Translation not up to date
Ten kurs prowadzi użytkownika przez szkolenie modelu do przewidywania, czy klient może kupić namiot ze sklepu ze sprzętem zewnętrznym.
Utwórz eksperyment AutoAI w celu zbudowania modelu, który analizuje dane i wybiera najlepszy typ modelu i algorytmy do tworzenia, uczenia i optymalizowania rurociągów. Po przejrzenia rurociągów, zapisz go jako model, wdróż go, a następnie przetestuj, aby uzyskać predykcję.
Obejrzyj ten film wideo, aby zobaczyć podgląd kroków w tym kursie.
Ten film wideo udostępnia metodę wizualną, która umożliwia poznanie pojęć i zadań w tej dokumentacji.
Zapis wideo Czas Transkrypcja 00:00 W tym filmie wideo można zobaczyć, jak zbudować binarny model klasyfikacji, który ocenia prawdopodobieństwo, że klient firmy z zewnątrz kupi namiot. 00:11 W tym filmie wideo używany jest zestaw danych o nazwie "GoSales", który znajdziesz w galerii. 00:16 Wyświetl zestaw danych. 00:20 Kolumny opcji to: "GENDER", "AGE", "MARITAL_STATUS" i "ZAWODU" i zawierają atrybuty, dla których model uczenia maszynowego będzie przewidywać predykcje podstawowe. 00:31 Kolumny etykiet to "IS_TENT", "PRODUCT_LINE" i "PURCHASE_AMOUNT" i zawierają wyniki historyczne, które mogą zostać przeszkolone przez modele w celu przewidywania. 00:44 Dodaj ten zestaw danych do projektu "Machine Learning", a następnie przejdź do projektu. 00:56 Plik GoSales.csv z innymi zasobami danych znajduje się w pliku .csv. 01:02 Dodaj do projektu eksperyment "AutoAI ". 01:08 W tym projekcie jest już powiązana usługa Watson Machine Learning . 01:13 Jeśli jeszcze tego nie zrobiono, obejrzyj film pokazujący, jak uruchomić eksperyment AutoAI w oparciu o przykład. 01:22 Wystarczy podać nazwę dla eksperymentu, a następnie kliknąć przycisk "Utwórz". 01:30 Zostanie wyświetlony program budujący eksperymenty AutoAI . 01:33 Najpierw musisz załadować dane treningowe. 01:36 W takim przypadku zestaw danych będzie miał miejsce z projektu. 01:40 Wybierz z listy plik .csv GoSales. 01:45 AutoAI odczytuje zestaw danych i wyświetla listę kolumn znajdujących się w zestawie danych. 01:50 Ponieważ model ma przewidywać prawdopodobieństwo zakupu namiotu przez danego klienta, należy wybrać opcję "IS_TENT" jako kolumnę do przewidzenia. 01:59 Teraz edytuj ustawienia eksperymentu. 02:03 Najpierw należy spojrzeć na ustawienia źródła danych. 02:06 Jeśli istnieje duży zestaw danych, można uruchomić eksperyment na podpróbce wierszy, a także określić, ile danych będzie wykorzystywanych do szkolenia oraz ile będzie można ich użyć do oceny. 02:19 Domyślnie jest to podział na poziomie 90% /10%, gdzie 10% danych jest zarezerwowanych do oceny. 02:27 Można również wybrać kolumny z zestawu danych, które mają być uwzględniane podczas wykonywania eksperymentu. 02:35 W panelu "Predykcja" można wybrać typ predykcji. 02:39 W tym przypadku AutoAI przeanalizował dane i ustał, że kolumna "IS_TENT" zawiera prawdziwe informacje, które nadają się do modelu "klasyfikacji binarnej". 02:52 Klasa dodatnia ma wartość "PRAWDA", a rekomendowana metryka to "Dokładność". 03:01 Jeśli chcesz, możesz wybrać konkretne algorytmy do rozważenia dla tego eksperymentu oraz liczbę najlepszych algorytmów dla AutoAI do przetestowania, która określa liczbę wygenerowanych rurociągów. 03:16 Na panelu "Środowisko wykonawcze" można przejrzeć inne szczegóły dotyczące eksperymentu. 03:21 W tym przypadku akceptowanie ustawień domyślnych sprawia, że jest to najbardziej sensowne. 03:25 Teraz uruchom eksperyment. 03:28 AutoAI najpierw ładuje zestaw danych, a następnie rozprzestrzenia dane do danych uczących i danych holdout. 03:37 Następnie należy poczekać, jak "Pipeline leaderboard" wypełnia się, aby pokazać generowane rurociągi przy użyciu różnych estymatorów, takich jak klasyfikator XGBoost, lub udoskonalenia, takie jak optymalizacja hiperparametrów i inżynierii fabularnej, z rurociągami w rankingu na podstawie pomiaru dokładności. 03:58 Optymalizacja hiperparametrów to mechanizm automatycznego eksplorowania przestrzeni wyszukiwania dla potencjalnych hiperparametrów, budowania serii modeli i porównywania modeli z wykorzystaniem metryk zainteresowań. 04:10 Inżynieria składników próbuje transformować dane surowe w kombinację funkcji, które najlepiej odzwierciedlają problem, aby osiągnąć najdokładniejszą predykcję. 04:21 W porządku, bieg zakończył się. 04:24 Domyślnie zostanie wyświetlona "Mapa relacji". 04:28 Można jednak zamieniać widoki, aby zobaczyć "Mapę postępu". 04:32 Możesz chcieć zacząć od porównywania rurociągów. 04:36 Ten wykres udostępnia wielkości mierzone dla ośmiu rurociągów, które są przeglądane przez wynik walidacji krzyżowej lub wynik holdout. 04:46 Na podstawie innych wielkości mierzonych, takich jak średnia precyzja, można wyświetlić ranking potoków. 04:55 Na karcie "Podsumowanie eksperymentu" rozwiń potok, aby wyświetlić miary ewaluacji modelu i krzywą ROC. 05:03 Podczas szkolenia AutoAI zestaw danych jest podzielony na dwie części: dane treningowe i dane wyholowania. 05:11 Dane uczących są wykorzystywane przez etapy szkolenia AutoAI do generowania modeli rurociągów, a wyniki walidacji krzyżowej są wykorzystywane do ich oceny. 05:21 Po szkoleniu dane holdout są wykorzystywane do tworzenia wynikowego modelu rurociągu i obliczania informacji o wydajności, takich jak krzywe ROC i matryce pomieszania. 05:33 Można wyświetlić pojedynczy potok, aby wyświetlić więcej szczegółów oprócz macierzy pomieszania, krzywej przywracania dokładności, informacji o modelu i istotności dla funkcji. 05:46 Ten potok miał najwyższy ranking, dzięki czemu można zapisać go jako model uczenia maszynowego. 05:52 Wystarczy zaakceptować wartości domyślne i zapisać model. 05:56 Teraz, gdy model został przeszkolony, jesteś gotowy do wyświetlenia modelu i wdrożenia go. 06:04 Na karcie Przegląd wyświetlane jest podsumowanie modelu i schemat wejściowy. 06:09 Aby wdrożyć model, należy go awansować do miejsca wdrożenia. 06:15 Wybierz miejsce wdrożenia z listy, dodaj opis modelu i kliknij opcję "Awansuj". 06:24 Użyj odsyłacza, aby przejść do obszaru wdrażania. 06:28 Oto model, który właśnie został utworzony, który można teraz wdrożyć. 06:33 W tym przypadku będzie to wdrożenie on-line. 06:37 Wystarczy podać nazwę wdrożenia i kliknąć opcję "Utwórz". 06:41 Następnie należy poczekać, aż model zostanie wdrożony. 06:44 Po zakończeniu wdrażania modelu wyświetl wdrożenie. 06:49 Na karcie "Odwołanie do interfejsu API" można znaleźć punkt końcowy oceniania dla przyszłych odwołań. 06:56 Można również znaleźć fragmenty kodu dla różnych języków programowania, aby wykorzystać to wdrożenie z poziomu aplikacji. 07:05 Na karcie "Test" można przetestować predykcję modelu. 07:09 Można wprowadzić dane wejściowe testu lub wkleić dane wejściowe JSON, a następnie kliknąć przycisk "Predict". 07:20 To pokazuje, że istnieje bardzo duże prawdopodobieństwo, że pierwszy klient kupi namiot i bardzo duże prawdopodobieństwo, że drugi klient nie kupi namiotu. 07:33 Po powrocie do projektu można znaleźć eksperyment AutoAI oraz model na karcie "Zasoby". 07:44 Więcej filmów wideo można znaleźć w dokumentacji Cloud Pak for Data as a Service .
Przegląd zestawów danych
Przykładowe dane są ustrukturyzowane (w wierszach i kolumnach) i zapisywane w formacie pliku .csv.
Przykładowy plik danych można wyświetlić w edytorze tekstu lub arkuszu kalkulacyjnym:

Co chcesz przewidzieć?
Wybierz kolumnę, której wartości mają być predyktowane przez model.
W tym kursie model predyktuje wartości kolumny IS_TENT :
IS_TENT: Informacja o tym, czy klient kupił namiot
Model, który został zbudowany w tym kursie, przewiduje, czy klient może zakupić namiot.
Przegląd zadań
Ten kurs przedstawia podstawowe czynności związane z budowaniem i szkoleniem modelu uczenia maszynowego za pomocą programu AutoAI:
Czynność 1: tworzenie projektu
- Z poziomu Samples(Przykłady) pobierz plik zestawu danych GoSales na komputer lokalny.
- Na stronie Projekty, aby utworzyć nowy projekt, wybierz opcję Nowy projekt.
a. Wybierz opcję Utwórz pusty projekt.
b. Uwzględnij nazwę projektu.
c. Kliknij makro Create.
Czynność 2: tworzenie eksperymentu AutoAI
Na karcie Zasoby , z poziomu projektu, kliknij opcję Nowe zadanie > Buduj automatycznie modele uczenia maszynowego.
Podaj nazwę i opcjonalny opis nowego eksperymentu.
Wybierz odsyłacz Powiąż instancję usługi Machine Learning , aby powiązać instancję Watson Machine Learning Server z projektem. Kliknij przycisk Przeładuj , aby potwierdzić konfigurację.
Aby dodać źródło danych, można wybrać jedną z następujących opcji:
a. Jeśli plik został pobrany lokalnie, należy przesłać plik danych treningowych GoSales.csvz komputera lokalnego. Przeciągnij plik na panel danych lub kliknij przycisk Przeglądaj i postępuj zgodnie z instrukcjami.
b. Jeśli plik został już przesłany do projektu, kliknij opcję select from project(wybierz z projektu), a następnie wybierz kartę data asset (Zasób danych) i wybierz opcję GoSales.csv.
Zadanie 3: Szkolenie eksperymentu
W sekcji Szczegóły konfiguracjiwybierz opcję Nie , aby wybrać opcję utworzenia prognozy serii czasowej.
Wybierz
IS_TENTjako kolumnę do przewidzenia. Funkcja AutoAI analizuje dane i określa, że kolumnaIS_TENTzawiera informacje o wartości Prawda i Fałsz, dzięki czemu dane te są odpowiednie dla modelu klasyfikacji binarnej. Domyślna metryka dla klasyfikacji binarnej to ROC/AUC.
Kliknij opcję Uruchom eksperyment. Jako pociągi modelowe, infografika pokazuje proces budowy rurociągów.
Uwaga:Możliwe jest wyświetlenie nieznacznych różnic w wynikach w oparciu o platformę Cloud Pak for Data i wersję, której można użyć.

Listę algorytmów lub estymatorów dostępnych dla każdej techniki uczenia maszynowego w obszarze AutoAIzawiera sekcja Szczegóły implementacjiAutoAI.
Po utworzeniu wszystkich rurociągów można porównać ich dokładność na Potoku leaderboard.

Wybierz potok z rangą 1 i kliknij przycisk Zapisz jako , aby utworzyć model. Następnie wybierz opcję Utwórz. Ta opcja powoduje zapisanie potoku w sekcji Modele na karcie Zasoby aplikacyjne .
Czynność 4: wdrażanie wyszkolonego modelu
Model można wdrożyć na stronie szczegółów modelu. Dostęp do strony szczegółów modelu można uzyskać na jeden z następujących sposobów:
- Kliknięcie nazwy modelu w powiadomieniu wyświetlonym po zapisaniu modelu.
- Otwórz kartę Zasoby dla projektu, wybierz sekcję Modele i wybierz nazwę modelu.
Kliknij opcję Awansuj na miejsce wdrożenia , a następnie wybierz lub utwórz obszar, w którym zostanie wdrożony model.
- Aby utworzyć obszar wdrażania:
- Wprowadź nazwę.
- Powiąż ją z usługą Machine Learning .
- Wybierz opcję Utwórz.
- Aby utworzyć obszar wdrażania:
Po utworzeniu obszaru wdrażania lub wybraniu istniejącego obszaru wdrażania należy wybrać opcję Awansuj.
Kliknij odsyłacz obszaru wdrażania od powiadomienia.
Na karcie Zasoby w obszarze wdrażania:
- Umieść wskaźnik myszy nad nazwą modelu, a następnie kliknij ikonę wdrażania
 .
.- Na stronie, która zostanie otwarta, wypełniaj pola:
- Wybierz opcję Tryb z połączeniem jako Typ wdrożenia.
- Podaj nazwę wdrożenia.
- Kliknij makro Create.
- Na stronie, która zostanie otwarta, wypełniaj pola:
- Umieść wskaźnik myszy nad nazwą modelu, a następnie kliknij ikonę wdrażania
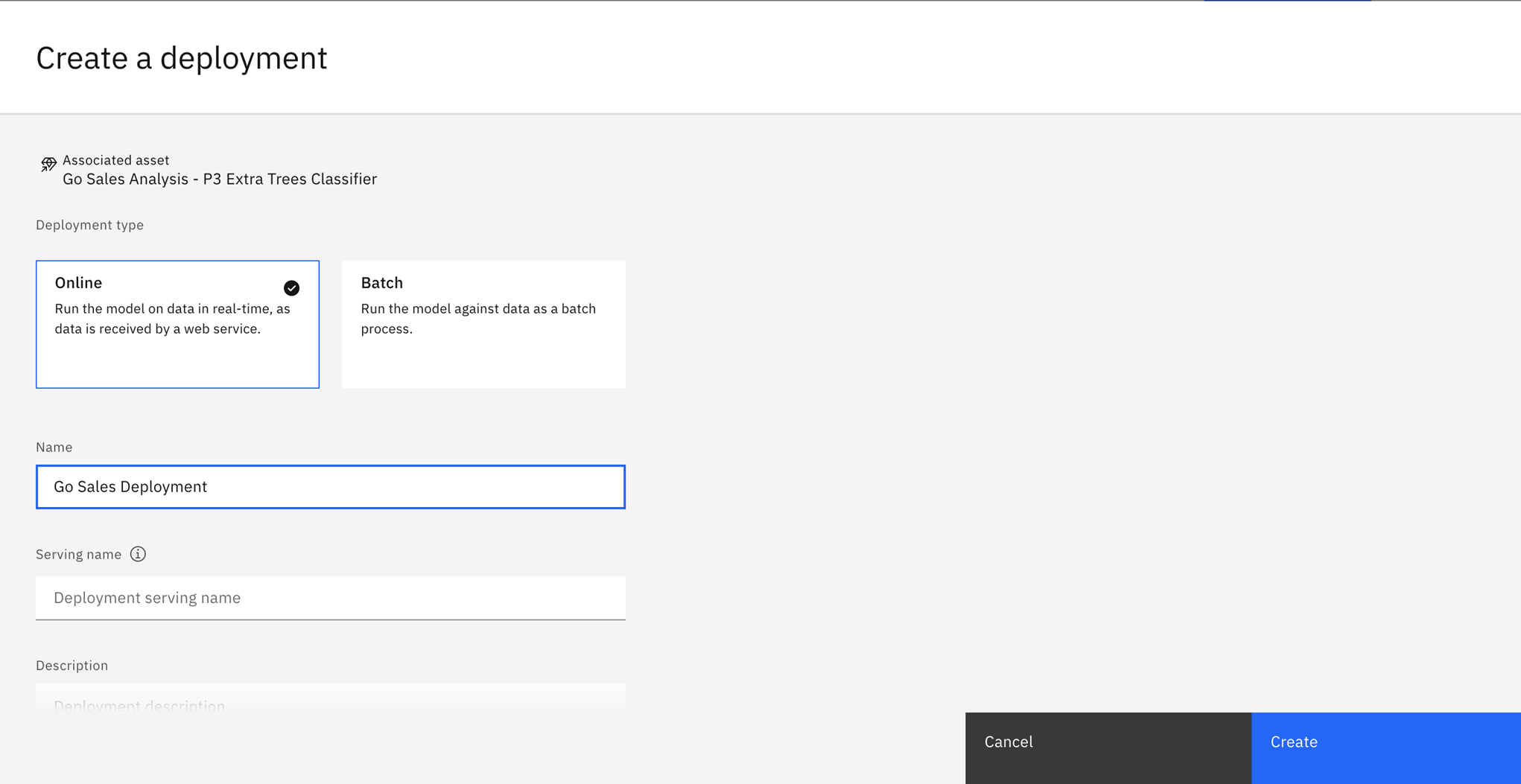
Po zakończeniu wdrażania kliknij opcję Deployments (Wdrożenia), a następnie wybierz nazwę wdrożenia, aby wyświetlić stronę szczegółów.
Czynność 5: testowanie wdrożonego modelu
Wdrożonego modelu można przetestować na stronie szczegółów wdrożenia:
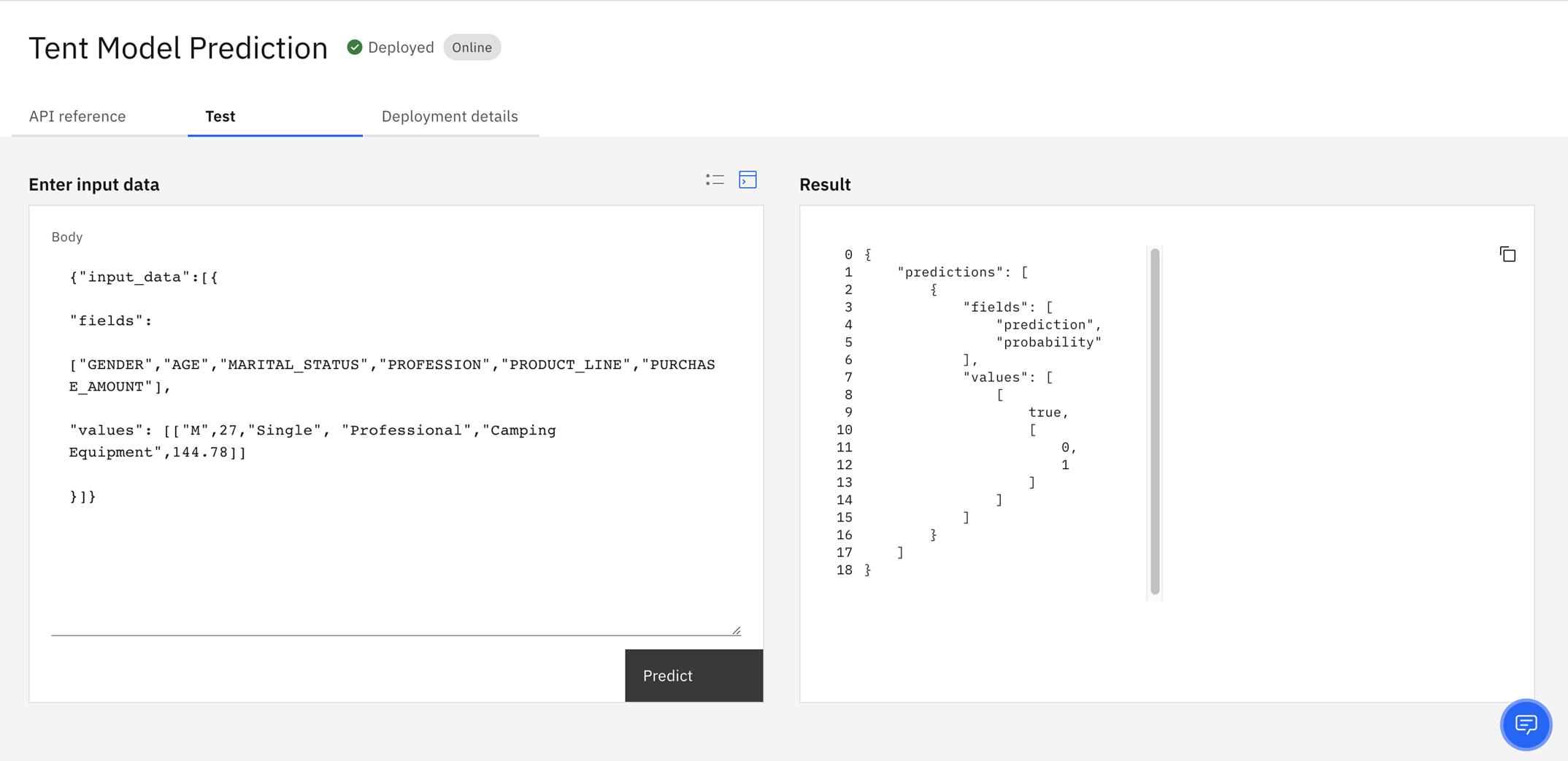
Na karcie Test na stronie szczegółów wdrożenia wypełniaj formularz z wartościami testowymi lub wprowadź dane testowe JSON, klikając ikonę terminalu
 , aby udostępnić następujące dane wejściowe JSON.
, aby udostępnić następujące dane wejściowe JSON.{"input_data":[{ "fields": ["GENDER","AGE","MARITAL_STATUS","PROFESSION","PRODUCT_LINE","PURCHASE_AMOUNT"], "values": [["M",27,"Single", "Professional","Camping Equipment",144.78]] }]}Uwaga: Dane testowe replikują pola danych dla modelu, z wyjątkiem pola predykcji.
Kliknij opcję Predykt , aby przewidzieć, czy klient z wprowadzonym atrybutami będzie prawdopodobnie kupował namiot. Wynikający z niego predykcja wskazuje, że klient z wprowadzonym atrybutami ma duże prawdopodobieństwo zakupu namiotu.
Czynność 6: Tworzenie zadania wsadowego w celu oceny modelu
W przypadku wdrożenia wsadowego należy podać dane wejściowe, zwane również ładunkiem modelu, w pliku CSV. Dane muszą być tak skonstruowane, jak dane treningowe, z tymi samymi nagłówkami kolumn. Zadanie wsadowe przetwarza każdy wiersz danych i tworzy odpowiednią predykcję.
W przypadku rzeczywistego scenariusza można wprowadzić nowe dane do modelu w celu uzyskania wyniku. Ten kurs korzysta jednak z tych samych danych uczących GoSales-updated.csv , które zostały pobrane w ramach konfiguracji kursu. Przed przesłaniem pliku do zadania wsadowego upewnij się, że kolumna IS_TENT została usunięta i zeskładowana. Podczas wdrażania modelu można dodać dane ładunku do projektu, przesłać go do obszaru lub utworzyć odsyłacz do niego w repozytorium pamięci masowej, takim jak zasobnik Cloud Object Storage . Na potrzeby tego kursu należy przesłać plik bezpośrednio do obszaru wdrażania.
Krok 1: Dodawanie danych do obszaru
Na stronie Zasoby w obszarze wdrażania:
- Kliknij opcję Dodaj do obszaru , a następnie wybierz opcję Dane.
- Prześlij plik GoSales-updated.csv , który został zapisany lokalnie.
Krok 2: Tworzenie wdrożenia wsadowego
Teraz można zdefiniować wdrożenie wsadowe.
- Kliknij ikonę wdrażania znajdującą się obok nazwy modelu.
- Wprowadź nazwę dla wdrożenia.
- Wybierz opcję Zadanie wsadowe jako Typ wdrożenia.
- Wybierz najmniejszą specyfikację sprzętu.
- Kliknij makro Create.
Krok 3: Tworzenie zadania wsadowego
Zadanie wsadowe uruchamia wdrożenie. Aby utworzyć zadanie, należy określić dane wejściowe i nazwę pliku wyjściowego. Zadanie można skonfigurować do uruchamiania w harmonogramie lub uruchamiane natychmiast.
- Kliknij opcję Nowa praca.
- Podaj nazwę zadania
- Konfiguracja do najmniejszej specyfikacji sprzętu
- (Opcjonalne): Aby ustawić harmonogram i otrzymywać powiadomienia.
- Prześlij plik wejściowy: GoSales-updated.csv
- Nazwij plik wyjściowy: GoSales-output.csv
- Przejrzyj i kliknij przycisk Utwórz , aby uruchomić zadanie.
Krok 4: wyświetlanie danych wyjściowych
Gdy status wdrożenia zmieni się na Wdrożony, wróć do strony Zasoby dla miejsca wdrożenia. Plik GoSales-output.csv został utworzony i dodany do listy zasobów użytkownika.
Kliknij ikonę pobierania znajdującą się obok pliku wyjściowego, a następnie otwórz plik w edytorze. Można przejrzeć wyniki predykcji dla informacji o kliencie, które są wprowadzane do przetwarzania wsadowego.
Dla każdego przypadku zwracana predykcja wskazuje na pewność siebie, czy klient kupi namiot.
Następne kroki
Temat nadrzędny: PrzeglądAutoAI