About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
資料の 英語版 に戻る
顧客にオファーを出す(自己学習)
図1: サンプルモデラーの流れ 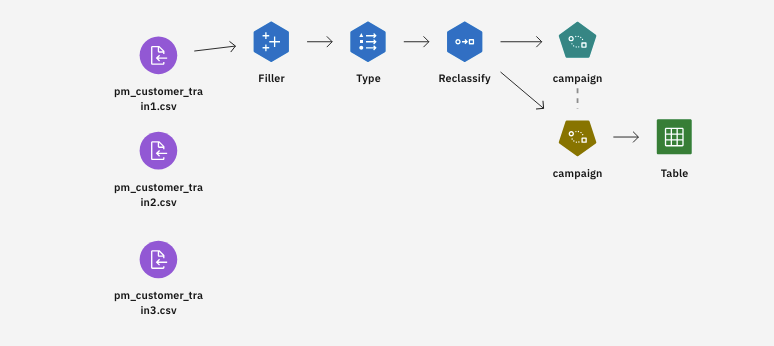
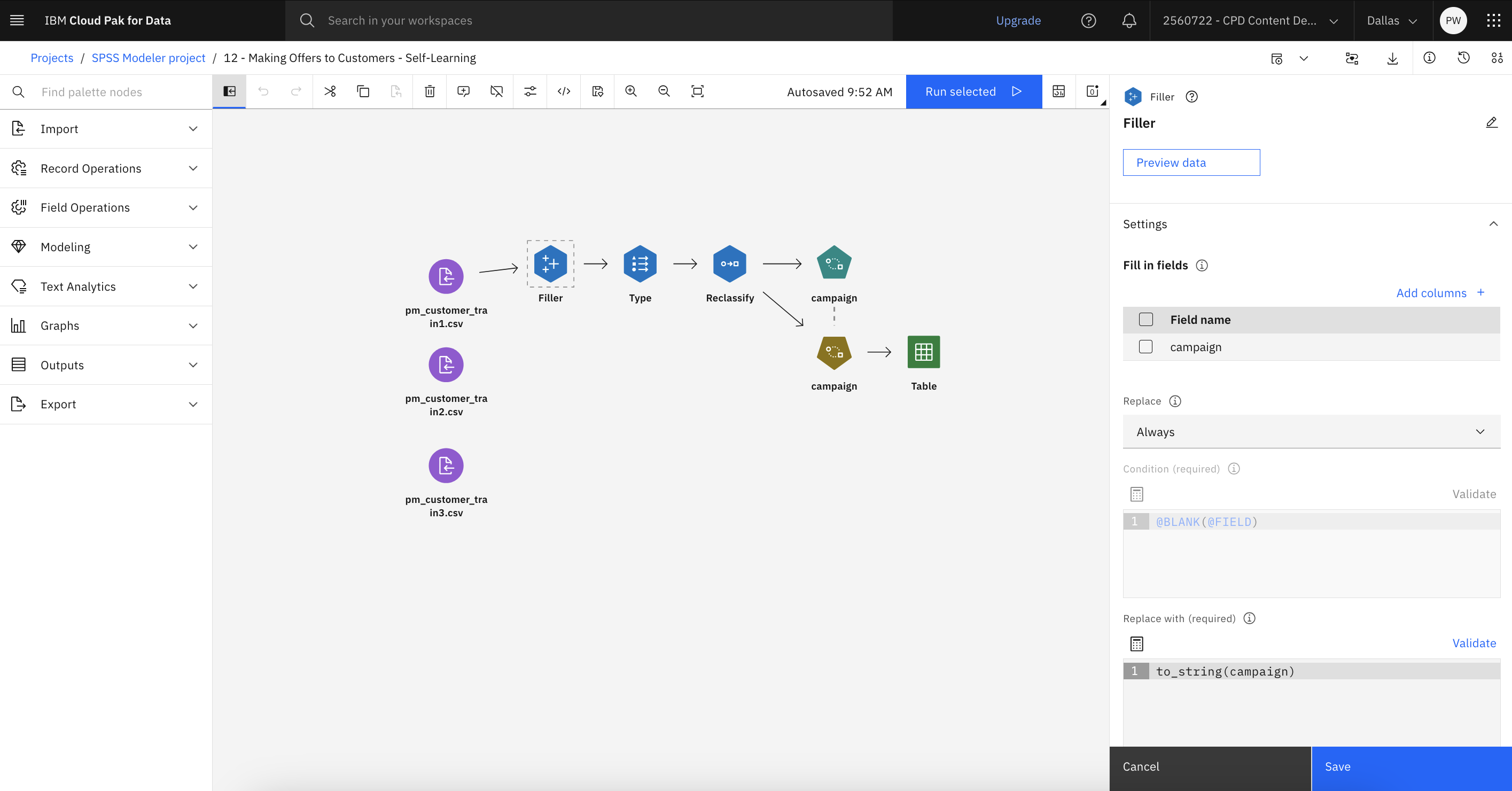
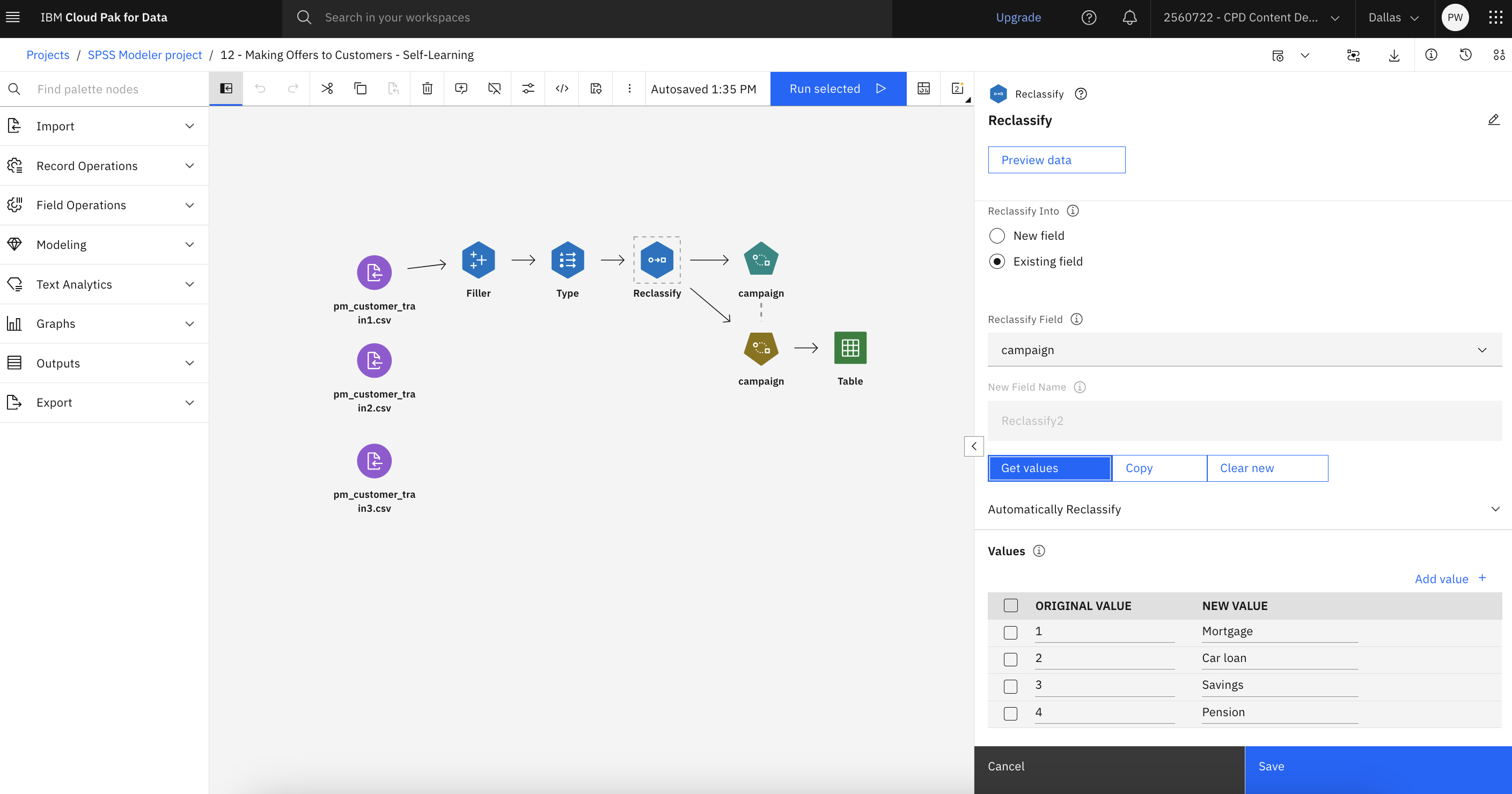
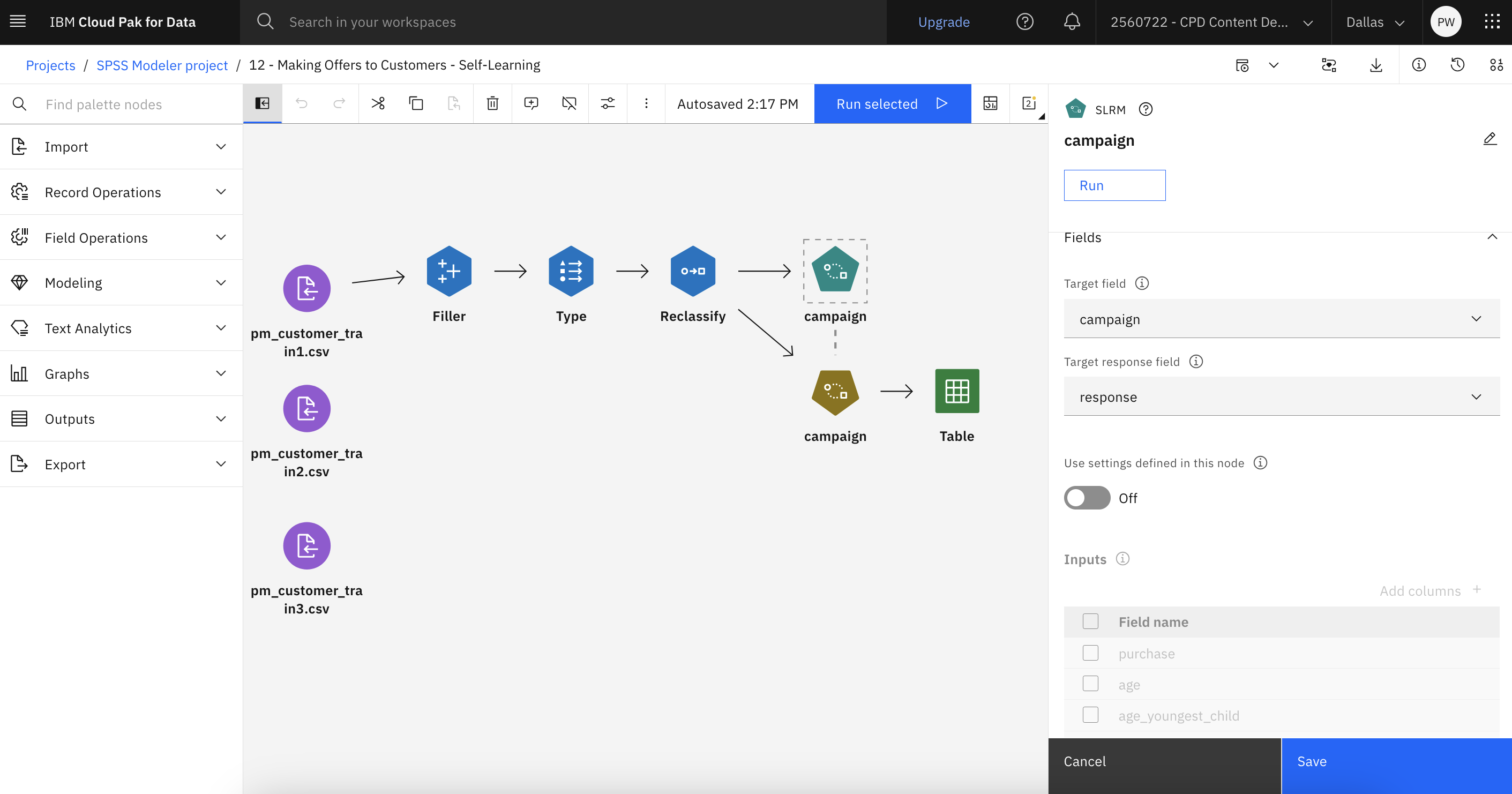
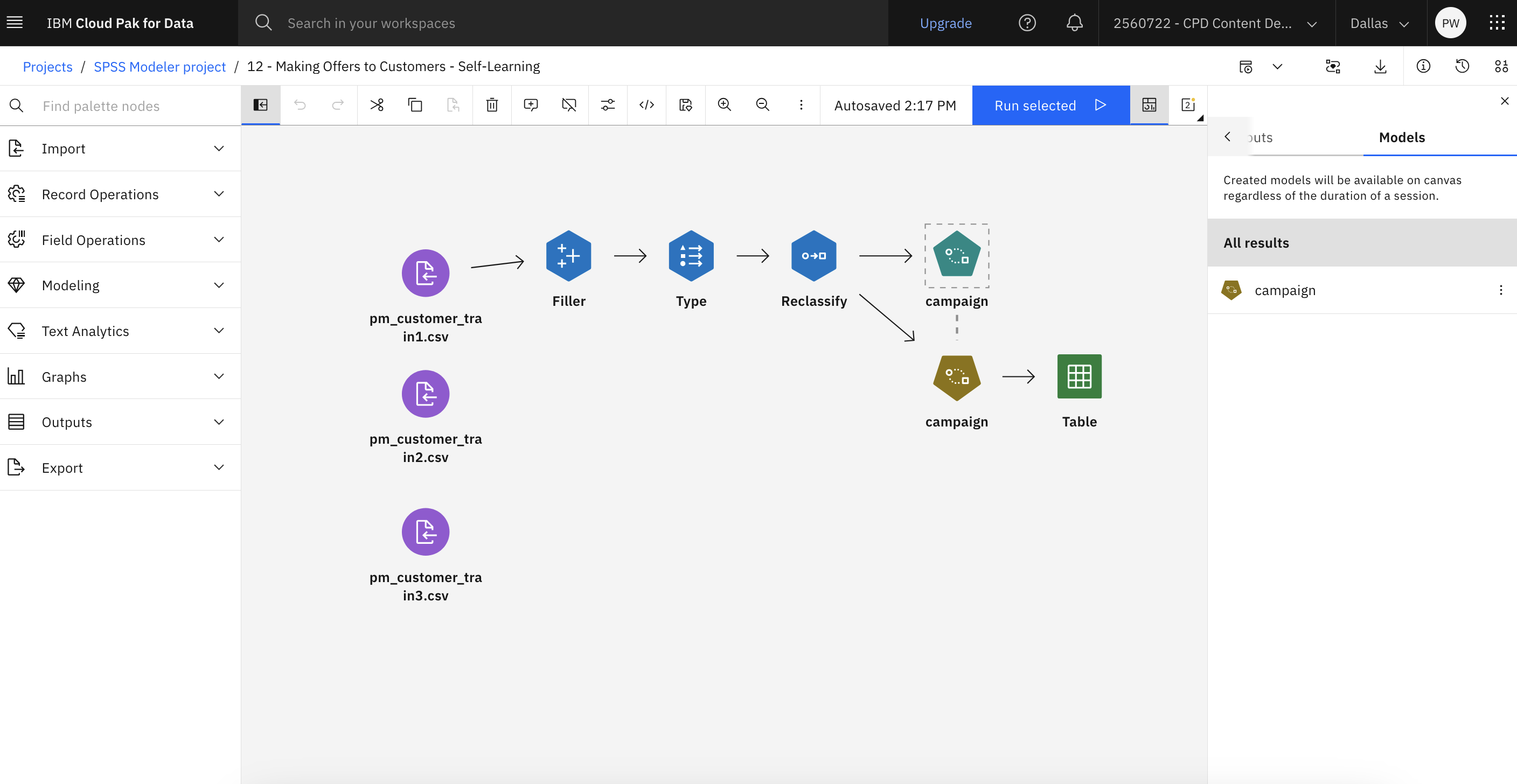
図 8. モデル出力-予測オファーと信頼度スコア 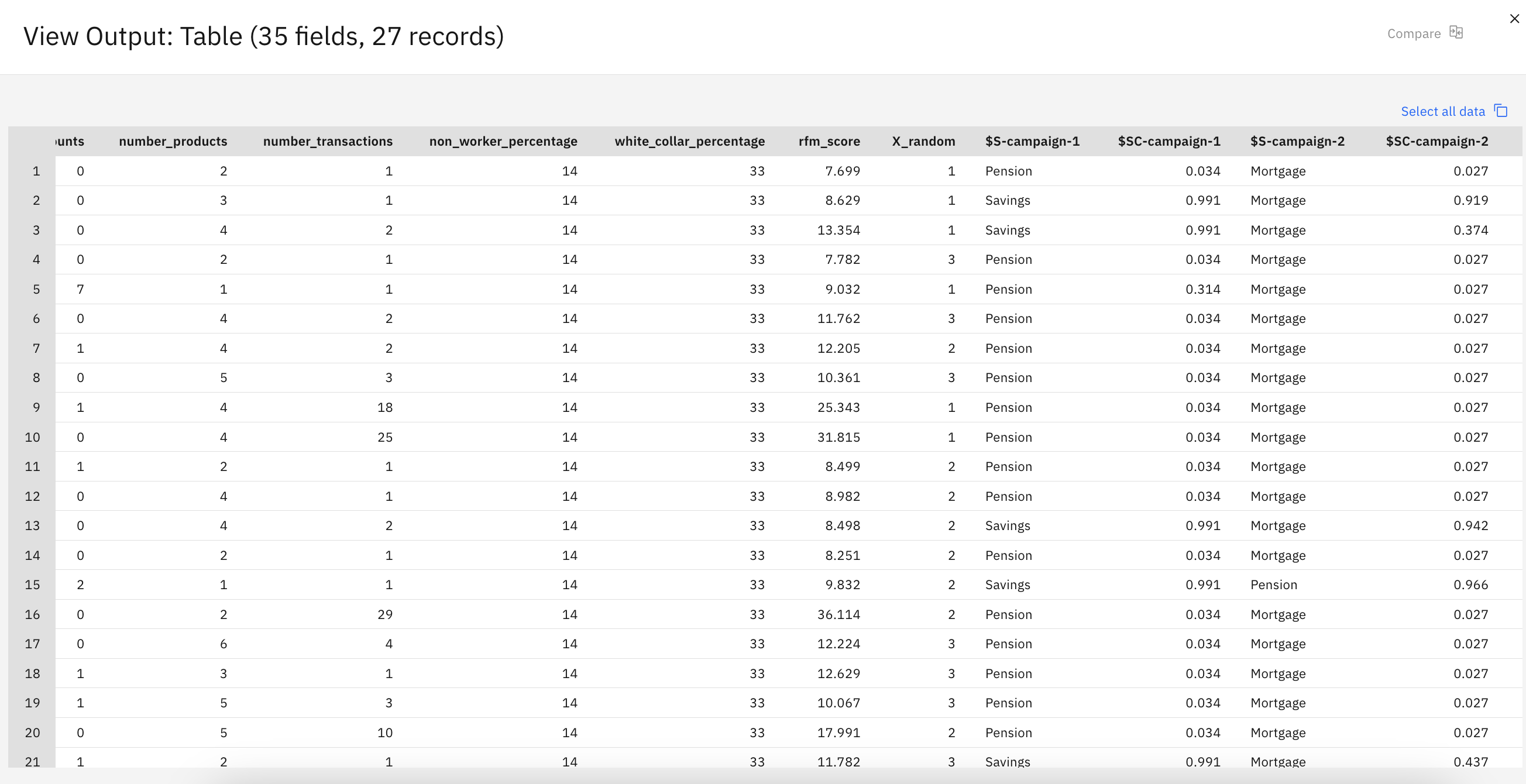
顧客にオファーを出す(自己学習)
最終更新: 2025年2月11日
このチュートリアルでは、「自己学習反応モデル(SLRM)ノードを使用します。このノードは、どのオファーが顧客に最も適切で、オファーが受け入れられる確率を予測するモデルを生成し、更新できるようにします。 このような種類のモデルは、マーケティング・アプリケーションやコール・センターなどのカスタマー・リレーションシップ・マネジメントで最も役立ちます。
この例は、架空の銀行に基づいています。 マーケティング部門は、適切な金融サービスのオファーを各顧客にマッチングすることで、将来のキャンペーンでより収益性の高い結果を達成したいと考えています。 具体的には、この例では、自己学習応答モデルを使用して、以前の提案および応答を基に、好意的な反応を示す可能性が最も高い顧客の特徴を識別し、その結果に基づいて現在の最良の提案を促進します。
チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、このドキュメントの概念とタスクを視覚的に学習する方法を提供しています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、このドキュメントの概念とタスクを視覚的に学習する方法を提供しています。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
このチュートリアルでは、サンプルプロジェクトの「顧客へのオファー - 自己学習」フローを使用します。 使用されるデータファイルはpm_customer_train1.csv、pm_customer_train2.csv、pm_customer_train3.csvである。 次の図は、モデラーのフロー例を示しています。
この銀行には、過去のキャンペーンで顧客に行った提案、およびそれらの提案に対する反応を追跡する履歴データがあります。 このデータには、さまざまな顧客の反応率を予測するために使用できる人口統計および財務情報も含まれています。 次の画像はサンプルデータセットです。図2: サンプルデータセット 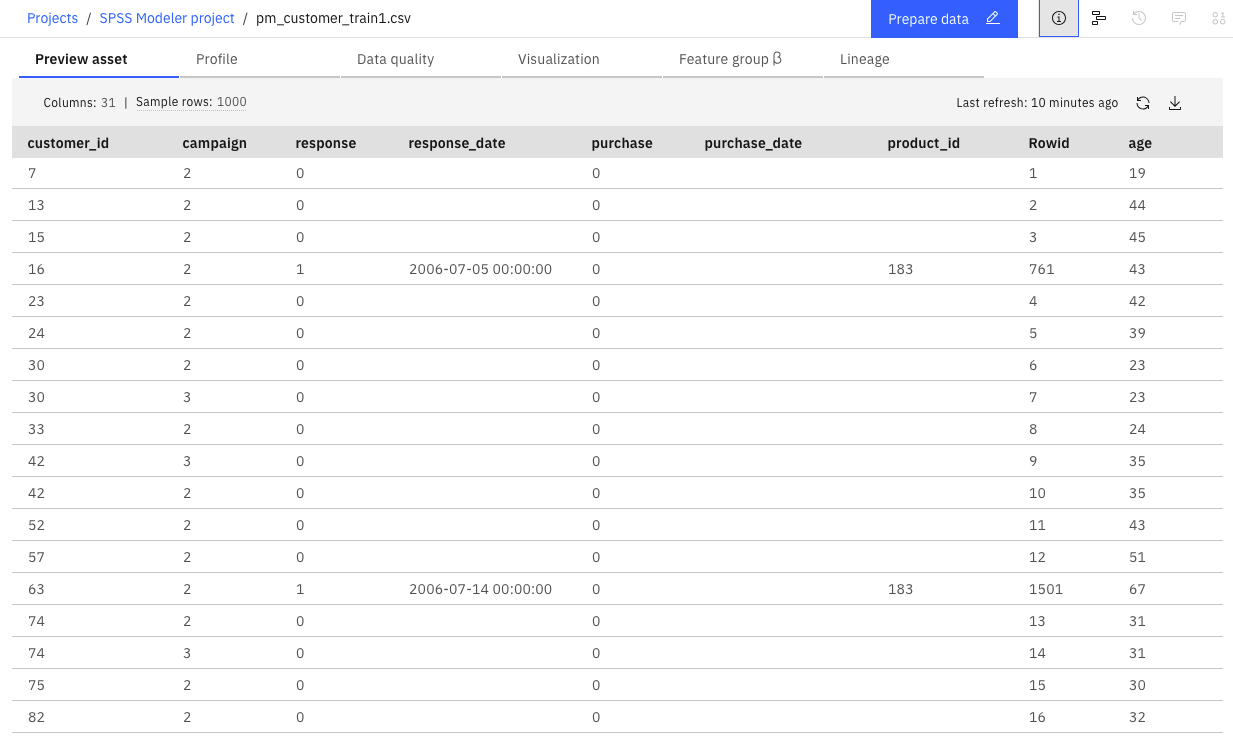
タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプルプロジェクトをまだお持ちでない場合は、 チュートリアルのトピックを参照してサンプルプロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataナビゲーションメニュー から
 、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。
、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。 - SPSS ModelerProjectをクリックします。
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。
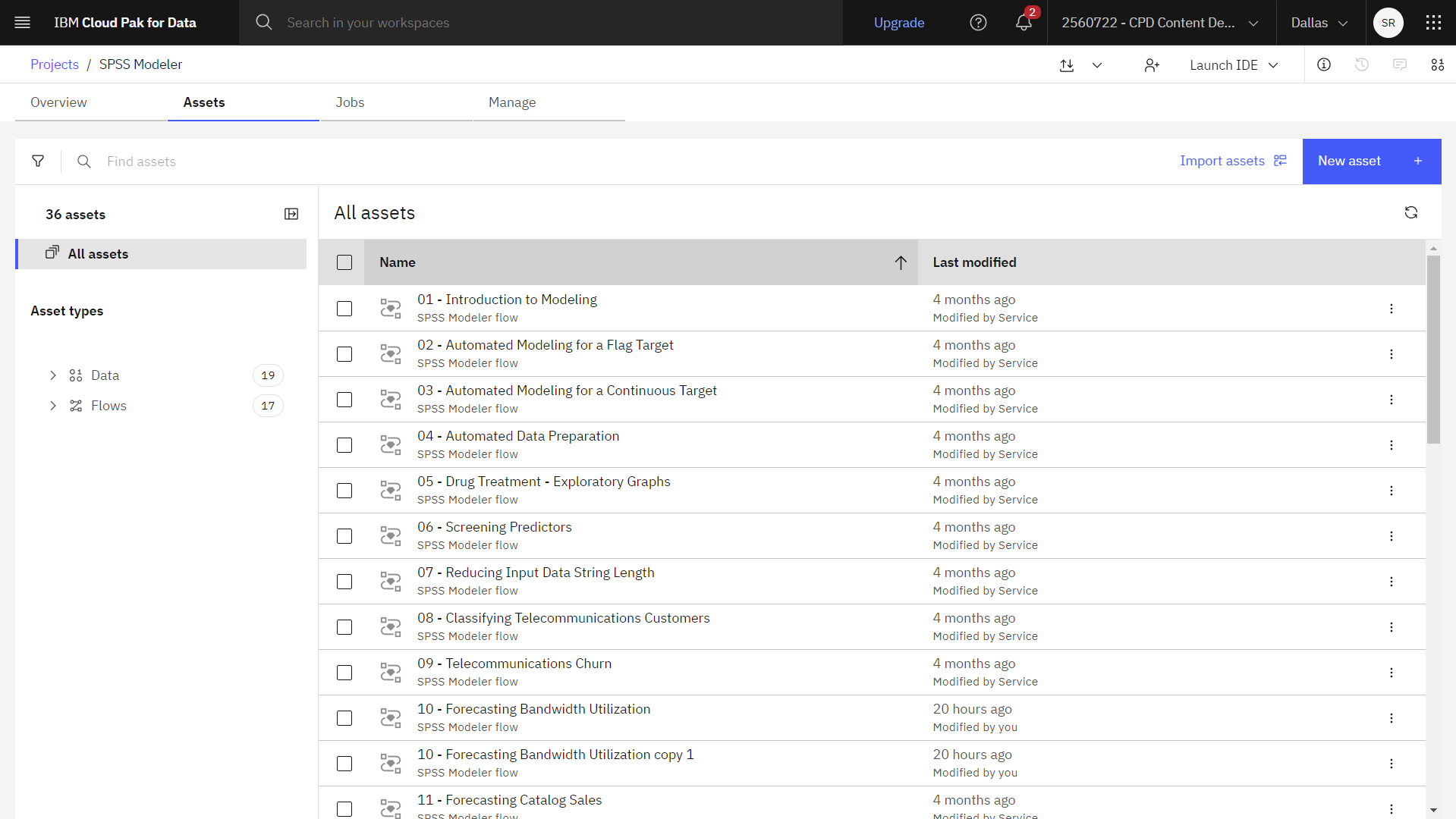
タスク2:データ・アセットとフィラー・ノードを調べる
顧客にオファーを出す - Self-Learningモデラーフローにはいくつかのノードがあります。 以下の手順に従って、データ・アセット・ノードと フィラー・ノードを調べます:
- アセットタブから、「顧客への提案 - 自己学習」モデラーフローを開き、キャンバスがロードされるのを待ちます。
- pm_customer_train1.csvノードをダブルクリックします。 このノードは、プロジェクト内のpm_customer_train1.csvファイルを指すData Assetノードです。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
- Fillerノードをダブルクリックします。フィラー・ノードは、フィールド値の置換やストレージの変更に使用される。
@BLANK(FIELD)campaign - キャンセルをクリックする。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はFillerノードを示している。 これでTypeノードとReclassifyノードを調べる準備ができた。
タスク3:ノードのタイプと再分類を調べる
以下の手順に従って、TypeノードとReclassifyノードを調べます:
- Typeノードをダブルクリックしてプロパティを見る。Typeノードでは、使用するフィールドのタイプと、それらがどのように結果の予測に使用されるかを示すことができる。
campaignresponseresponse - 値を読む」をクリックする。
図3: 尺度 
- 保存 をクリックします。
キャンペーン・フィールドのデータが数字のリスト (1、2、3、4) として表示されるため、フィールドを再分類してより分かりやすいタイトルにすることができます。
- Reclassifyノードをダブルクリックしてプロパティを表示します。
- Reclassify Intoセクションで、Existingフィールドを選択する。
- 次に、Reclassify Fieldセクションで、campaignを選択する。
- 「値を取得 (Get values)」をクリックします。 キャンペーンの値は「
ORIGINAL VALUE NEW VALUE- Mortgage
- Car loan
- Savings
- Pension
- 保存 をクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はReclassifyノードを示しています。 これでSLRMノードを探索する準備が整いました。
タスク4:SLRMノードの探索
以下の手順に従って、SLRMノードを探索してください:
- キャンペーン(SLRM)ノードをダブルクリックしてプロパティを表示します。
- Targetフィールドには「
campaignresponse - モデルオプション]の[レコードごとの最大予測数]の数字を2に減らす。 つまり、各顧客に対して、受け入れられる確率が最も高い2つのオファーが特定される。
- モデルの信頼性を考慮する」が選択されていることを確認する。
- 保存 をクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、このフローを示しています。 これでモデルを生成する準備が整いました。
タスク5:モデルの生成
以下の手順でモデルを生成する:
- キャンペーン(SLRM)ノードの上にカーソルを移動し、 実行アイコン
 をクリックします。
をクリックします。 - アウトプットとモデルペインで、結果を表示するキャンペーンモデルをクリックします。
最初のビューには、各提案の予測の推定精度が表示されます。 「予測値の重要度」をクリックしてモデルの推定における各予測値の相対重要度を表示したり、「応答との関連付け (Association With Response)」をクリックして各予測値と対象変数の相関を表示したりすることもできます。
図4: キャンペーンモデルのパフォーマンス 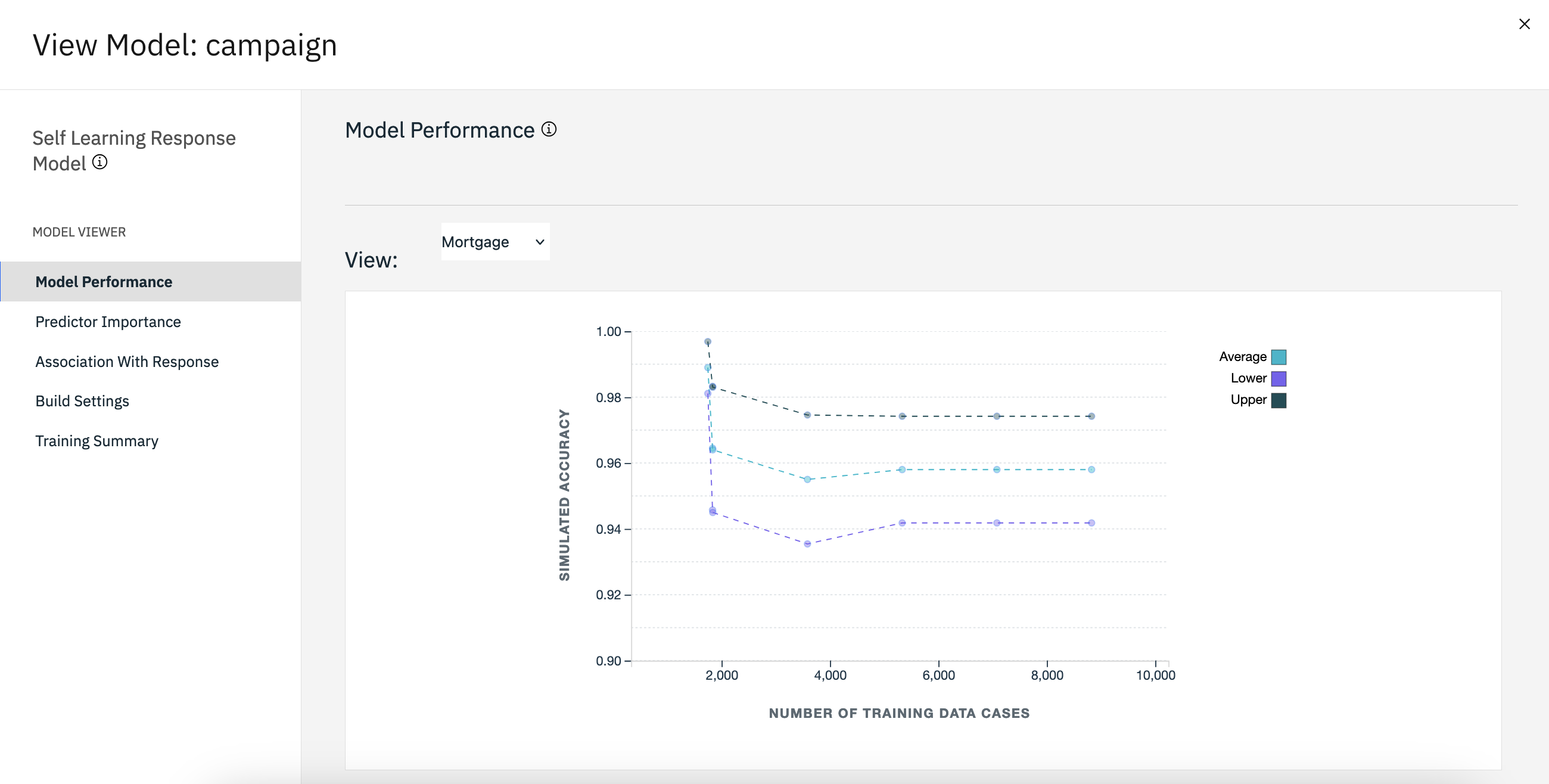
- 予想がある4つのオファーをそれぞれ切り替えるには、「表示」メニューを使用する。
- フローに戻ります。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、このフローを示しています。 これで他のデータ・アセット・ノードを試す準備ができました。
タスク6:他のデータアセットノードを試す
以下の手順に従って、他のデータアセットノードを試してみてください:
- Fillerノードからpm_customer_train1.csvノードを切断します。
- pm_customer_train2.csvノードをFillerノードに接続します。
- campaign (SLRM)ノードをダブルクリックし、Build OptionsでContinue training existing modelが選択されていることを確認します。
- 保存 をクリックします。
- フローを実行して、モデル・ナゲットを再生成します。 キャンペーン(SLRM)ノードの上にカーソルを移動し、 実行アイコン をクリックします。
- アウトプットとモデルペインで、結果を表示するキャンペーンモデルをクリックします。 これで、モデルには、各提案の予測の精度の、改訂済み推定値が表示されます。
図 5. キャンペーンモデルのパフォーマンス 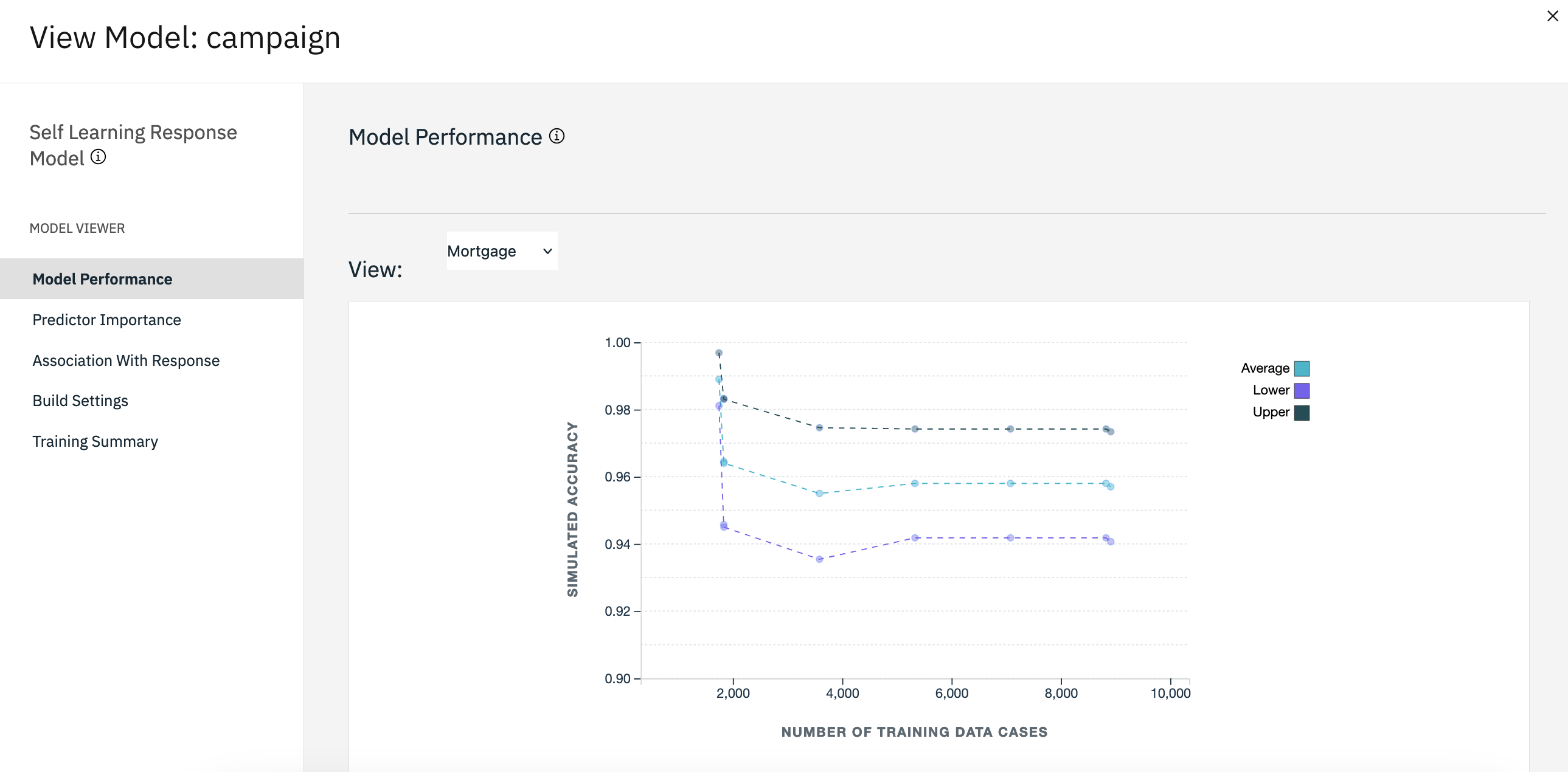
- Fillerノードからpm_customer_train2.csvノードを切断します。
- pm_customer_train3.csvノードをFillerノードに接続します。
- フローを実行して、モデル・ナゲットを再生成します。 キャンペーン(SLRM)ノードの上にカーソルを移動し、 実行アイコン をクリックします。
- アウトプットとモデルペインで、結果を表示するキャンペーンモデルをクリックします。
図 6. キャンペーンモデルのパフォーマンス 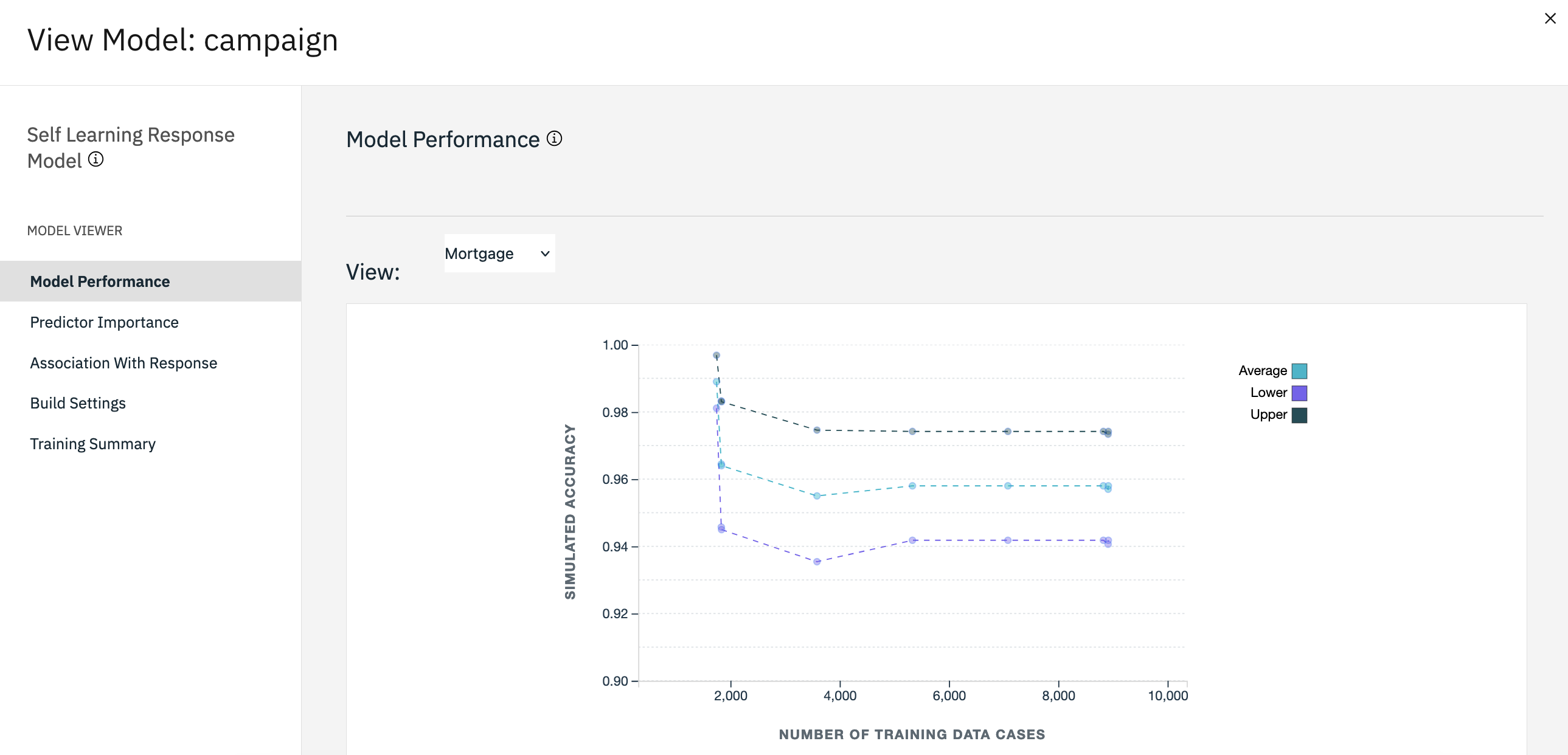
これで、モデルには、各提案の予測の最終推定精度が表示されます。 表示されているように、平均精度は、データ・ソースを追加すると若干減少します。 しかし、この変動はごくわずかであり、入手可能なデータ内のわずかな異常に起因するものかもしれない。
- テーブルノードの上にカーソルを移動し、 実行アイコン をクリックします。
- Outputs and models"ペインで、"Table "モデルをクリックして結果を表示する。
図 7. キャンペーンモデルのパフォーマンス
表の予測は、各顧客の詳細に応じて、顧客がどのオファーを受け入れる可能性が最も高いか、またそのオファーを受け入れる確信度を示している。 例えば、1行目では、以前自動車ローンを組んだ顧客が年金を勧められた場合、それを受け入れるかどうかの信頼度は13.2しかない(「$SC-campaign-10.132
使用されているモデリング手法の数学的基礎の説明は、 SPSS ModelerSPSS Modeler アルゴリズムガイドで入手できます。
これらの結果はトレーニングデータのみに基づいている。 モデルが現実世界の他のデータに対してどの程度一般化されるかを評価するために、テストと検証の目的でレコードのサブセットを保持するためにパーティション・ノードを使用します。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、このフローを示しています。
サマリー
この例では、Self-Learning Response Model (SLRM)ノードを使用して、各顧客の詳細に応じて、顧客がオファーを受け入れる可能性が最も高いオファーと、オファーを受け入れる確信度を予測する方法を示した。
次のステップ
これで、他の SPSS® Modeler チュートリアルを試す準備ができました。
トピックは役に立ちましたか?
0/1000