AutoAIてRAG(Retrieval-augmented generation)実験を行う。 ドキュメントのコレクションをアップロードし、大規模な言語モデルの出力を改善するために使用できるベクトルに変換します。 最適化されたパイプラインを比較し、アプリケーションに最適なRAGパターンを選択します。
データソースの準備
RAG実験を作成する前に、文書コレクションとデータ資産を準備します。 この文書コレクションは、即座に入力される回答の背景情報を提供します。 評価データは、RAGパターンのパフォーマンスを測定するために使用するサンプル質問と回答のJSONファイルです。
データ収集の準備として、以下のガイドラインに従ってください:
- ドキュメントコレクションのサポートされているフォーマット:PDF、HTML、DOCX、MD、またはプレーンテキスト
- 評価データファイルのサポート形式:JSON
JSON評価ファイルのテンプレート
評価データファイルは、RAGパターンのパフォーマンスを評価するための一連のサンプル問題と正解を提供します。 JSONファイルにはこのフォーマットを使用する:
[
{
"question": "<text>",
"correct_answer": "<text>",
"correct_answer_document_ids": [
"<file>",
"<file>"
]
},
{
"question": "<text>",
"correct_answer": "<text>",
"correct_answer_document_ids": [
"<file>",
"<file>"
]
},
{
"question": "<text>",
"correct_answer": "<text>",
"correct_answer_document_ids": [
"<file>",
"<file>"
]
}
]
例えば、以下はwatsonx.ai Pythonライブラリのドキュメントで学習したパターンの質問と回答のサンプルです。
[
{
"question": "What foundation models are available in watsonx.ai?",
"correct_answer": "The following models are available in watsonx.ai: \nflan-t5-xl-3b\nFlan-t5-xxl-11b\nflan-ul2-20b\ngpt-neox-20b\ngranite-13b-chat-v2\ngranite-13b-chat-v1\ngranite-13b-instruct-v2\ngranite-13b-instruct-v1\nllama-2-13b-chat\nllama-2-70b-chat\nmpt-7b-instruct2\nmt0-xxl-13b\nstarcoder-15.5b",
"correct_answer_document_ids": [
"5B37710FE7BBD6EFB842FEB7B49B036302E18F81_0.txt"
]
},
{
"question": "What foundation models are available on Watsonx, and which of these has IBM built?",
"correct_answer": "The following foundation models are available on Watsonx:\n\n1. flan-t5-xl-3b\n2. flan-t5-xxl-11b\n3. flan-ul2-20b\n4. gpt-neox-20b\n5. granite-13b-chat-v2 (IBM built)\n6. granite-13b-chat-v1 (IBM built)\n7. granite-13b-instruct-v2 (IBM built)\n8. granite-13b-instruct-v1 (IBM built)\n9. llama-2-13b-chat\n10. llama-2-70b-chat\n11. mpt-7b-instruct2\n12. mt0-xxl-13b\n13. starcoder-15.5b\n\n The Granite family of foundation models, including granite-13b-chat-v2, granite-13b-chat-v1, and granite-13b-instruct-v2 has been build by IBM.",
"correct_answer_document_ids": [
"5B37710FE7BBD6EFB842FEB7B49B036302E18F81_0.txt",
"B2593108FA446C4B4B0EF5ADC2CD5D9585B0B63C_0.txt"
]
},
{
"question": "What is greedy decoding?",
"correct_answer": "Greedy decoding produces output that closely matches the most common language in the model's pretraining data and in your prompt text, which is desirable in less creative or fact-based use cases. A weakness of greedy decoding is that it can cause repetitive loops in the generated output.",
"correct_answer_document_ids": [
"42AE491240EF740E6A8C5CF32B817E606F554E49_1.txt"
]
},
{
"question": "When to tune a foundation model?",
"correct_answer": "Tune a foundation model when you want to do the following things:\n\nReduce the cost of inferencing at scale\nGet the model's output to use a certain style or format\nImprove the model's performance by teaching the model a specialized task\nGenerate output in a reliable form in response to zero-shot prompts\"",
"correct_answer_document_ids": [
"FBC3C5F81D060CD996489B772ABAC886F12130A3_0.txt"
]
},
{
"question": "What tuning parameters are available for IBM foundation models?",
"correct_answer": "Tuning parameter values for IBM foundation models:\nInitialization method\ninitialization text\nbatch_size\naccumulate_steps\nlearning_rate\nnum_epochs\"",
"correct_answer_document_ids": [
"51747F17F413F1F34CFD73D170DE392D874D03DD_2.txt"
]
},
{
"question": "How do I avoid generating personal information with foundation models?",
"correct_answer": "To exclude personal information, try these techniques:\n- In your prompt, instruct the model to refrain from mentioning names, contact details, or personal information.\n- In your larger application, pipeline, or solution, post-process the content that is generated by the foundation model to find and remove personal information.\"",
"correct_answer_document_ids": [
"E59B59312D1EB3B2BA78D7E78993883BB3784C2B_4.txt"
]
},
{
"question": "What is Watson OpenScale?",
"correct_answer": "Watson OpenScale is a tool that helps organizations evaluate and monitor the performance of their AI models. It tracks and measures outcomes from AI models, and helps ensure that they remain fair, explainable, and compliant no matter where the models were built or are running. Watson OpenScale also detects and helps correct the drift in accuracy when an AI model is in production.",
"correct_answer_document_ids": [
"777F72F32FD20E96C4A5F0CCA461FE9A79334E96_0.txt"
]
}
]
ベクターストアの選択
ベクトル化されたドキュメントは、質問と回答プロセスのコンテンツの保存と検索に使用されるデータベースに保存する場所を提供する必要があります。 利用可能なデータベースオプションの詳細については、ベクターストアの選択を参照してください。
- デフォルトのメモリ内Chromaデータベースは、実験を実行するための一時的なベクターストアである。 この指数は実験終了後も持続しないので、本番での使用には向かない。
- 恒久的なベクターストアが必要な場合は、 Milvus データベースに接続するか、セットアップしてください。 RAGパターンを展開する予定がある場合は、このオプションを使用する。 詳細は、 watsonx.data Milvus ベクターストアの設定を参照してください
Milvus ベクターストアに接続するには、一般的な Milvus 一般的なコネクタタイプ、または watsonx.data Milvus コネクタを選択できます。
このビデオでAutoAIRAG実験の作成方法をご覧ください。
このビデオは、このドキュメントのコンセプトとタスクを学ぶための視覚的な方法を提供します。
AutoAIRAG実験の作成
以下の手順に従って、デフォルトのコンフィギュレーション設定をfastpathとして使用して、ユースケースに最適なRAGパターンを検索する実験を定義し、実行します。
- watsonx.aiのウェルカムページまたはプロジェクトの新規アセットページから、AI ソリューションを自動的に構築するをクリックします。
- 実験のタイプとしてBuild a RAG solutionを選択する。
- 文書収集と評価データのアップロードまたは接続。 ドキュメントコレクションに最大20個のドキュメントフォルダとファイルを選択します。 評価データファイルは単一のJSONファイルでなければなりません。
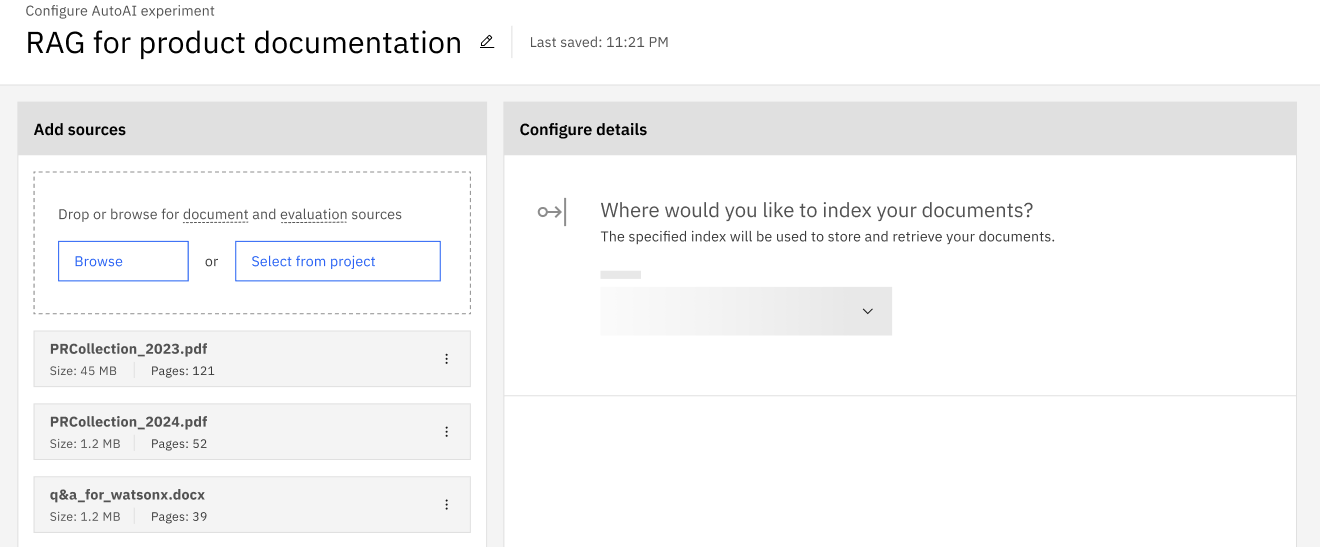
- ドキュメントコレクションのベクトルベースインデックスを保存する場所を選択します。
- 実験結果を評価するためのベンチマークデータとして使用するJSONファイルを指定します。
- Run experiment をクリックすると、デフォルト設定で RAG パイプラインが作成されます:
- 最適化されたメトリック:アンサー忠実度メトリックのRAGパターンの作成を最適化する。
- 考慮するモデル:デフォルトのAll model typesは、RAGパターンを生成するために利用可能なすべての基礎モデルを考慮する。
実験の設定は、使用するケースに合わせてカスタマイズできる。 RAG実験設定のカスタマイズを参照。
結果の表示
以下のツールを使って進捗状況を確認し、結果をレビューする。
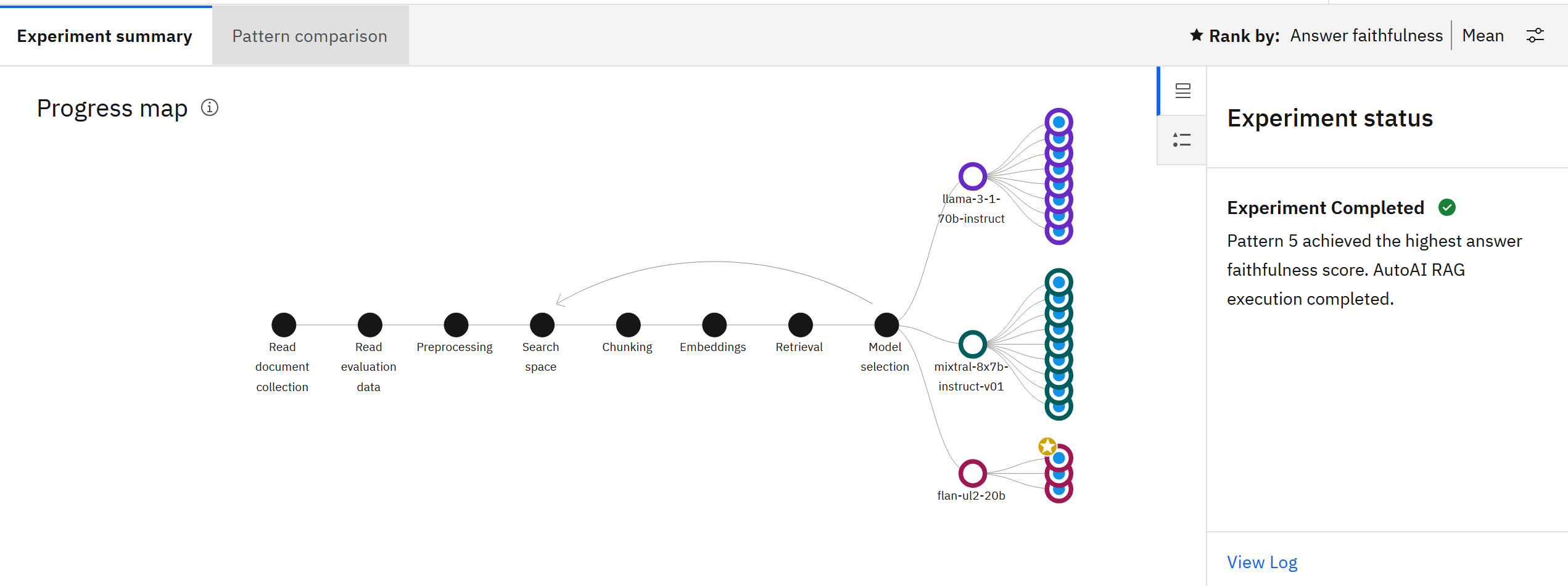
実験が実行されると、進捗マップがパイプラインがどのように作成され、最適化されたかを視覚化する。 ノードにカーソルを合わせると、詳細が表示されます。
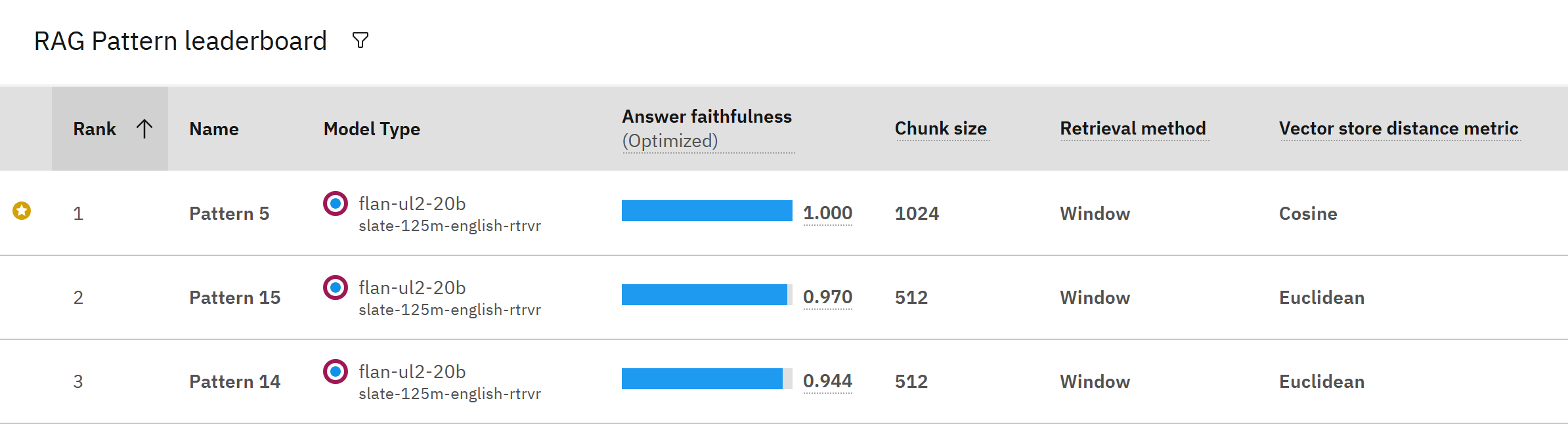
実験が完了したら、最適化されたメトリックの結果に従ってランク付けされた実験パイプラインを表示するリーダーボードを確認する。
パイプライン名をクリックすると詳細が表示されます。 サンプルの質問と回答に対して評価された、パイプラインのさまざまな測定基準のスコアを確認します。
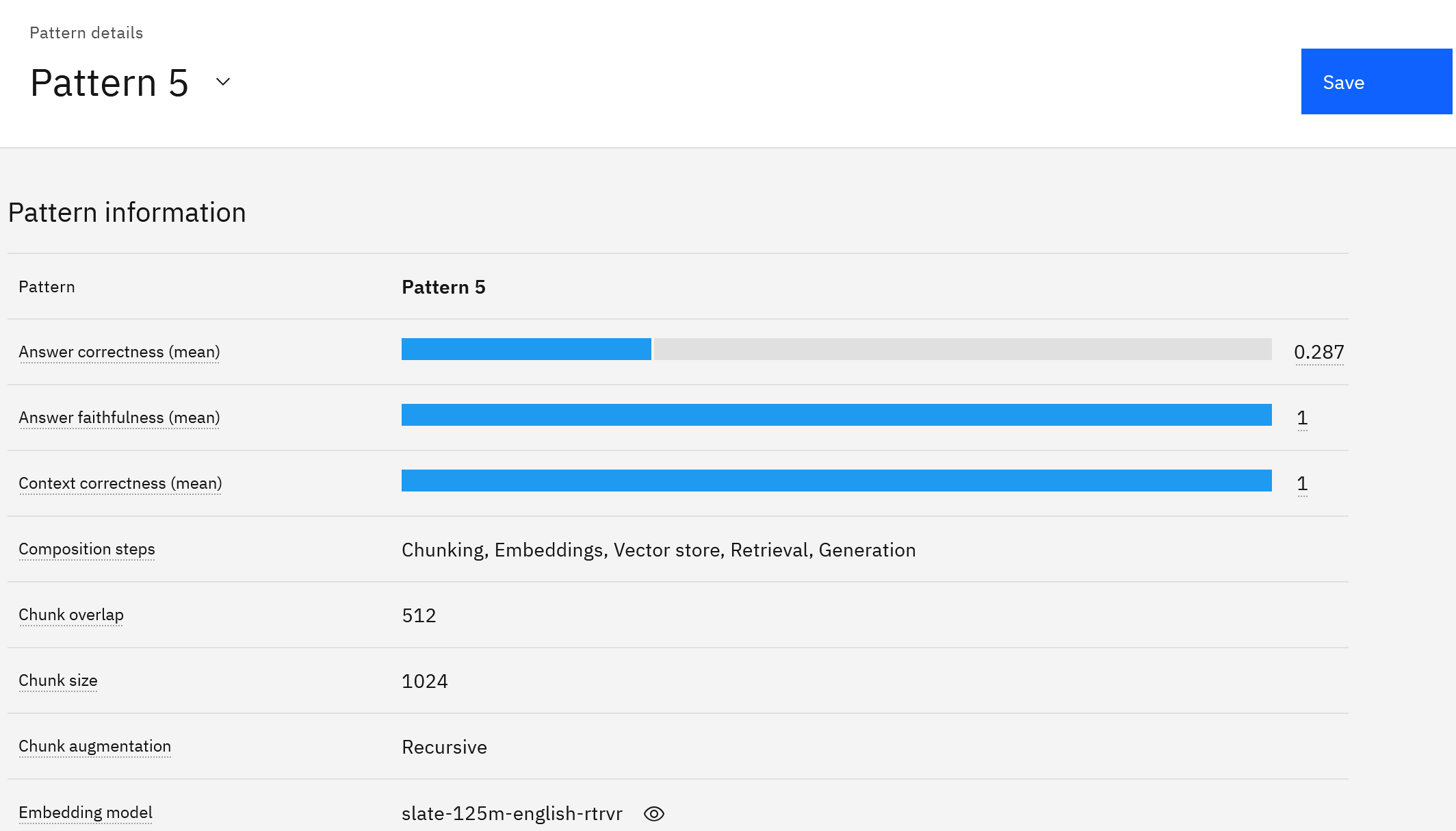
分析が完了したら、「保存」をクリックすると、RAGパターンのテストや使用に使用できるノートブック資産が自動的に生成されます。
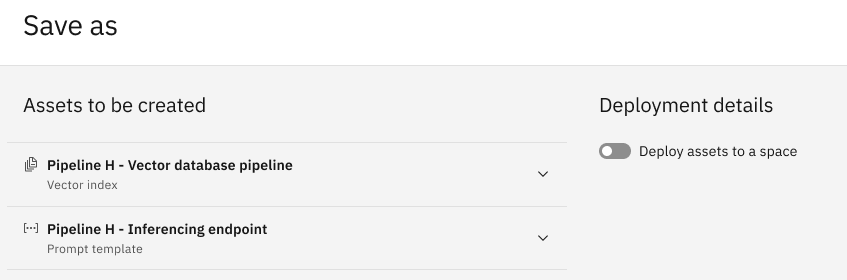
出来上がったノートブックを見直し、実行し、RAGパターンをテストまたは使用する。 詳細は、 RAGパターンの保存を参照してください。
今後のステップ
- コンフィギュレーションオプションを編集するには、RAG実験設定のカスタマイズを参照のこと。
- パターンを分析するには、AutoAIRAGパターンの詳細を参照してください。
- RAGパターンを保存して使用するには 、「RAGパターンの保存」 を参照してください。
親トピック AutoAIでRAG実験を構築する