ホテル満足度のテキスト分析
このチュートリアルでは、テキストの処理に特化したノードを使用してテキストを分析するのに役立ちます。 例えば、センチメント分析を行うことができる。
このチュートリアルでは、ホテルの支配人がホテルのレビューを分析し、顧客がどのように考えているかを見たいとします。 このレビューでは、ホテルの担当者、快適さ、清潔さ、価格、およびその他の関心分野についての意見が示されます。

チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足となることを目的としています。 このビデオでは、このドキュメントのコンセプトとタスクを視覚的に学習する方法を提供しています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足となることを目的としています。 このビデオでは、このドキュメントのコンセプトとタスクを視覚的に学習する方法を提供しています。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
このチュートリアルでは、サンプルプロジェクトのHotel Satisfactionフローを使用します。 このフローでは、Text Analytics ノードを使用して、ホテルに関する架空のレビューを分析します。 使用したデータファイルはhotelSatisfaction.csv である。 次の図は、モデラーのフロー例を示しています。
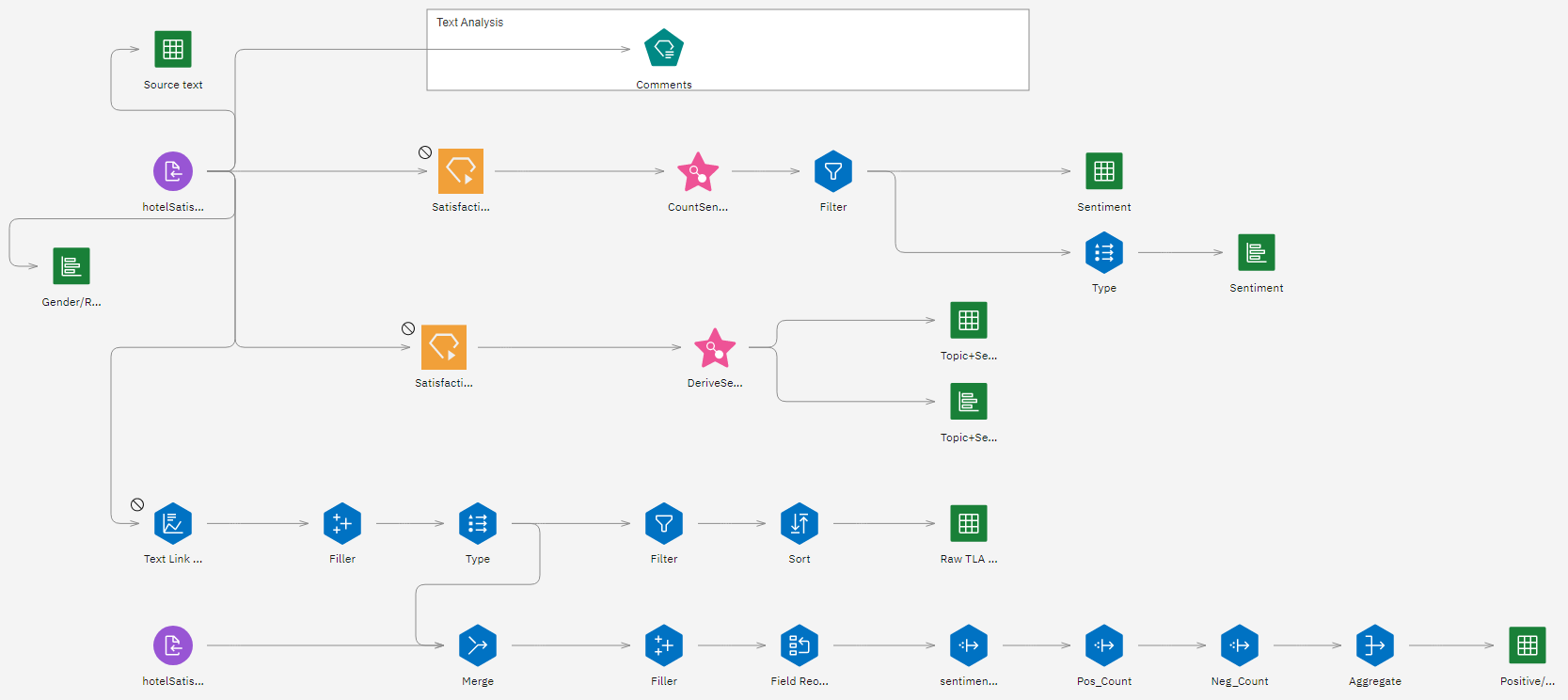
タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプルプロジェクトをまだお持ちでない場合は、 チュートリアルのトピックを参照してサンプルプロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataナビゲーションメニューから
 、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。
、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。 - SPSS ModelerProjectをクリックします。
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。

タスク2:データ資産ノードを調べる
ホテル満足度にはいくつかのノードがある。 以下の手順に従って、Data Assetノードを調べます:
- AssetsタブからHotel Satisfactionモデラーフローを開き、キャンバスがロードされるのを待ちます。
- hotelSatisfaction.csvノードをダブルクリックします。 このノードは、プロジェクト内のhotelSatisfaction.csvファイルを指すData Assetノードです。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、Data Assetノードを示しています。 これでText Miningノードを調べる準備ができた。

タスク3:テキストマイニングノードを調べる
テキストマイニングは、テキストデータから関連する概念やパターンを特定する反復プロセスである。 テキストマイニングノードを実行すると、抽出エンジンがテキストデータを読み取り、関連する概念を特定し、それぞれにタイプを割り当てます。 その後、Text Analytics Workbench を使用して抽出結果を確認し、抽出プロセスを微調整することができます。 テキストマイニングノードを再実行して新しい結果を出し、新しい結果を評価することができます。 Data Asset」ノードと「Text Mining」ノードの間に「Type」ノードがあることに注意する。 Typeノードは、データセットのフィールドを正しく識別するために必要である。 テキストマイニングノードを調べるには、以下の手順に従ってください:
- Comments (Text Mining)」ノードをダブルクリックしてプロパティを見る。
- Fieldsセクションでこれらのプロパティを設定する:
- テキスト・フィールドでは、「コメント」を選択する。
- IDフィールドには idを選択する。注: テキスト・フィールドのみが必須です。
図3: テキスト・マイニング・ノードのプロパティー 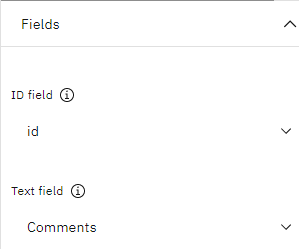
- モデル」セクションで、選択されたテキスト分析パッケージが「ホテル満足度(英語)/トピック+意見」であることに注目してください。
テキスト分析パッケージ(TAP)とは、あらかじめ定義されたライブラリや高度な言語的・非言語的リソースのセットであり、1つ以上のあらかじめ定義されたカテゴリのセットとバンドルされている。 アプリケーションに該当するテキスト分析パッケージがない場合、代わりにリソーステンプレートを選択することができます。 リソース・テンプレートとは、特定のドメインや用途に合わせて微調整された、定義済みのライブラリや高度な言語・非言語リソースのセットである。
- Build modelsセクションで、これらのプロパティを設定する:
- ビルド・モードフィールドが'インタラクティブに構築する(カテゴリーモデルナゲット)に設定されていることを確認する。 このオプションは、後でノードを実行するときにText Analytics Workbench を起動します。
- Begin session byフィールドがExtracting concepts and text linksに設定されていることを確認する。 概念抽出オプションは概念のみを抽出するのに対し、TLA抽出は概念と、トピック(サービス、人材、食事など)と意見のつながりであるテキストリンクの両方を出力する。
- Expert]セクションを展開し、[Accommodate spelling for minimum word character length]オプションが[Spelling limit]を '
5locationlocattoin図4: テキストマイニングノードエキスパートのプロパティ。 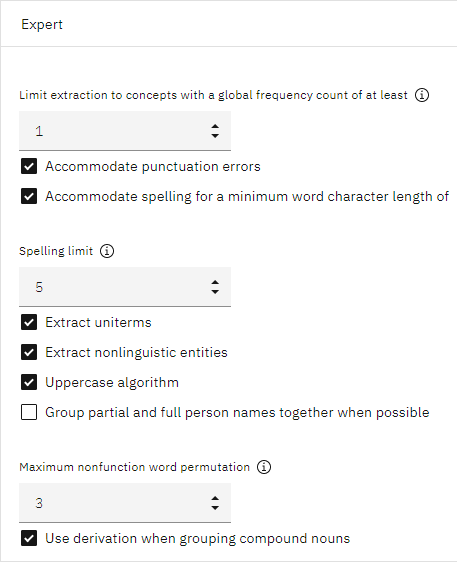
- 保存 をクリックします。
- 「コメント(テキストマイニング)」ノードにカーソルを合わせ 、「実行」アイコン
 をクリックします。
をクリックします。 - Outputs and models(出力とモデル)]ペインで、[Comments(コメント)]という名前の結果をクリックして、[Text Analytics Workbench(テキスト分析ワークベンチ)]を開きます。
![]() 進捗状況を確認する
進捗状況を確認する
次の画像はテキスト分析ワークベンチを示しています。 これで結果を調整する準備が整った。

タスク4:テキスト分析ワークベンチで結果を調整する
Text Analytics Workbenchには、抽出結果とテキスト分析パッケージに含まれるカテゴリモデルが含まれます。 これは、抽出された結果を探索し、微調整し、カテゴリーを構築し、洗練させ、カテゴリーモデルナゲットを構築することができるインタラクティブなワークベンチです。 以下の手順に従って、Text Analytics Workbenchで結果を調整します:
コンセプト
- コンセプト」タブをクリックする。
抽出プロセスでは、テキストデータを分析して、「
airportlocationairport pick-upこのようにして、1つの概念が複数の基礎となる用語を表すことがある。 それは、あなたの文章でその用語がどのように使われているか、また、あなたが使っている一連の言語資源によります。
- フィルタアイコンをクリックします。

- フィルタを使用して、概念のサブセットを選択することもできます。 次の画像は、さまざまなオプションを示しています:
図 5. テキスト分析ワークベンチ - フィルタオプション 
フィルターを取り除き、すべてのコンセプトを表示したい場合は、「フィルターをクリア」をクリックします。
キャンセル]をクリックして[フィルター]ペインを閉じます。
テキスト・リンク
- テキストリンク」タブをクリックする。
テキストリンク分析(TLA)はパターンマッチング技術で、TLAのルールと、テキストに含まれる抽出された概念や関係を比較します。 テキストリンク」タブでは、テキストデータから見つかったTLAパターンを構築し、探索することができます。
- タイプ・パターン(たとえば「<サービス>+<ポジティブ)を選択すると、文書内のテキストのプレビューが表示されます。 ドキュメントプレビューのテキストが途中で切れている場合は、 ドキュメント全体を表示するアイコン
 をクリックして、テキスト全体を表示します。
をクリックして、テキスト全体を表示します。
カテゴリ
- カテゴリー」タブをクリックする。
カテゴリーを作成し、管理することができます。 テキストデータから概念とタイプが抽出されたら、概念包含、意味ネットワーク(英語のみ)、または手動などのテクニックを使用して、自動的にカテゴリを構築し始めることができます。
このフロー例では、テキスト分析パッケージのテンプレートを使用しているため、カテゴリーモデルはすでに入力されています。
- すべてを採点する」をクリックすると、文書や記録に点数が付けられます。 カテゴリが作成または更新されるたびに、特定のカテゴリの記述子と一致するテキストがあるかどうかを確認できます。 合致が見つかった場合は、ドキュメントまたはレコードはそのカテゴリーに割り当てられます。 その結果、すべてではないにしても、ほとんどの文書や記録が、カテゴリー内の記述子に基づいてカテゴリーに割り当てられる。
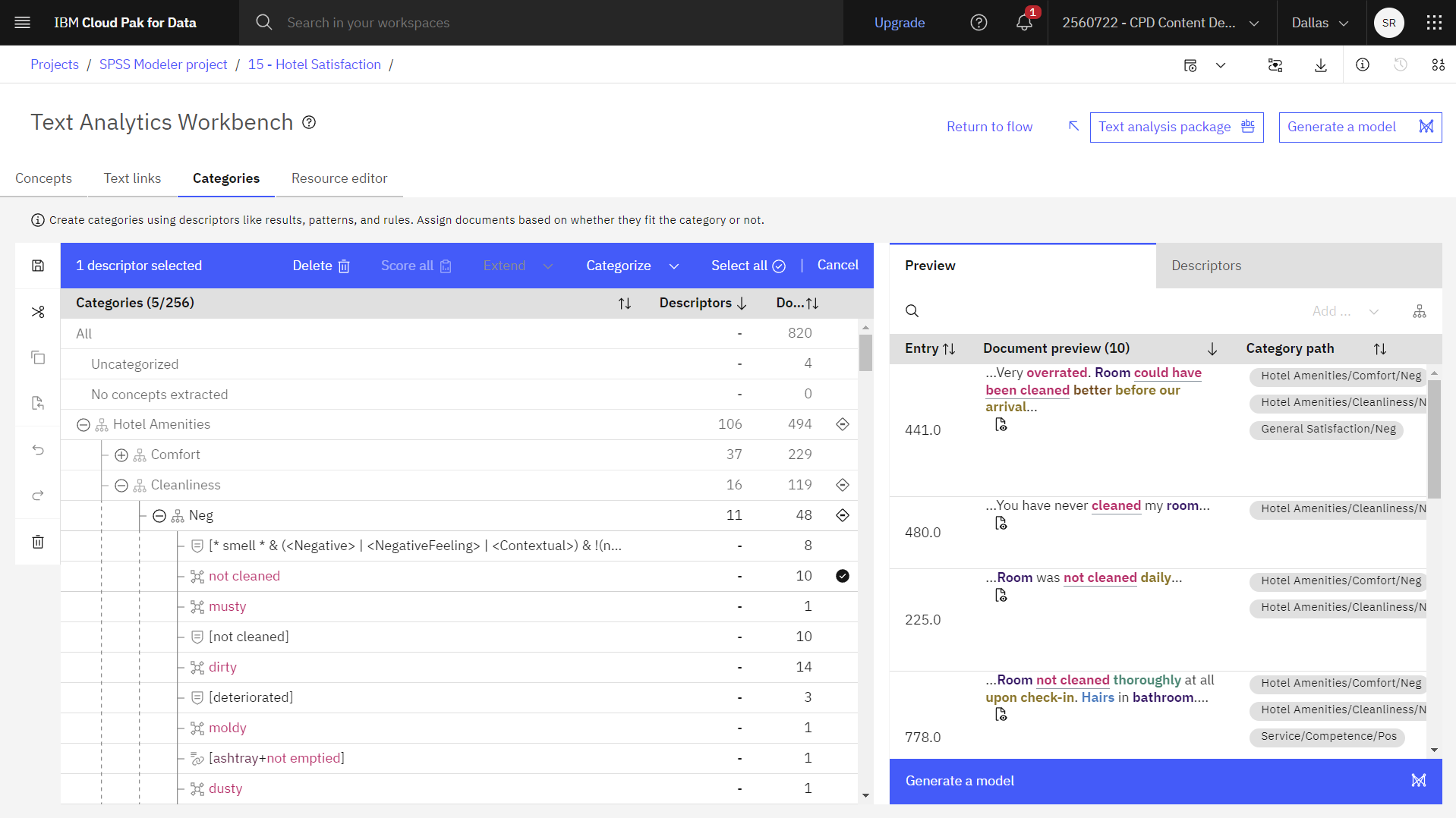
- 例えば、「ホテルのアメニティ」>「清潔さ」>「Neg」>「掃除されていない」のようにカテゴリーを展開する。
- プレビュー]タブと[説明]タブでドキュメントを表示し、ソースデータを確認します。
![]() 進捗状況を確認する
進捗状況を確認する
次の画像は、「清潔さ」カテゴリのドキュメントプレビューです。 これでモデルを作る準備ができた。
タスク5:モデルの構築
抽出プロセスのチューニングが完了したら、カスタマイズと構築したカテゴリからカテゴリモデルを生成できます。 以下の手順に従って、モデルを構築し、デプロイしてください:
- カテゴリー・モデルを生成するには、モデルを生成するをクリックします。

- Buildをクリックして、カテゴリーモデルを生成することを確認します。
- 成功だ!表示されたら メッセージが表示されたら、「フローに戻る」をクリックする。
- 保存して終了するをクリックして変更を保存し、'テキストマイニングノードをフローに入れる。生成されたカテゴリーモデルナゲットは、フローキャンバスに表示されます。
図 6. 生成されたカテゴリーモデルナゲット 
- フロー例の2つの満足度モデルノードに注目。 Text Analytics Workbenchが検証し、カテゴリーモデルを生成したので、それをフローに導入し、同じデータセットを採点するか、新しいデータを採点することができます。 各モデルで採点モードが異なる。
図 7. 2 つのモードでのスコアリングのサンプル・フロー 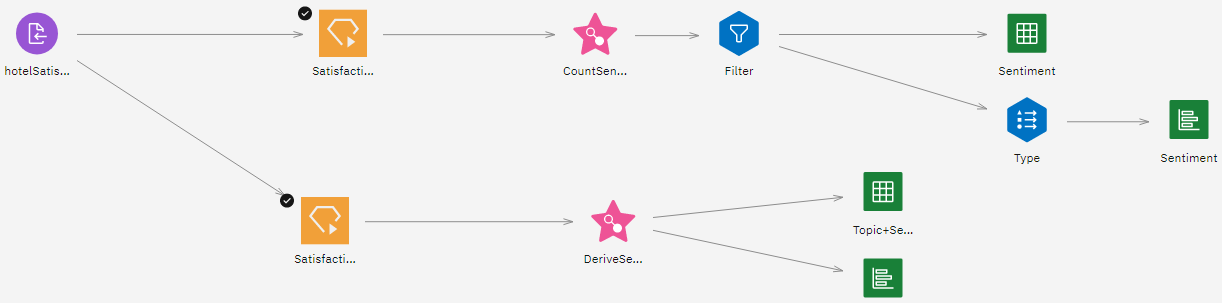
- 最初の満足度モデル・ノードをダブルクリックします。
- 設定]セクションを展開し、このノードが[カテゴリー]をフィールドのスコアリング・モードとして使用していることを確認します。 この採点モードでは、入力記録と同じ数の出力記録がある。
- データのプレビューをクリックする。 各レコードには、モデルタブで選択されたカテゴリーごとに1つの新しいフィールドが含まれていることがわかります。 フィールドごとに、true および false のフラグ値 (
True/False1/010図 8. モデル結果 - フィールドとしてのカテゴリー(1)。 
- 「プレビュー」ウィンドウを閉じます。
- 「キャンセル」をクリックします。
- 2番目の満足度モデル・ノードをダブルクリックします。
- 設定セクションを展開し、このノードがCategories as recordsスコアリングモードを使用していることを確認する。
category, document - データのプレビューをクリックする。 入力フィールドとともに、それがどのようなモデルであるかに応じて、新しいフィールドもデータに追加されているのがわかるだろう。
図 9. モデル結果 - レコードとしてのカテゴリー(2)。 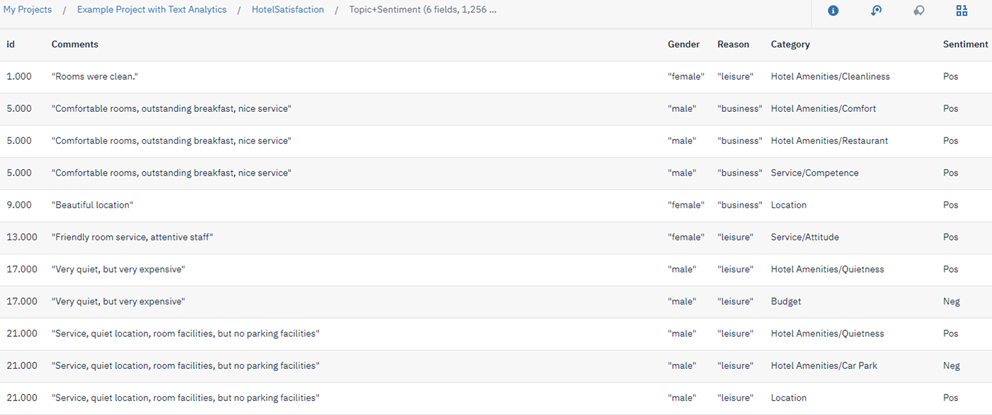
- 「プレビュー」ウィンドウを閉じます。
- 「キャンセル」をクリックします。
- 設定セクションを展開し、このノードがCategories as recordsスコアリングモードを使用していることを確認する。
![]() 進捗状況を確認する
進捗状況を確認する
次の画像は、ドキュメント・プレビュー付きの満足度モデルを示しています。 これでコメントを視覚化する準備が整った。
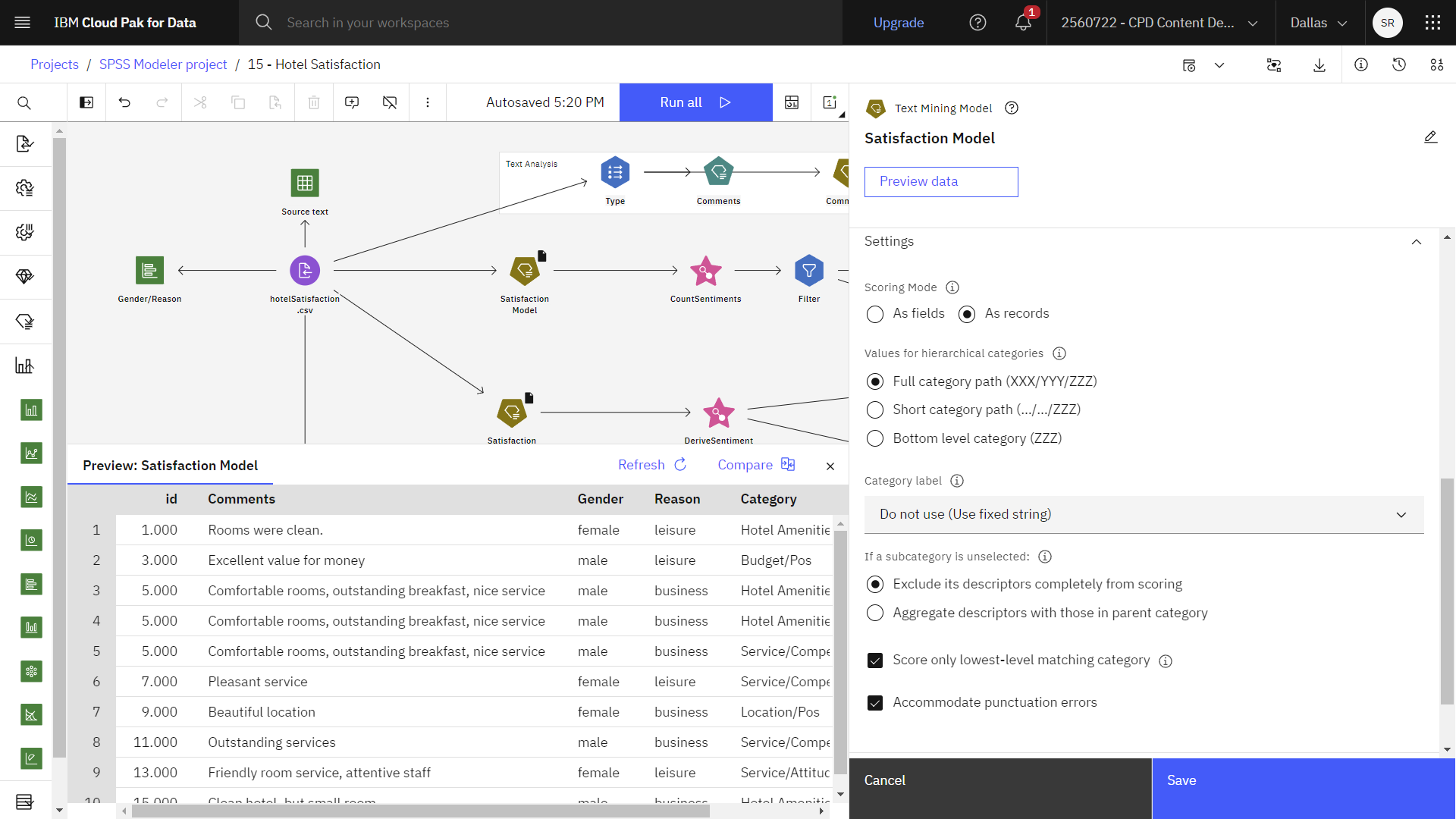
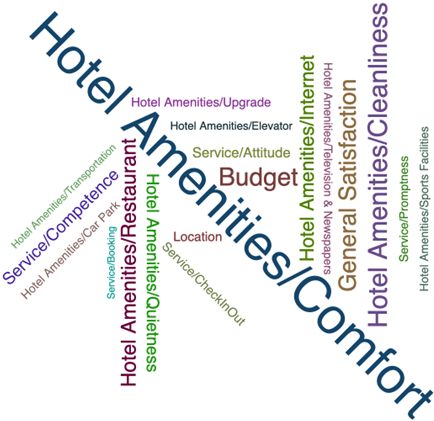
タスク6:コメントの可視化
コメントを可視化することで、ゲストがホテルについてどのような点を評価しているのかを素早く把握することができる。 以下の手順でワードクラウドチャートを作成します:
- 肯定的なコメントを選ぶ:
- パレットで、レコード操作セクションを展開する。
- Selectノードをキャンバスにドラッグします。
- センチメントの導出」スーパーノードを「選択」ノードに接続する。
- Selectノードをダブルクリックしてプロパティを表示します。
- Modeは Includeを選択。
- 条件には「
Sentiment = "Pos" - 保存 をクリックします。
- チャートを追加する:
- パレットで、グラフセクションを展開する。
- Chartsノードをキャンバスにドラッグします。
- SelectノードをChartsノードに接続する。
- ワードクラウドチャートを作成する:
- Chartsノードをダブルクリックしてプロパティを表示します。
- Launch Chart Builderをクリックする。
- 可視化する列で、「コメント」を選択する。
- すべてのチャートタイプのリストを表示し、ワードクラウドを選択します。
図 10. すべてのチャートタイプ 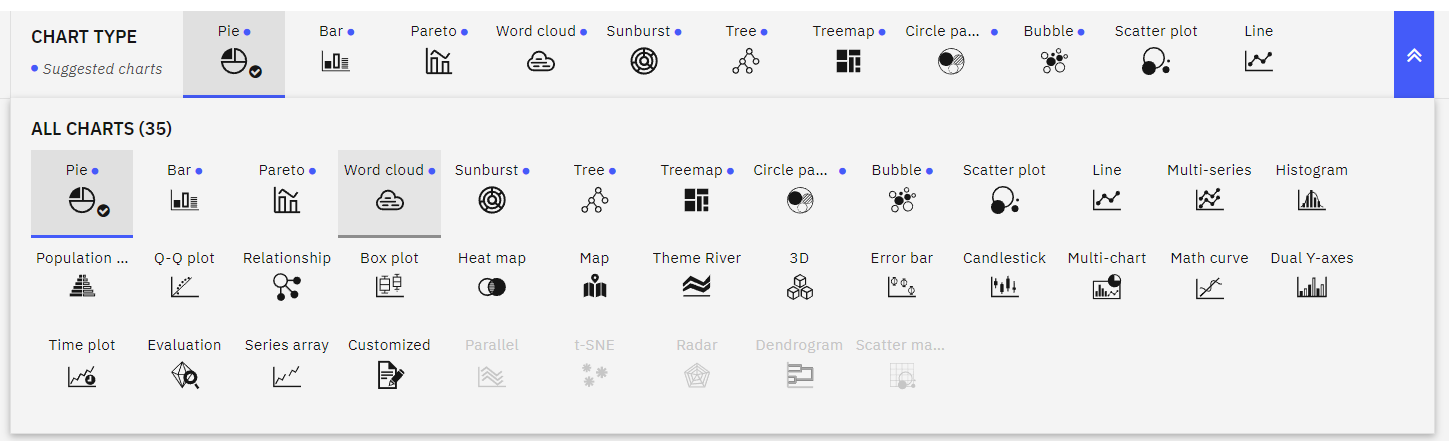
- 終了したら、「フローに戻る」をクリックする。
![]() 進捗状況を確認する
進捗状況を確認する
次の画像はワードクラウドチャートである。 これでテキストリンク分析ノードを調べる準備ができました。
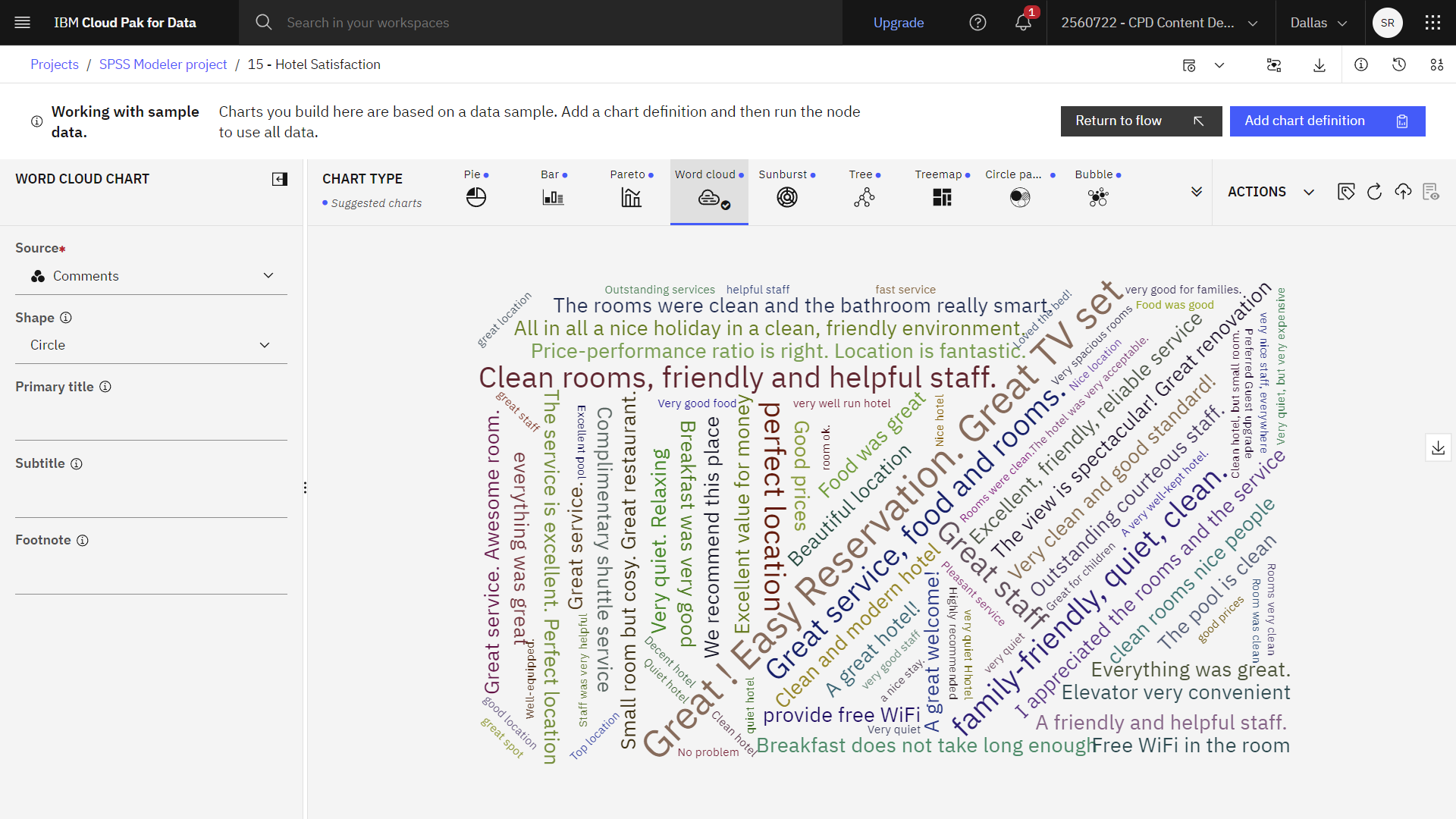
タスク 7:テキストリンク分析ノードを調べる
- テキスト・リンク分析」ノードをダブルクリックして、そのプロパティを表示します。
- Fieldsセクションでこれらのプロパティを設定する:
- テキスト・フィールドでは、「コメント」を選択する。
- IDフィールドには idを選択する。注: テキスト・フィールドのみが必須です。
図 11. テキストリンク分析ノードの FIELD プロパティ。 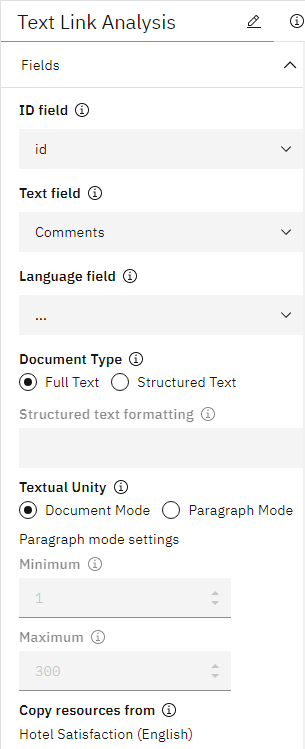
- リソースのコピー元セクションで、選択されているリソーステンプレートが「Hotel Satisfaction (English)」であることに注意してください。
リソース・テンプレートとは、特定のドメインや用途に合わせて微調整された、定義済みのライブラリや高度な言語・非言語リソースのセットである。
- Expert]セクションを展開し、[Accommodate spelling for minimum word character length]オプションが[Spelling limit]を '
5図 12. テキストリンク分析ノード Expert プロパティ。 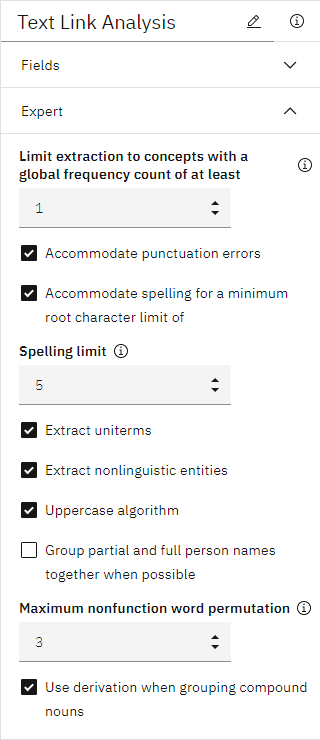
- 保存 をクリックします。
- Raw TLA出力ノードの上にカーソルを移動し、 実行アイコン をクリックします。
- Outputs and models"ペインで、"Raw TLA output "という名前の結果をクリックすると、結果が表示されます。
図 13. 生のTLA出力。 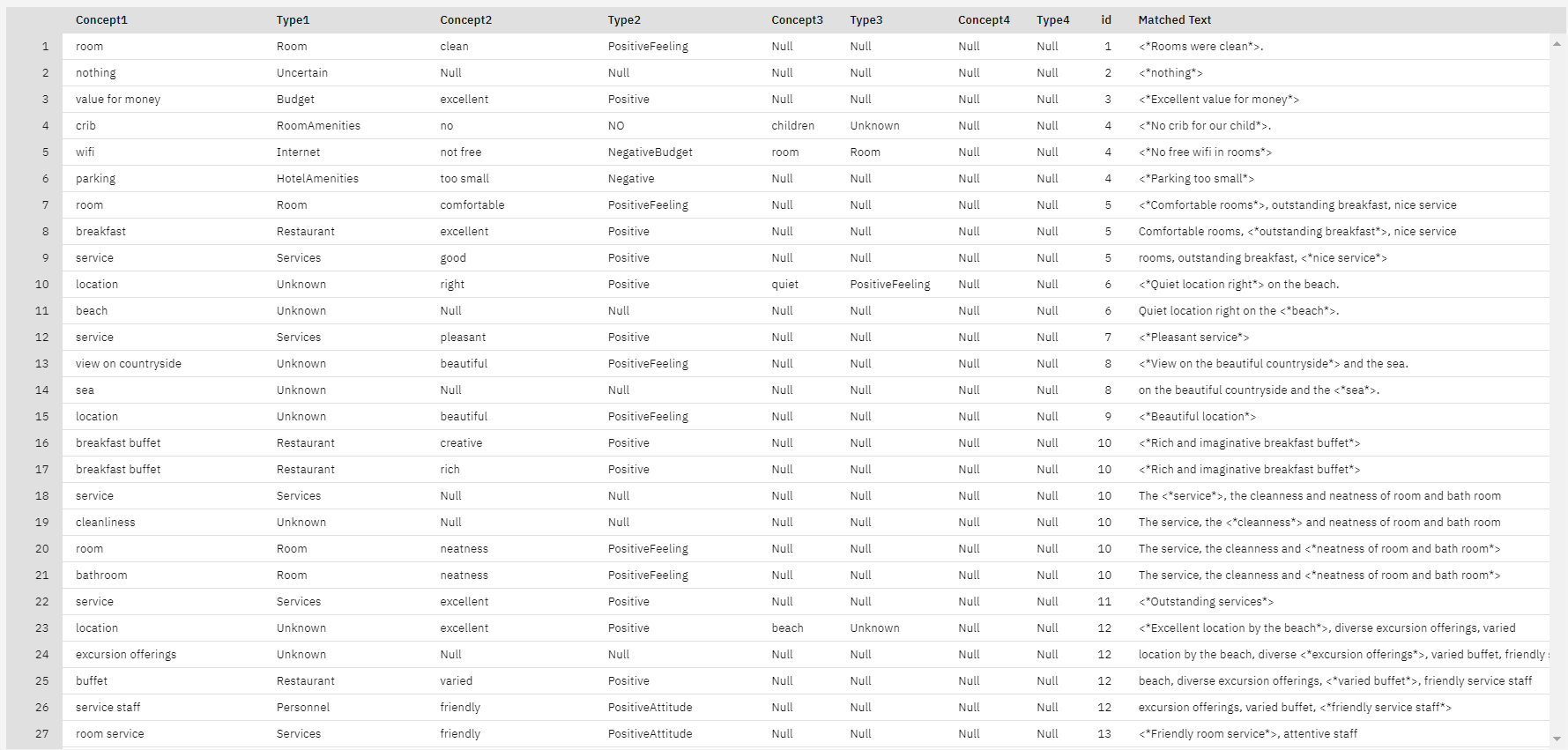
図 14. TLAノードでセンチメントをカウントする。 
![]() 進捗状況を確認する
進捗状況を確認する
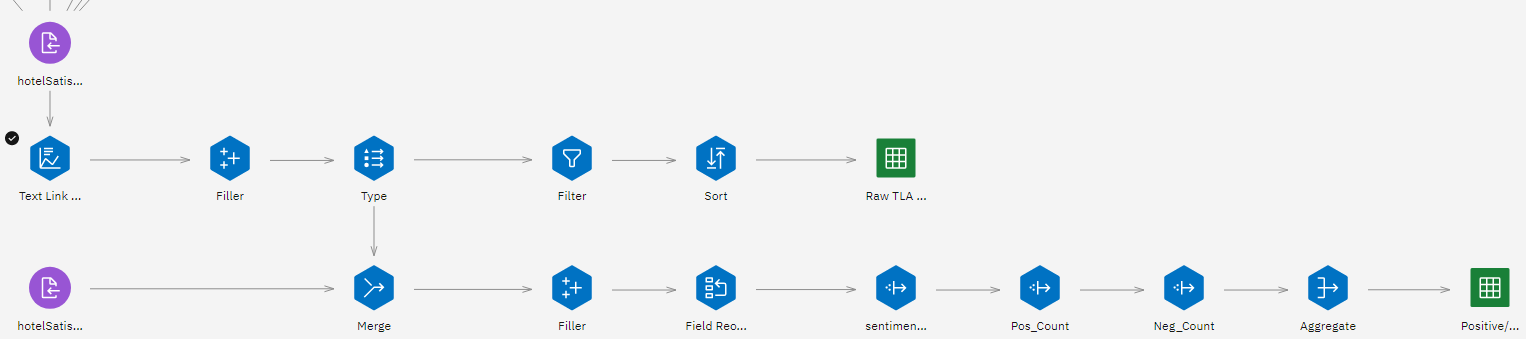
次の図は、完成したフローを示している。
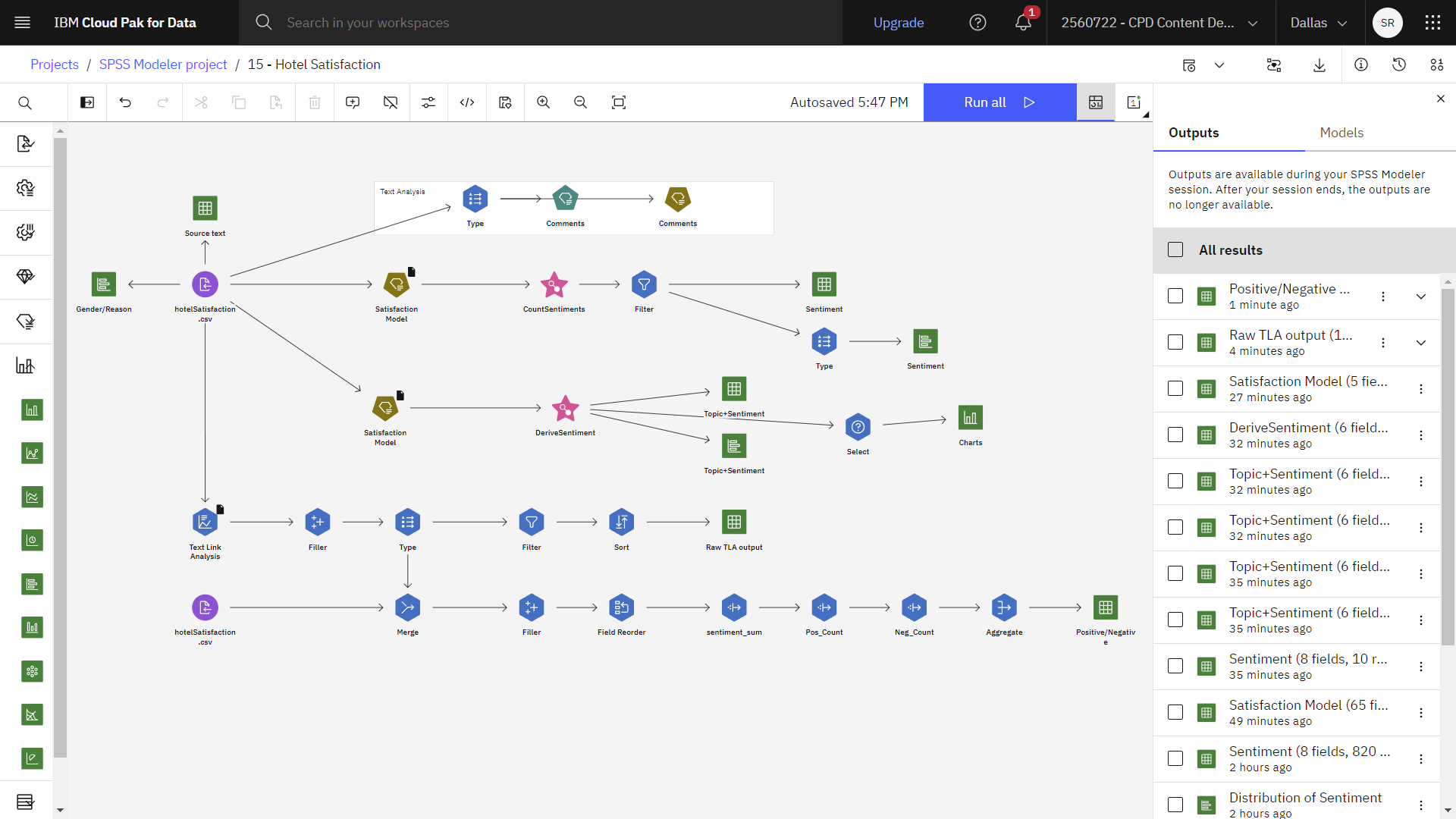
サマリー
このホテル満足度フローでは、ホテルのマネージャーがホテルのレビューを分析し、ホテルの従業員、快適さ、清潔さ、価格、その他関心のある分野についての顧客の意見を見る方法を紹介した。 このフローは、テキスト・マイニング・ノードまたはテキスト・リンク分析ノードを使用して、テキスト・データを分析する2つの方法を示している。
次のステップ
これで、他の SPSS® Modeler チュートリアルを試す準備ができました。