画面予測値
チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足となることを目的としています。 このビデオでは、このドキュメントのコンセプトとタスクを視覚的に学習する方法を提供しています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足となることを目的としています。 このビデオでは、このドキュメントのコンセプトとタスクを視覚的に学習する方法を提供しています。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
このチュートリアルでは、サンプル・プロジェクトのスクリーニング予測フローを使用します。 使用するデータファイルはcustomer_dbase.csvである。 次の図は、モデラーのフロー例を示しています。

- 特徴量選択なし。 データ・セットのすべての予測値フィールドが CHAID ツリーへの入力として使用されます。
- 特徴量選択あり。 特徴選択(Feature Selection)ノードは,ベスト10の予測子を選択するために使用される. これらの予測変数はCHAIDツリーに入力される。
結果として得られた2つのツリーモデルを比較することで、特徴選択がいかに効果的な結果をもたらすかがわかる。

タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプルプロジェクトをまだお持ちでない場合は、 チュートリアルのトピックを参照してサンプルプロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataナビゲーションメニュー から
 、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。
、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。 - SPSS ModelerProjectをクリックします。
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。

タスク 2: データアセットとタイプノードを調べる
スクリーニング予測にはいくつかのノードがある。 以下の手順に従って、データ・アセットと タイプ・ノードを調べます:
- アセットタブから、スクリーニング予測モデラーフローを開き、キャンバスがロードされるのを待ちます。
- customer_dbase.csvノードをダブルクリックします。 このノードは、プロジェクト内のcustomer_dbase.csvファイルを指すData Assetノードです。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
- Typeノードをダブルクリックする。 これらの各フィールドのRoleの値に注目してほしい:
- response_01は Targetに設定されている
- response_02、response_03、およびcustidはNoneに設定されます
- 他のすべてのフィールドはInputに設定されている
図3: タイプノード測定レベル 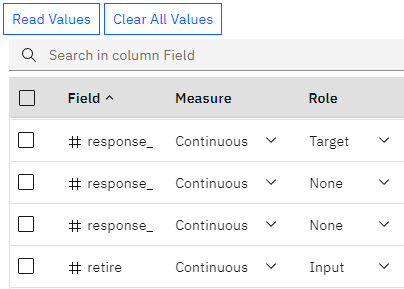
- 「値の読み込み」をクリックします。
- オプション:データ・プレビューをクリックすると、タイプ・プロパティが適用されたデータ・セットが表示されます。
- 保存 をクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はTypeノードを示している。 これでモデルを作る準備ができた。

タスク3:モデルの構築
以下の手順でモデルを作成する:
- response_01(Feature Selection)ノードをダブルクリックして、プロパティを表示します。
- Build Options(ビルド・オプション)セクションを展開すると、フィールドのスクリーニングや除外に使用される定義済みのルールや基準が表示されます。
図4: 機能選択 ビルド・オプション 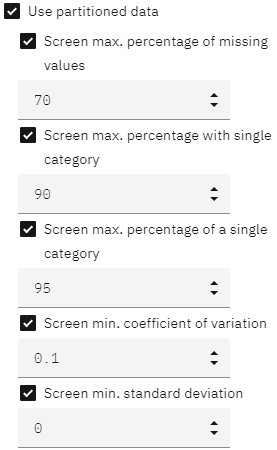
- response_01 (機能選択)ノードにカーソルを合わせ、 実行アイコン
 をクリックします。
をクリックします。 - 出力とモデルペインで、response_01という名前のモデルをクリックして、モデルを表示します。 結果は、予測に役立つと思われる分野を重要度順に並べたものである。 これらのフィールドを検証して、この後のモデル化セッションに使用するフィールドを決定することができます。
特徴選択なしで結果を比較するには、フローで2つのCHAIDモデリング・ノードを使用する必要があります:1つは特徴選択を使用し、もう1つは使用しません。
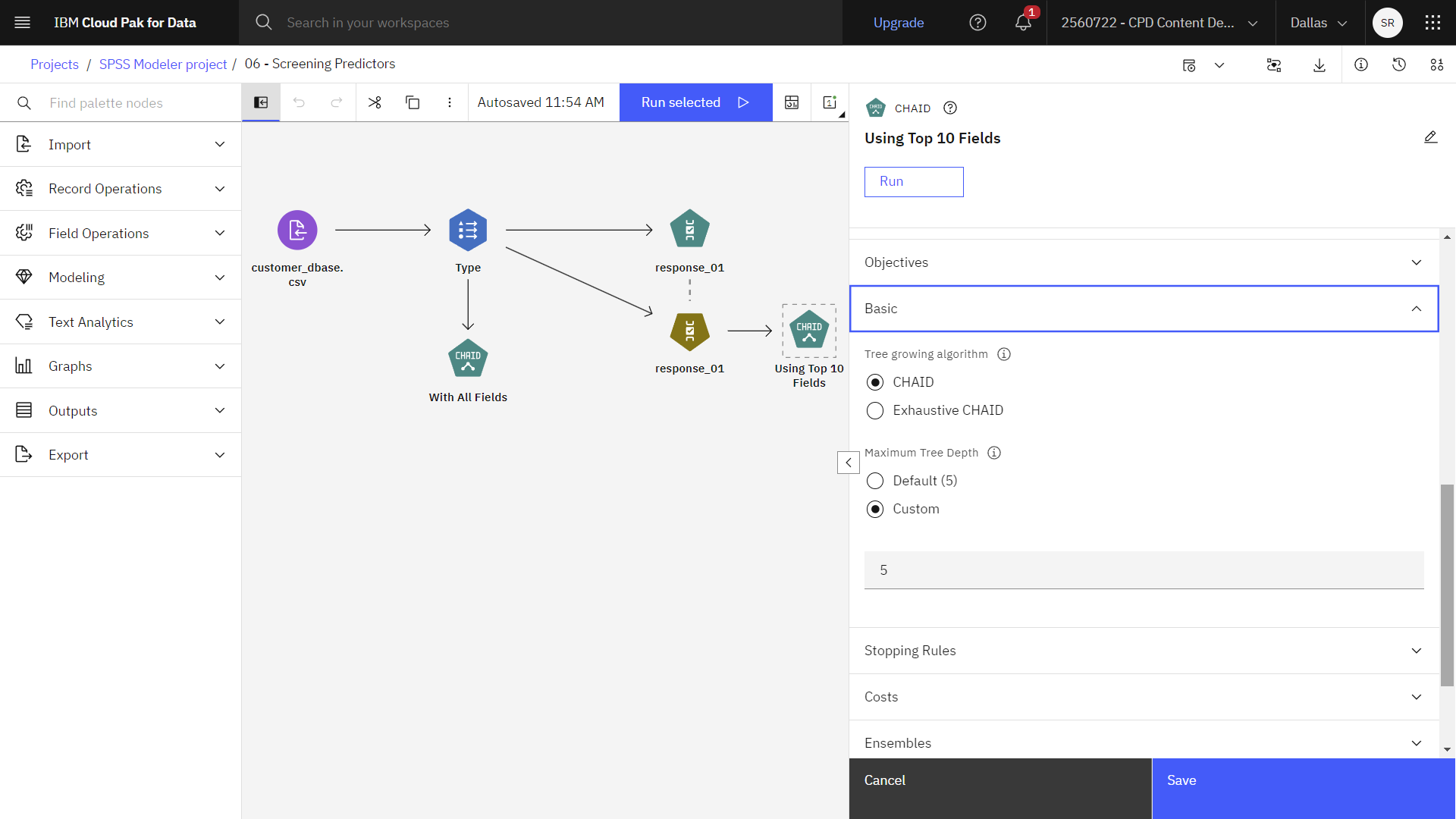
- With All Fields (CHAID)ノードをダブルクリックしてプロパティを表示します。
- Objectives(目的)]で、[Build new model(新しいモデルの構築)]と[Create standard model(標準モデルの作成)]が選択されていることを確認します。
- Basicセクションを展開し、Maximum Tree Depthが Customに設定され、レベル数が'
5
- 保存 をクリックします。
- Using Top 10 Fields (CHAID)ノードをダブルクリックして、プロパティを表示します
- With All Fields (CHAID)ノードと同じプロパティを確認する。
- 保存 をクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はModelingノードを示している。 これでフローを実行し、結果を見る準備ができた。
タスク4:フローの実行と結果の表示
以下の手順に従ってフローを実行し、特徴選択を行った場合と行わなかった場合の2つのモデルの結果を表示します:
- すべて実行をクリック 。 実行しながら、各モデルが構築し終わるのにかかる時間に注目してください。
- Outputs and modelsペインで、With All fieldsという名前のモデルをクリックして、結果を表示します。
- ツリーダイアグラムのページをクリックします。
- ズームアウトしてツリー図の範囲を見る。
- モデルの詳細ウィンドウを閉じます。
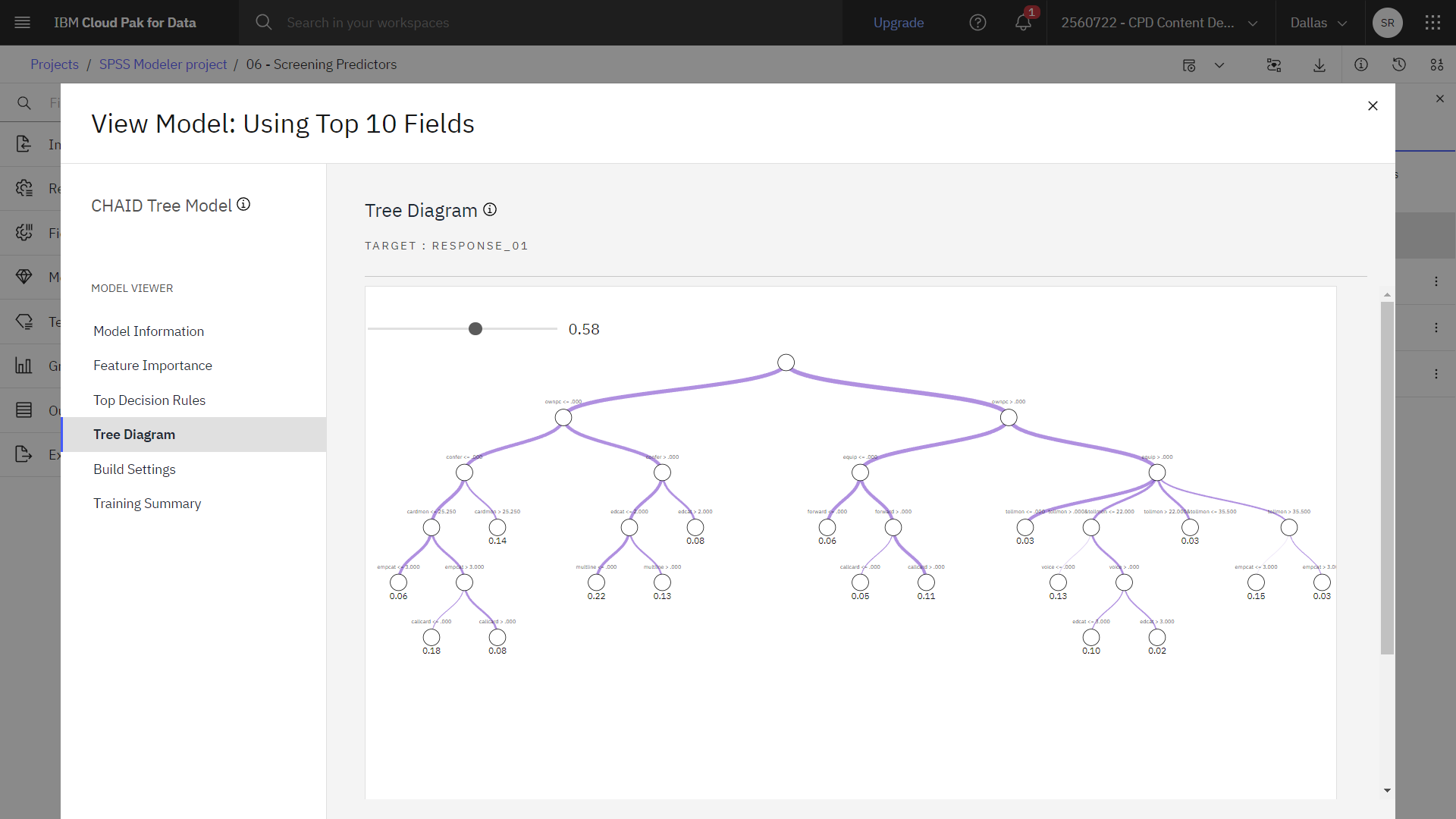
- Outputs and models(出力とモデル)ペインで、Using Top 10 fields(トップ10フィールドを使用)という名前の modelrun をクリックして、結果を表示します。
- ツリーダイアグラムのページをクリックします。
- ズームアウトしてツリー図の範囲を見る。
分かりにくい場合もありますが、最初のモデルよりも 2 番目のモデルの方が高速で実行されます。 このデータセットは比較的小さいので、実行時間の差はおそらく数秒であろう。しかし、より大きな実世界のデータセットでは、その差は数分、あるいは数時間と顕著になるかもしれない。 特徴選択を使えば、処理時間を劇的に短縮できるかもしれない。
その代わりに、ツリー構築アルゴリズムを使って特徴選択を行い、ツリーが最も重要な予測因子を識別できるようにすることもできる。 実際に、CHAID アルゴリズムはこの目的のために使用されることが多く、1 レベルずつツリーを成長させてツリーの深度と複雑性をコントロールすることも可能です。 しかし、Feature Selectionノードの方が高速で使いやすい。 これは1つの速いステップですべての予測因子をランク付けし、最も重要な分野を素早く特定するのに役立ちます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、このモデルによるツリー図である。
サマリー
また、2 番目のツリーは 1 番目のツリーに比べて、ツリー・ノードも少数です。 そのため理解しやすくなっています。 使用する予測値が少ないほど低コストになります。 つまり、収集、処理、モデルに送信するデータが少なくなります。 計算時間が短縮されます。 この例では、特徴量選択の手順が増えたにも関わらず、モデル構築は予測数が少ない方が速くなりました。 より大きな実世界のデータセットがあれば、時間の節約は大きく増幅されるかもしれない。
使用する予測値が少ないほど、スコアリングはシンプルになります。 例えば、販売促進活動に反応しそうな顧客のプロファイルを 4 つだけ識別します。 予測変数の数が多くなると、モデルをオーバー・フィッティングする危険性があります。 より単純なモデルの方が、他のデータセットに対してより良く一般化できるかもしれない(ただし、この方法を確かめるにはテストが必要だ)。
次のステップ
これで、他の SPSS® Modeler チュートリアルを試す準備ができました。