Détails de l'implémentation de série temporelle
Ces détails d'implémentation décrivent les étapes et le traitement spécifiques à une expérimentation de série temporelle AutoAI .
Détails de l'implémentation
Reportez-vous à ces détails d'implémentation et de configuration pour votre expérimentation de séries temporelles.
- Étapes des séries temporelles pour le traitement d'une expérimentation.
- Métriques d'optimisation de séries temporelles pour l'optimisation de vos pipelines.
- Algorithmes de série temporelle pour la génération des pipelines.
- Formats de date et d'heure pris en charge.
Etapes de série temporelle
Une expérimentation de série temporelle AutoAI inclut les étapes suivants lors de l'exécution d'une expérimentation :
- Initialisation
- Sélection de pipeline
- Evaluation du modèle
- Génération de pipelines définitifs
- Test rétro-actif de validité
Etape 1: Initialisation
L'étape d'initialisation traite les données d'entraînement dans l'ordre suivant :
- Chargement des données
- Fractionner le fichier L dans les données de formation T et les données d'éléments restants H
- Définissez la validation, le traitement des colonnes d'horodatage et la génération de la fenêtre de récupération des consultations. Remarques :
- Les données de formation (T) sont égales au fichier (F) moins l'élément restant (H). Lors de la configuration de l'expérimentation, vous pouvez ajuster la taille des données d'évaluation (holdout). Par défaut, la taille des données restantes est de 20 étapes.
- Vous pouvez éventuellement spécifier la colonne d'horodatage.
- Par défaut, une fenêtre de récupération des consultations est générée automatiquement en détectant la période saisonnière à l'aide de la méthode de traitement des signaux. Toutefois, si vous avez une idée d'une fenêtre appropriée de récupération des consultations, vous pouvez spécifier directement la valeur.
Etape 2: Sélection de pipeline
L'étape de sélection de pipeline utilise une méthode efficace appelée T-Daub (Time Series Data Allocation Using Upper Bounds). La méthode sélectionne les pipelines en allouant davantage de données d'apprentissage aux pipelines les plus prometteurs, tout en allouant moins de données d'apprentissage aux pipelines non prometteurs. Ainsi, tous les pipelines ne voient pas l'ensemble complet des données et le processus de sélection est généralement plus rapide. Les étapes suivantes décrivent la présentation du processus:
- Tous les pipelines sont alloués séquentiellement à plusieurs petits sous-ensembles de données d'apprentissage. Les données les plus récentes sont allouées en premier.
- Chaque pipeline est entraîné sur chaque sous-ensemble de données d'apprentissage alloué et évalué avec des données de test (données restantes).
- Un modèle de régression linéaire est appliqué à chaque pipeline à l'aide de l'ensemble de données décrit à l'étape précédente.
- Le score d'exactitude du pipeline est projeté sur l'ensemble des données d'apprentissage. Cette méthode génère un ensemble de données contenant la précision et la taille des données allouées pour chaque pipeline.
- Le meilleur pipeline est sélectionné en fonction de la précision projetée et du rang attribué 1.
- Davantage de données sont allouées au meilleur pipeline. Ensuite, la précision projetée est mise à jour pour les autres pipelines.
- Les deux étapes précédentes sont répétées jusqu'à ce que les N premiers pipelines soient entraînés sur toutes les données.
Etape 3: Evaluation du modèle
Dans cette étape, les pipelines gagnants N sont entraînés à nouveau sur l'ensemble de données d'apprentissage T. De plus, ils sont évalués avec les données restantes H.
Etape 4: Génération de pipeline finale
Dans cette étape, les pipelines gagnants sont reformés sur l'ensemble du fichier (L) et générés en tant que pipelines finaux.
Au fur et à mesure que le réentraînement de chaque pipeline se termine, le pipeline est posté dans le tableau de classement. Vous pouvez choisir d'inspecter les détails du pipeline ou d'enregistrer le pipeline en tant que modèle.
Etape 5: Backtest
Dans l'étape finale, les pipelines gagnants sont réentraînés et évalués à l'aide de la méthode de backtest. Les étapes suivantes décrivent la méthode backtest:
- La longueur des données d'entraînement est déterminée par le nombre de tests rétro-actifs de validité (backtests), la longueur de l'écart et la taille des données de validation (holdout, éléments restants). Pour en savoir plus sur ces paramètres, voir Génération d'une expérimentation de série temporelle.
- A partir des données les plus anciennes, l'expérimentation est entraînée à l'aide des données d'apprentissage.
- De plus, l'expérience est évaluée sur le premier jeu de données de validation. Si la longueur de l'écart est différente de zéro, toutes les données de l'écart sont ignorées.
- La fenêtre des données d'entraînement est avancée en augmentant la taille de l'élément restant et la longueur de l'écart pour former un nouvel ensemble d'entraînement.
- Une nouvelle expérimentation est entraînée avec ces nouvelles données et évaluée avec le jeu de données de validation suivant.
- Les deux étapes précédentes sont répétées pour les périodes de contre-essais restantes.
Métriques d'optimisation de séries temporelles
Acceptez la métrique par défaut ou choisissez une métrique à optimiser pour votre expérimentation.
| Métrique | Descriptif |
|---|---|
| Erreur absolue moyenne en pourcentage symétrique (SMAPE) | A chaque point ajusté, la différence absolue entre la valeur réelle et la valeur prédite est divisée par la moitié de la somme de la valeur réelle absolue et de la valeur prédite. Ensuite, la moyenne est calculée pour toutes ces valeurs sur tous les points ajustés. |
| Erreur absolue moyenne (MAE) | Moyenne des différences absolues entre les valeurs réelles et les valeurs prédites. |
| Racine de l'erreur quadratique moyenne (RMSE, Root Mean Squared Error) | Racine carrée de la moyenne des carrés des différences entre les valeurs réelles et les valeurs prédites. |
| R2 | Mesure de la comparaison des performances du modèle avec le modèle de référence ou le modèle moyen. Le R2 doit être égal ou inférieur à 1. Une valeur R2 négative signifie que le modèle considéré est pire que le modèle moyen. La valeur zéro R2 signifie que le modèle considéré est aussi bon ou mauvais que le modèle moyen. Une valeur R2 positive signifie que le modèle considéré est meilleur que le modèle moyen. |
Examen des métriques d'une expérimentation
Lorsque vous affichez les résultats d'une expérimentation de série temporelle, vous voyez les valeurs des métriques utilisées pour entraîner l'expérimentation dans le tableau de classement du pipeline:
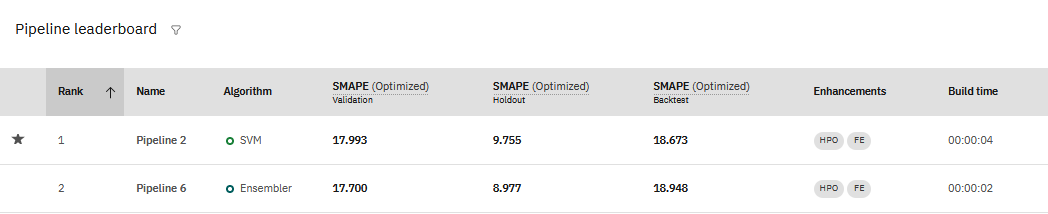
Vous pouvez voir que les mesures de précision pour les expériences de séries temporelles peuvent varier considérablement, en fonction des données d'expérimentation évaluées.
- La validation est le score calculé sur les données d'apprentissage.
- La rétention est le score calculé sur les données de rétention réservées.
- Backtest est le score moyen de tous les scores de backtests.
Algorithmes de série temporelle
Ces algorithmes sont disponibles pour votre expérimentation de série temporelle. Vous pouvez utiliser les algorithmes sélectionnés par défaut ou configurer votre expérimentation pour inclure ou exclure des algorithmes spécifiques.
| Algorithme | Descriptif |
|---|---|
| ARIMA | Le modèle ARIMA (Autoregressive Integrated Moving Average) est un modèle de série temporelle typique qui peut transformer des données non stationnaires en données stationnaires par le biais de la différenciation, puis prévoir la valeur suivante à l'aide des valeurs passées, y compris les valeurs décalées et les erreurs de prévision décalées |
| BATS | L'algorithme BATS combine la transformation de Box-Cox, les résidus ARMA, les facteurs de tendance et de saisonnalité pour prévoir les valeurs futures. |
| Ensembler | Ensembler combine plusieurs méthodes de prévision pour surmonter l'exactitude de la prévision simple et éviter un surajustement éventuel. |
| Holt-Winters | Utilise le lissage exponentiel triple pour prévoir les points de données d'une série, si la série est répétitive dans le temps (saisonnière). Deux types de modèles Holt-Winters sont fournis : Holt-Winters additif et Holt-Winters multiplicatif. |
| Forêt aléatoire | Modèle de régression basée sur l'arbre dans lequel chaque arbre de l'ensemble est construit à partir d'un échantillon qui est dessiné avec remplacement (par exemple, un échantillon de bootstrap) à partir de l'ensemble d'apprentissage. |
| Support Vector Machine (SVM) | Les machines virtuelles sont un type de modèle d'apprentissage automatique qui peut être utilisé à la fois pour la régression et la classification. Les machines virtuelles utilisent un hyperplan pour diviser les données en classes distinctes. |
| Régression linéaire | Crée une relation linéaire entre la variable de série temporelle et l'index de date / heure ou d'heure avec les résidus qui suivent le processus AR. |
Formats de date et d'heure pris en charge
Les formats de date / heure pris en charge dans les expérimentations de séries temporelles sont basés sur les définitions fournies par dateutil.
Les formats de date pris en charge sont :
Fréquents :
YYYY YYYY-MM, YYYY/MM, or YYYYMM YYYY-MM-DD or YYYYMMDD mm/dd/yyyy mm-dd-yyyy JAN YYYY
Peu fréquents :
YYYY-Www or YYYYWww - ISO week (day defaults to 0) YYYY-Www-D or YYYYWwwD - ISO week and day
Le nombre pour les valeurs de semaine et de jour ISO suit la même logique que datetime.date.isocalendar().
Les formats d'heure pris en charge sont :
hh hh:mm or hhmm hh:mm:ss or hhmmss hh:mm:ss.ssssss (Up to 6 sub-second digits) dd-MMM yyyy/mm
Remarques :
- Minuit peut être représenté au format 00:00 ou 24:00. Le séparateur décimal peut être un point ou une virgule.
- Les dates peuvent être soumises sous forme de chaînes, avec des guillemets, tels que "1958-01-16".
Fonctions de support
Les fonctions de support, également appelées fonctions exogènes, sont des fonctions d'entrée qui peuvent influencer la cible de prévision. Vous pouvez utiliser des fonctions de prise en charge pour inclure des colonnes supplémentaires de votre jeu de données afin d'améliorer la prévision et d'augmenter la précision de votre modèle. Par exemple, dans une expérimentation de série temporelle pour prévoir les prix dans le temps, une fonction de support peut être des données sur les ventes et les promotions. Ou bien, dans un modèle qui prévoit la consommation d'énergie, y compris la température quotidienne, la prévision est plus précise.
Algorithmes et pipelines qui utilisent les fonctions de prise en charge
Seul un sous-ensemble d'algorithmes autorise les fonctions de prise en charge. Par exemple, les Holt-Winters et les BATS ne prennent pas en charge l'utilisation des fonctions de prise en charge. Les algorithmes qui ne prennent pas en charge les fonctions de prise en charge ignorent votre sélection pour les fonctions de prise en charge lorsque vous exécutez l'expérimentation.
Certains algorithmes utilisent des fonctions de prise en charge pour certaines variantes de l'algorithme, mais pas pour d'autres. Par exemple, vous pouvez générer deux pipelines différents avec l'algorithme Random Forest, RandomForestRegressor et ExogenousRandomForestRegressor. La variation ExogenousRandomForestRegressor prend en charge les caractéristiques de soutien, ce qui n'est pas le cas de RandomForestRegressor.
Ce tableau indique si un algorithme prend en charge les fonctions de prise en charge dans une expérimentation de série temporelle:
| Algorithme | Pipeline | Prise en charge des fonctions de prise en charge |
|---|---|---|
| Forêt aléatoire | RandomForestRegressor | Non |
| Forêt aléatoire | ExogenousRandomForestRegressor | Oui |
| SVM | SVM | Non |
| SVM | ExogenousSVM | Oui |
| Ensembler | LocalizedFlattenEnsembler | Oui |
| Ensembler | DifferenceFlattenEnsembler | Non |
| Ensembler | FlattenEnsembler | Non |
| Ensembler | ExogenousLocalizedFlattenEnsembler | Oui |
| Ensembler | ExogenousDifferenceFlattenEnsembler | Oui |
| Ensembler | ExogenousFlattenEnsembler | Oui |
| Régression | MT2RForecaster | Non |
| Régression | ExogenousMT2RForecaster | Oui |
| Holt-Winters | HoltWinterAdditive | Non |
| Holt-Winters | HoltWinterMultiplicative | Non |
| BATS | BATS | Non |
| ARIMA | ARIMA | Non |
| ARIMA | ARIMAX | Oui |
| ARIMA | ARIMAX_RSAR | Oui |
| ARIMA | ARIMAX_PALR | Oui |
| ARIMA | ARIMAX_RAR | Oui |
| ARIMA | ARIMAX_DMLR | Oui |
En savoir plus
Evaluation d'un modèle de série temporelle
Rubrique parent: Génération d'une expérimentation de série temporelle