サンプル・データを使用して、予測フィールドに影響を与える特徴量をサポートすることで汚染率と温度を予測する多変量の時系列実験をトレーニングします。
実験をセットアップすると、2010 年から 2014 年まで北京の気象状況を追跡するサンプル・データがロードされます。 この実験では、一連のパイプラインが生成されます。これらのパイプラインは、アルゴリズムを使用して、露天、圧力、雪、雨などのサポート機能により、将来の汚染と温度を予測します。 パイプラインを生成した後、AutoAI はそれらを比較してテストし、最良のパフォーマンスを提供するものを選択して、ユーザーが確認できるようにリーダーボードに表示します。
始める前に
以下のサービスが使用可能であることを確認します。
- watsonx.aiStudio サービス
- Watson Machine Learning サービス
データ・セットの概要
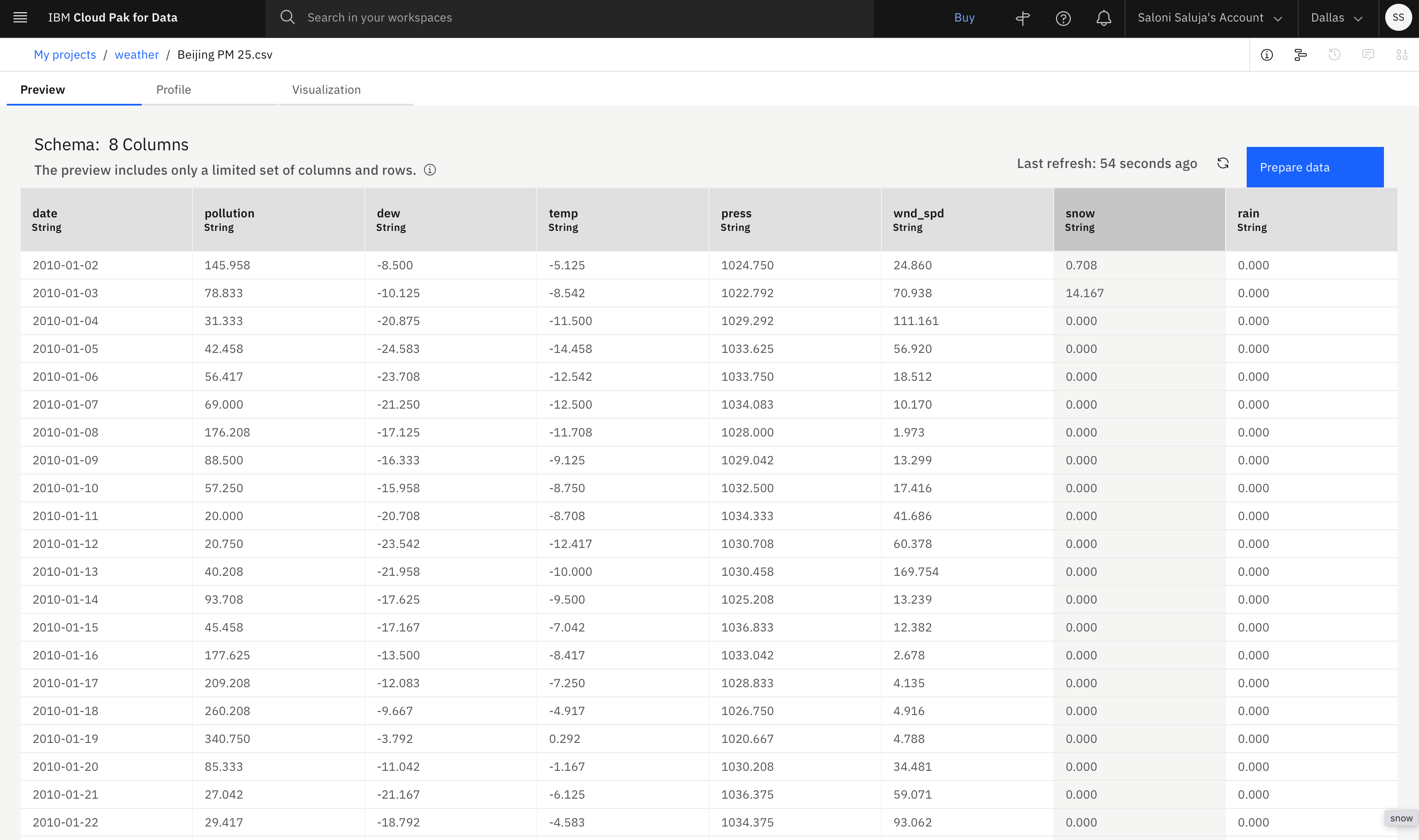
このチュートリアルでは、Resource hubのBeijing PM2.5データセットを使用します。 このデータ・セットは、2010 年から 2014 年までの北京の気象条件を記述します。これらの気象条件は、1 日のステップまたは増分で測定されます。 このデータ・セットを使用して、 AutoAI エクスペリメントを構成し、サポート・フィーチャーを選択します。 ここでは、データ・セットの詳細について説明します。
- 日付列以外の各列は、汚染指標に影響を与える気象条件を表します。
- リソース・ハブ・エントリーは、データの発信元を示します。 ファイルをダウンロードする前に、ファイルをプレビューできます。
- サンプル・データは行と列に構造化され、.CSV ファイルとして保存されます。
タスクの概要
このチュートリアルでは、以下のステップに従って、サポート・フィーチャーを使用する多変量時系列エクスペリメントを作成します。
プロジェクトの作成
以下の手順に従って、空のプロジェクトを作成し、Cloud Pak for Data as a ServiceResourceハブから北京PM2.5データセットをダウンロードします:
- メイン・ナビゲーション・ペインで、 「プロジェクト」 > 「すべてのプロジェクトを表示」をクリックし、 「新規プロジェクト」をクリックします。
a。 空のプロジェクトを作成をクリックしてください。
b. プロジェクトの名前とオプションの説明を入力します。
c. 「作成」をクリックします。 - メインナビゲーションパネルからResource hubをクリックし、北京PM2.5データセットのローカルコピーをダウンロードする。
AutoAI 実験の作成
以下のステップに従って、 AutoAI エクスペリメントを作成し、サンプル・データをエクスペリメントに追加します。
上の資産プロジェクト内のタブから新しいアセット > 機械学習モデルを自動的に構築。
エクスペリメントの名前とオプションの説明を指定します。
機械学習サービス・インスタンスをエクスペリメントに関連付けます。
8 vCPU と 32 GB RAM の環境定義を選択します。
「作成」 をクリックします。
サンプル・データを追加するには、以下のいずれかの方法を選択します。
- ファイルをローカルにダウンロードした場合は、 「参照」 をクリックしてからプロンプトに従って、トレーニング・データ・ファイル PM25.csv をアップロードします。
- 既にファイルをプロジェクトにアップロードしている場合は、 「プロジェクトから選択」をクリックし、 「データ資産」 タブを選択して、 「北京 PM 25.csv」を選択します。
エクスペリメントの構成
多変量 AutoAI 時系列エクスペリメントを構成するには、以下のステップを実行します。
時系列予測を作成するオプションの Yes をクリックします。
予測列として
pollution、tempを選択します。日付/時刻列として選択する:
date。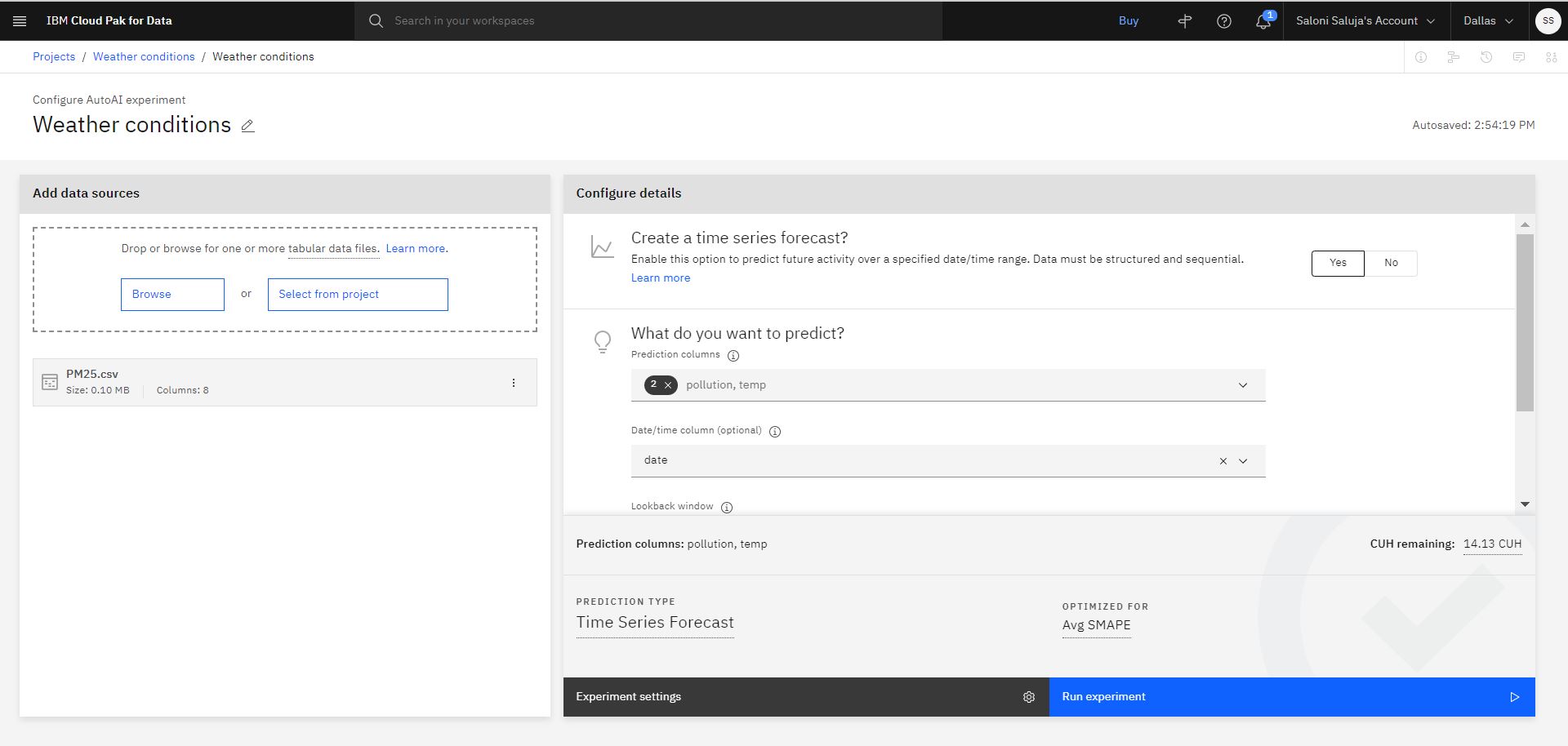
「エクスペリメント設定」 をクリックして、エクスペリメントを構成します。
a. 「予測」 ページで、含めるアルゴリズムのデフォルト選択を受け入れます。 サポート機能の使用が許可されているアルゴリズムは、「Allows supporting features(サポート機能を許可する)」列のチェックマークで示されます。
「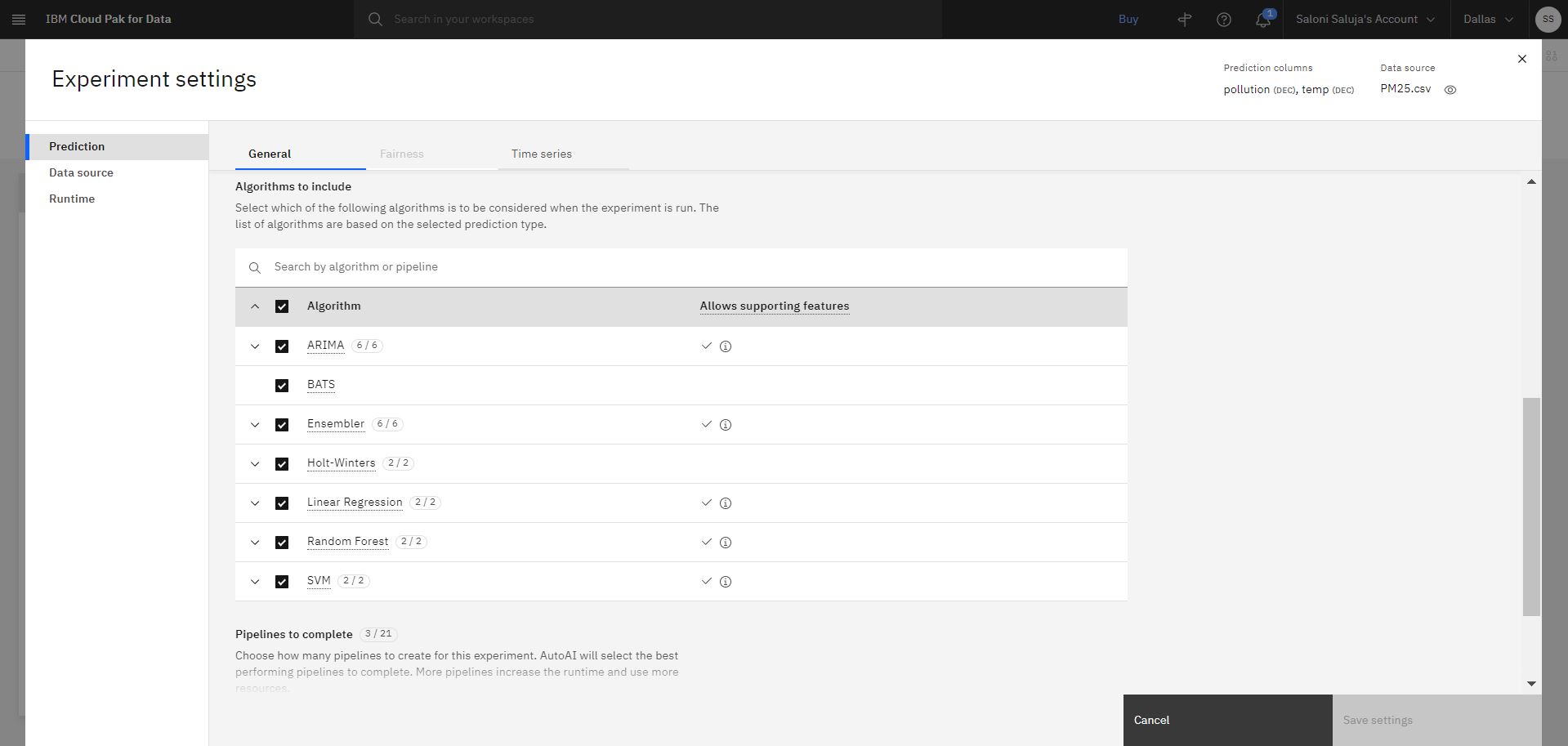 「
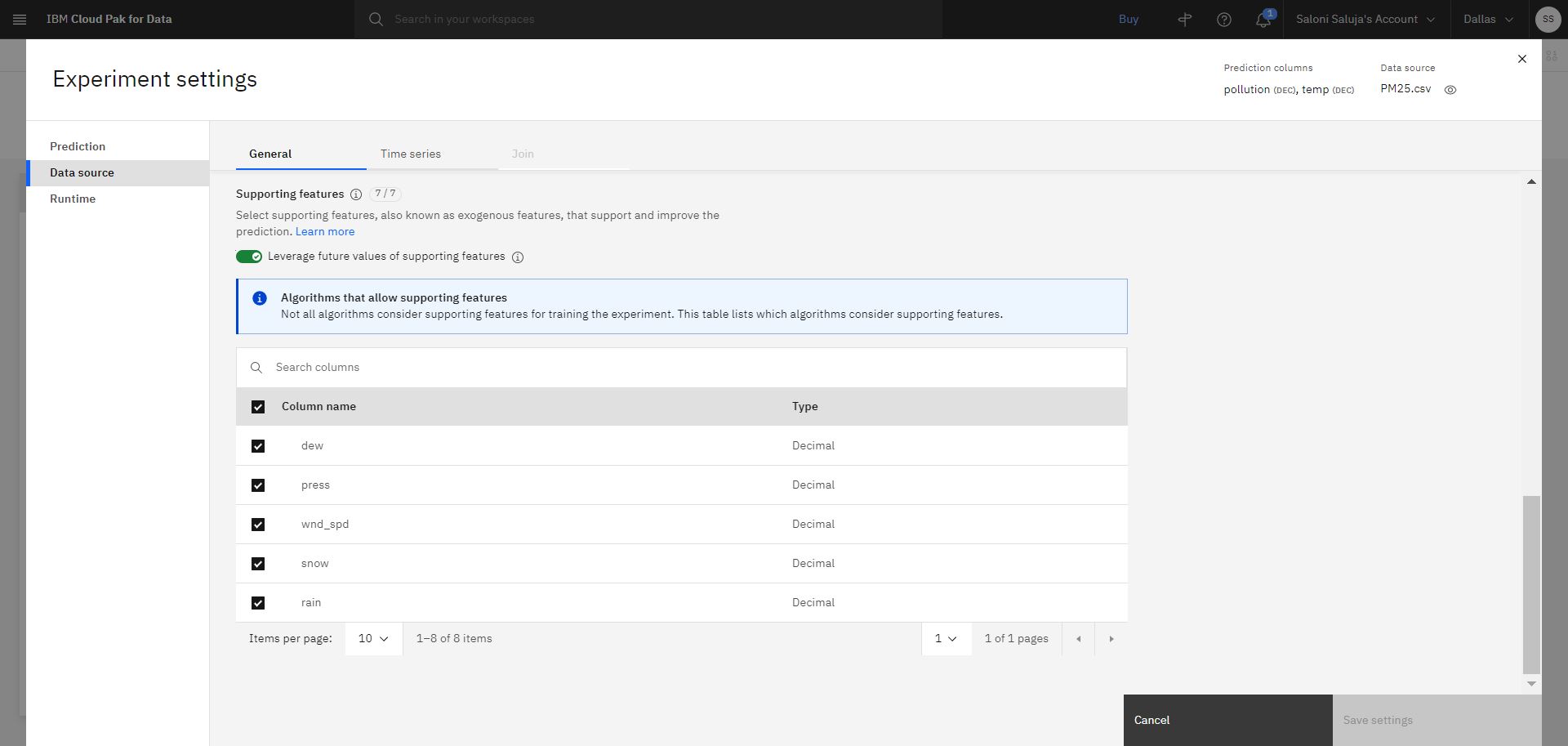
「b. 「データ・ソース」 ページに移動します。 このチュートリアルでは、テスト中にサポート機能の将来の値を指定します。 将来の値は、サポートする特徴量の値が予測期間で認識できる場合に役立ちます。 「サポート・フィーチャーの将来の値を活用」のデフォルトの有効化を受け入れます。 さらに、サポート機能として使用されるカラムのデフォルト選択を受け入れます。
'
c. 「キャンセル」 をクリックして、エクスペリメント設定を終了します。Run experiment をクリックして、トレーニングを開始します。
エクスペリメント結果の確認
テストが完了するまでに数分かかります。 テストのトレーニング時に、関係マップには、パイプラインの作成に使用される変換が表示されます。 以下のステップに従って、テスト結果を確認し、最良のパフォーマンスでパイプラインを保存します。
オプション: 関係マップ内の任意のノードに移動して、特定のパイプラインの変換に関する詳細を取得します。
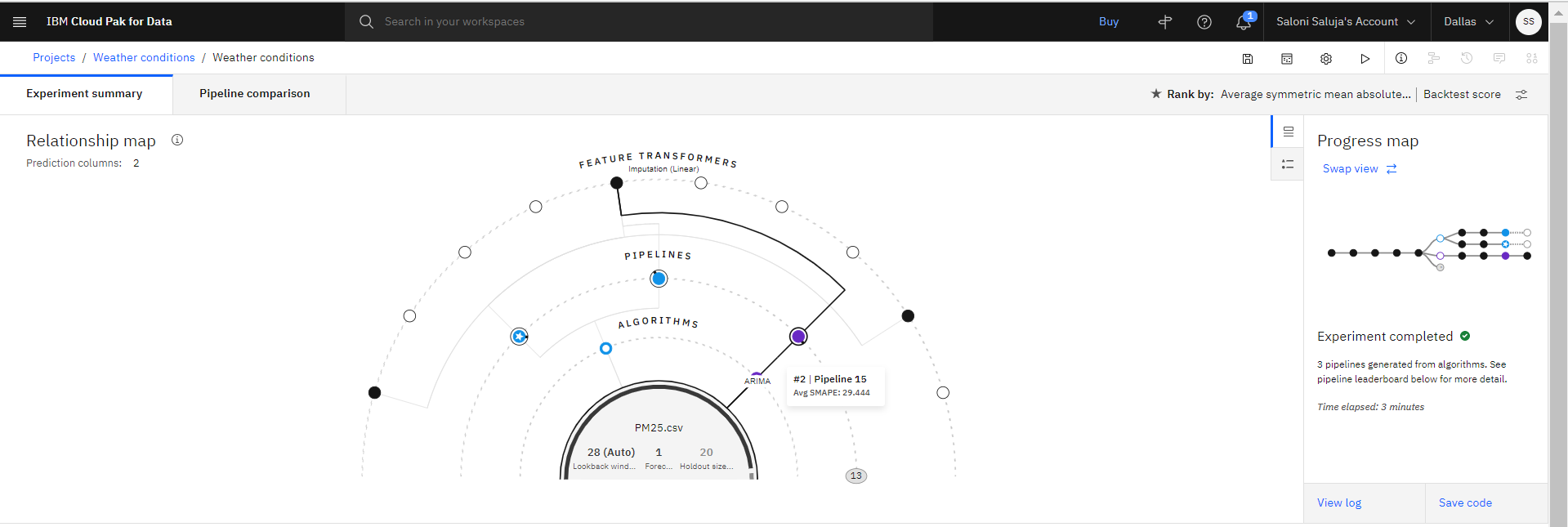
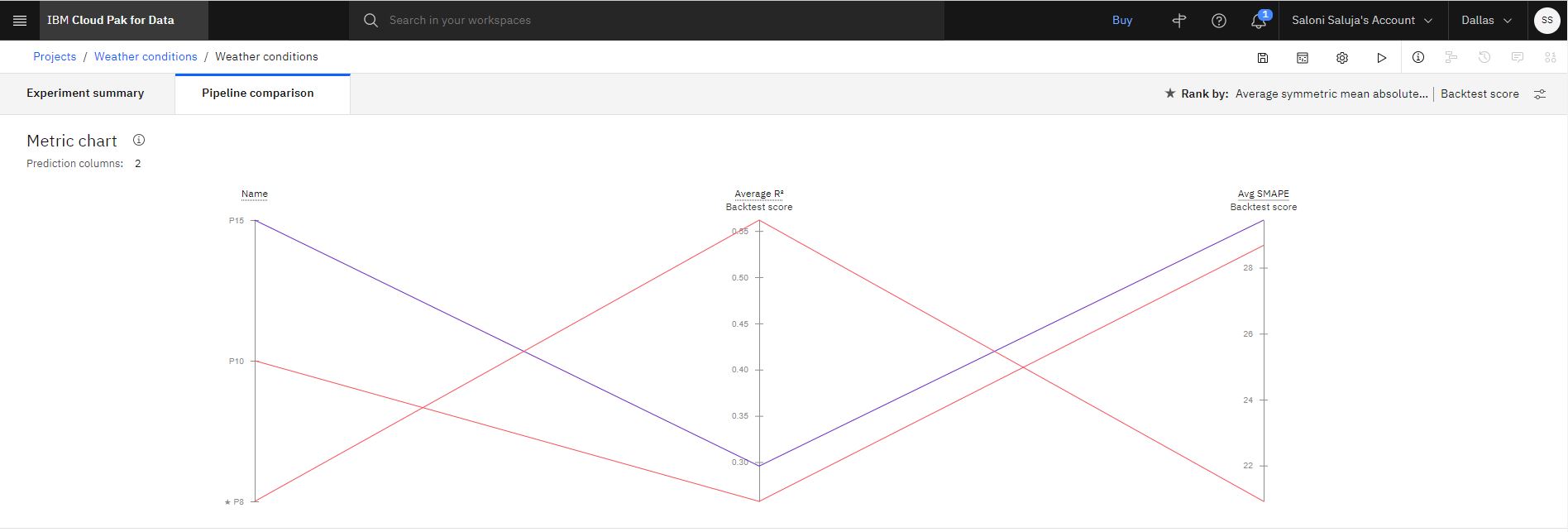
オプション: パイプラインがリーダーボードにリストされたら、 「パイプラインの比較 (Pipeline comparison)」 をクリックして、それらの違いを確認します。 次に例を示します。
トレーニングが完了すると、最もパフォーマンスの良い上位 3 つのパイプラインがリーダーボードに保存されます。 詳細を確認するには、任意のパイプライン名をクリックします。
注: サポート機能を使用するパイプラインは、**SUP* * 機能拡張によって示されます。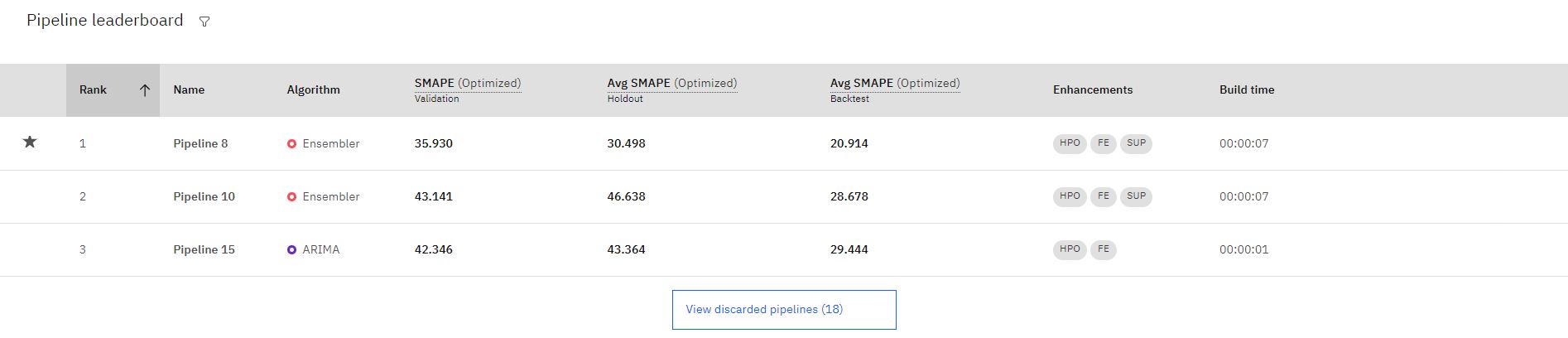
ランク 1 のパイプラインを選択し、 名前を付けて保存 をクリックしてモデルを作成します。 次に「作成」をクリックします。 このアクションにより、 「資産」 タブの 「モデル」 セクションの下にパイプラインが保存されます。
トレーニングされたモデルのデプロイ
トレーニングされたモデルを使用して新規データの予測を行う前に、モデルをデプロイする必要があります。 トレーニング済みモデルをデプロイメント・スペースにプロモートするには、以下の手順を実行します。
- 「モデルの詳細」 ページからモデルをデプロイできます。 「モデルの詳細」 ページにアクセスするには、以下のいずれかのオプションを選択します。
- モデルの保存時に表示される通知内のモデルの名前をクリックします。
- モデルを含むプロジェクトの 「資産」 ページを開き、 Machine Learning 「モデル」 セクションでモデルの名前をクリックします。
- 配備スペースへのプロモーション「
 アイコンをクリックし、モデルを配置する配置スペースを選択または作成します。
アイコンをクリックし、モデルを配置する配置スペースを選択または作成します。
オプション: 以下のステップに従って、デプロイメント・スペースを作成します。
a. 「ターゲット・スペース」リストから、 「新規デプロイメント・スペースの作成」を選択します。
b. デプロイメント・スペースの名前を入力します。
c. 機械学習インスタンスを関連付けるには、 「機械学習サービスの選択 (オプション) (Select machine learning service (optional))」 に移動し、リストから機械学習インスタンスを選択します。
d. 「作成」をクリックします。 - スペースを選択または作成したら、 「プロモート」をクリックします。
- 通知からデプロイメント・スペースのリンクをクリックしてください。
- デプロイメント・スペースの 「資産」 タブから:
a. モデル名にカーソルを合わせ、展開アイコン「 」をクリックします。
」をクリックします。
b. 開いたページで、以下のフィールドに入力します。
-デプロイメント・タイプとして 「オンライン」 を選択します。
-デプロイメントの名前を指定します。
- 「作成」をクリックします。
デプロイメントが完了したら、 「デプロイメント」 タブをクリックし、デプロイメント名を選択して詳細ページを表示します。
デプロイされたモデルのテスト
デプロイメントの詳細ページからデプロイ済みモデルをテストするには、以下の手順を実行します。
デプロイメントの詳細ページの 「テスト」 タブで、 「新しい観測 (オプション)」 スプレッドシートに移動し、以下の値を入力します。
optional (double):80.417
temp (double):-5.5
dew (double):-7.083
press (double):1020.667
wnd_spd (double):9.518
snow (double):0
rain (倍精度浮動小数点数):0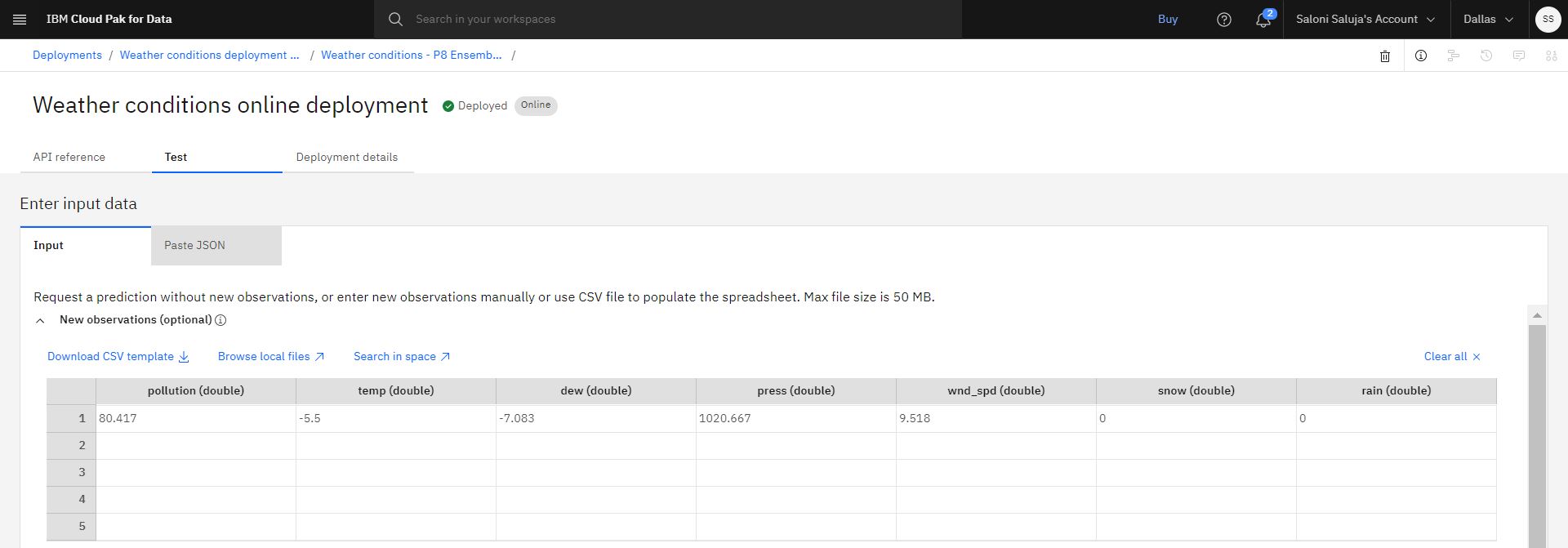
サポート・フィーチャーの将来の値を追加するには、 「将来の外因性フィーチャー (オプション)」 スプレッドシートに移動し、以下の値を入力します。
dew (double):-12.667
press (double):1023.708
wnd_spd (double):9.518
snow (double):0
rain (double):0.042注: 将来の外因性特徴量には、実験構成段階で設定した予測期間と同じ数の値を指定する必要があります。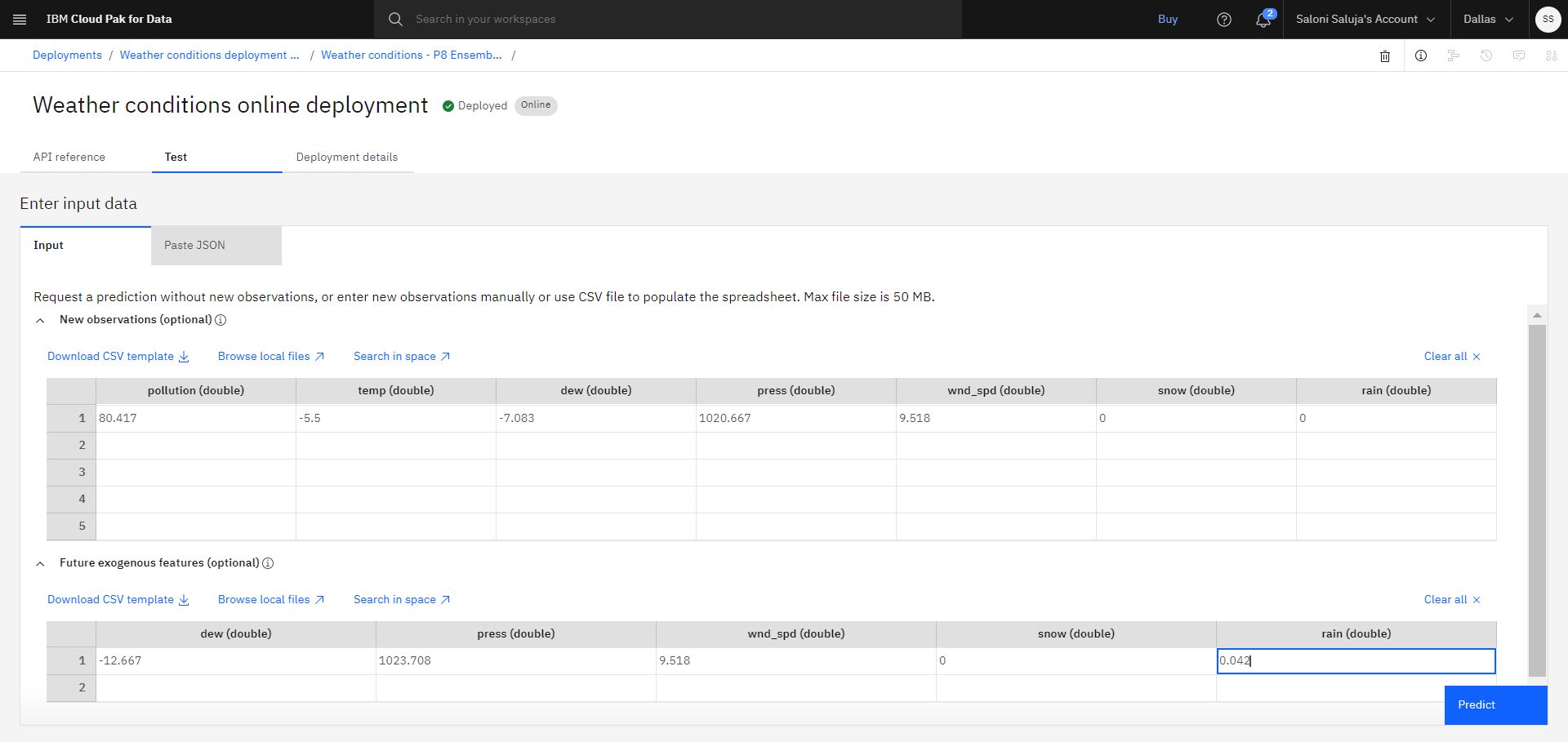
予測をクリックしてください。 結果の予測は、汚染と温度の値を示します。
注: デプロイメントをテストすると、出力に表示される予測値が異なる場合があります。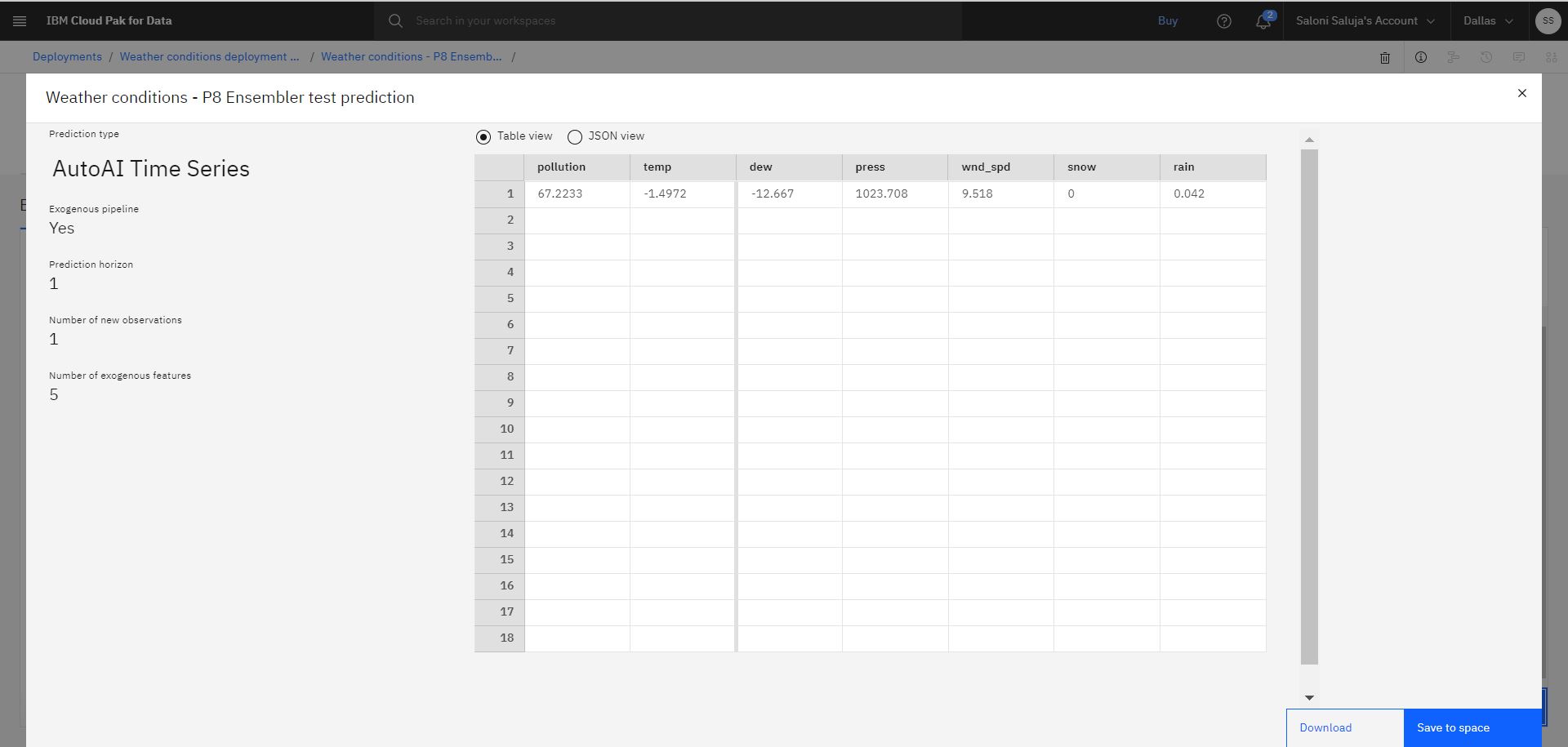
もっと見る
親トピック 時系列実験の構築