Translation not up to date
Użyj funkcji analizy tekstu AutoAI, aby przeprowadzić analizę tekstu na temat eksperymentów. Na przykład: wykonaj podstawową analizę sentymentu, aby przewidzieć wynik w oparciu o komentarze tekstowe.
Przegląd analizy tekstu
Podczas tworzenia eksperymentu, który korzysta z funkcji analizy tekstu, proces AutoAI korzysta z algorytmu word2vec do transformowania tekstu w wektory, a następnie porównuje wektory w celu określenia wpływu na kolumnę predykcji.
Algorytm word2vec przyjmuje korpus tekstu jako dane wejściowe i wyprowadza zestaw wektorów. Zamieniając tekst w liczbową reprezentację, może wykrywać i porównywać podobne słowa. Podczas szkolenia z wystarczającą ilością danych program word2vec może wprowadzać dokładne predykcje dotyczące znaczenia słowa lub związku z innymi słowami. Predykcje mogą być używane do analizy tekstu i odgadnienia w znaczeniu w aplikacjach do analizy sentymentu.
Podczas fazy inżynierii składowej szkolenia eksperymentu generowane są 20 funkcji dla kolumny tekstowej, za pomocą algorytmu word2vec . Automatyczne wykrywanie funkcji tekstu jest oparte na analizie liczby unikalnych wartości w kolumnie oraz liczby tokenów w rekordzie (minimalna liczba elementów = 3). Jeśli liczba unikalnych wartości jest mniejsza niż liczba wszystkich wartości podzielonych przez 5, to kolumna nie jest traktowana jako tekst.
Po zakończeniu eksperymentu można przejrzeć wyniki prac inżynierskich z poziomu strony szczegółów potoku. Można również zapisać potok jako notatnik, w którym można przejrzeć transformacje i zobaczyć wizualizację transformacji.
Przykład: analizowanie komentarzy klientów
W tym przykładzie komentarze dotyczące fikcyjnej wypożyczalni samochodów są używane do uczenia modelu, który przewiduje ocenę satysfakcji w momencie wprowadzania nowego komentarza.
Obejrzyj ten krótki film, aby zobaczyć ten przykład, a następnie przeczytaj więcej szczegółów na temat funkcji tekstu poniżej filmu wideo.
Ten film wideo udostępnia metodę wizualną, która umożliwia poznanie pojęć i zadań w tej dokumentacji.
Zapis wideo Czas Transkrypcja 00:00 W tym filmie wideo można zobaczyć, jak utworzyć eksperyment AutoAI w celu wykonania analizy sentymentu w pliku tekstowym. 00:09 W celu wykonania analizy tekstu w eksperymentach można użyć inżynierii funkcji tekstu. 00:15 Na przykład: wykonaj podstawową analizę sentymentu, aby przewidzieć wynik w oparciu o komentarze tekstowe. 00:22 Rozpocznij w projekcie i dodaj zasób aplikacyjny do tego projektu, a następnie nowy eksperyment AutoAI . 00:29 Wystarczy podać nazwę, opis, wybrać usługę uczenia maszynowego, a następnie utworzyć eksperyment. 00:38 Po wyświetleniu programu budującego eksperymenty AutoAI można dodać zestaw danych. 00:43 W tym przypadku zestaw danych jest już zapisany w projekcie jako zasób danych. 00:48 Wybierz zasób aplikacyjny, który ma zostać dodany do eksperymentu. 00:53 Przed wykonaniem dalszych czynności wyświetl podgląd danych. 00:56 Ten zestaw danych ma dwie kolumny. 00:59 Pierwsza zawiera komentarze klientów, a druga-0, dla "Niespełnione", lub 1, dla "Spełnione". 01:08 To nie jest prognoza szeregów czasowych, więc wybierz "Nie" dla tej opcji. 01:13 Następnie wybierz kolumnę do przewidzenia, co w tym przykładzie jest "Zadowolenie". 01:19 AutoAI określa, że kolumna zadowolenia zawiera dwie możliwe wartości, dzięki czemu jest ona odpowiednia dla modelu klasyfikacji binarnej. 01:28 A dodatnia klasa to 1, dla "Zadowolony". 01:32 Otwórz ustawienia eksperymentu, jeśli chcesz dostosować eksperyment. 01:36 Na panelu źródła danych zostaną wyświetlone opcje dotyczące inżynierii funkcji tekstu. 01:41 Można automatycznie wybrać kolumny tekstowe lub większą kontrolę, określając kolumny dla inżynierii funkcji tekstu ręcznie. 01:52 Można również wybrać liczbę wektorów, które mają zostać utworzone dla każdej kolumny podczas projektowania funkcji tekstu. 01:58 Niższa liczba szybciej i wyższa liczba jest bardziej dokładna, ale wolniejsza. 02:03 Teraz uruchom eksperyment, aby wyświetlić transformacje i postęp. 02:09 Podczas tworzenia eksperymentu, który korzysta z funkcji analizy tekstu, proces AutoAI korzysta z algorytmu word2vec do transformowania tekstu w wektory, a następnie porównuje wektory w celu określenia wpływu na kolumnę predykcji. 02:23 Podczas fazy projektowania funkcji szkolenia eksperymentu generowane są dwadzieścia elementów dla kolumny tekstowej za pomocą algorytmu word2vec . 02:33 Po zakończeniu eksperymentu można przejrzeć wyniki prac inżynierskich z poziomu strony szczegółów potoku. 02:40 Na panelu podsumowania składników można przejrzeć transformacje tekstu. 02:45 Można zauważyć, że funkcja AutoAI stworzyła kilka funkcji tekstu, stosując funkcję algorytmu do elementów kolumn, wraz z znaczeniem funkcji pokazując, które funkcje wnoszą najwięcej do danych wyjściowych predykcji. 02:59 Ten potok można zapisać jako model lub jako notatnik. 03:03 Notatnik zawiera kod, aby zobaczyć transformacje i wizualizacje tych transformacji. 03:09 W tym przypadku należy utworzyć model. 03:13 Użyj odsyłacza, aby wyświetlić model. 03:16 Teraz należy awansować model do miejsca wdrożenia. 03:23 Poniżej przedstawiono szczegóły modelu, a z tego miejsca można wdrożyć model. 03:28 W tym przypadku będzie to wdrożenie on-line. 03:36 Po zakończeniu tego procesu otwórz wdrożenie. 03:39 W aplikacji testowej można określić jeden lub więcej komentarzy do analizy. 03:46 Następnie kliknij opcję "Predict". 03:49 Przewiduje się, że pierwszy klient nie będzie zadowolony z usługi. 03:54 I przewiduje się, że drugi klient będzie zadowolony z usługi. 03:59 Więcej filmów wideo można znaleźć w dokumentacji Cloud Pak for Data as a Service .
Biorąc pod uwagę zestaw danych zawierający kolumnę komentarzy do recenzji (Customer_service) oraz kolumnę, która zawiera binarną ocenę satysfakcji (Zadowolenie), gdzie 0 oznacza negatywny komentarz, a 1 oznacza pozytywny komentarz, eksperyment jest przeszkolony w celu przewidywania oceny satysfakcji w momencie wprowadzenia nowych informacji zwrotnych.
Szkolenie eksperymentu transformacji tekstowej
Po załadowaniu zestawu danych i określeniu kolumny predykcji (Zadowolenie) w polu Ustawienia eksperymentu zostanie wybrana opcja Użyj inżynierii składnika tekstu .
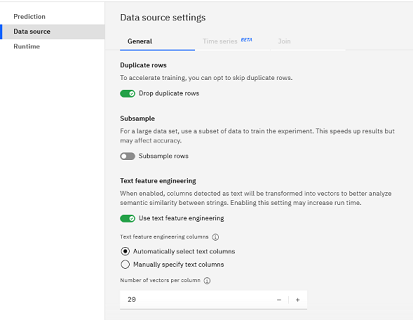
Należy zwrócić uwagę na niektóre szczegóły dotyczące strojenia eksperymentu analizy tekstu:
- Użytkownik może zaakceptować domyślny wybór automatycznego wybierania kolumn tekstu lub wykonywać większą kontrolę poprzez ręczne określanie kolumn dla inżynierii elementów tekstowych.
- Po uruchomieniu eksperymentu dla kolumny tekstowej zostanie wygenerowana domyślna wartość 20 opcji przy użyciu algorytmu
word2vec. Istnieje możliwość edytowania tej wartości w celu zwiększenia lub zmniejszenia liczby składników. Im więcej wektorów, które generujesz tym bardziej dokładny model, są, ale dłuższe szkolenie takess. - Pozostała część opcji odnosi się do wszystkich typów eksperymentów, dzięki czemu można precyzyjnie dostosować sposób obsługi końcowych danych treningowych.
Uruchom eksperyment, aby wyświetlić transformacje w toku.
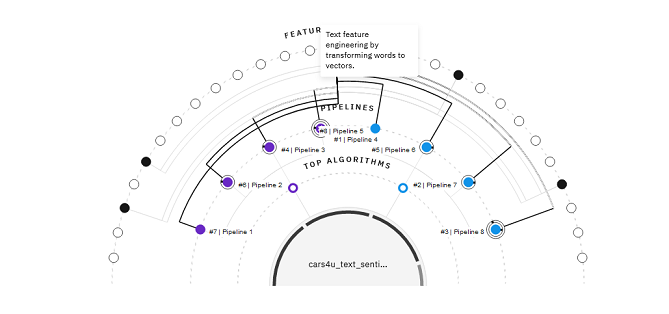
Wybierz nazwę potoku, a następnie kliknij opcję Podsumowanie funkcji , aby przejrzeć transformacje tekstu.
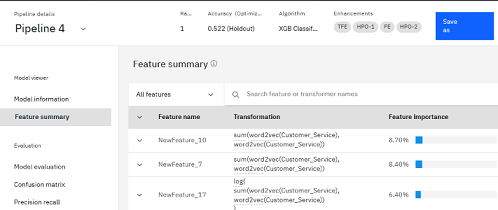
Potok eksperymentu można również zapisać jako notatnik i przejrzeć transformacje jako wizualizację.
Wdrażanie i ocenianie modelu transformacji tekstu
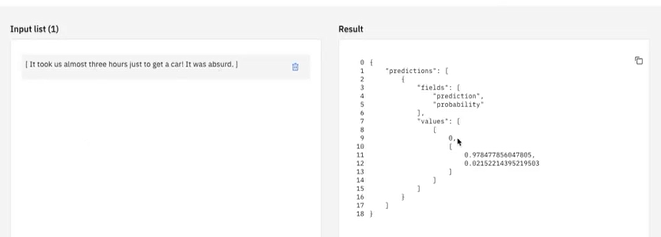
Podczas oceniania tego modelu należy wprowadzić nowe komentarze, aby uzyskać predykcję z zaufaniem dla tego, czy komentarz jest wynikiem pozytywnej lub ujemnej oceny satysfakcji.
Na przykład, wkraczając na komentarz " To zajęło nam prawie trzy godziny, aby dostać samochód. To było absurdalne " prognozuje ocenę satysfakcji z 0 z wynikiem ufności 95%.
Następne kroki
Tworzenie eksperymentu prognozy serii czasowych
Temat nadrzędny: Budowanie modelu AutoAI