Translation not up to date
Użyj przykładowych danych, aby potrenować wielozmienny eksperyment szeregów czasowych, który przewiduje współczynnik zanieczyszczeń i temperaturę przy pomocy funkcji wspomagających, które wpływają na zmienne predykcyjne.
Podczas konfigurowania eksperymentu ładujesz przykładowe dane, które śledzią warunki pogodowe w Pekinie od 2010 do 2014 roku. Eksperyment generuje zestaw rurociągów, które wykorzystują algorytmy do przewidywania przyszłych zanieczyszczeń i temperatury przy pomocy cech wspomagających, w tym rosy, ciśnienia, śniegu i deszczu. Po wygenerowaniu rurociągów, AutoAI porównuje je i testuje, wybiera najlepszych wykonawców i prezentuje je w tablicy liderów, aby można było je przejrzeć.
Zanim rozpoczniesz
Upewnij się, że dostępne są następujące usługi:
- Usługa Watson Studio
- Usługa Watson Machine Learning
Przegląd zestawu danych
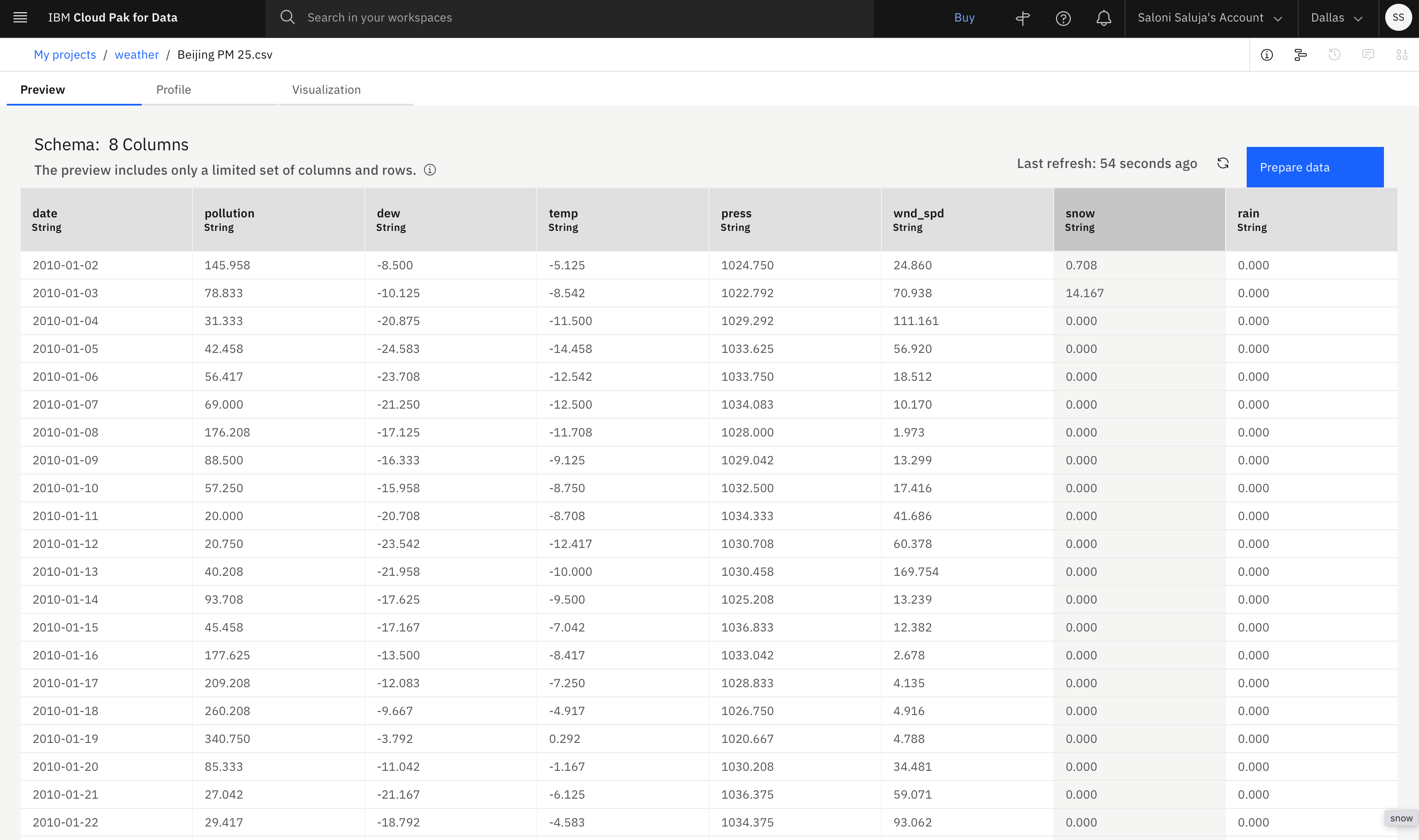
Na potrzeby tego kursu użytkownik korzysta z zestawu danych Beijing PM 2.5 z galerii. Ten zestaw danych opisuje warunki pogodowe w Pekinie od 2010 do 2014, które są mierzone w krokach co 1 dzień, lub przyrostu. Ten zestaw danych służy do konfigurowania eksperymentu AutoAI i wybierania opcji obsługi. Szczegółowe informacje na temat zestawu danych są opisane tutaj:
- Każda kolumna, inna niż kolumna daty, reprezentuje warunek pogodowy, który wpływa na indeks zanieczyszczenia.
- Pozycja Galeria zawiera informacje o pochodzeniu danych. Podgląd pliku można wyświetlić przed pobraniem pliku.
- Przykładowe dane są ustrukturyzowane w wierszach i kolumnach i zapisywane w postaci pliku .csv.
Przegląd zadań
W tym kursie należy wykonać kroki w celu utworzenia wielozmiennego eksperymentu szeregów czasowych, który korzysta z funkcji obsługi:
Tworzenie projektu
Aby utworzyć pusty projekt i pobrać zestaw danych Beijing PM 2.5 z galerii Cloud Pak for Data as a Service , należy wykonać następujące kroki:
- W głównym panelu nawigacyjnym kliknij opcję Projekty > Wyświetl wszystkie projekty, a następnie kliknij opcję Nowy projekt.
a. Kliknij opcję Utwórz pusty projekt.
b. Wprowadź nazwę i opcjonalny opis projektu.
c. Kliknij makro Create. - Na głównym panelu nawigacyjnym kliknij opcję Galeria , a następnie pobierz lokalną kopię zestawu danych Pekin PM 2.5 .
Tworzenie eksperymentu AutoAI
Aby utworzyć eksperyment AutoAI i dodać przykładowe dane do eksperymentu, wykonaj następujące kroki:
Na karcie Zasoby , z poziomu projektu, kliknij opcję Nowy zasób > AutoAI.
Podaj nazwę i opcjonalny opis eksperymentu.
Powiąż instancję usługi uczenia maszynowego z eksperymentem.
Wybierz definicję środowiska o wielkości 8 vCPU i 32 GB pamięci RAM.
Kliknij makro Create.
Aby dodać przykładowe dane, wybierz jedną z następujących metod:
- Jeśli plik został pobrany lokalnie, należy przesłać plik danych uczących PM25.csv , klikając przycisk Przeglądaj , a następnie podążając za zachętą.
- Jeśli plik został już przesłany do projektu, kliknij opcję Wybierz z projektu, a następnie wybierz kartę Zasób danych i wybierz opcję Beijing PM 25.csv.
Konfiguruj eksperyment
Aby skonfigurować wielozmienny eksperyment szeregów czasowych AutoAI , należy wykonać następujące czynności:
Kliknij przycisk Tak , aby wybrać opcję utworzenia prognozy szeregów czasowych.
Wybierz jako kolumny predykcji:
pollution,temp.Wybierz kolumnę daty/godziny:
date.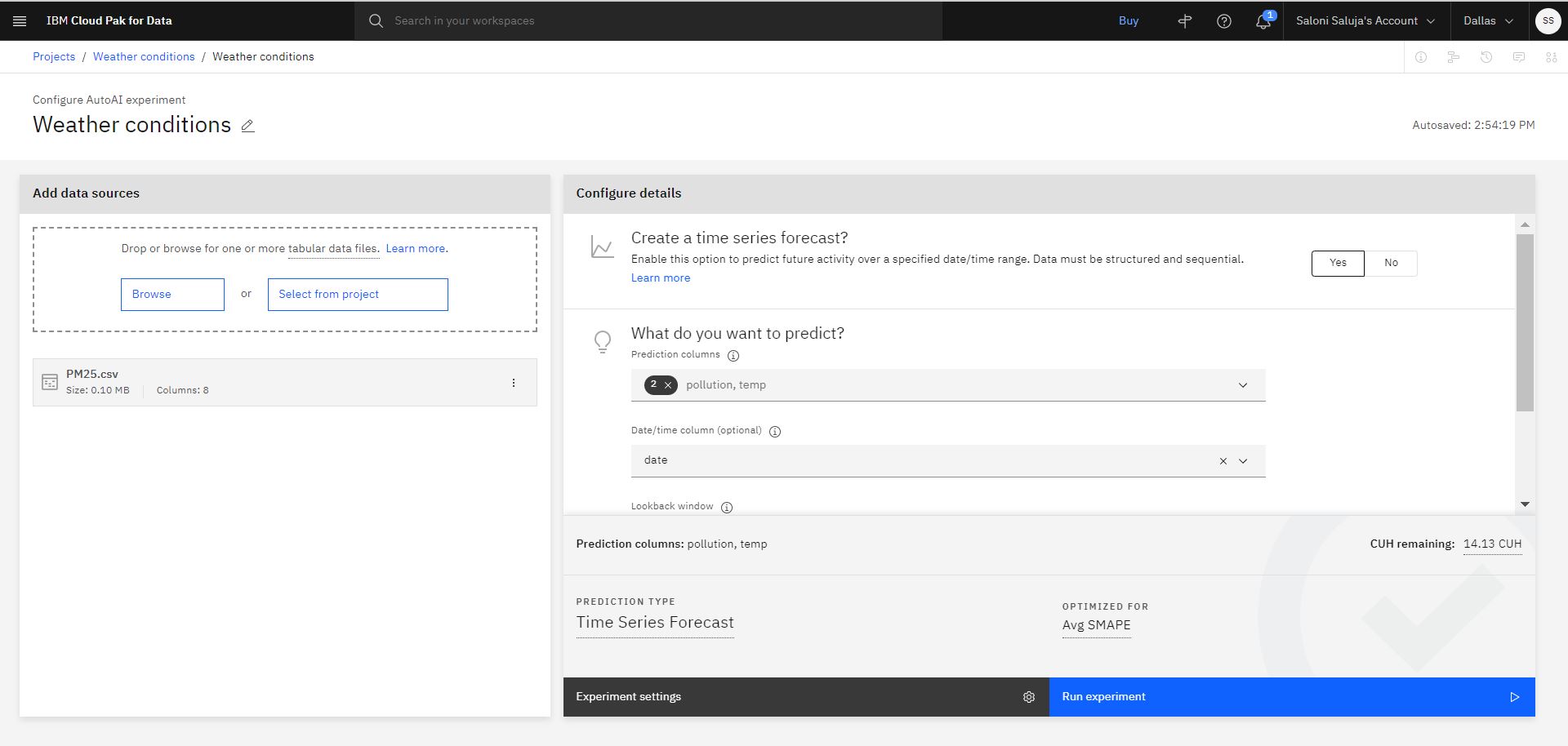
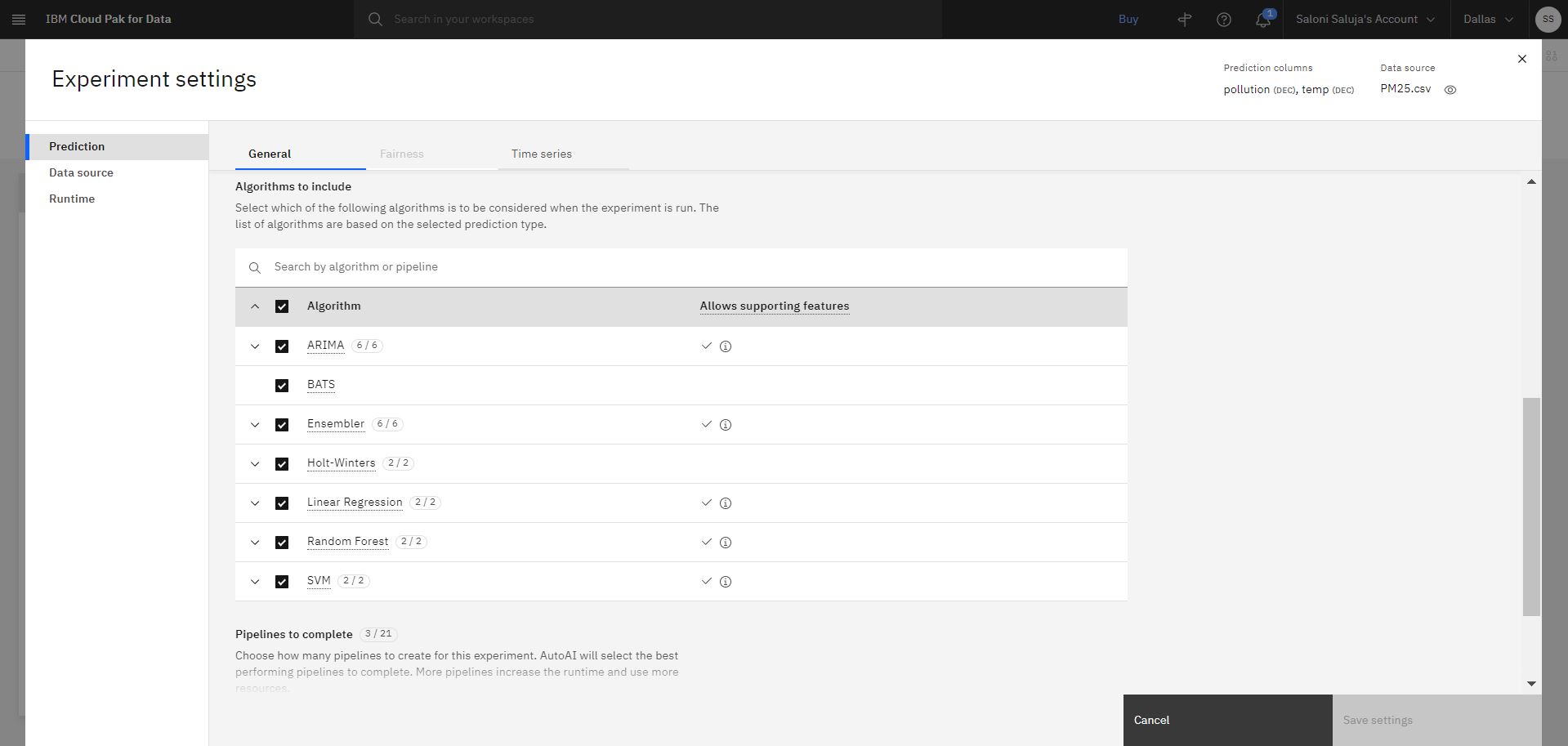
Kliknij opcję Ustawienia eksperymentu , aby skonfigurować eksperyment:
a. Na stronie Predykcja zaakceptuj domyślny wybór dla algorytmów, które mają być uwzględnione. Algorytmy, które umożliwiają korzystanie z funkcji obsługi, są oznaczone znacznikiem wyboru w kolumnie Pozwala na obsługę funkcji.
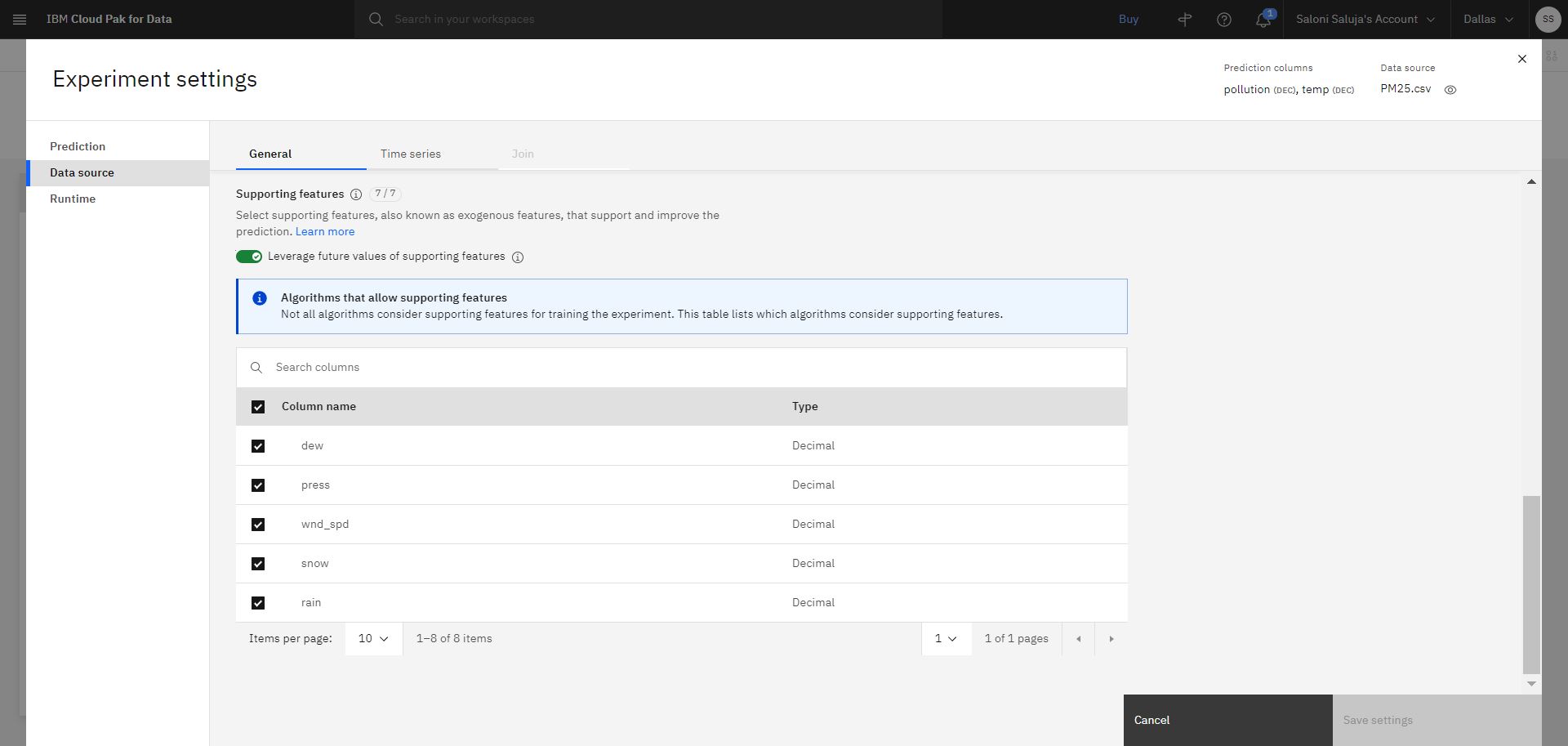
b. Przejdź do strony Źródło danych . W tym kursie zostaną podane przyszłe wartości funkcji obsługi podczas testowania. Przyszłe wartości są przydatne, gdy wartości dla funkcji pomocniczych są dopuszczalne dla horyzontu predykcji. Zaakceptuj domyślne włączenie opcji Leverage future values of supporting features(Wynajmij przyszłe wartości opcji obsługi). Dodatkowo zaakceptuj domyślny wybór dla kolumn, które będą używane jako funkcje pomocnicze.
c. Kliknij przycisk Anuluj , aby wyjść z ustawień Eksperyment.Kliknij opcję Uruchom eksperyment , aby rozpocząć szkolenie.
Przejrzyj wyniki eksperymentu
Wykonanie eksperymentu trwa kilka minut. Jako pociągi eksperymentu mapa relacji przedstawia transformacje, które są używane do tworzenia rurociągów. Wykonaj poniższe kroki, aby przejrzeć wyniki eksperymentu i zapisać rurociąg przy użyciu najlepszej wydajności.
Opcjonalnie: Umieść kursor myszy nad dowolnym węzłem w mapie relacji, aby uzyskać szczegółowe informacje na temat transformacji dla konkretnego potoku.
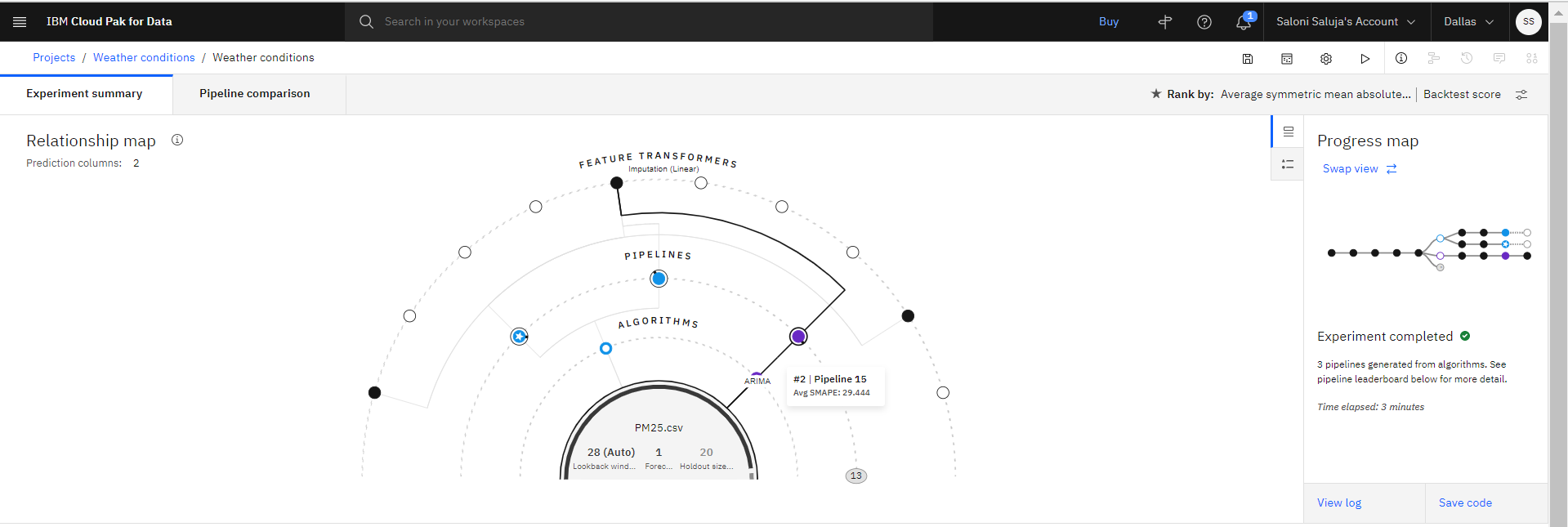
Opcjonalnie: Po tym, jak potoki są wyświetlane na tablicy liderów, kliknij opcję Porównanie potoku , aby sprawdzić, w jaki sposób różnią się one. Na przykład:
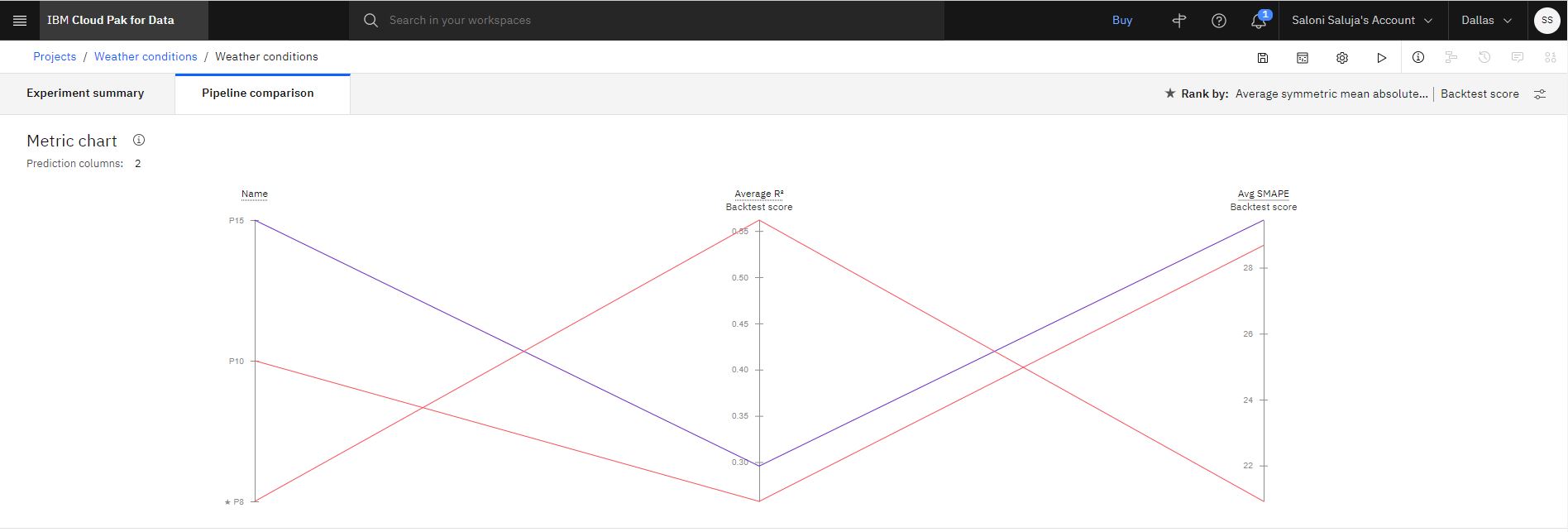
Po zakończeniu szkolenia najlepsze trzy najlepsze wyniki są zapisywane na tablicy liderów. Kliknij nazwę potoku, aby przejrzeć szczegóły.
Uwaga: Pipeliny, które korzystają z funkcji obsługi, są oznaczone przez rozszerzenie **SUP* *.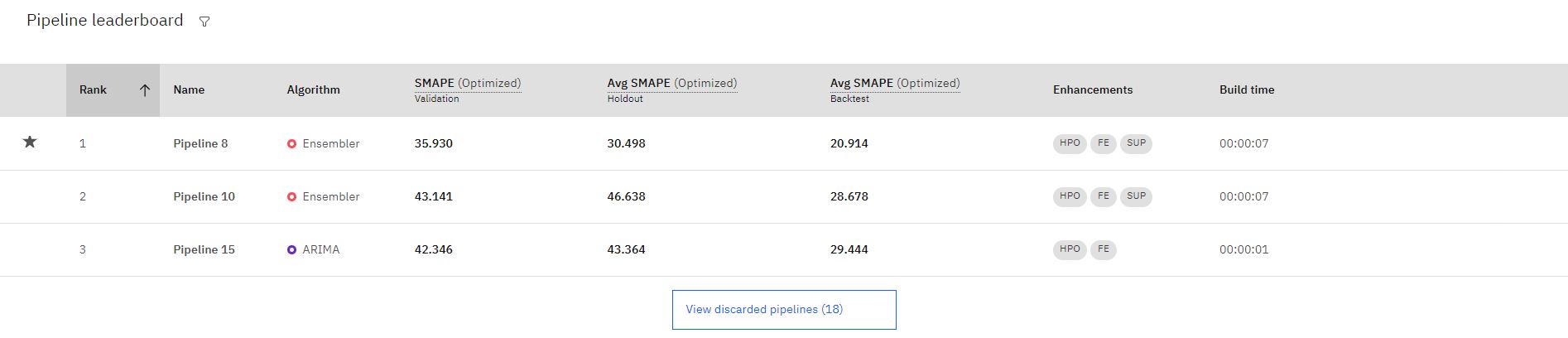
Wybierz potok z rangą 1 i kliknij przycisk Zapisz jako , aby utworzyć model. Następnie kliknij przycisk Utwórz. To działanie spowoduje zapisanie potoku w sekcji Modele na karcie Zasoby aplikacyjne .
Wdróż wyszkolony model
Zanim będzie można użyć wyszkolonego modelu do tworzenia predykcji dla nowych danych, należy wdrożyć model. Aby awansować wyszkolony model do miejsca wdrożenia, należy wykonać następujące kroki:
- Model można wdrożyć na stronie Szczegóły modelu . Aby uzyskać dostęp do strony Szczegóły modelu , należy wybrać jedną z następujących opcji:
- Kliknij nazwę modelu w powiadomieniu, które jest wyświetlane podczas zapisywania modelu.
- Otwórz stronę Zasoby dla projektu, który zawiera model, a następnie kliknij nazwę modelu w sekcji Model Machine Learning .
- Wybierz opcję Awansuj do obszaru wdrażania, a następnie wybierz lub utwórz miejsce wdrożenia, w którym zostanie wdrożony model.
Opcjonalnie: Wykonaj następujące kroki, aby utworzyć obszar wdrażania:
a. Z listy obszarów docelowych wybierz opcję Utwórz nowy obszar wdrażania.
b. Wprowadź nazwę obszaru wdrażania.
c. Aby powiązać instancję uczenia maszynowego, przejdź do sekcji Wybierz usługę uczenia maszynowego (opcjonalnie) , a następnie wybierz z listy instancję uczenia maszynowego.
d. Kliknij makro Create. - Po wybraniu lub utworzeniu obszaru kliknij opcję Awansuj.
- Kliknij odsyłacz obszaru wdrażania od powiadomienia.
- Na karcie Zasoby w obszarze wdrażania:
a. Umieść wskaźnik myszy nad nazwą modelu, a następnie kliknij ikonę wdrażania .
.
b. Na stronie, która zostanie otwarta, wypełniaj pola:
-Wybierz opcję Tryb z połączeniem jako typ wdrożenia.
-umożliwia określenie nazwy dla wdrożenia.
-Kliknij przycisk Utwórz.
Po zakończeniu wdrażania kliknij kartę Deployments (Wdrożenia), a następnie wybierz nazwę wdrożenia, aby wyświetlić stronę szczegółów.
Testowanie wdrożonego modelu
Aby przetestować wdrożony model na stronie szczegółów wdrożenia, wykonaj następujące kroki:
Na karcie Test , na stronie szczegółów wdrożenia, przejdź do arkusza kalkulacyjnego Nowe obserwacje (opcjonalnie) i wprowadź następujące wartości:
pollution (double):80.417
temp (double):-5.5
dew (double):-7.083
press (double):1020.667
wnd_spd (double):9.518
snow (double):0
rain (double):0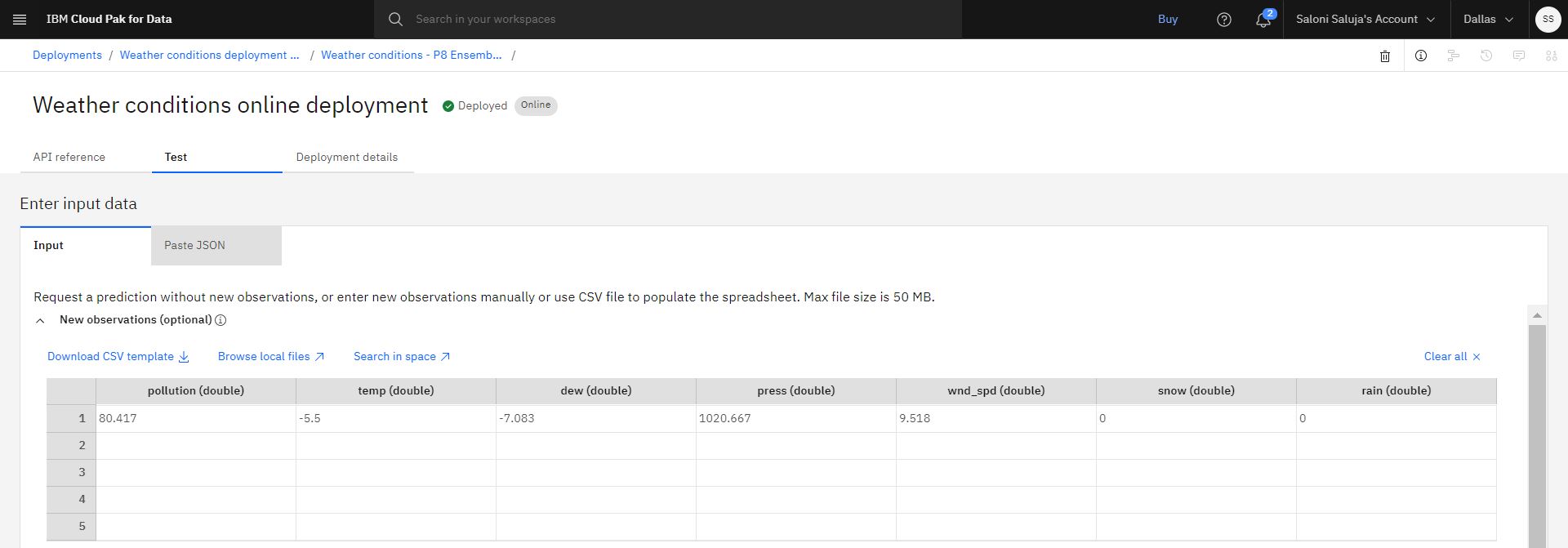
Aby dodać przyszłe wartości funkcji pomocniczych, należy przejść do arkusza kalkulacyjnego Future exogenous features (optional) i wprowadzić następujące wartości:
dew (double):-12.667
press (double):1023.708
wnd_spd (double):9.518
snow (double):0
rain (double):0.042Uwaga: Należy podać taką samą liczbę wartości dla przyszłych elementów egzogenicznych, jak horyzont predykcji, który został ustawiony podczas konfigurowania eksperymentu.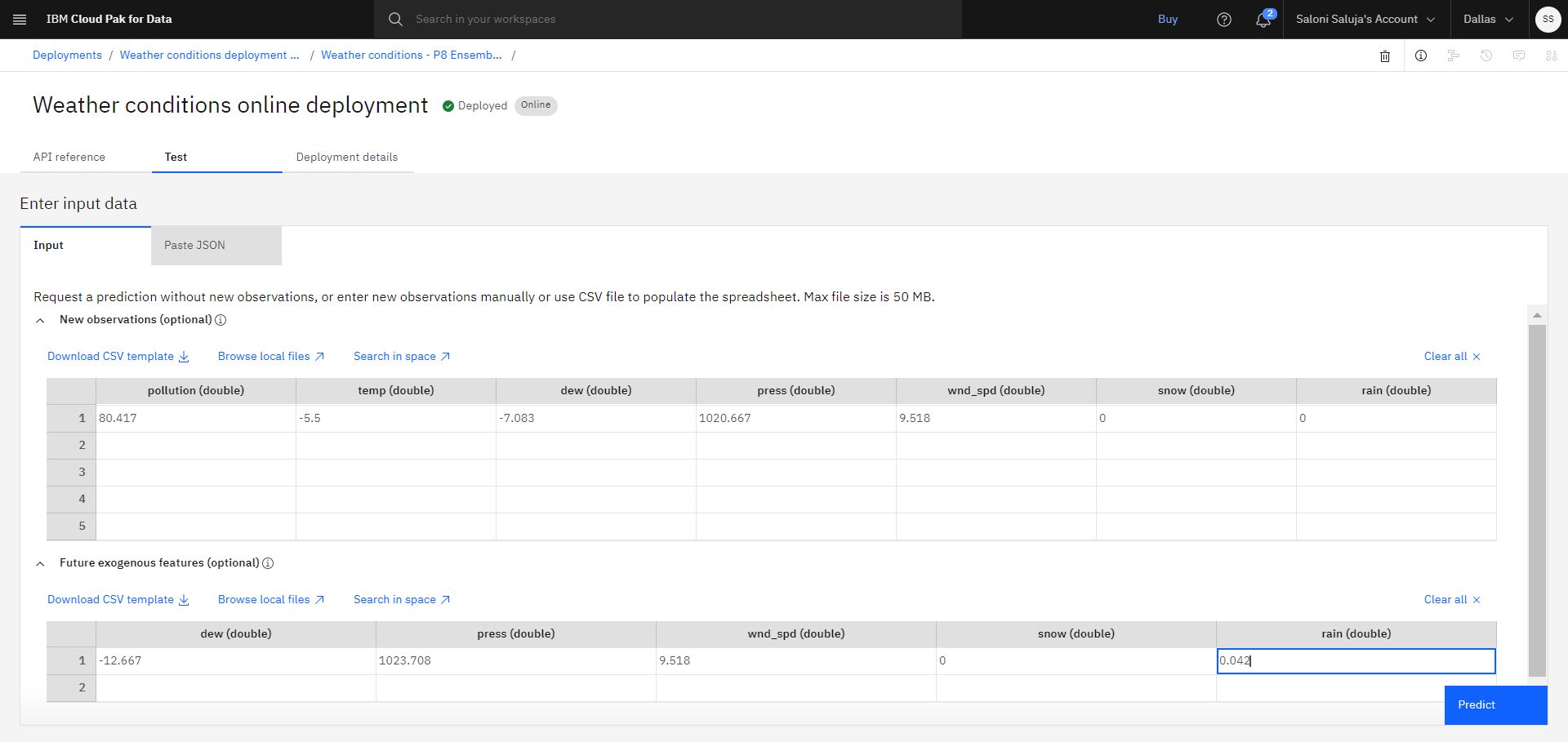
Kliknij opcję Predict. Wynikowa predykcja wskazuje wartości dla zanieczyszczenia i temperatury.
Uwaga: Wartości predykcji, które są wyświetlane w danych wyjściowych, mogą się różnić w przypadku testowania wdrożenia.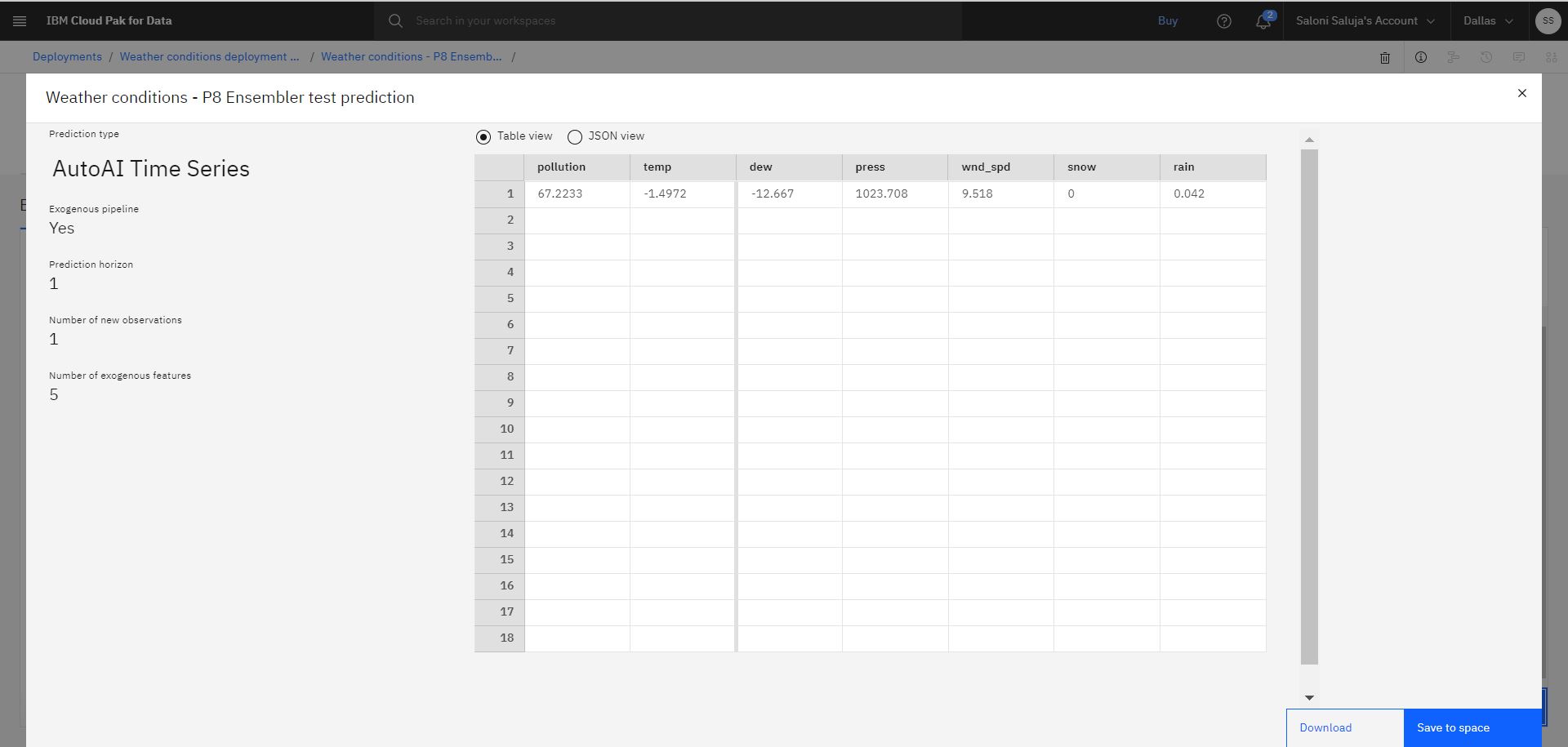
Więcej inform.
Temat nadrzędny: Budowanie eksperymentu szeregów czasowych