当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
AutoAI エクスペリメントへの公平性テストの適用
最終更新: 2024年11月28日
実験の公平性を評価して、あるグループの結果が別のグループの結果よりも偏っていないことを確認します。
制限
時系列実験では公平性評価はサポートされていません。
公平性のための実験とモデルの評価
エクスペリメントを定義し、機械学習モデルを生成する場合、結果の信頼性とバイアスがないことを確認する必要があります。 トレーニング中にモデルが誤ったレッスンを学習すると、機械学習モデルのバイアスが発生する可能性があります。 このシナリオは、モデルが予測を生成するときに、データが不十分であるか、データの収集または管理が不十分な結果になる場合に発生する可能性があります。 バイアスの兆候がないか実験を評価して、必要に応じてそれらを修復し、モデルの結果に対する信頼性を構築することが重要です。
AutoAI には、バイアスの実験を評価して修復するのに役立つ以下のツール、手法、および機能が含まれています。
定義と用語
公平性属性 -通常、バイアスまたは公平性は、性別、民族性、年齢などの公平性属性を使用して測定されます。
モニター/参照グループ -モニター対象グループは、バイアスを測定する公平性属性の値です。 モニター対象グループの値は、参照グループの値と比較されます。 例えば、 Fairness Attribute=Gender
好ましい結果/好ましくない結果 -バイアス検出の重要な概念は、モデルの好ましい結果と好ましくない結果の概念です。 例えば、 Claim approvedClaim denied
異種の影響 -バイアスを測定するために使用されるメトリック (参照グループの好ましい結果のパーセンテージに対する、モニター対象グループの好ましい結果のパーセンテージの比率として計算されます)。 バイアスは、異種の影響値が指定されたしきい値より小さい場合に存在すると考えられます。
例えば、男性の保険金請求の 80% が承認されているが、女性の保険金請求の 60% のみが承認されている場合、異なる影響は次のようになります: 60/80 = 0.75。 通常、バイアスのしきい値は 0.8 です。 この異なる影響率は 0.8 未満であるため、モデルはバイアスがあると見なされます。
異種の影響率が 1.25 [逆の値 (1/disparate 影響) がしきい値 0.8] より大きい場合も、バイアスがあると見なされることに注意してください。
公平性の評価と向上に関するビデオをご覧ください。
このビデオを視聴して、公平性について機械学習モデルを評価し、結果に偏りがないことを確認する方法を確認してください。
このビデオは、本書の概念とタスクを学習するためのビジュアル・メソッドを提供します。
UI での AutoAI エクスペリメントの公平性テストの適用
Experiment settingsを開きます。
公平性 タブをクリックしてください。
公平性のオプションを有効にします。 オプションは以下のとおりです。
- 公平性評価: 異なる影響率を計算して各パイプラインのバイアスを検査するには、このオプションを有効にします。 このメソッドは、パイプライン・シューズが、あるグループに対して別のグループよりも好ましい (優先される) 結果を提供する傾向があるかどうかを追跡します。
- 公平性しきい値: 公平性しきい値を設定して、異種の影響率の値に基づいて、パイプラインにバイアスが存在するかどうかを判別します。 デフォルトは 80 です。これは、異なる影響の比率が 0.80未満であることを表します。
- 好ましい結果: 好ましいと見なされる値を予測列から指定します。 例えば、値は「approved」、「accepted」、または予測タイプに適合するものなどです。
- 自動保護属性メソッド: バイアスの潜在的な原因である特徴量を評価する方法を選択してください。 自動検出を指定できます。この場合、 AutoAI は一般的に保護されている属性 (性別、民族性、婚姻状況、年齢、郵便番号など) を検出します。 各カテゴリー内で、AutoAI は保護されたグループを判別しようとします。 例えば、
sexfemale
注: 自動モードでは、フィーチャーが英語以外の言語などの標準的でない値を持つ場合、そのフィーチャーは保護属性として正しく識別されない可能性があります。 自動検出は英語でのみサポートされます。- 手動保護属性メソッド: 結果を手動で指定し、属性のリストから選択して保護属性を指定します。 属性を手動で指定する場合は、グループを定義し、そのグループが予期される結果 (参照グループ) を持つ可能性が高いかどうか、または予期される結果 (モニター対象グループ) との差異を検出するために検討する必要があるかどうかを指定する必要があります。
例えば、次の画像は、モニター用に手動で指定された属性グループのセットを示しています。
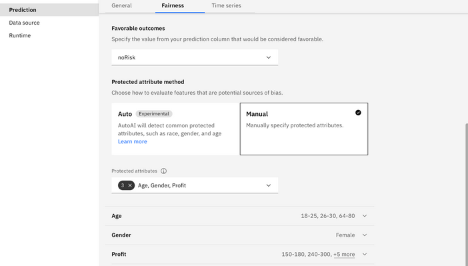
設定を保存して適用し、エクスペリメントを実行して公平性評価をパイプラインに適用します。
注:
- マルチクラス・モデルの場合、予測列で複数の値を選択して、適切かどうかを分類できます。
- 回帰モデルの場合、好ましい結果または好ましくない結果と見なされる結果の範囲を指定できます。
- 公平性評価は、現在、時系列実験では使用できません。
公平性を測定するために自動的に検出される属性のリスト
自動検出が有効になっている場合、以下の属性がトレーニング・データに存在すると、 AutoAI によって自動的に検出されます。 属性は英語でなければなりません。
- エージングを行う
- 市民状況
- color
- 身体障害
- 人種
- 性別
- 遺伝情報
- ハンディキャップ
- 言語
- 婚姻関係
- 政治的信念
- pregnancy
- 宗教
- 退役軍人の状況
ノートブックでの AutoAI エクスペリメントの公平性テストの適用
ノートブックでトレーニングされた AutoAI エクスペリメントで公平性テストを実行し、UI で提供されている機能を超えて機能を拡張することができます。
バイアス検出の例
この例では、watsonx.aiRuntimePythonAPI (ibm-watson-machine-learning) を使って、バイアス検出のためのオプティマイザ設定を以下の入力で設定する:
- 名前 - エクスペリメント名
- prediction_type - 問題のタイプ
- prediction_column - ターゲット列名
- fairness_info - バイアス検出構成
fairness_info = {
"protected_attributes": [
{
"feature": "personal_status",
"reference_group": ["male div/sep", "male mar/wid", "male single"],
"monitored_group": ["female div/dep/mar"]
},
{
"feature": "age",
"reference_group": [[26, 100]],
"monitored_group": [[1, 25]]}
],
"favorable_labels": ["good"],
"unfavorable_labels": ["bad"],
}
from ibm_watson_machine_learning.experiment import AutoAI
experiment = AutoAI(wml_credentials, space_id=space_id)
pipeline_optimizer = experiment.optimizer(
name='Credit Risk Prediction and bias detection - AutoAI',
prediction_type=AutoAI.PredictionType.BINARY,
prediction_column='class',
scoring='accuracy',
fairness_info=fairness_info,
retrain_on_holdout=False
)
結果の評価
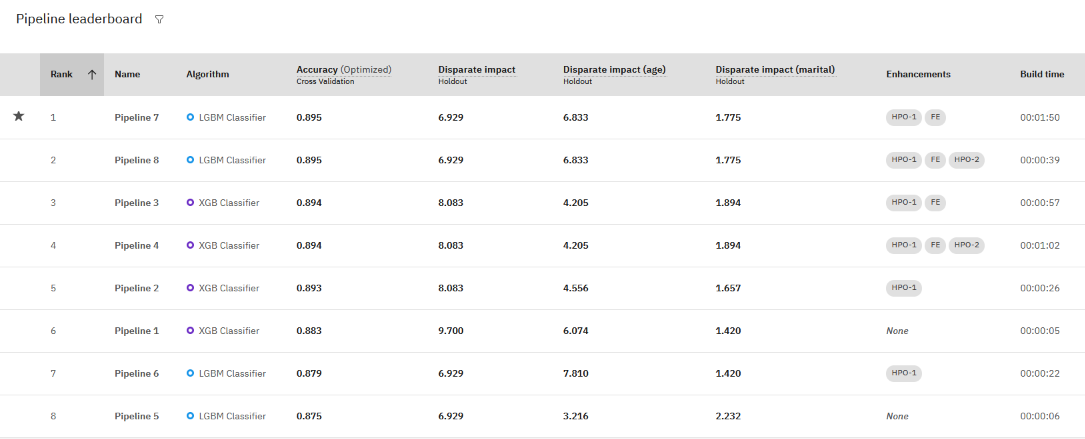
各パイプラインの評価結果を表示できます。
- エクスペリメントの要約 ページで、パイプライン・リーダーボードのフィルター・アイコンをクリックしてください。
- エクスペリメントの異種影響メトリックを選択してください。 このオプションは、モニター対象グループごとに 1 つの一般メトリックと 1 つのメトリックを評価します。
- 異なる影響についてパイプラインの評価指標を確認して、バイアスに問題があるかどうかを判断するか、公平性評価のためにどのパイプラインのパフォーマンスが向上しているかを判断します。
この例では、正確さのために最初にランク付けされたパイプラインにも、許容限度内の異種の所得スコアがあります。
バイアス緩和
実験でバイアスが検出された場合、"combined scorers "を使って実験を最適化することで、バイアスを軽減することができます: accuracy_and_disparate_impactr2_and_disparate_impact
検索および最適化のプロセスでは、公正で正確なモデルを返すために、結合されたスコアが使用されます。
例えば、分類エクスペリメントのバイアス検出を最適化するには、以下のようにします。
- Experiment settingsを開きます。
- 「予測 (Predictions)」 ページで、エクスペリメントの 「正確度と異種の影響 (Accuracy and disparate impact)」 を最適化することを選択します。
- エクスペリメントを再実行します。
「正確度と異種の影響」 指標は、分類実験の正確度と公平性の結合スコアを作成します。 スコアが高いほど、パフォーマンスと公平性の指標が優れていることを示します。 異種の影響スコアが 0.9 から 1.11 (許容レベル) の間である場合、正解率スコアが返されます。 それ以外の場合は、正確度スコアより低い異種の影響値が返され、公平性のギャップを示す低い (負の) 値が返されます。
AutoAI におけるバイアス検出に関する Medium のブログポストをお読みください。
次のステップ
親トピック: AutoAI の概要
トピックは役に立ちましたか?
0/1000