Tutoriel: expérimentation de séries temporelles multivariées AutoAI avec des fonctions de prise en charge
Utilisez des données d'échantillon pour entraîner une expérience de série temporelle multivariée qui prédit le taux de pollution et la température à l'aide de fonctions de support qui influencent les champs de prévision.
Lorsque vous configurez l'expérience, vous chargez des échantillons de données qui suivent les conditions météorologiques à Pékin de 2010 à 2014. L'expérience génère un ensemble de pipelines qui utilisent des algorithmes pour prédire la pollution et la température futures avec des caractéristiques de soutien, telles que la rosée, la pression, la neige et la pluie. Après avoir généré les pipelines, AutoAI compare et teste ces pipelines, choisit les plus performants et les présente dans un tableau de classement pour que vous les examiniez.
Avant de commencer
Vérifiez que vous disposez des services suivants:
- watsonx.ai Studio service
- Service Watson Machine Learning
Présentation de l'ensemble de données
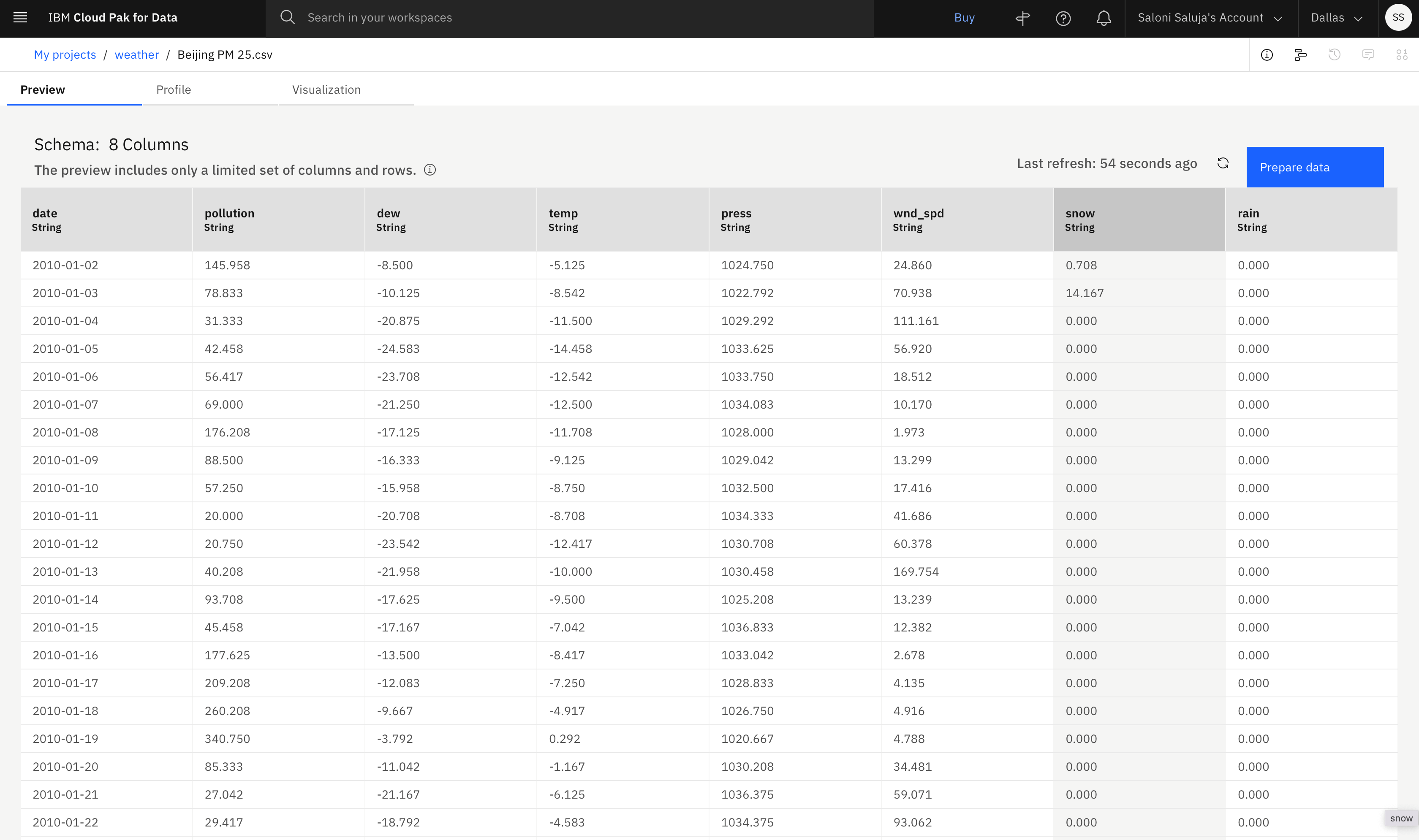
Pour ce tutoriel, vous utilisez l'ensemble de données Beijing PM 2.5 du centre de ressources. Cet ensemble de données décrit les conditions météorologiques en Pékin de 2010 à 2014, qui sont mesurées par paliers de 1 jour ou par incréments. Vous utilisez cet ensemble de données pour configurer votre expérimentation AutoAI et sélectionner des fonctions de prise en charge. Les détails relatifs à l'ensemble de données sont décrits ici:
- Chaque colonne, autre que la colonne de date, représente une condition météorologique qui a un impact sur l'indice de pollution.
- L'entrée du concentrateur de ressources indique l'origine des données. Vous pouvez prévisualiser le fichier avant de le télécharger.
- Les données exemple sont structurées en lignes et colonnes et sauvegardées sous forme de fichier .CSV.
Présentation des tâches
Dans ce tutoriel, vous suivez les étapes pour créer une expérimentation de série temporelle multivariée qui utilise les fonctions de prise en charge:
Créer un projet
Suivez ces étapes pour créer un projet vide et télécharger l'ensemble de données Beijing PM 2.5 à partir du hub de ressources Cloud Pak for Data as a Service:
- Dans le panneau de navigation principal, cliquez sur Projets > Afficher tous les projets, puis sur Nouveau projet.
a: Cliquez sur Créer un projet vide.
b. Entrez un nom et une description facultative pour votre projet.
c. Cliquez sur Créer. - Dans le panneau de navigation principal, cliquez sur " Centre de ressources et téléchargez une copie locale de l'ensemble de données " Le Premier ministre de Pékin " 2.5
Créer une expérimentation AutoAI
Procédez comme suit pour créer une expérimentation AutoAI et ajouter des exemples de données à votre expérimentation:
Sur le Actifs depuis votre projet, cliquez sur Nouvel actif > Créer automatiquement des modèles d'apprentissage automatique .
Indiquez un nom et une description facultative pour votre expérimentation.
Associez une instance de service d'apprentissage automatique à votre expérimentation.
Choisissez une définition d'environnement de 8 vCPU et de 32 Go de mémoire RAM.
Cliquez sur Créer.
Pour ajouter des exemples de données, choisissez l'une des méthodes suivantes:
- Si vous avez téléchargé votre fichier localement, téléchargez le fichier de données d'entraînement PM25.csv en cliquant sur Parcourir , puis en suivant les invites.
- Si vous avez déjà téléchargé votre fichier dans votre projet, cliquez sur Sélectionner dans le projet, puis sélectionnez l'onglet Actif de données et choisissez Beijing PM 25.csv.
Configurer l'expérimentation
Pour configurer votre expérimentation multivariée de séries temporelles AutoAI , procédez comme suit:
Cliquez sur Oui pour créer une prévision de séries temporelles.
Choisir comme colonnes de prévision:
pollutiontempChoisissez la colonne date / heure :
date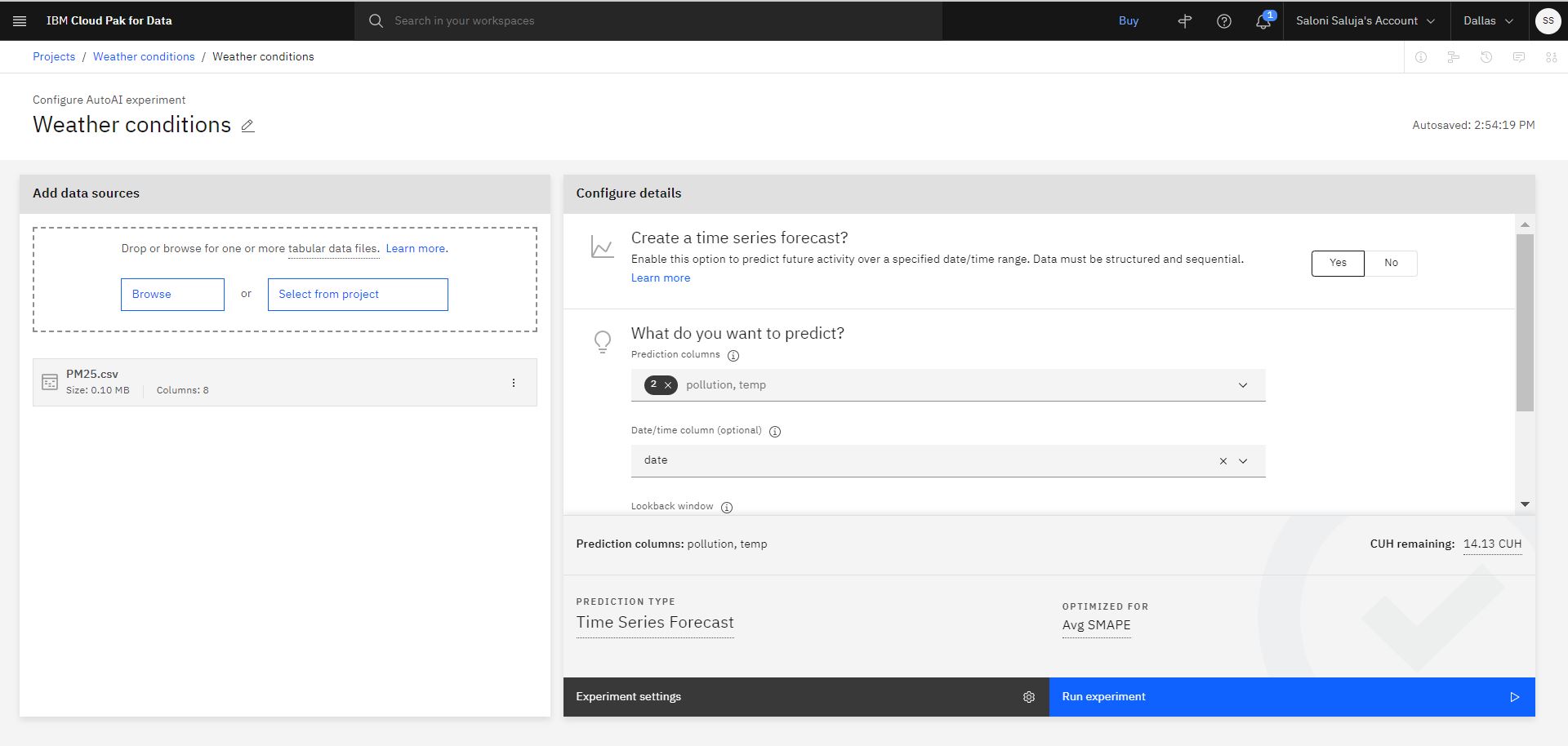
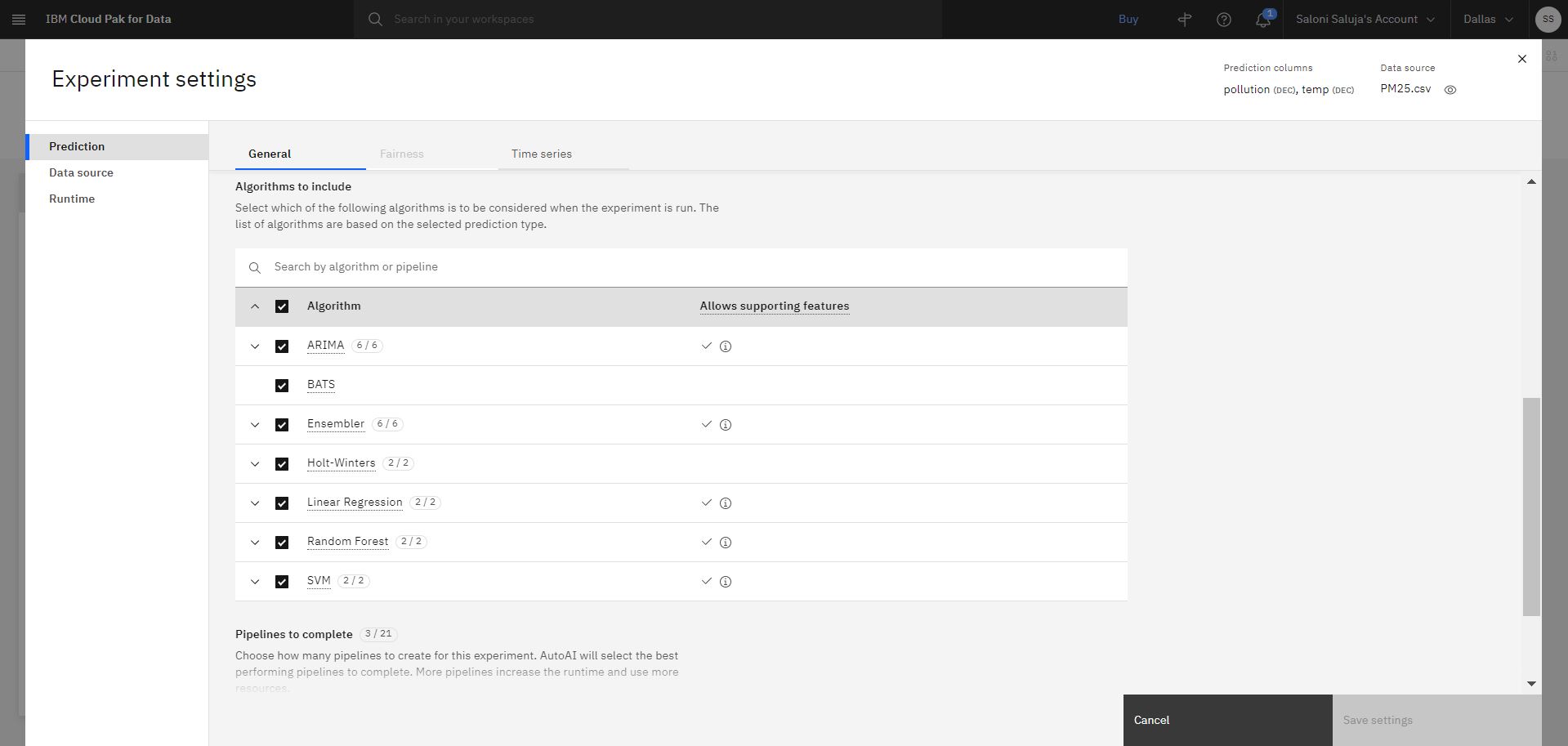
Cliquez sur Paramètres de l'expérimentation pour configurer l'expérimentation:
a. Dans la page Prévision , acceptez la sélection par défaut des algorithmes à inclure. Les algorithmes qui vous permettent d'utiliser les fonctions de support sont indiqués par une coche dans la colonne Autorise les fonctions de support.
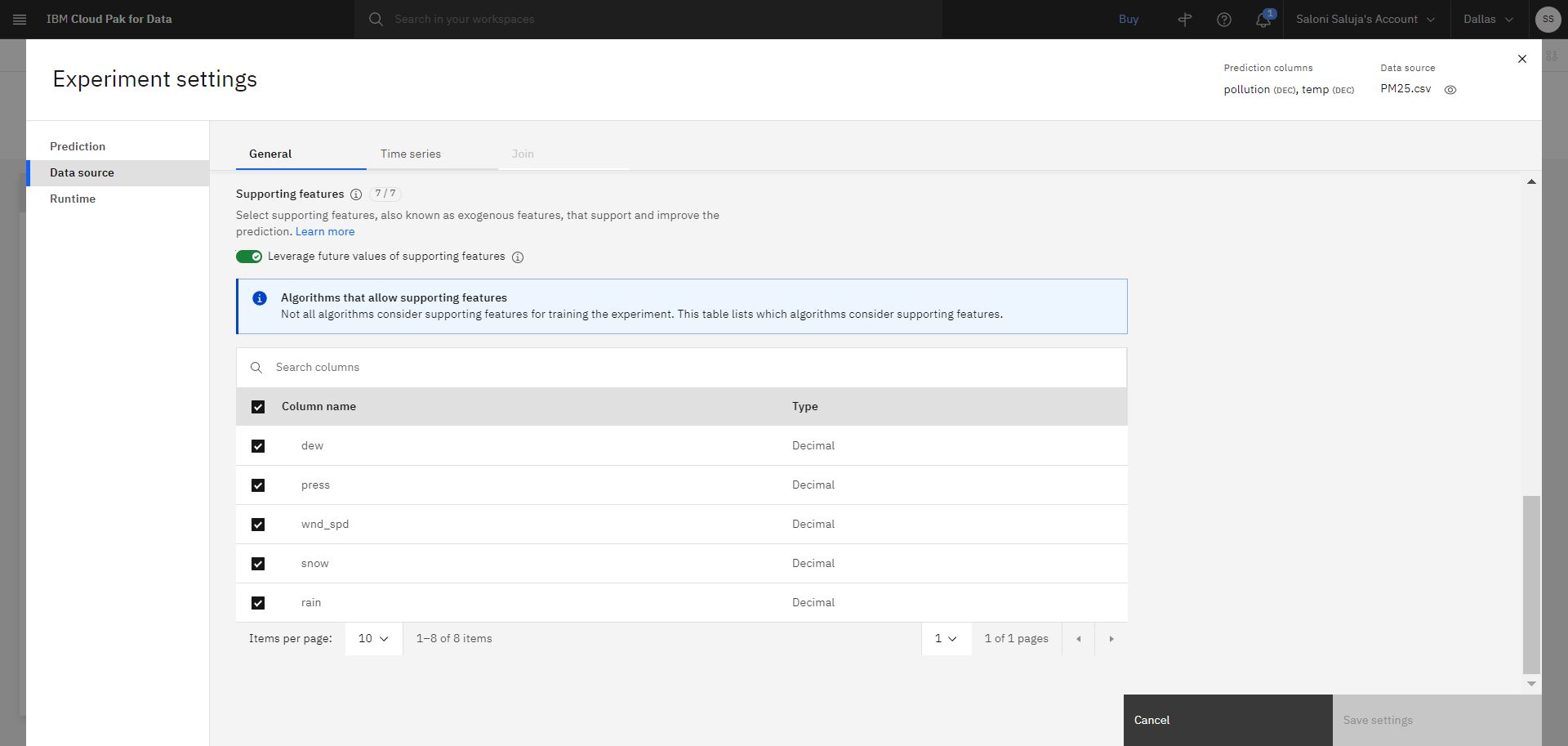
b. Accédez à la page Source de données . Pour ce tutoriel, vous fournirez les valeurs futures des fonctions de support lors du test. Les valeurs futures sont utiles lorsque les valeurs des fonctions de support sont connues pour l'horizon de prévision. Acceptez l'activation par défaut pour Optimiser les valeurs futures des fonctions de prise en charge. En outre, acceptez la sélection par défaut des colonnes qui seront utilisées comme éléments de soutien.
"
c. Cliquez sur Annuler pour quitter les paramètres de l'expérimentation.Cliquez sur Exécuter l'expérimentation pour commencer l'entraînement.
Réviser les résultats de l'expérimentation
L'expérience prend plusieurs minutes. Au fur et à mesure que l'expérimentation s'entraîne, la mappe de relations affiche les transformations utilisées pour créer des pipelines. Procédez comme suit pour examiner les résultats d'expérimentation et sauvegarder le pipeline avec les meilleures performances.
Facultatif: surprenez n'importe quel noeud de la mappe de relations pour obtenir des détails sur la transformation d'un pipeline particulier.
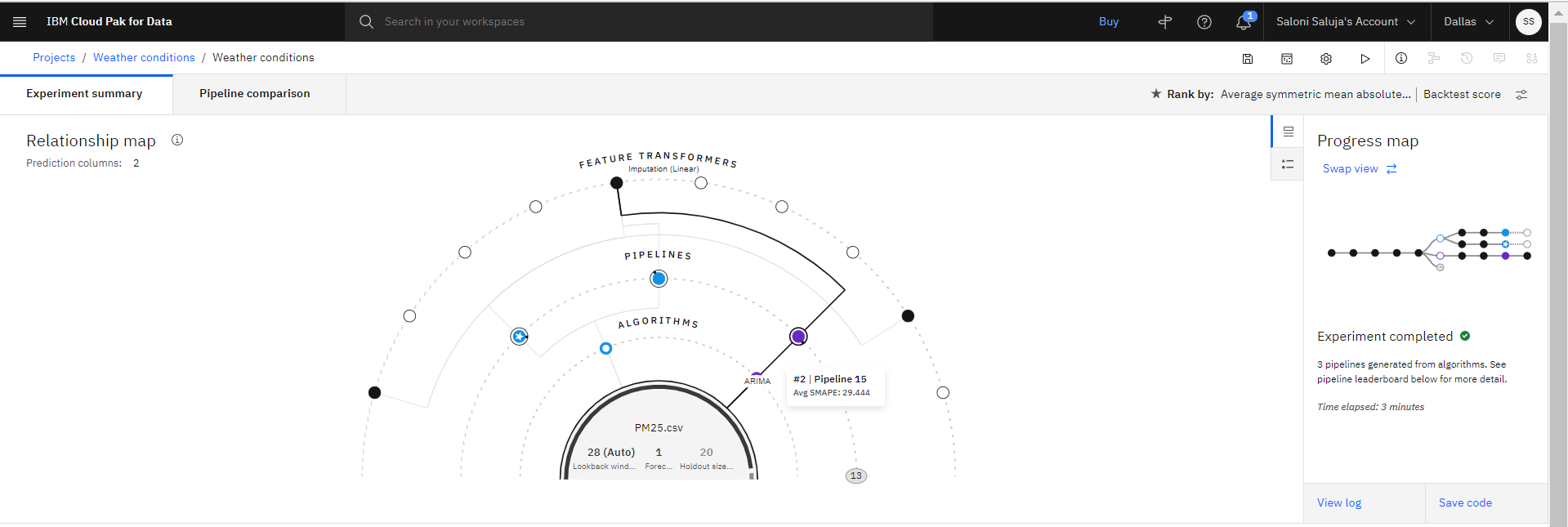
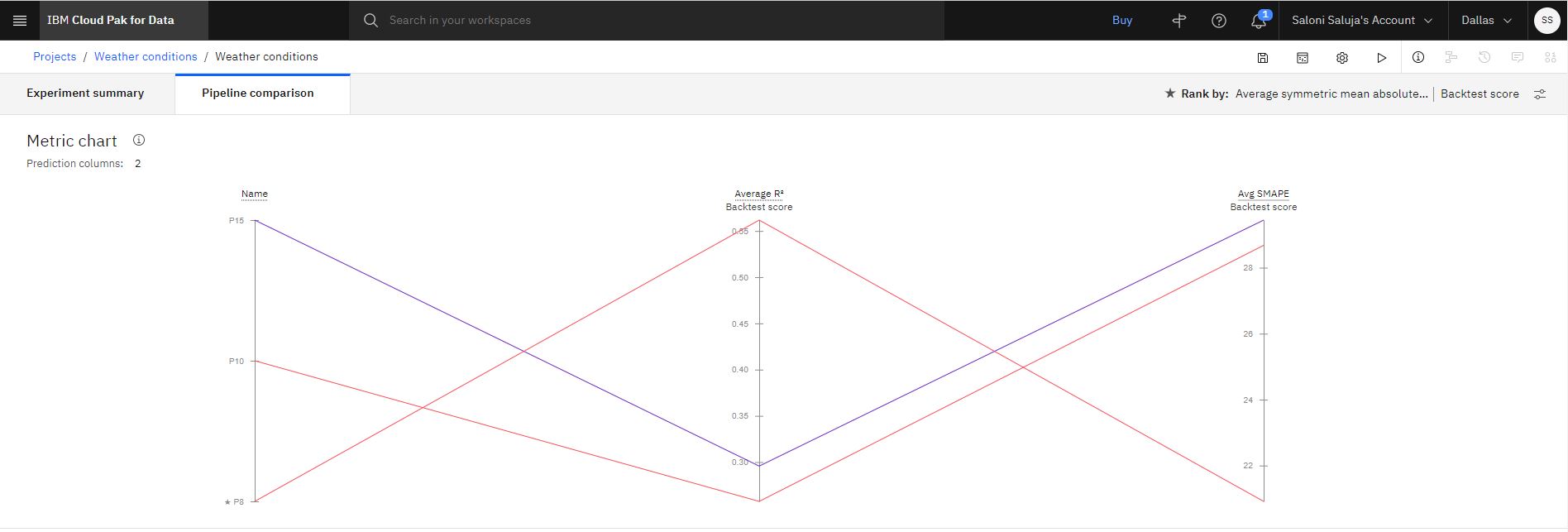
Facultatif: une fois que les pipelines sont répertoriés dans le tableau de classement, cliquez sur Comparaison de pipelines pour voir leur différence. Par exemple :
Une fois l'entraînement terminé, les trois pipelines les plus performants sont sauvegardés dans le tableau de classement. Cliquez sur un nom de pipeline pour consulter les détails.
Remarque: Les pipelines qui utilisent des fonctions de prise en charge sont indiqués par l'amélioration **SUP* *.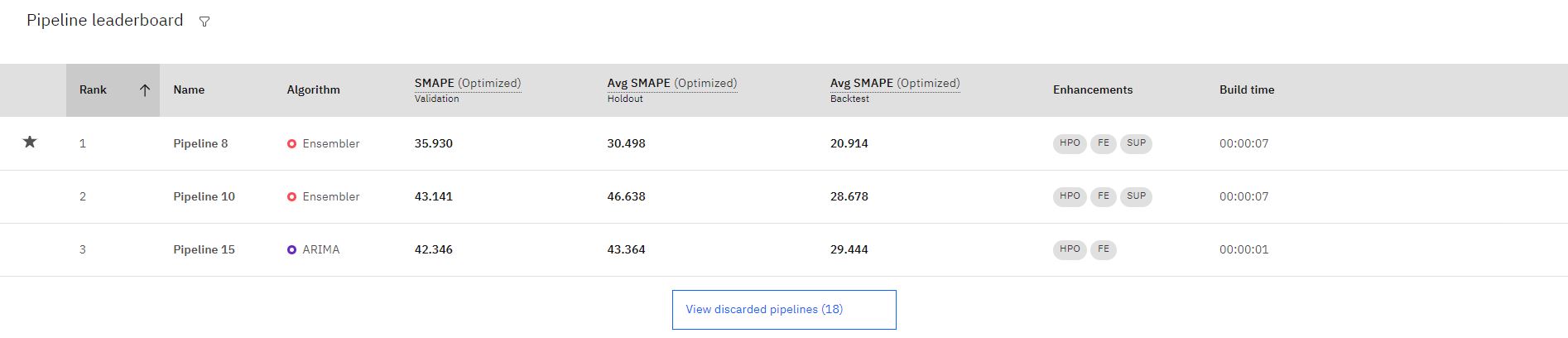
Sélectionnez le pipeline avec le rang 1 et cliquez sur Enregistrer sous pour créer votre modèle. Ensuite, cliquez sur Créer. Cette action sauvegarde le pipeline sous la section Modèles de l'onglet Actifs .
Déploiement du modèle entraîné
Pour pouvoir utiliser votre modèle entraîné afin d'effectuer des prévisions concernant de nouvelles données, vous devez déployer le modèle. Procédez comme suit pour promouvoir votre modèle entraîné dans un espace de déploiement:
- Vous pouvez déployer le modèle à partir de la page Détails du modèle . Pour accéder à la page Détails du modèle , choisissez l'une des options suivantes:
- Cliquez sur le nom du modèle dans la notification qui s'affiche lorsque vous sauvegardez le modèle.
- Ouvrez la page Actifs du projet qui contient le modèle et cliquez sur le nom du modèle dans la section ModèleMachine Learning .
- Cliquez sur l'icône Promouvoir vers l'espace de déploiement "
 , puis sélectionnez ou créez un espace de déploiement où le modèle sera déployé.
, puis sélectionnez ou créez un espace de déploiement où le modèle sera déployé.
Facultatif: suivez ces étapes pour créer un espace de déploiement:
a. Dans la liste Espace cible, sélectionnez Créer un espace de déploiement.
b. Entrez un nom pour votre espace de déploiement.
c. Pour associer une instance d'apprentissage automatique, accédez à Sélectionner un service d'apprentissage automatique (facultatif) et sélectionnez une instance d'apprentissage automatique dans la liste.
d. Cliquez sur Créer. - Une fois que vous avez sélectionné ou créé votre espace, cliquez sur Promouvoir.
- Cliquez sur le lien de l'espace de déploiement à partir de la notification.
- Dans l'onglet Actifs de l'espace de déploiement:
a. Survolez le nom du modèle et cliquez sur l'icône de déploiement " .
.
b. Dans la page qui s'ouvre, renseignez les zones:
-Sélectionnez En ligne comme type de déploiement.
-Indiquez un nom pour le déploiement.
-Cliquez sur Créer.
Une fois le déploiement terminé, cliquez sur l'onglet Déploiements et sélectionnez le nom du déploiement pour afficher la page des détails.
Test du modèle déployé
Procédez comme suit pour tester le modèle déployé à partir de la page des détails du déploiement:
Dans l'onglet Test de la page des détails du déploiement, accédez à la feuille de calcul Nouvelles observations (facultatif) et entrez les valeurs suivantes:
pollution (double):80.417
temp (double):-5.5
dew (double):-7.083
appuyez sur (double):1020.667
wnd_spd (double):9.518
snow (double):0
pluie (double):0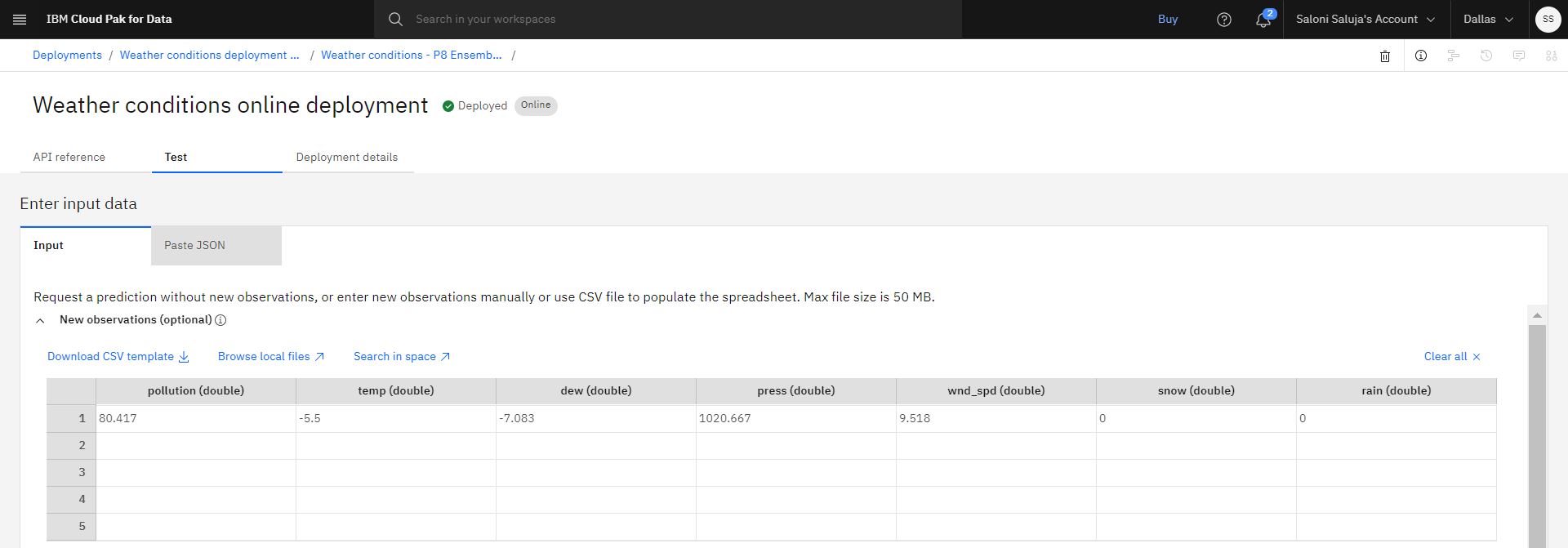
Pour ajouter les valeurs futures des fonctions de support, accédez à la feuille de calcul Future exogène features (optional) et entrez les valeurs suivantes:
dew (double):-12.667
press (double):1023.708
wnd_spd (double):9.518
snow (double):0
rain (double):0.042Remarque: Vous devez fournir le même nombre de valeurs pour les futures fonctions exogènes que l'horizon de prévision que vous avez défini lors de la phase de configuration de l'expérimentation.
Cliquez sur Prévoir. La prédiction qui en résulte indique des valeurs pour la pollution et la température.
Remarque: les valeurs de prévision affichées dans la sortie peuvent différer lorsque vous testez votre déploiement.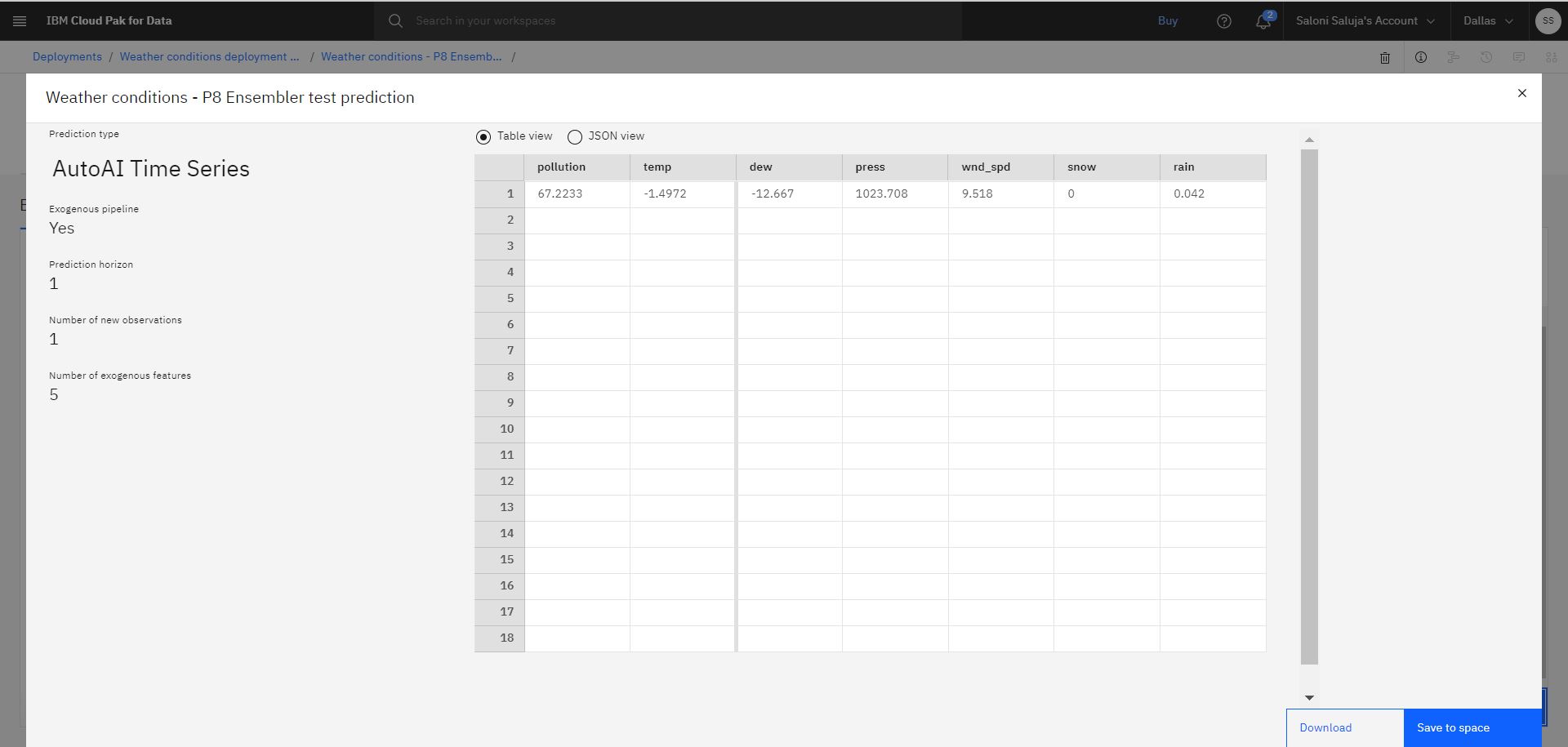
En savoir plus
Sujet parent : Construire une expérience sur les séries temporelles