Review the considerations and requirements for deploying a custom foundation model for inferencing with watsonx.ai.
As you prepare to deploy a custom foundation model, review these planning considerations:
- Review the Requirements and usage notes for custom foundation models
- Review the Supported architectures for custom foundation models to make sure that your model is compatible.
- Collect the details that are required as prerequisites for deploying a custom foundation model.
- Select a hardware specification for your custom foundation model.
- Review the deployment limitations
- Enable task credentials to be able to deploy custom foundation models.
Requirements and usage notes for custom foundation models
Deployable custom models must meet these requirements:
-
Uploading and using your own custom model is available only in the Standard plan for watsonx.ai.
-
The model must be compatible with the Text Generation Inference (TGI) standard and be built with a supported model architecture type.
-
The file list for the model must contain a
config.jsonfile. -
The model must be in a
safetensorsformat with the supported transformers library and must include atokenizer.jsonfile.Important:- You must make sure that your custom foundation model is saved with the supported
transformerslibrary. If the model.safetensors file for your custom foundation model uses an unsupported data format in the metadata header, your deployment might fail. For more information, see Troubleshooting watsonx.ai Runtime. - Make sure that the project or space where you want to deploy your custom foundation model has an associated watsonx.ai Runtime instance. Open the Manage tab in your project or space to check that.
- You must make sure that your custom foundation model is saved with the supported
Supported model architectures
The following table lists the model architectures that you can deploy as custom models for inferencing with watsonx.ai. The model architectures are listed together with information about their supported quantization methods, parallel tensors, deployment configuration sizes, and software specifications.
Two software specifications are available for your deployments: watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1. The watsonx-cfm-caikit-1.1 specification is better in terms of performance, but it's not
available with every model architecture.
| Model architecture type | Quantization method | Parallel tensors (multiGpu) | Deployment configurations | Software specifications |
|---|---|---|---|---|
bloom |
N/A | Yes | Small, Medium, Large | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
codegen |
N/A | No | Small | watsonx-cfm-caikit-1.0 |
falcon |
N/A | Yes | Small, Medium, Large | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
gpt_bigcode |
gptq |
Yes | Small, Medium, Large | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
gpt-neox |
N/A | Yes | Small, Medium, Large | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
gptj |
N/A | No | Small | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
llama |
gptq |
Yes | Small, Medium, Large | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
mixtral |
gptq |
No | Small | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
mistral |
N/A | No | Small | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
mt5 |
N/A | No | Small | watsonx-cfm-caikit-1.0 |
mpt |
N/A | No | Small | watsonx-cfm-caikit-1.0, watsonx-cfm-caikit-1.1 |
t5 |
N/A | Yes | Small, Medium, Large | watsonx-cfm-caikit-1.0 |
- IBM does not support deployment failures as a result of deploying foundation models with unsupported architectures.
- Deployments of
llama 3.1models might fail. To address this issue, see steps that are listed in Troubleshooting. - It is not possible to deploy
codegen,mt5, andt5type models with thewatsonx-cfm-caikit-1.1software specification. - If your model does not support parallel tensors, the only configuration that you can use is
Small. If your model was trained with more parameters than theSmallconfiguration supports it will fail. This means that you won't be able to deploy some of your custom models. For more information on limitations, see Resource utilization guidelines.
Collecting the prerequisite details for a custom foundation model
-
Check for the existence of the file
config.jsonin the foundation model content folder. Deployment service will mandate for existence of the fileconfig.jsonin the foundation model content folder after it is uploaded to the cloud storage. -
Open the
config.jsonfile to confirm that the foundation model uses a supported architecture. -
View the list of files for the foundation model to check for the
tokenizer.jsonfile and that the model content is in.safetensorsformat.Important:You must make sure that your custom foundation model is saved with the supported
transformerslibrary. If the model.safetensors file for your custom foundation model uses an unsupported data format in the metadata header, your deployment might fail. For more information, see Troubleshooting watsonx.ai Runtime.
See an example:
For the falcon-40b model stored on Hugging Face, click Files and versions to view the file structure and check for config.json:
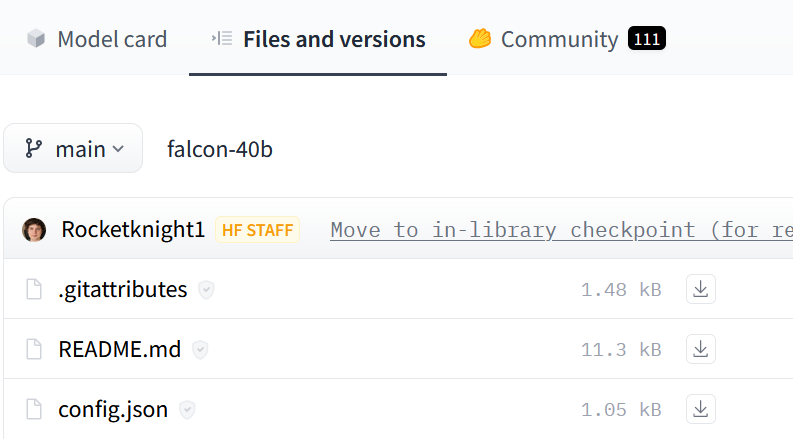
The example model uses a version of the supported falcon architecture.

This example model contains the tokenizer.json file and is in the .safetensors format:
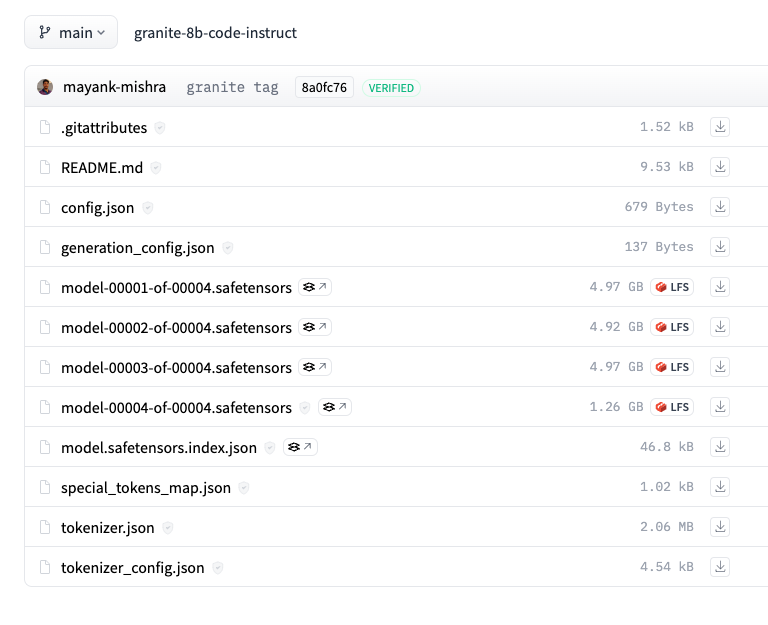
If the model does not meet these requirements, you cannot create a model asset and deploy your model.
Resource utilization guidelines
Three configurations are available to support your custom foundation model: Small, Medium, and Large. To determine the most suitable configuration for your custom foundation model, see the following guidelines:
- Assign the
Smallconfiguration to any double-byte precision model under 26B parameters, subject to testing and validation. - Assign the
Mediumconfiguration to any double-byte precision model between 27B and 53B parameters, subject to testing and validation. - Assign the
Largeconfiguration to any double byte precision model between 54B and 106B parameters, subject to testing and validation.
If the selected configuration fails during the testing and validation phase, consider exploring the next higher configuration available. For example, try the Medium configuration if the Small configuration fails.
Currently the Large configuration is the highest available configuration.
| Configuration | Examples of suitable models |
|---|---|
| Small | llama-3-8bllama-2-13bstarcoder-15.5bmt0-xxl-13bjais-13bgpt-neox-20bflan-t5-xxl-11bflan-ul2-20ballam-1-13b |
| Medium | codellama-34b |
| Large | llama-3-70b llama-2-70b |
Limitation and restrictions for custom foundation models
Note these limits on how you can deploy and use custom foundation models with watsonx.ai.
Limitations for deploying custom foundation models
Due to high demand for custom foundation model deployments and limited resources to accommodate it, watsonx.ai has a deployment limit of either four small models, two medium models, or one large model per IBM Cloud account. If you attempt to import a custom foundation model beyond these limits, you will be notified and asked to share your feedback through a survey. This will help us understand your needs and plan for future capacity upgrades.
Restrictions for using custom foundation model deployments
Note these restrictions for using custom foundation models after they are deployed with watsonx.ai:
- You cannot tune a custom foundation model.
- You cannot use watsonx.governance to evaluate or track a prompt template for a custom foundation model.
- You can prompt a custom foundation model but cannot save a prompt template for a custom model.
Help us improve this experience
If you want to share your feedback now, click this link. Your feedback is essential in helping us plan for future capacity upgrades and improve the overall custom foundation model deployment experience. Thank you for your cooperation!
Next steps
Downloading a custom foundation model and setting up storage
Parent topic: Deploying a custom foundation model