About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Last updated: Jan 12, 2024
AutoAI automatically prepares data, applies algorithms, and attempts to build model pipelines that are best suited for your data and use case. Learn how to evaluate the model pipelines so that you can save one as a model.
Reviewing experiment results
During AutoAI training, your data set is split to a training part and a hold-out part. The training part is used by the AutoAI training stages to generate the AutoAI model pipelines and cross-validation scores that are used to rank them. After AutoAI training, the hold-out part is used for the resulting pipeline model evaluation and computation of performance information such as ROC curves and confusion matrices, which are shown in the leaderboard. The training/hold-out split ratio is 90/10.
As the training progresses, you are presented with a dynamic infographic and leaderboard. Hover over nodes in the infographic to explore the factors that pipelines share and their unique properties. For a guide to the data in the infographic, click the Legend tab in the information panel. Or, to see a different view of the pipeline creation, click the Experiment details tab of the notification panel, then click Switch views to view the progress map. In either view, click a pipeline node to view the associated pipeline in the leaderboard. The leaderboard contains model pipelines that are ranked by cross-validation scores.
View the pipeline transformations
Hover over a node in the infographic to view the transformations for a pipeline. The sequence of data transformations consists of a pre-processing transformer and a sequence of data transformers, if feature engineering was performed for the pipeline. The algorithm is determined by model selection and optimization steps during AutoAI training.

See Implementation details to review the technical details for creating the pipelines.
View the leaderboard
Each model pipeline is scored for various metrics and then ranked. The default ranking metric for binary classification models is the area under the ROC curve. For multi-class classification models the default metric is accuracy. For regression models, the default metric is the root mean-squared error (RMSE). The highest-ranked pipelines display in a leaderboard, so you can view more information about them. The leaderboard also provides the option to save select model pipelines after you review them.

You can evaluate the pipelines as follows:
- Click a pipeline in the leaderboard to view more detail about the metrics and performance.
- Click Compare to view how the top pipelines compare.
- Sort the leaderboard by a different metric.

Viewing the confusion matrix
One of the details you can view for a pipeline for a binary classification experiment is a Confusion matrix.
The confusion matrix is based on the holdout data, which is the portion of the training dataset that is not used for training the model pipeline but only used to measure its performance on data that was not seen during training.
In a binary classification problem with a positive class and a negative class, the confusion matrix summarizes the pipeline model’s positive and negative predictions in four quadrants depending on their correctness regarding the positive or negative class labels of the holdout data set.
For example, the Bank sample experiment seeks to identify customers that take promotions that are offered to them. The confusion matrix for the top-ranked pipeline is:
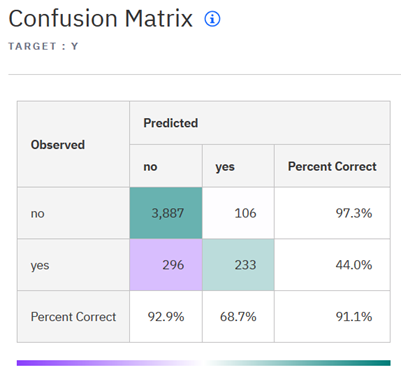
The positive class is ‘yes’ (meaning a user takes the promotion). You can see that the measurement of true negatives, that is, customers the model predicted correctly they would refuse their promotions, is high.
Click the items in the navigation menu to view other details about the selected pipeline. For example, Feature importance shows which data features contribute most to your prediction output.
Save a pipeline as a model
When you are satisfied with a pipeline, save it using one of these methods:
- Click Save model to save the candidate pipeline as a model to your project so you can test and deploy it.
- Click Save as notebook to create and save an auto-generated notebook to your project. You can review the code or run the experiment in the notebook.
Next steps
Promote the trained model to a deployment space so that you can test it with new data and generate predictions.
Learn more
Parent topic: AutoAI overview