時系列実装の詳細
これらの実装の詳細は、 AutoAI 時系列実験に固有のステージと処理について説明しています。
実装の詳細
時系列エクスペリメントについては、これらの実装と構成の詳細を参照してください。
- 実験を処理するための時系列ステージです。
- パイプラインをチューニングするための 時系列最適化メトリック 。
- パイプラインを作成するための 時系列アルゴリズム 。
- サポートされる日時形式。
時系列ステージ
エクスペリメントを実行する際、AutoAI 時系列エクスペリメントには以下のステージが含まれます。
ステージ 1: 初期化
初期化ステージは、以下の順序でトレーニング・データを処理します。
- データをロードする
- データ・セット L をトレーニング・データ T とホールドアウト・データ H に分割します
- 検証、タイム・スタンプ列の処理、および遡及ウィンドウの生成を設定します。 注:
- トレーニング・データ (T ) は、データ・セット (L) からホールドアウト (H) を引いた値に等しくなります。 エクスペリメントの構成時に、ホールドアウト・データのサイズを調整できます。 デフォルトでは、ホールドアウト・データのサイズは 20 ステップです。
- オプションで、タイム・スタンプ列を指定できます。
- デフォルトでは、信号処理方式を使用して季節期間を検出することにより、遡及ウィンドウが自動的に生成されます。 ただし、適切なルックバック範囲を自分で設定したい場合は、値を直接指定できます。
ステージ 2: パイプラインの選択
パイプライン選択ステップでは、 T-Daub (上限を使用した時系列データ割り振り) と呼ばれる効率的な方法を使用します。 このメソッドは、より多くのトレーニング・データを最も有望なパイプラインに割り振り、より少ないトレーニング・データを約束のないパイプラインに割り振ることによって、パイプラインを選択します。 このようにすると、すべてのパイプラインが完全なデータ・セットを表示するわけではなく、通常は選択プロセスが高速になります。 以下のステップでは、プロセスの概要について説明します。
- すべてのパイプラインには、トレーニング・データのいくつかの小さなサブセットが順次割り振られます。 最新のデータが最初に割り振られます。
- 各パイプラインは、トレーニング・データの割り振り済みサブセットごとにトレーニングされ、テスト・データ (ホールドアウト・データ) を使用して評価されます。
- 線形回帰モデルは、前のステップで説明したデータ・セットを使用して、各パイプラインに適用されます。
- パイプラインの正確度スコアは、トレーニング・データ・セット全体に予測されます。 この方法では、各パイプラインに割り振られたデータの正確さとサイズがデータ・セットに含まれます。
- 最適なパイプラインは、予測される精度と割り当てられたランク 1 に従って選択されます。
- より多くのデータが最良のパイプラインに割り振られます。 その後、他のパイプラインの予測される正確度が更新されます。
- 前の 2 つのステップは、上位 N 個のパイプラインがすべてのデータでトレーニングされるまで繰り返されます。
ステージ 3: モデル評価
このステップでは、ウィニング・パイプライン N がトレーニング・データ・セット T全体でリトレーニングされます。 さらに、ホールドアウト・データ Hを使用して評価されます。
ステージ 4: 最終パイプライン生成
このステップでは、ウィニング・パイプラインはデータ・セット (L) 全体でリトレーニングされ、また最終パイプラインとして生成されます。
各パイプラインのリトレーニングが完了すると、パイプラインがリーダーボードに通知されます。 パイプラインの詳細を検査するか、パイプラインをモデルとして保存するかを選択できます。
ステージ 5: バックテスト
最終ステップでは、バックテスト方式を使用して、勝利したパイプラインがリトレーニングされ、評価されます。 以下のステップでは、バックテスト方式について説明します。
- トレーニング・データの長さが、バックテストの数、ギャップの長さ、およびホールドアウトのサイズに基づいて決定されます。 これらのパラメーターについて詳しくは、 時系列エクスペリメントの作成を参照してください。
- 最も古いデータから始めて、テストはトレーニング・データを使用してトレーニングされます。
- さらに、テストは最初の検証データ・セットで評価されます。 ギャップの長さがゼロ以外の場合、ギャップ内のデータはスキップオーバーされます。
- 新しいトレーニング・セットを形成するために、ホールドアウトのサイズとギャップの長さを増やすことにより、トレーニング・データ・ウィンドウを進めます。
- 新しいエクスペリメントは、この新しいデータを使用してトレーニングされ、次の検証データ・セットを使用して評価されます。
- 前の 2 つのステップは、残りのバックテスト期間についても繰り返されます。
時系列最適化メトリック
デフォルトのメトリックを受け入れるか、エクスペリメント用に最適化するメトリックを選択します。
| メトリック | 説明 |
|---|---|
| 調整平均絶対誤差率 (SMAPE) | 適合ポイントごとに、実際の値と予測値の絶対差を、実際の絶対値と予測値の合計の半分で除算します。 次に、適合したすべてのポイントにわたって、そのようなすべての値の平均が計算されます。 |
| 平均絶対誤差 (MAE) | 実際の値と予測された値の間の絶対差の平均。 |
| 二乗平均平方根誤差 (RMSE)(Root Mean Squared Error (RMSE)) | 実際の値と予測された値の間の平均 2 乗差の平方根。 |
| R2 | ベースライン・モデルまたは平均モデルとモデル・パフォーマンスを比較した指標。 R2 は 1 以下でなければなりません。 負の R2 値は、検討中のモデルが平均モデルより悪いことを意味します。 0 R2 値は、検討中のモデルが平均モデルと同じくらい良好または不良であることを意味します。 正の R2 値は、検討中のモデルが平均モデルより優れていることを意味します。 |
テストのメトリックの確認
時系列エクスペリメントの結果を表示すると、パイプライン・リーダーボードでエクスペリメントのトレーニングに使用されるメトリックの値が表示されます。
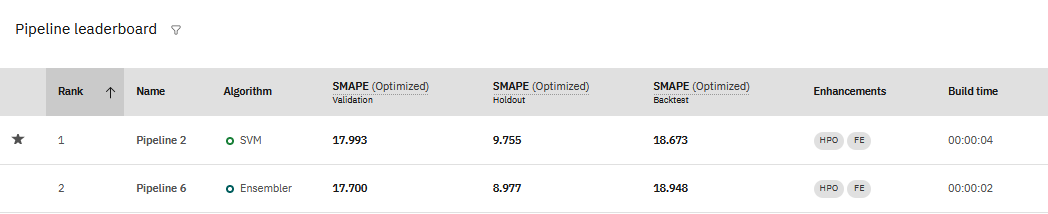
評価されるエクスペリメント・データによって、時系列実験の正確度の測定方法が大きく異なる場合があることが分かります。
- 検証は、トレーニング・データに基づいて計算されるスコアです。
- ホールドアウトは、予約されたホールドアウト・データに対して計算されたスコアです。
- バックテストは、すべてのバックテスト・スコアの平均スコアです。
時系列アルゴリズム
これらのアルゴリズムは、時系列エクスペリメントで使用できます。 デフォルトで選択されているアルゴリズムを使用することも、特定のアルゴリズムを含めるか除外するようにエクスペリメントを構成することもできます。
| アルゴリズム | 説明 |
|---|---|
| ARIMA | 自己回帰積分移動平均 (ARIMA) モデルは標準的な時系列モデルであり、差分を介して非定常データを定常データに変換し、過去の値 (遅延値や遅延予測誤差など) を使用して次の値を予測することができます。 |
| BATS | BATSアルゴリズムは、Box-Cox変換、ARMA残差、トレンド、季節性要因を組み合わせて将来の値を予測する。 |
| アンサンブル | Ensembler は、複数の予測方式を組み合わせることで、単純な予測の精度を克服し、オーバーフィッティングの可能性を回避します。 |
| Holt-Winters | 3 つの指数平滑法を使用して、系列のデータ・ポイントを予測します (その系列が時間の経過とともに反復する (季節性) 場合)。 Holt-Winters 加法および Holt-Winters 乗法という 2 つのタイプの Holt-Winters モデルを使用できます |
| ランダム・フォレスト | ツリー・ベースの回帰モデル。アンサンブル内の各ツリーは、学習セットから置換 (ブートストラップ・サンプルなど) を使用して抽出されたサンプルから作成されます。 |
| Support Vector Machine (SVM) | SVM は、回帰と分類の両方に使用できる機械学習モデルの一種です。 SVM は、ハイパープレーンを使用してデータを別々のクラスに分割します。 |
| 線形回帰 | AR プロセスに従う残差を使用して、時系列変数と日付/時刻または時刻インデックスとの間の線形関係を作成します。 |
サポートされる日時形式
時系列実験でサポートされる日付/時刻形式は、 dateutilによって提供される定義に基づいています。
サポートされる日付形式は次のとおりです。
共通:
YYYY YYYY-MM, YYYY/MM, or YYYYMM YYYY-MM-DD or YYYYMMDD mm/dd/yyyy mm-dd-yyyy JAN YYYY
特殊:
YYYY-Www or YYYYWww - ISO week (day defaults to 0) YYYY-Www-D or YYYYWwwD - ISO week and day
ISO の週と日の値の数値は、 datetime.date.isocalendar() と同じロジックに従います。
サポートされる時刻形式は次のとおりです。
hh hh:mm or hhmm hh:mm:ss or hhmmss hh:mm:ss.ssssss (Up to 6 sub-second digits) dd-MMM yyyy/mm
注:
- 深夜は 00:00 または 24:00 と表すことができます。 小数点には、ピリオドまたはコンマを使用できます。
- 日付は、「1958-01-16」のように、二重引用符付きのストリングとして送信できます。
サポート機能
サポート・フィーチャー (外因性フィーチャーとも呼ばれる) は、予測ターゲットに影響を与える可能性がある入力フィーチャーです。 サポート・フィーチャーを使用してデータ・セットから追加の列を組み込むことで、予測を向上させ、モデルの正確度を向上させることができます。 例えば、時系列の実験で時間の経過とともに価格を予測する場合、サポート・フィーチャーとして、販売とプロモーションに関するデータが考えられます。 また、エネルギー消費量を予測するモデルでは、毎日の気温を含むため、予測の精度が向上します。
サポート・フィーチャーを使用するアルゴリズムおよびパイプライン
サポート機能を許可するのは、アルゴリズムのサブセットのみです。 例えば、Holt-winters と BATS は、サポート・フィーチャーの使用をサポートしません。 サポート機能をサポートしないアルゴリズムは、エクスペリメントの実行時にサポート機能の選択を無視します。
アルゴリズムによっては、アルゴリズムの特定のバリエーションに対してサポート機能を使用するものもあれば、サポート機能を使用しないものもあります。 例えば、RandomForestRegressorとExogenousRandomForestRegressor の2つの異なるパイプラインを生成できます。 ExogenousRandomForestRegressorのバリエーションは、RandomForestRegressorがそうでないのに対して、サポートする特徴のサポートを提供する。
この表では、アルゴリズムが時系列エクスペリメントでサポート・フィーチャーを提供するかどうかについて詳しく説明します。
| アルゴリズム | パイプライン | サポート・フィーチャーのサポートの提供 |
|---|---|---|
| ランダム・フォレスト | RandomForestRegressor | いいえ |
| ランダム・フォレスト | ExogenousRandomForestRegressor | はい |
| SVM | SVM | いいえ |
| SVM | ExogenousSVM | はい |
| アンサンブル | LocalizedFlattenEnsembler | はい |
| アンサンブル | DifferenceFlattenEnsembler | いいえ |
| アンサンブル | FlattenEnsembler | いいえ |
| アンサンブル | ExogenousLocalizedFlattenEnsembler | はい |
| アンサンブル | ExogenousDifferenceFlattenEnsembler | はい |
| アンサンブル | ExogenousFlattenEnsembler | はい |
| 回帰分析 | MT2RForecaster | いいえ |
| 回帰分析 | ExogenousMT2RForecaster | はい |
| Holt-Winters | HoltWinterAdditive | いいえ |
| Holt-Winters | HoltWinterMultiplicative | いいえ |
| BATS | BATS | いいえ |
| ARIMA | ARIMA | いいえ |
| ARIMA | ARIMAX | はい |
| ARIMA | ARIMAX_RSAR | はい |
| ARIMA | ARIMAX_PALR | はい |
| ARIMA | ARIMAX_RAR | はい |
| ARIMA | ARIMAX_DMLR | はい |
もっと見る
親トピック: 時系列エクスペリメントの作成