Utilizzare i dati di esempio per addestrare un esperimento di serie temporali multivariate che prevede il tasso di inquinamento e la temperatura con l'aiuto di funzioni di supporto che influenzano i campi di previsione.
Quando si imposta l'esperimento, si caricano i dati di esempio che tracciano le condizioni meteorologiche a Pechino dal 2010 al 2014. L'esperimento genera una serie di condutture che utilizzano algoritmi per prevedere l'inquinamento e la temperatura futuri con caratteristiche di supporto, tra cui rugiada, pressione, neve e pioggia. Dopo aver generato le pipeline, AutoAI le confronta e le verifica, sceglie le migliori prestazioni e le presenta in una classifica da esaminare.
Panoramica del dataset
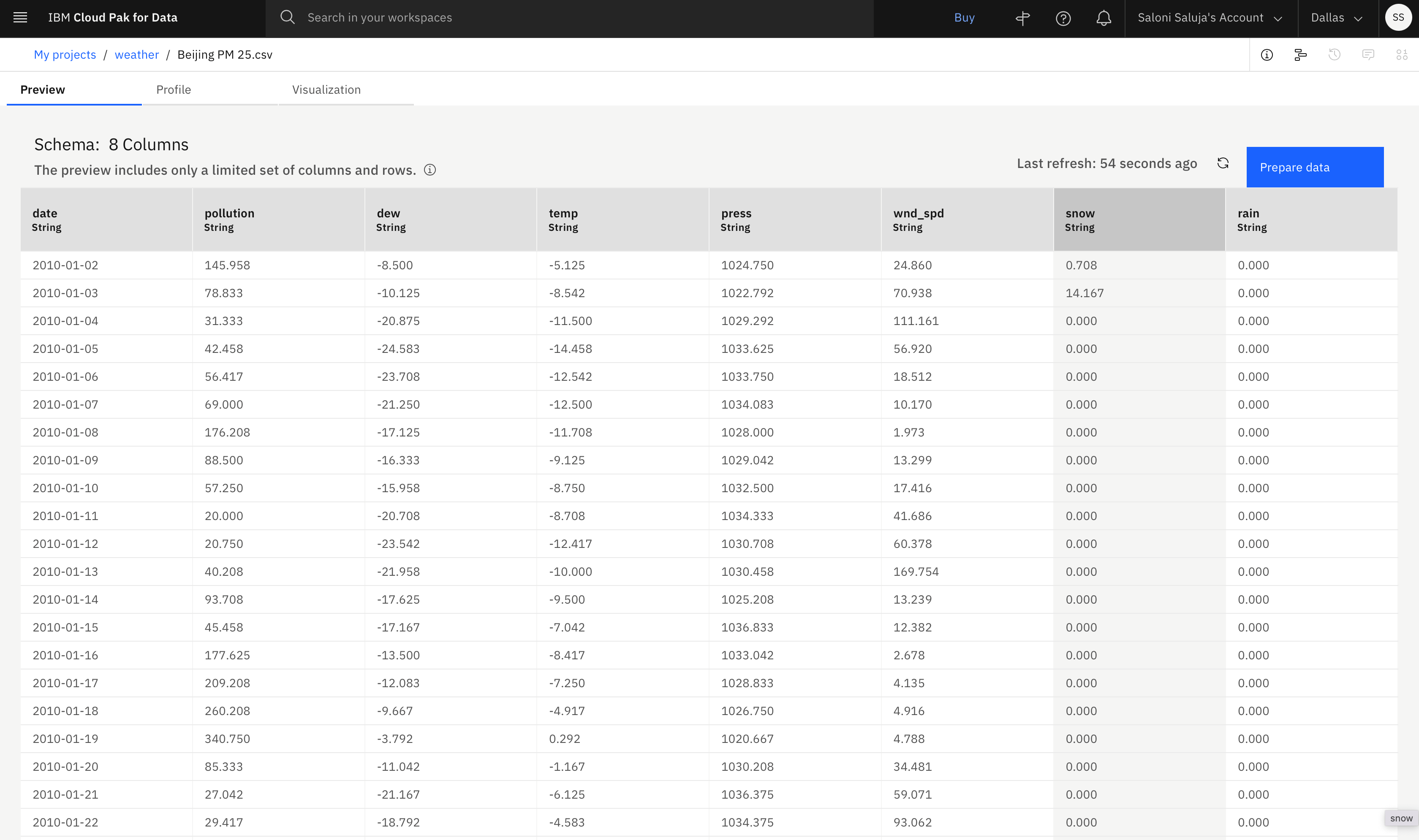
Per questa esercitazione, si utilizza il set di dati Beijing PM 2.5 dall'hub delle risorse. Questo dataset descrive le condizioni meteo a Pechino dal 2010 al 2014, misurate in passi o incrementi di 1 giorno. Utilizzare questo dataset per configurare l'esperimento AutoAI e selezionare le funzioni di supporto. I dettagli sul dataset sono descritti di seguito:
- Ogni colonna, diversa dalla colonna data, rappresenta una condizione meteorologica che influisce sull'indice di inquinamento.
- La voce Risorsa hub mostra l'origine dei dati. È possibile visualizzare l'anteprima del file prima di scaricarlo.
- I dati di esempio sono strutturati in righe e colonne e salvati come file .csv.
Panoramica delle attività
In questa esercitazione, si seguono i passaggi per creare un esperimento di serie temporali multivariate che utilizza le funzioni di supporto:
Crea un progetto
Seguite questi passaggi per creare un progetto vuoto e scaricare il set di dati Beijing PM 2.5 dall'hub delle risorse IBM watsonx:
- Dal riquadro di navigazione principale, fare clic su Progetti > Visualizza tutti i progetti, quindi fare clic su Nuovo progetto.
a. Fare clic su Crea un progetto vuoto.
b. Immettere un nome e una descrizione facoltativa per il progetto.
c. Fare clic su Crea. - Dal pannello di navigazione principale, fare clic su Resource hub e scaricare una copia locale del set di dati PM 2.5 di Pechino.
Crea un esperimento AutoAI
Seguire questa procedura per creare un esperimento AutoAI e aggiungere dati di esempio all'esperimento:
Nella scheda Asset dall'interno del progetto, fare clic su Nuovo asset> Crea modelli di machine learning automaticamente.
Specificare un nome e una descrizione facoltativa per l'esperimento.
Associare un'istanza del servizio di machine learning al tuo esperimento.
Scegli una definizione di ambiente di 8 vCPU e 32 GB di RAM.
Fare clic su Crea.
Per aggiungere dati di esempio, scegliere uno dei seguenti metodi:
- Se hai scaricato il tuo file localmente, carica il file dei dati di training, PM25.csv facendo clic su Sfoglia e seguendo le richieste.
- Se hai già caricato il tuo file nel progetto, fai clic su Select from project, quindi seleziona la scheda Data asset e scegli Beijing PM 25.csv.
Configurare l'esperimento
Attenersi alla seguente procedura per configurare l'esperimento di serie temporale AutoAI multivariato:
Fare clic su Sì per creare una previsione di serie temporali.
Scegliere come colonne di previsione:
pollution,temp.Scegliere come colonna data/ora:
date.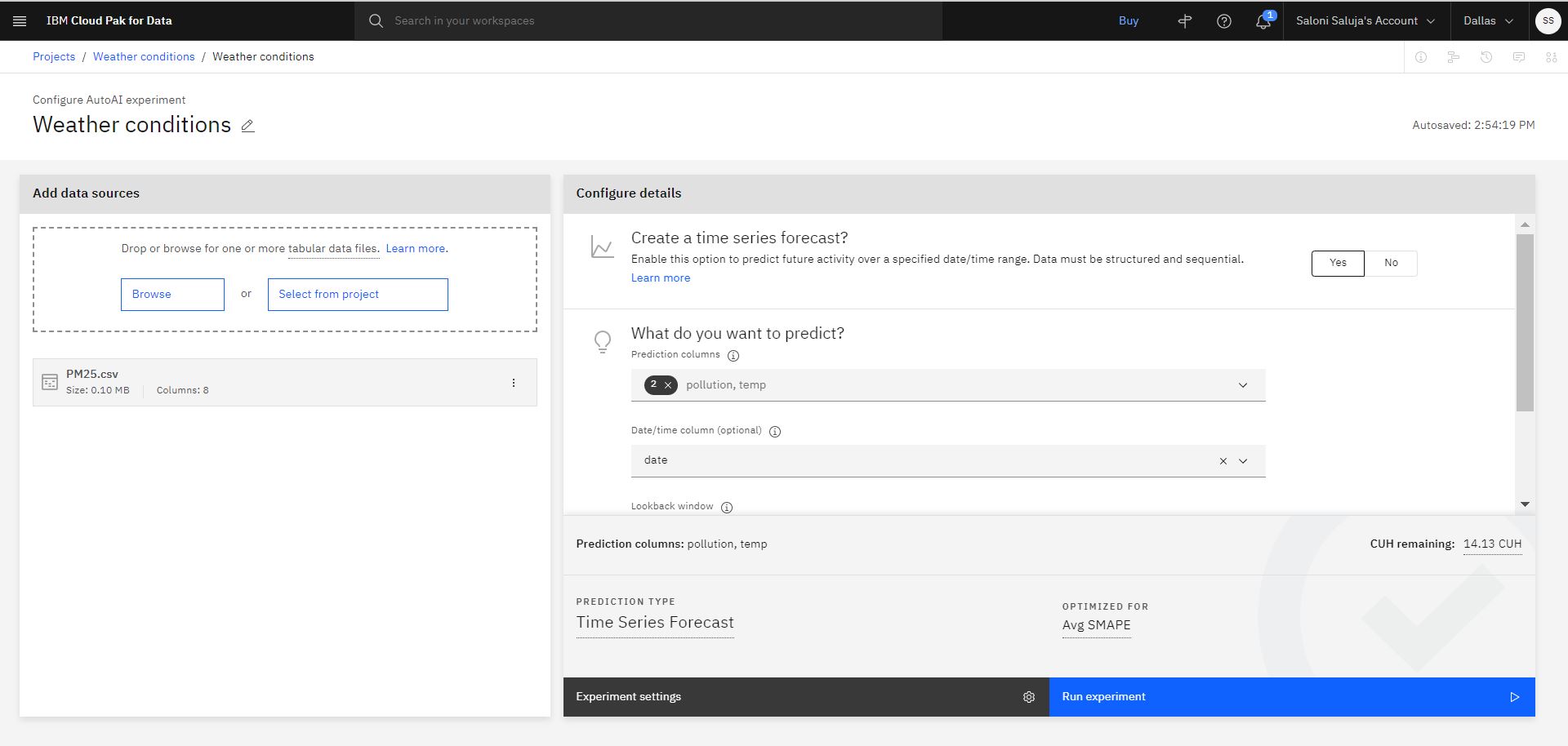
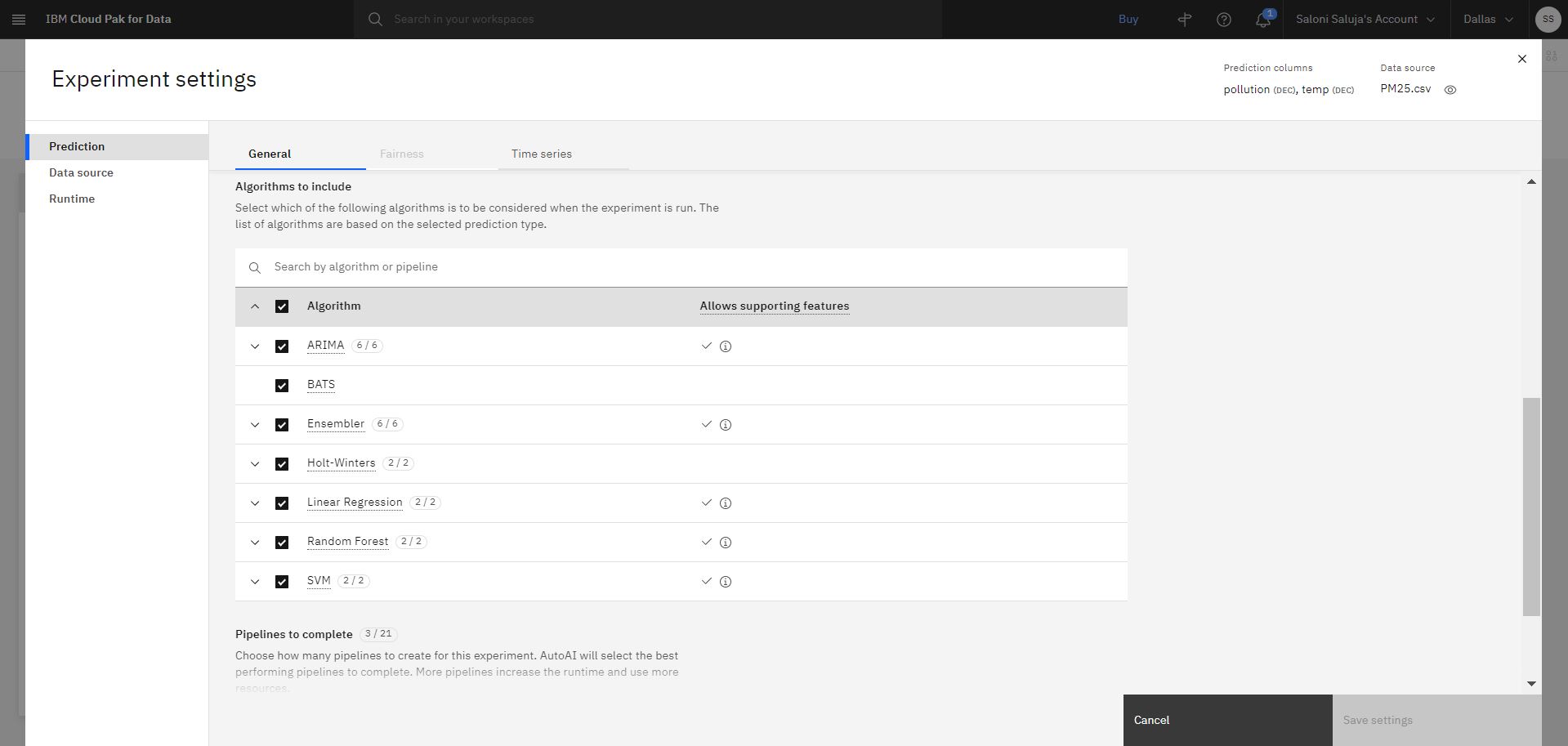
Fare clic su Impostazioni esperimento per configurare l'esperimento:
a. Nella pagina Previsione , accettare la selezione predefinita per gli algoritmi da includere. Gli algoritmi che consentono di utilizzare le funzioni di supporto sono indicati da un segno di spunta nella colonna Consente funzioni di supporto.
' '
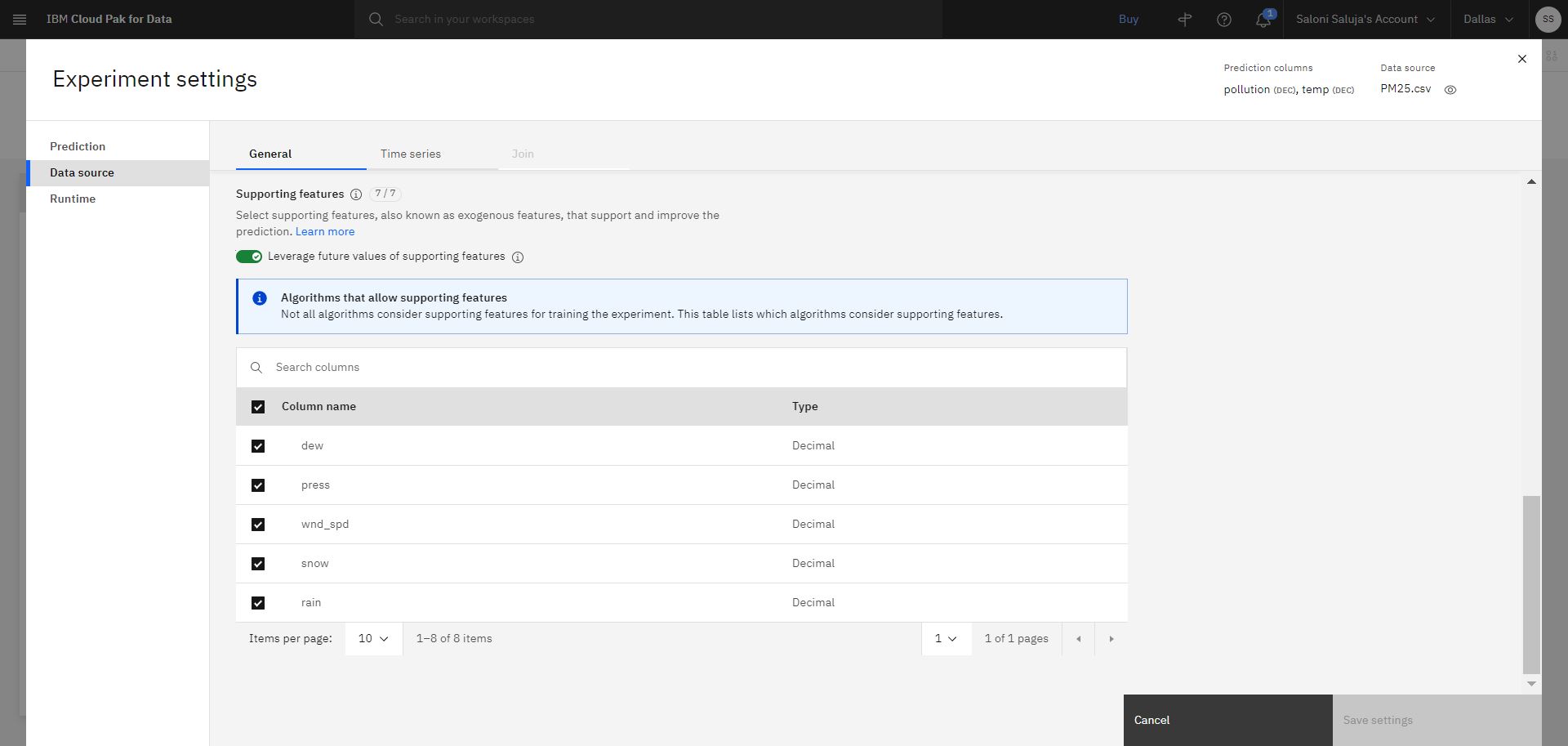
'b. Passare alla pagina Origine dati . Per questa esercitazione, verranno forniti i valori futuri delle funzioni di supporto durante il test. I valori futuri sono utili quando i valori per le funzioni di supporto sono noti per l'orizzonte di previsione. Accettare l'abilitazione predefinita per Utilizzare i valori futuri delle funzioni di supporto. Inoltre, accettare la selezione predefinita per le colonne che verranno utilizzate come caratteristiche di supporto.
'
c. Fare clic su Annulla per uscire dalle impostazioni dell'esperimento.Fare clic su Esegui esperimento per iniziare l'addestramento.
Esamina i risultati dell'esperimento
L'esperimento richiede diversi minuti per essere completato. Mentre l'esperimento si allena, la mappa delle relazioni mostra le trasformazioni utilizzate per la creazione delle pipeline. Seguire questa procedura per esaminare i risultati dell'esperimento e salvare la pipeline con le migliori prestazioni.
Facoltativo: passare con il mouse su qualsiasi nodo nella mappa della relazione per ottenere i dettagli sulla trasformazione per una particolare pipeline.
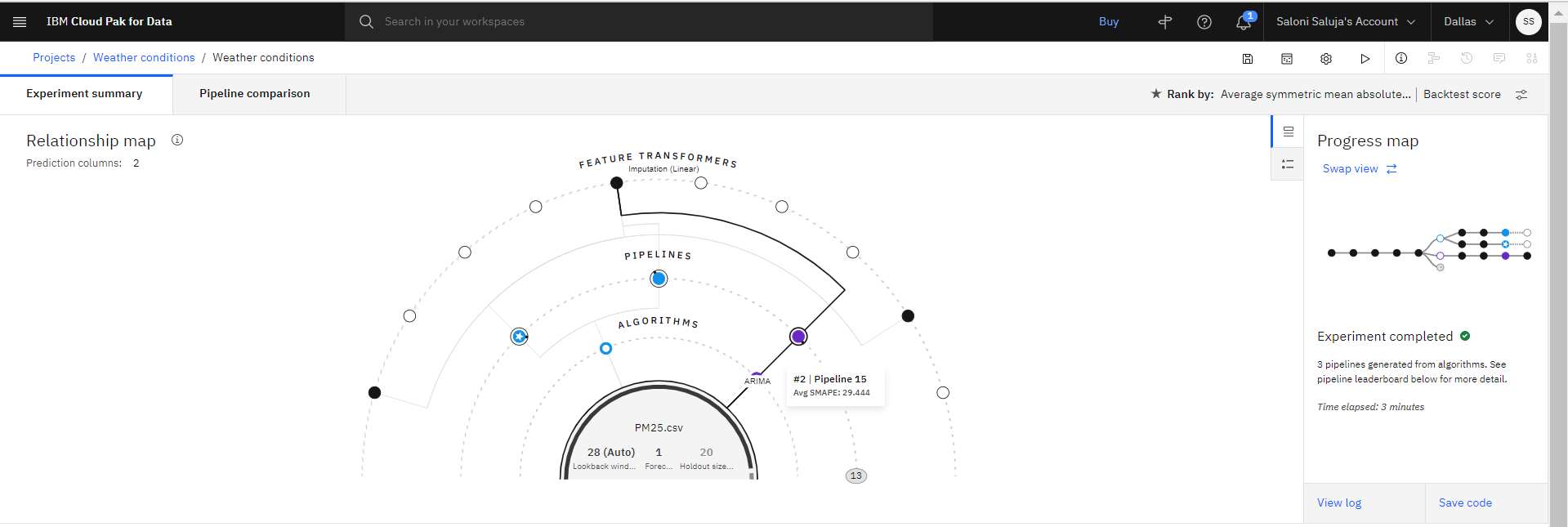
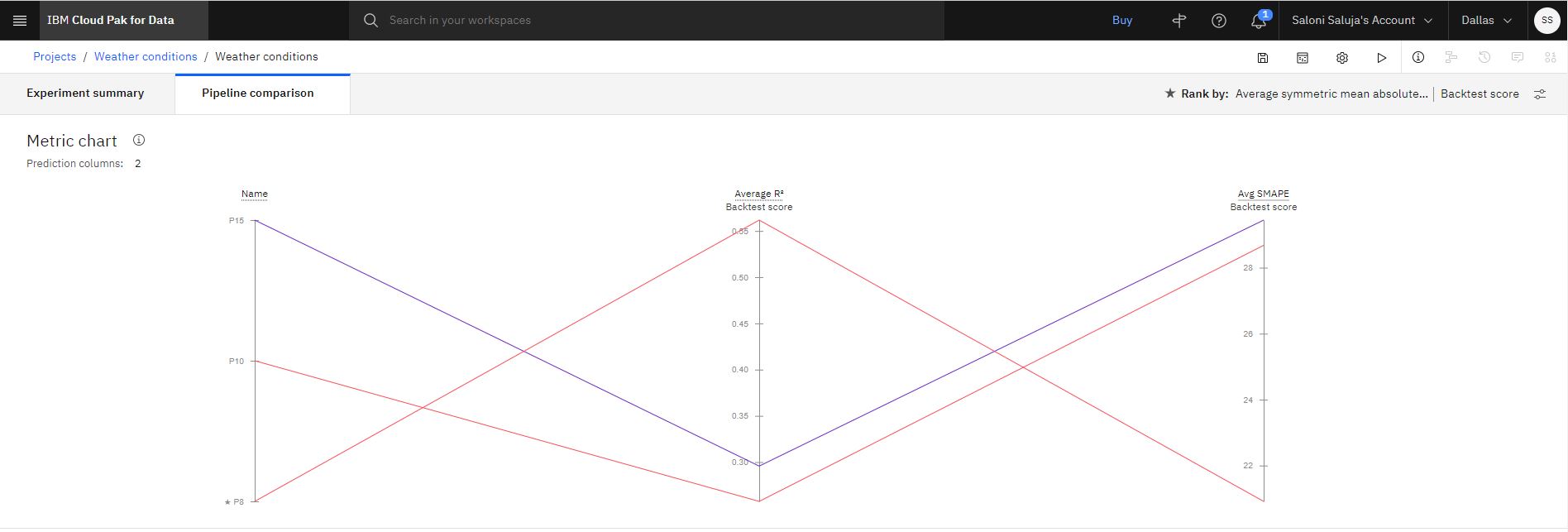
Facoltativo: dopo che le pipeline sono elencate nella classifica, fai clic su Confronto pipeline per vedere come differiscono. Ad esempio:
Una volta completata la formazione, le prime tre pipeline con le prestazioni migliori vengono salvate nella classifica. Fare clic sul nome di una pipeline per esaminare i dettagli.
Nota: le pipeline che utilizzano funzioni di supporto sono indicate dal miglioramento **SUP* *.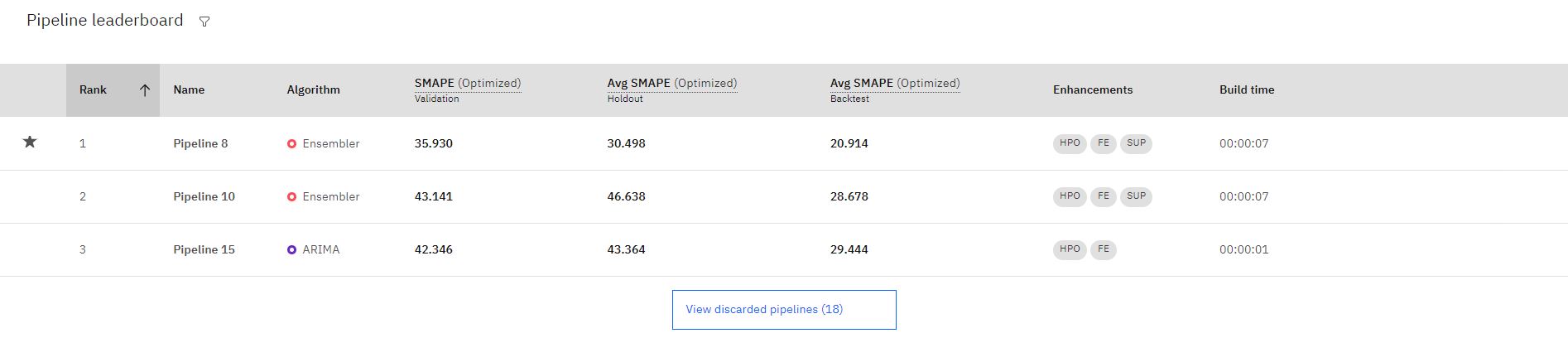
Seleziona la pipeline con la classificazione 1 e fai clic su Salva come per creare il tuo modello. Quindi, fare clic su Crea. Questa azione salva la pipeline nella sezione Modelli nella scheda Asset .
Distribuisci il modello sottoposto a training
Prima di poter utilizzare un modello addestrato per effettuare previsioni sui nuovi dati, è necessario distribuire il modello. Attieniti alla seguente procedura per promuovere il tuo modello preparato a uno spazio di distribuzione:
- È possibile distribuire il modello dalla pagina Dettagli modello . Per accedere alla pagina Dettagli modello , scegliere una delle seguenti opzioni:
- Fare clic sul nome del modello nella notifica visualizzata quando si salva il modello.
- Aprire la pagina Asset per il progetto che contiene il modello e fare clic sul nome del modello nella sezione Machine Learning Modello .
- Fare clic sull'icona Promuovi nello spazio di distribuzione '
 , quindi selezionare o creare uno spazio di distribuzione in cui verrà distribuito il modello.
, quindi selezionare o creare uno spazio di distribuzione in cui verrà distribuito il modello.
Facoltativo: segui questa procedura per creare un spazio di distribuzione:
a. Dall'elenco Spazio di destinazione, selezionare Crea un nuovo spazio di distribuzione.
b. Immettere un nome per il proprio spazio di distribuzione.
c. Per associare un'istanza di machine learning, vai a Select machine learning service (facoltativo) e seleziona un'istanza di machine learning dall'elenco.
g. Fare clic su Crea
. - Una volta selezionato o creato lo spazio, fare clic su Promuovi.
- Fare clic sul link dello spazio di distribuzione dalla notifica.
- Dalla scheda Asset dello spazio di distribuzione:
a. Passare il mouse sul nome del modello e fare clic sull'icona di distribuzione ' .
.
b. Nella pagina che si apre, completare i campi:
- Selezionare In linea come tipo di distribuzione.
- Specificare un nome per la distribuzione.
- Fare clic su Crea.
Una volta completata la distribuzione, fare clic sul separatore Distribuzioni e selezionare il nome della distribuzione per visualizzare la pagina dei dettagli.
Verifica il modello distribuito
Seguire questa procedura per verificare il modello distribuito dalla pagina dei dettagli di distribuzione:
Nella scheda Test della pagina dei dettagli di distribuzione, andare al foglio di calcolo Nuove osservazioni (facoltative) e immettere i seguenti valori:
inquinamento (doppio):80.417
temp (doppio):-5.5
rugiada (doppia):-7.083
premere (doppia):1020.667
wnd_spd (doppia):9.518
snow (doppia):0
pioggia (doppia):0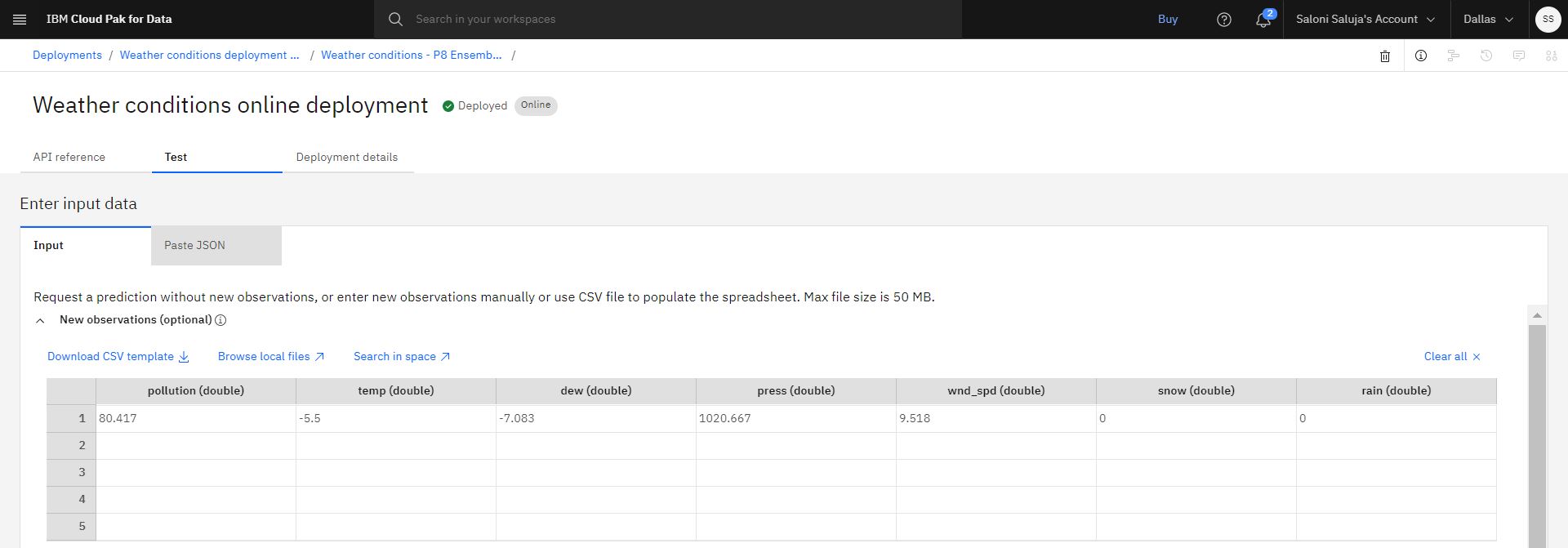
Per aggiungere i valori futuri delle funzioni di supporto, andare al foglio di calcolo Funzioni esogene future (facoltative) e immettere i seguenti valori:
dew (double):-12.667
press (double):1023.708
wnd_spd (double):9.518
snow (double):0
rain (double):0.042Nota: è necessario fornire lo stesso numero di valori per le funzioni esogene future dell'orizzonte di previsione impostato durante la fase di configurazione dell'esperimento.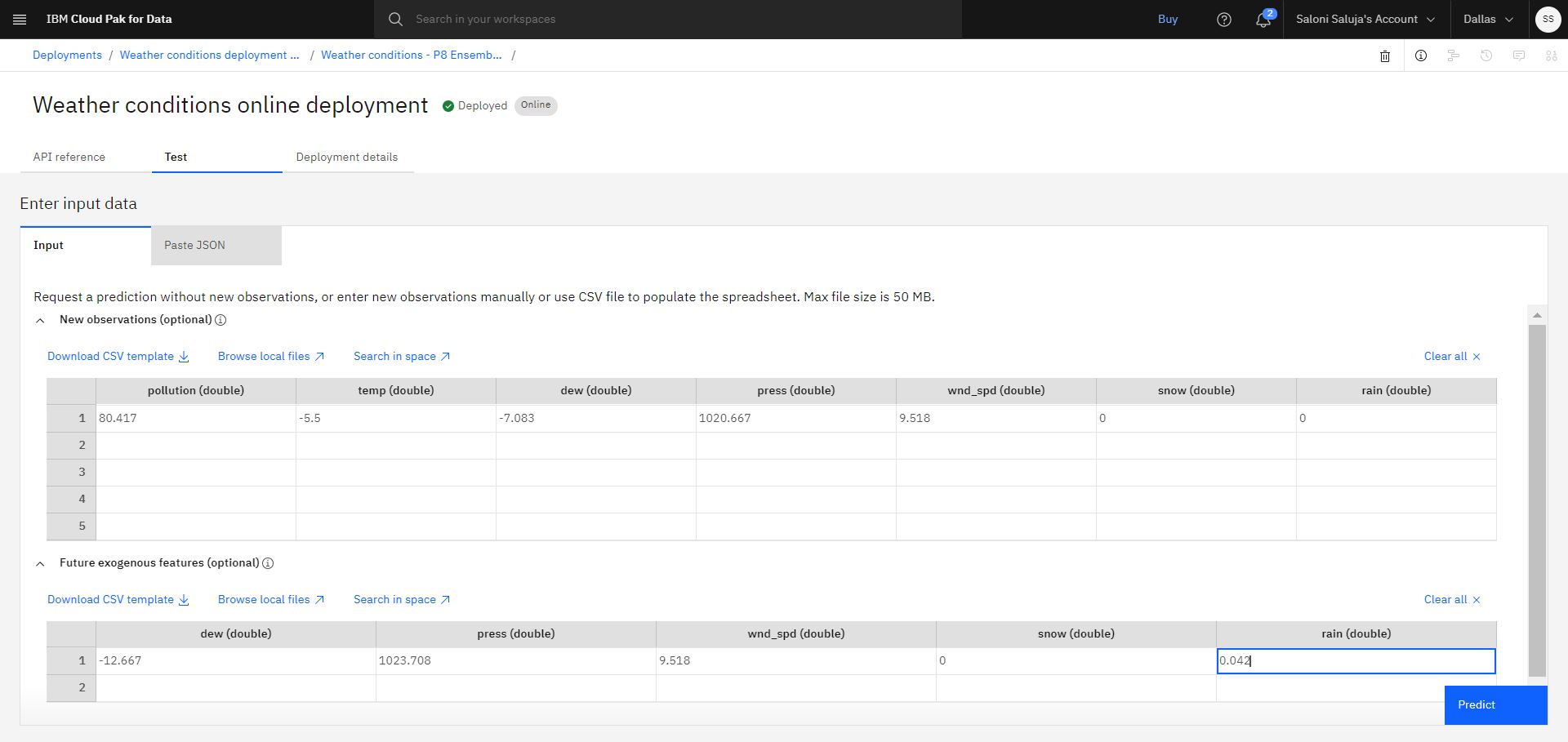
Fare clic su Previsione. La previsione risultante indica i valori di inquinamento e temperatura.
Nota: i valori di previsione mostrati nell'output potrebbero essere diversi quando si verifica la distribuzione.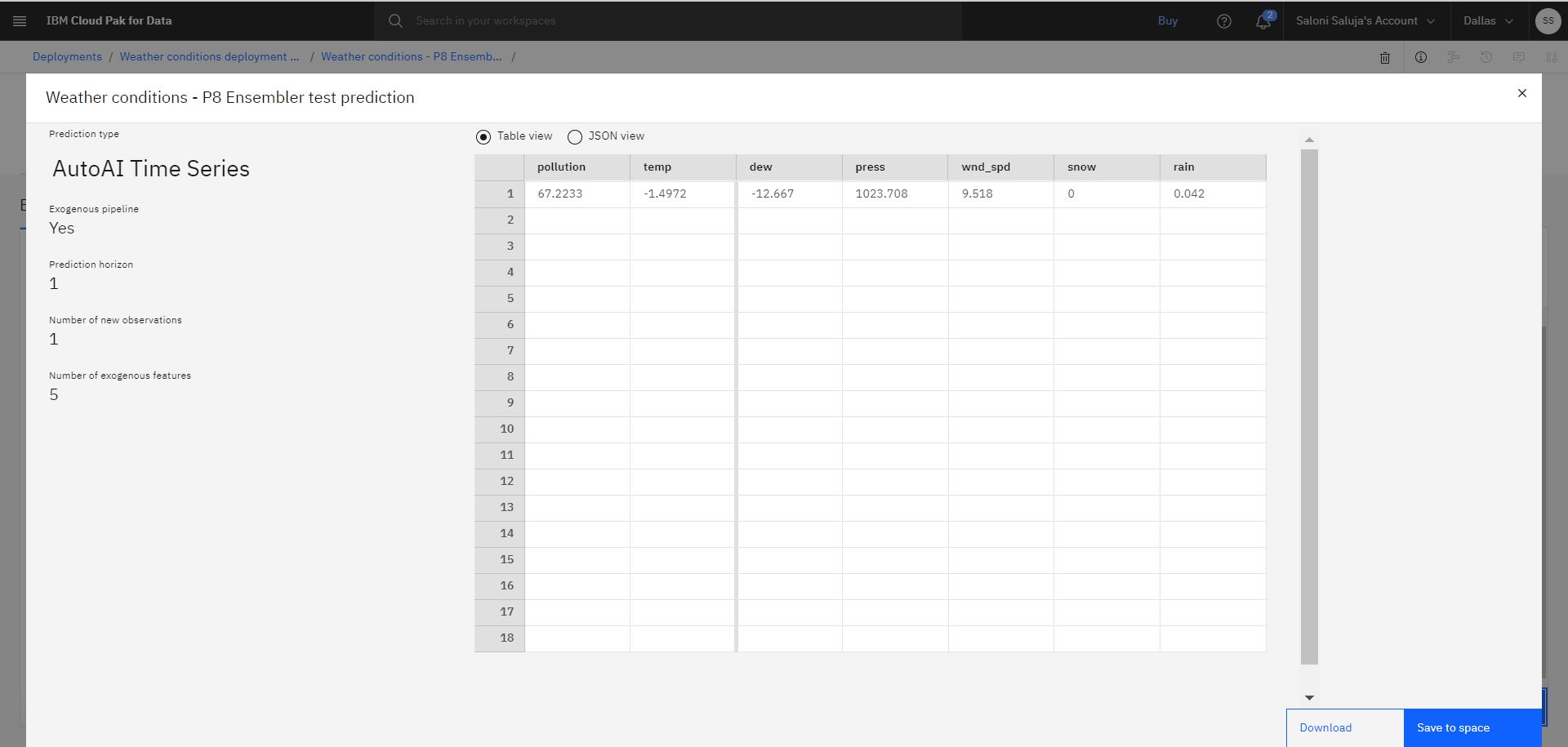
Ulteriori informazioni
Argomento principale: Costruire un esperimento sulle serie temporali