Ce tutoriel construit deux modèles pour prédire les effets de futures promotions des ventes, puis compare les modèles.
Comme pour le tutoriel sur la surveillance des conditions, le processus d'exploration des données comprend les phases d'exploration, de préparation des données, de formation et de test. Toutes les données du fichier " telco.csv ne sont pas utiles pour prédire le taux de désabonnement. Vous pouvez utiliser le filtre pour sélectionner uniquement les données considérées comme importantes pour une utilisation en tant que prédicteur (les champs marqués comme importants dans le modèle).
Aperçu du tutoriel
Regardez cette vidéo pour prévisualiser les étapes de ce tutoriel. Il peut y avoir de légères différences dans l'interface utilisateur présentée dans la vidéo. La vidéo est destinée à accompagner le tutoriel écrit. Cette vidéo fournit une méthode visuelle pour apprendre les concepts et les tâches de cette documentation.
Essayez le tutoriel
Dans ce tutoriel, vous exécutez les tâches suivantes :
Exemple de flux de modélisateurs et d'ensembles de données
Ce tutoriel utilise le flux Promotion des ventes au détail du projet d'exemple. Le fichier de données utilisé est goods2n.csv. L'image suivante montre un exemple de flux de modélisation.
Figure 1 : Flux du modeleur d'échantillon
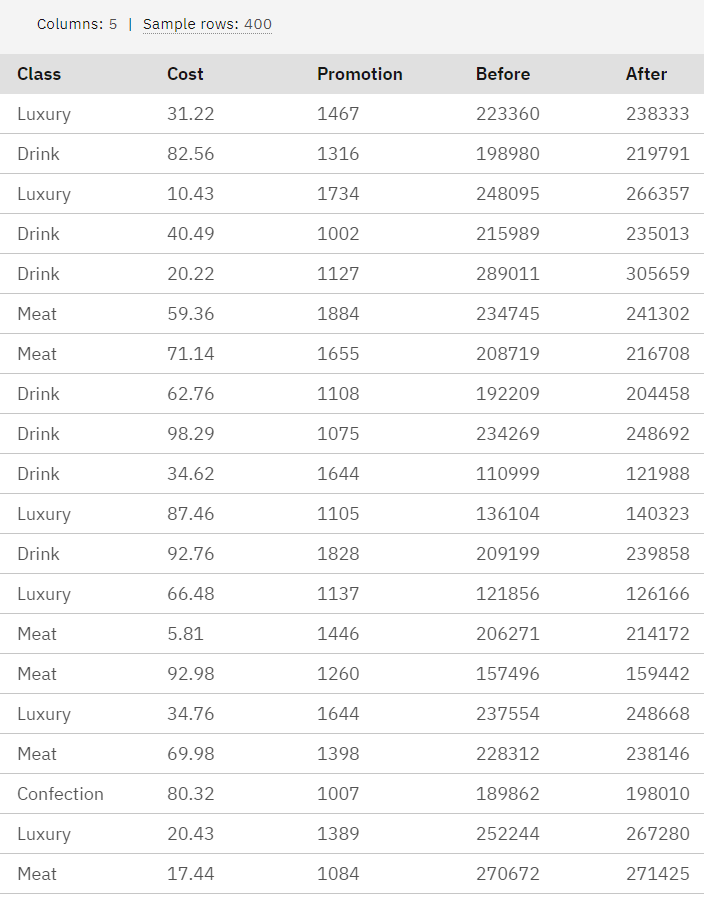
L'image suivante montre l'échantillon de données.Figure 2. Exemple de données
Tâche 1 : Ouvrir le projet d'exemple
L'exemple de projet contient plusieurs ensembles de données et des exemples de flux de modélisation. Si vous n'avez pas encore le projet exemple, reportez-vous à la rubrique Tutoriels pour créer le projet exemple. Suivez ensuite les étapes suivantes pour ouvrir l'exemple de projet :
Dans le menu de navigation , choisissez Projets > Afficher tous les projets Cloud Pak for Data dans le menu de navigation, choisissez Projets > Voir tous les projets.
Cliquez sur SPSS Modeler Project.
Cliquez sur l'onglet Actifs pour voir les ensembles de données et les flux du modélisateur.
Vérifiez vos progrès
L'image suivante montre l'onglet Actifs du projet. Vous êtes maintenant prêt à travailler avec l'exemple de flux du modeleur associé à ce tutoriel.
Tâche 2 : Examiner les nœuds Data Asset, Derive et Type
La promotion des ventes au détail comprend plusieurs nœuds. Procédez comme suit pour examiner les nœuds Data Asset, Derive et Type:
Noeud Actif de données
Dans l'onglet Actifs, ouvrez le flux du modeleur Promotion des ventes au détail et attendez que le canevas se charge.
Double-cliquez sur le nœud goods1n.csv. Ce nœud est un nœud d'actif de données qui pointe vers le fichier goods1n.csv du projet.
Examinez les propriétés du format de fichier.
Cliquez sur Aperçu des données pour voir l'ensemble des données.
Remarquez que chaque enregistrement contient
Class. Type de produit.
Cost. Prix unitaire.
Promotion. Indice du montant dépensé pour une promotion particulière.
Before. Chiffre d'affaires avant promotion.
After. Chiffre d'affaires après promotion.
Les deux champs relatifs au chiffre d'affaires (Before et After) sont exprimés en termes absolus. Toutefois, il semble probable que l'augmentation des recettes après la promotion (et probablement grâce à elle) soit un chiffre plus utile.
Fermez l'aperçu des données et le volet latéral des propriétés.
Noeud Calculer
Double-cliquez sur le nœud Augmenter (Dériver). Ce nœud dérive la valeur de l'augmentation des recettes.
Examinez les paramètres, en particulier le champ Expression, qui contient une formule permettant de calculer l'augmentation en pourcentage des recettes avant la promotion : " (After - Before) /
Before * 100.0.
Cliquez sur Aperçu des données pour voir l'ensemble des données avec les valeurs dérivées.
Remarquez la colonne Augmentation.
Pour chaque catégorie de produits, il existe une relation quasi-linéaire entre l'augmentation du chiffre d'affaires et le coût de l'action promotionnelle. Il est donc probable qu'un arbre décision ou un réseau de neurones puisse prévoir, avec une exactitude relativement fiable, l'augmentation des recettes à l'aide des autres champs disponibles.
Fermez l'aperçu des données et le volet latéral des propriétés.
Noeud type
Double-cliquez sur le nœud Définir les types (Type). Ce nœud spécifie les propriétés des champs, telles que le niveau de mesure (le type de données que le champ contient), et le rôle de chaque champ en tant que cible ou entrée dans la modélisation. Le niveau de mesure est une catégorie qui indique le type de données du champ. Le fichier de données source utilise trois niveaux de mesure différents :
Un champ continu (tel que le champ " Age ) contient des valeurs numériques continues.
Un champ nominal (tel que le champ " Education ) a deux ou plusieurs valeurs distinctes - dans ce cas " College ou " High school.
Un champ ordinal (tel que le champ " Income level ) décrit des données comportant plusieurs valeurs distinctes ayant un ordre inhérent - dans ce cas " Low, " Medium et " High.
Pour chaque champ, le nœud Type spécifie également un rôle afin d'indiquer le rôle que joue chaque champ dans la modélisation. Le rôle est défini sur Cible pour le champ " Increase, qui est le champ dérivé. Le " target est le champ pour lequel vous voulez prédire la valeur.
Le rôle est défini sur Entrée pour la plupart des autres champs. Les champs d'entrée sont parfois appelés " predictors, ou champs dont les valeurs sont utilisées par l'algorithme de modélisation pour prédire la valeur du champ cible.
Le rôle du champ " After est défini sur " None", ce qui signifie que ce champ n'est pas utilisé par l'algorithme de modélisation.
Facultatif : Cliquez sur Aperçu des données pour afficher l'ensemble des données avec les valeurs dérivées.
Vérifiez vos progrès
L'image suivante montre le nœud Type. Vous êtes maintenant prêt à générer et à comparer les modèles.
Le flux entraîne un réseau de neurones et un arbre de décision à prédire l'augmentation du chiffre d'affaires. Suivez les étapes suivantes pour générer les deux modèles :
Générer les modèles
Double-cliquez sur le nœud Increase (Neural net) pour consulter ses propriétés.
Développez la section Bases pour voir que le type de modèle est le Perceptron multicouche. Cette propriété détermine la manière dont le réseau relie les prédicteurs aux cibles à travers les couches cachées. Le perceptron multicouche permet d'établir des relations plus complexes au prix éventuel d'une augmentation du temps de formation et de notation.
Développez la section Options du modèle pour voir les propriétés d'évaluation et de notation.
Double-cliquez sur le nœud Augmenter (Arbre C&R) pour afficher ses propriétés.
Cliquez sur Run all, et attendez que les pépites du modèle soient générées.
Comparer les modèles
Connecter la pépite du modèle d'augmentation (arbre C&R) à l'augmentation (réseau neuronal).
Ajouter un nœud d'analyse :
Dans la palette, développez la section Outputs.
Faites glisser le nœud d'analyse sur le canevas.
Connecter la pépite du modèle Increase (Neural net) au nœud Analysis.
Modifier l'ensemble de données afin d'utiliser d'autres données pour l'analyse :
Double-cliquez sur le nœud goods1n.csv pour afficher ses propriétés.
CV lick Modifier l'ensemble des données.
Naviguez jusqu'à Data asset > GOODS2n.csv.
Cliquez sur Sélectionner.
Cliquez sur Sauvegarder.
Survolez le nœud Analyse et cliquez sur l'icône Exécuter.
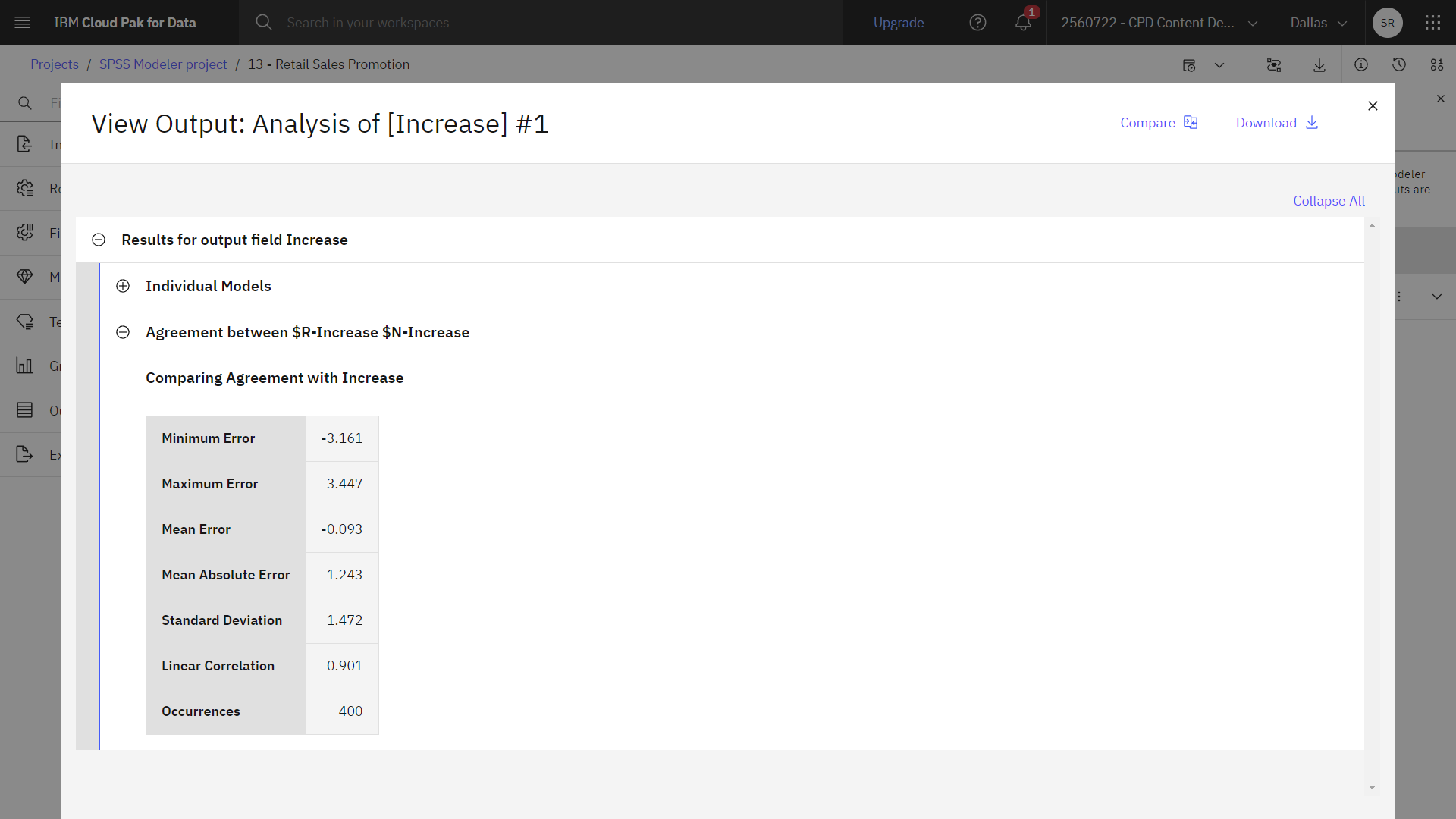
Dans le volet Sorties et modèles, cliquez sur la sortie portant le nom Analyse pour afficher les résultats.
Les résultats de l'analyse, en particulier la corrélation linéaire entre l'augmentation prédite et la réponse correcte, montrent que les systèmes formés prédisent l'augmentation des recettes avec un degré de réussite élevé.
Une étude plus poussée pourrait révéler des cas où les systèmes entraînés commettent des erreurs relativement importantes. Vous pouvez identifier ces erreurs en représentant graphiquement l'augmentation prévue des recettes par rapport à l'augmentation réelle. Vous pouvez ensuite sélectionner les valeurs aberrantes sur un graphique en utilisant les graphiques interactifs de SPSS Modeler et, à partir de leurs propriétés, il peut être possible d'ajuster la description des données ou le processus d'apprentissage afin d'améliorer la précision.
Vérifiez vos progrès
L'image suivante montre la sortie du nœud d'analyse.
Cet exemple vous a montré comment prévoir les effets de futures promotions des ventes. Comme dans l'exemple de la surveillance des conditions, le processus d'exploration des données comprend les phases d'exploration, de préparation des données, de formation et de test.
Use this interactive map to learn about the relationships between your tasks, the tools you need, the services that provide the tools, and where you use the tools.
Select any task, tool, service, or workspace
You'll learn what you need, how to get it, and where to use it.
Tasks you'll do
Some tasks have a choice of tools and services.
Tools you'll use
Some tools perform the same tasks but have different features and levels of automation.
Create a notebook in which you run Python, R, or Scala code to prepare, visualize, and analyze data, or build a model.
Automatically analyze your tabular data and generate candidate model pipelines customized for your predictive modeling problem.
Create a visual flow that uses modeling algorithms to prepare data and build and train a model, using a guided approach to machine learning that doesn’t require coding.
Create and manage scenarios to find the best solution to your optimization problem by comparing different combinations of your model, data, and solutions.
Create a flow of ordered operations to cleanse and shape data. Visualize data to identify problems and discover insights.
Automate the model lifecycle, including preparing data, training models, and creating deployments.
Work with R notebooks and scripts in an integrated development environment.
Create a federated learning experiment to train a common model on a set of remote data sources. Share training results without sharing data.
Deploy and run your data science and AI solutions in a test or production environment.
Find and share your data and other assets.
Import asset metadata from a connection into a project or a catalog.
Enrich imported asset metadata with business context, data profiling, and quality assessment.
Measure and monitor the quality of your data.
Create and run masking flows to prepare copies of data assets that are masked by advanced data protection rules.
Create your business vocabulary to enrich assets and rules to protect data.
Track data movement and usage for transparency and determining data accuracy.
Track AI models from request to production.
Create a flow with a set of connectors and stages to transform and integrate data. Provide enriched and tailored information for your enterprise.
Create a virtual table to segment or combine data from one or more tables.
Measure outcomes from your AI models and help ensure the fairness, explainability, and compliance of all your models.
Replicate data to target systems with low latency, transactional integrity and optimized data capture.
Consolidate data from the disparate sources that fuel your business and establish a single, trusted, 360-degree view of your customers.
Services you can use
Services add features and tools to the platform.
Develop powerful AI solutions with an integrated collaborative studio and industry-standard APIs and SDKs. Formerly known as Watson Studio.
Quickly build, run and manage generative AI and machine learning applications with built-in performance and scalability. Formerly known as Watson Machine Learning.
Discover, profile, catalog, and share trusted data in your organization.
Create ETL and data pipeline services for real-time, micro-batch, and batch data orchestration.
View, access, manipulate, and analyze your data without moving it.
Monitor your AI models for bias, fairness, and trust with added transparency on how your AI models make decisions.
Provide efficient change data capture and near real-time data delivery with transactional integrity.
Improve trust in AI pipelines by identifying duplicate records and providing reliable data about your customers, suppliers, or partners.
Increase data pipeline transparency so you can determine data accuracy throughout your models and systems.
Where you'll work
Collaborative workspaces contain tools for specific tasks.
Where you work with data.
> Projects > View all projects
Where you find and share assets.
> Catalogs > View all catalogs
Where you deploy and run assets that are ready for testing or production.
> Deployments
Where you manage governance artifacts.
> Governance > Categories
Where you virtualize data.
> Data > Data virtualization
Where you consolidate data into a 360 degree view.
À propos des cookies sur ce sitePour fonctionner correctement, nos sites Internet nécessitent certains cookies (requis). En outre, d'autres cookies peuvent être utilisés avec votre consentement pour analyser l'utilisation d'un site, améliorer l'expérience des utilisateurs et à des fins publicitaires.Pour plus informations, passez en revue vos options de préférences en. En visitant notre site Web, vous acceptez que nous traitions les informations comme décrit dans ladéclaration de confidentialité d’IBM.Pour faciliter la navigation, vos préférences en matière de cookie seront partagées dans les domaines Web d'IBM énumérés ici.
 Regardez cette vidéo pour prévisualiser les étapes de ce tutoriel. Il peut y avoir de légères différences dans l'interface utilisateur présentée dans la vidéo. La vidéo est destinée à accompagner le tutoriel écrit. Cette vidéo fournit une méthode visuelle pour apprendre les concepts et les tâches de cette documentation.
Regardez cette vidéo pour prévisualiser les étapes de ce tutoriel. Il peut y avoir de légères différences dans l'interface utilisateur présentée dans la vidéo. La vidéo est destinée à accompagner le tutoriel écrit. Cette vidéo fournit une méthode visuelle pour apprendre les concepts et les tâches de cette documentation.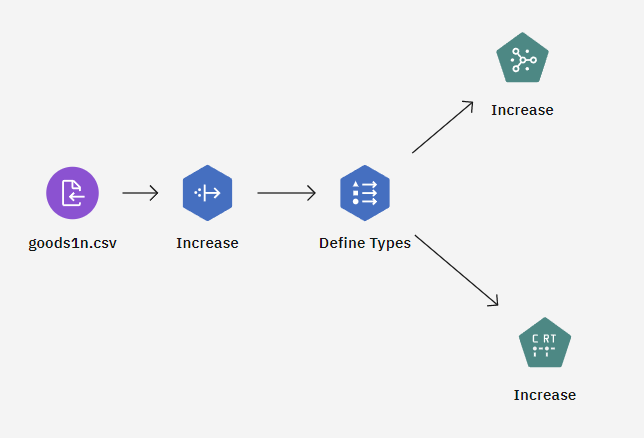
 , choisissez Projets > Voir tous les projets.
, choisissez Projets > Voir tous les projets.

 , et attendez que les pépites du modèle soient générées.
, et attendez que les pépites du modèle soient générées.