Reducir la longitud de la cadena de datos de entrada
Última actualización: 11 feb 2025
Reducir la longitud de la cadena de datos de entrada
Este tutorial ofrece un ejemplo de cuándo puede ser necesario reducir la longitud de la cadena de datos de entrada. Para los modelos de regresión logística binomial y los modelos de clasificador automático que incluyen un modelo de regresión logística binomial, los campos de serie están limitados a un máximo de ocho caracteres. Cuando las cadenas tienen más de ocho caracteres, puede recodificarlas utilizando un nodo Reclasificar.
Este ejemplo se centra en una pequeña parte de un flujo para mostrar el tipo de errores que pueden generarse con cadenas demasiado largas, y explica cómo utilizar el nodo Reclassify para cambiar los detalles de la cadena a una longitud aceptable. Aunque el ejemplo utiliza un nodo de Regresión Logística binomial, también puede utilizar el nodo Auto Clasificador para generar un modelo de Regresión Logística binomial.
Vista previa de la guía de aprendizaje
Vea este vídeo para obtener una vista preliminar de los pasos de esta guía de aprendizaje. Puede haber ligeras diferencias en la interfaz de usuario que se muestra en el vídeo. El vídeo pretende ser un complemento del tutorial escrito. Este vídeo ofrece un método visual para aprender los conceptos y tareas de esta documentación.
Pruebe el tutorial
En esta guía de aprendizaje, realizará estas tareas:
Ejemplo de flujo de modelización y conjunto de datos
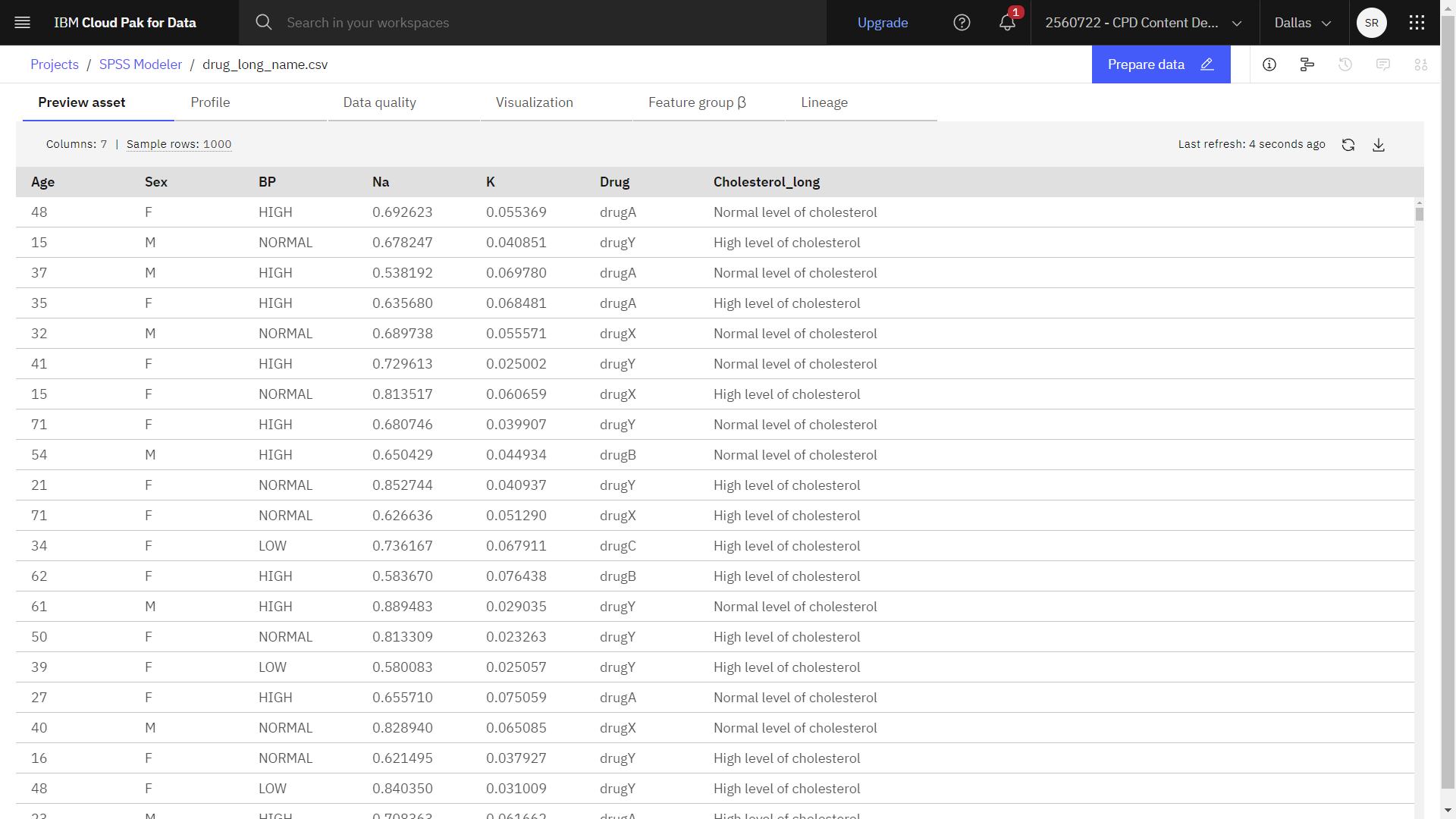
Este tutorial utiliza el flujo Reducir la longitud de la cadena de datos de entrada en el proyecto de ejemplo. El archivo de datos utilizado es drug_long_name.csv. La siguiente imagen muestra el flujo del modelador de muestra.
Figura 1. Flujo del modelador de muestras
La siguiente imagen muestra el conjunto de datos de muestra.Figura 2. Muestra de datos
Tarea 1: Abrir el proyecto de ejemplo
El proyecto de muestra contiene varios conjuntos de datos y flujos de modelado de muestra. Si aún no tiene el proyecto de muestra, consulte el tema Tutoriales para crear el proyecto de muestra. A continuación, siga estos pasos para abrir el proyecto de ejemplo:
En Cloud Pak for Data, en el menú de navegación, elija Proyectos > Ver todos los proyectos.
Haga clic en ProyectoSPSS Modeler.
Haga clic en la pestaña Activos para ver los conjuntos de datos y los flujos del modelador.
Compruebe su progreso
La siguiente imagen muestra la pestaña Activos del proyecto. Ya está preparado para trabajar con el flujo del modelador de ejemplo asociado a este tutorial.
Reducir la longitud de la cadena de datos de entrada incluye varios nodos. Siga estos pasos para examinar el nodo Activo de Datos y Tipo:
En la pestaña Activos, abra el flujo del modelador Reducir longitud de cadena de datos de entrada y espere a que se cargue el lienzo.
Haga doble clic en el nodo drug_long_name.csv. Este nodo es un nodo de Activo de Datos que apunta al archivo drug_long_name.csv en el proyecto.
Revise las propiedades del formato de archivo.
Opcional: Haga clic en Vista previa de datos para ver el conjunto de datos completo.
Haga doble clic en el nodo Tipo después del nodo Activo de datos. Este nodo especifica las propiedades de los campos, como el nivel de medición (el tipo de datos que contiene el campo) y la función de cada campo como objetivo o entrada en el modelado. El nivel de medición es una categoría que indica el tipo de datos del campo. El archivo de datos de origen utiliza tres niveles de medición diferentes:
Un campo continuo (como el campo " Age ") contiene valores numéricos continuos.
Un campo Nominal (como el campo " Drug ") tiene dos o más valores distintos; en este caso, " drugA o " drugB.
Un campo Bandera (como el campo " Sex ) describe datos con múltiples valores distintos que tienen un orden inherente; en este caso, " F, y " M.
Figura 3. Propiedades del nodo type
Para cada campo, el nodo Tipo también especifica una función para indicar el papel que desempeña cada campo en el modelado. La función se establece en Objetivo para el campo " Cholesterol_long, que es el campo que indica si un cliente tiene un nivel normal o alto de colesterol. El objetivo es el campo para el que desea predecir el valor.
Para los demás campos, la función es "Entrada". Los campos de entrada se conocen a veces como predictores, o campos cuyos valores se utilizan en el algoritmo de modelado para predecir el valor del campo objetivo.
Opcional: Haga clic en Vista previa de datos para ver el conjunto de datos filtrados.
Compruebe su progreso
La siguiente imagen muestra el nodo Tipo. Ahora está listo para ver el nodo Logística.
En esta tarea, ejecutas el modelo y descubres un error, Sigue estos pasos para reclasificar los valores y evitar el error:
Desde la sección Modelado de la paleta, arrastre el nodo Logística al lienzo y conéctelo al nodo Tipo existente después del nodo Activo de Datos.
Haga doble clic en el nodo Colesterol_largo para ver sus propiedades.
Seleccione el procedimiento Binomial (en lugar del procedimiento Multinomial por defecto).
Se utiliza un modelo binomial cuando el campo objetivo es una bandera o un campo nominal con dos valores discretos.
Se utiliza un modelo Multinomial cuando el campo objetivo es un campo nominal con más de dos valores.
Pulse Guardar.
Pase el cursor sobre el nodo Cholesterol_long y haga clic en el icono Ejecutar. Un mensaje de error le advierte de que los valores de la cadena ' Cholesterol_long ' son demasiado largos. Puede utilizar un nodo Reclasificar para transformar los valores y solucionar este problema. El nodo Reclasificar es útil para colapsar categorías o reagrupar datos para su análisis.
Figura 4. Notificaciones
Haga doble clic en el nodo Colesterol (Reclasificar) para ver sus propiedades. Observe que el campo de reclasificación es " Cholesterol_long " y el nombre del nuevo campo es " Cholesterol.
Haga clic en Obtener valores y, a continuación, amplíe la sección Reclasificar automáticamente. Añade los valores ' Cholesterol_long ' a la columna de valores original.
En la columna de nuevos valores, para el valor original Nivel alto de colesterol, escriba " High " y para el valor original Nivel normal de colesterol, escriba " Normal. Estos ajustes acortan los valores para evitar el mensaje de error.
Compruebe su progreso
La siguiente imagen muestra el nodo Reclasificar. Ahora está listo para comprobar el nodo Filtro.
Puede especificar propiedades de campo en un nodo Tipo. Siga estos pasos para definir el objetivo en el nodo Tipo:
Haga doble clic en el nodo Tipo después del nodo Filtro para ver sus propiedades.
Haga clic en Leer valores para leer los valores de su fuente de datos y establecer los tipos de medición de los campos. La función indica a los nodos de modelado si los campos son de entrada (campos de predicción) o de destino (campos de predicción) para un proceso de aprendizaje automático. Ambas y Ninguna también son funciones disponibles, junto con Partición, que indica un campo que se utiliza para dividir los registros en muestras separadas para la formación, la prueba y la validación. El valor Split especifica que se construyan modelos separados para cada valor posible del campo.
Para el campo Colesterol, establezca el rol en Objetivo.
Pulse Guardar.
Compruebe su progreso
La siguiente imagen muestra el nodo Tipo. Ya está listo para generar el modelo.
Este ejemplo muestra el tipo de errores que pueden generarse con cadenas demasiado largas, y explica cómo utilizar el nodo Reclasificar para cambiar los detalles de la cadena a una longitud aceptable. Aunque el ejemplo utiliza un nodo de Regresión Logística binomial, es igualmente aplicable cuando se utiliza el nodo Auto Clasificador para generar un modelo de Regresión Logística binomial.
Use this interactive map to learn about the relationships between your tasks, the tools you need, the services that provide the tools, and where you use the tools.
Select any task, tool, service, or workspace
You'll learn what you need, how to get it, and where to use it.
Tasks you'll do
Some tasks have a choice of tools and services.
Tools you'll use
Some tools perform the same tasks but have different features and levels of automation.
Create a notebook in which you run Python, R, or Scala code to prepare, visualize, and analyze data, or build a model.
Automatically analyze your tabular data and generate candidate model pipelines customized for your predictive modeling problem.
Create a visual flow that uses modeling algorithms to prepare data and build and train a model, using a guided approach to machine learning that doesn’t require coding.
Create and manage scenarios to find the best solution to your optimization problem by comparing different combinations of your model, data, and solutions.
Create a flow of ordered operations to cleanse and shape data. Visualize data to identify problems and discover insights.
Automate the model lifecycle, including preparing data, training models, and creating deployments.
Work with R notebooks and scripts in an integrated development environment.
Create a federated learning experiment to train a common model on a set of remote data sources. Share training results without sharing data.
Deploy and run your data science and AI solutions in a test or production environment.
Find and share your data and other assets.
Import asset metadata from a connection into a project or a catalog.
Enrich imported asset metadata with business context, data profiling, and quality assessment.
Measure and monitor the quality of your data.
Create and run masking flows to prepare copies of data assets that are masked by advanced data protection rules.
Create your business vocabulary to enrich assets and rules to protect data.
Track data movement and usage for transparency and determining data accuracy.
Track AI models from request to production.
Create a flow with a set of connectors and stages to transform and integrate data. Provide enriched and tailored information for your enterprise.
Create a virtual table to segment or combine data from one or more tables.
Measure outcomes from your AI models and help ensure the fairness, explainability, and compliance of all your models.
Replicate data to target systems with low latency, transactional integrity and optimized data capture.
Consolidate data from the disparate sources that fuel your business and establish a single, trusted, 360-degree view of your customers.
Services you can use
Services add features and tools to the platform.
Develop powerful AI solutions with an integrated collaborative studio and industry-standard APIs and SDKs. Formerly known as Watson Studio.
Quickly build, run and manage generative AI and machine learning applications with built-in performance and scalability. Formerly known as Watson Machine Learning.
Discover, profile, catalog, and share trusted data in your organization.
Create ETL and data pipeline services for real-time, micro-batch, and batch data orchestration.
View, access, manipulate, and analyze your data without moving it.
Monitor your AI models for bias, fairness, and trust with added transparency on how your AI models make decisions.
Provide efficient change data capture and near real-time data delivery with transactional integrity.
Improve trust in AI pipelines by identifying duplicate records and providing reliable data about your customers, suppliers, or partners.
Increase data pipeline transparency so you can determine data accuracy throughout your models and systems.
Where you'll work
Collaborative workspaces contain tools for specific tasks.
Where you work with data.
> Projects > View all projects
Where you find and share assets.
> Catalogs > View all catalogs
Where you deploy and run assets that are ready for testing or production.
> Deployments
Where you manage governance artifacts.
> Governance > Categories
Where you virtualize data.
> Data > Data virtualization
Where you consolidate data into a 360 degree view.
Acerca de las cookies de este sitioNuestros sitios web necesitan algunas cookies para funcionar correctamente (necesarias). Además, se pueden utilizar otras cookies con su consentimiento para analizar el uso del sitio, para mejorar la experiencia del usuario y para publicidad.Para obtener más información, consulte sus opciones de. Al visitar nuestro sitio web, acepta que procesemos la información tal y como se describe en ladeclaración de privacidad de IBM.Para facilitar la navegación, sus preferencias de cookies se compartirán entre los dominios web de IBM que se muestran aquí.
 Vea este vídeo para obtener una vista preliminar de los pasos de esta guía de aprendizaje. Puede haber ligeras diferencias en la interfaz de usuario que se muestra en el vídeo. El vídeo pretende ser un complemento del tutorial escrito. Este vídeo ofrece un método visual para aprender los conceptos y tareas de esta documentación.
Vea este vídeo para obtener una vista preliminar de los pasos de esta guía de aprendizaje. Puede haber ligeras diferencias en la interfaz de usuario que se muestra en el vídeo. El vídeo pretende ser un complemento del tutorial escrito. Este vídeo ofrece un método visual para aprender los conceptos y tareas de esta documentación.
 , elija Proyectos > Ver todos los proyectos.
, elija Proyectos > Ver todos los proyectos.


 . Un mensaje de error le advierte de que los valores de la cadena '
. Un mensaje de error le advierte de que los valores de la cadena ' 



