.loc[index, 'ed6'] = 1
elif row['education-num'] == 7:
training_dataset.loc[index, 'ed7'] = 1
elif row['education-num'] == 8:
training_dataset.loc[index, 'ed8'] = 1
elif row['education-num'] == 9:
training_dataset.loc[index, 'ed9'] = 1
elif row['education-num'] == 10:
training_dataset.loc[index, 'ed10'] = 1
elif row['education-num'] == 11:
training_dataset.loc[index, 'ed11'] = 1
elif row['education-num'] == 12:
training_dataset.loc[index, 'ed12'] = 1
elif row['education-num'] > 12:
training_dataset.loc[index, 'ed12more'] = 1
training_dataset.drop(['age', 'education-num'], axis=1, inplace=True)
# move class column to be last column
label = training_dataset['class']
training_dataset.drop('class', axis=1, inplace=True)
training_dataset['class'] = label
return training_dataset
Traiter les données d'apprentissage
Ce code utilise la fonction preprocess pour préparer les données.
# use the preprocess function to prepare the data
processed_dataset = preprocess(training_data)
# drop class column
processed_dataset.drop('class', inplace=True, axis='columns')
processed_dataset.head(10)
Créer des données utiles pour l'évaluation
Ce code crée l'ensemble des données de notation.
# create data payload for scoring
fields = processed_dataset.columns.values.tolist()
values = processed_dataset.values.tolist()
scoring_dataset = {client.deployments.ScoringMetaNames.INPUT_DATA: [{'fields': fields, 'values': values}]}
import json
print("Scoring data: ")
scoring_formatted = json.dumps(scoring_dataset, indent=2)
print(scoring_formatted)
Evaluer le modèle
Ce code envoie une demande de notation au modèle en utilisant l'ensemble de données de notation. Vous devrez inclure votre identifiant de déploiement en ligne dans ce code. Procédez comme suit pour trouver l'identifiant de déploiement en ligne.
- Accédez à vos espaces de déploiement.
- Ouvrez votre espace de déploiement.
- Cliquez sur l'onglet Déploiements.
- Ouvrez votre déploiement en ligne.
- Dans le volet d'information, copiez l'ID de déploiement et collez-le à la place de "
<insert-your-online-deployment-id-here>
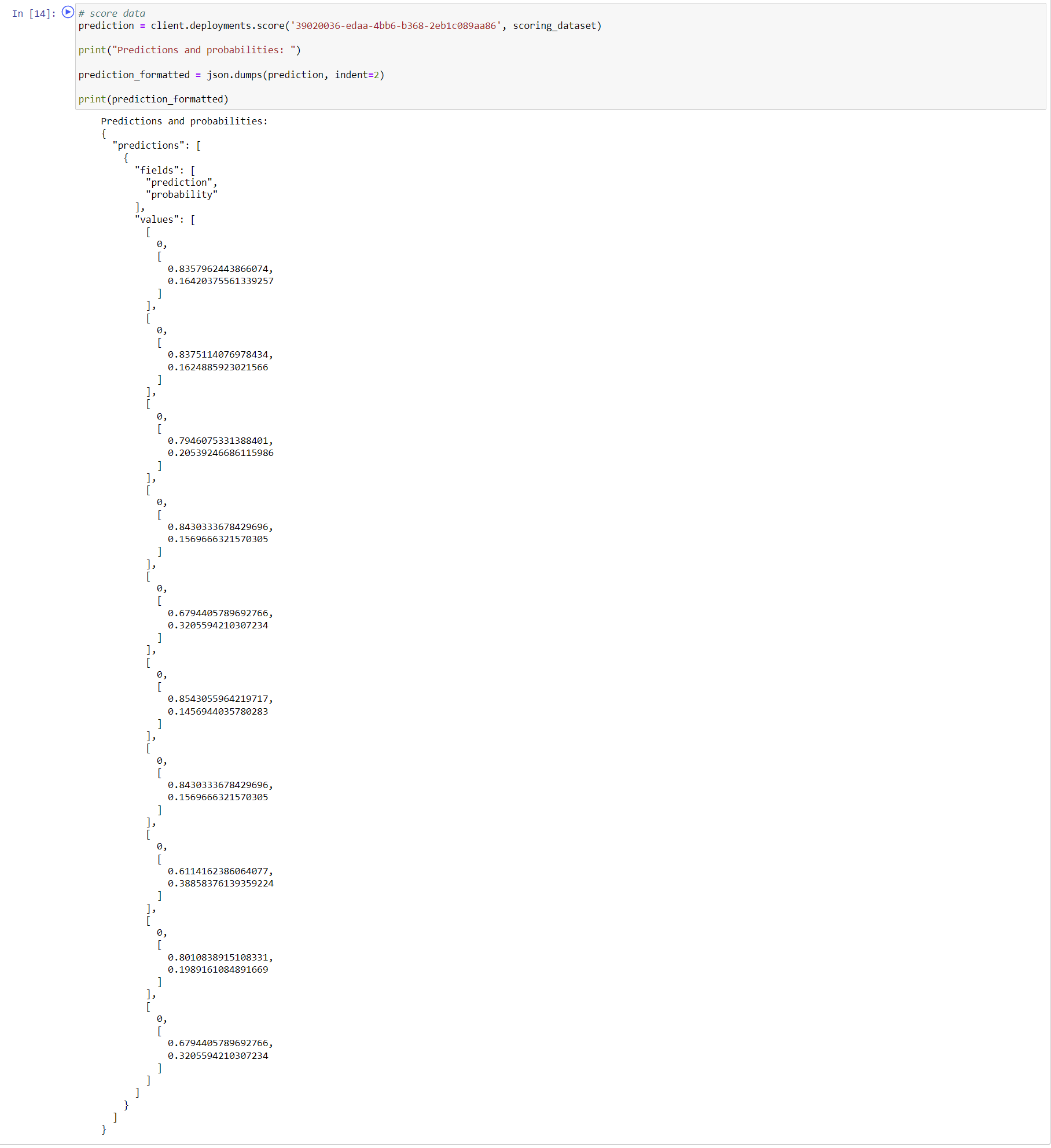
# score data
prediction = client.deployments.score('<insert-your-online-deployment-id-here>', scoring_dataset)
print("Predictions and probabilities: ")
prediction_formatted = json.dumps(prediction, indent=2)
print(prediction_formatted)
Vérifier votre progression
L'image suivante montre les prédictions et les probabilités de la demande de notation complétée.
'
Etapes suivantes
Est-vous prêt à créer votre propre expérimentation fédérée personnalisée ? Voir les étapes de haut niveau dans la création de votre expérience d'apprentissage fédéré.
Sujet parent : Tutoriel et exemples sur l'apprentissage fédéré