This tutorial provides an example of when you might need to reduce the input data string
length. For binomial logistic regression, and auto classifier models that include a binomial
logistic regression model, string fields are limited to a maximum of eight characters. Where strings
are more than eight characters, you can recode them using a Reclassify node.
This example focuses on a small part of a flow to show the type of errors that might be generated
with overlong strings, and explains how to use the Reclassify node to change the string
details to an acceptable length. Although the example uses a binomial Logistic Regression
node, you can also use the Auto Classifier node to generate a binomial Logistic Regression
model.
Preview the tutorial
Watch this video to preview the steps in this tutorial. There might
be slight differences in the user interface that is shown in the video. The video is intended to be
a companion to the written tutorial. This video provides a visual method to learn the concepts and
tasks in this documentation.
This tutorial uses the Reducing Input Data String Length flow in the sample project. The
data file used is drug_long_name.csv. The following image shows the sample modeler flow.
Figure 1. Sample modeler flow
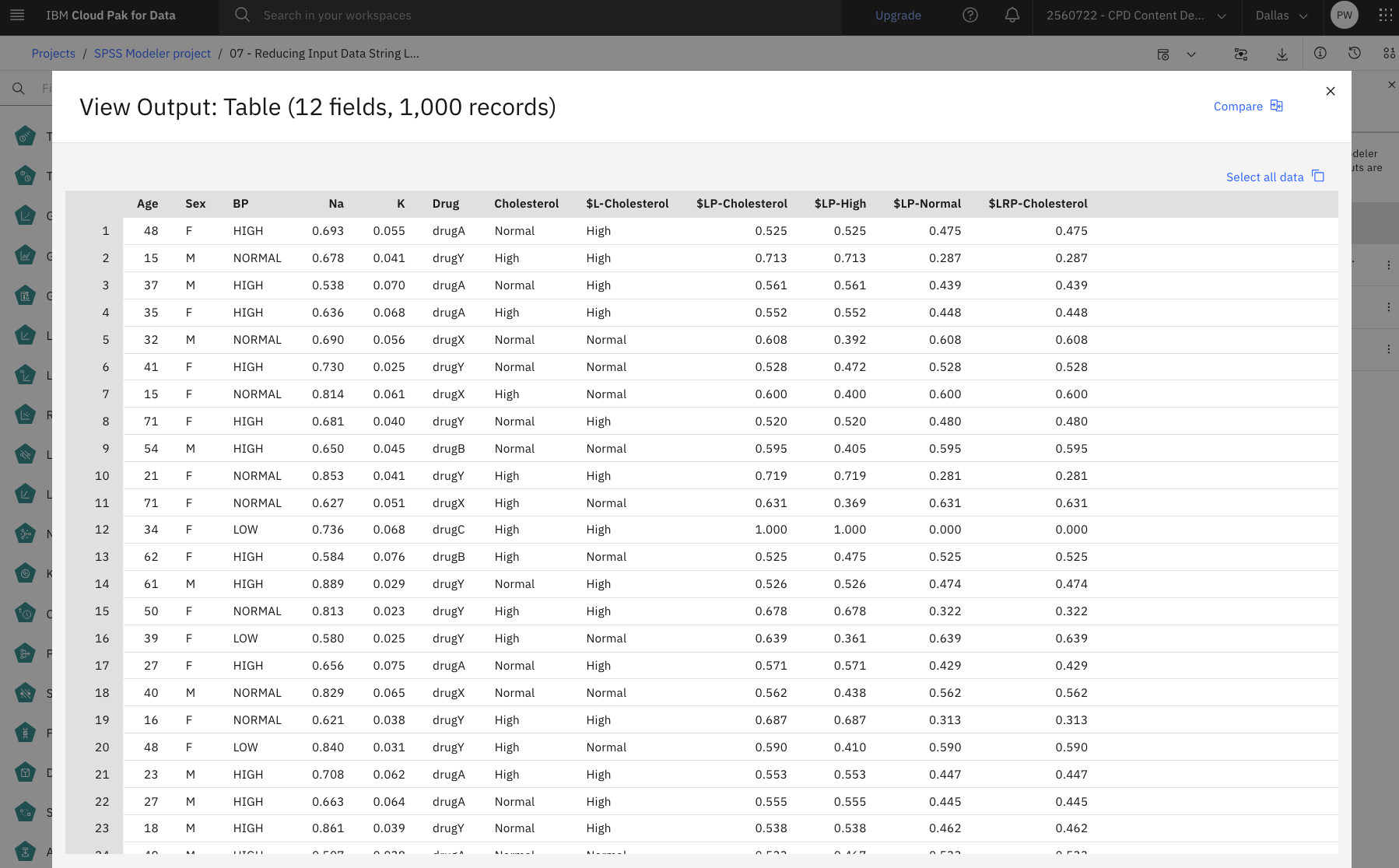
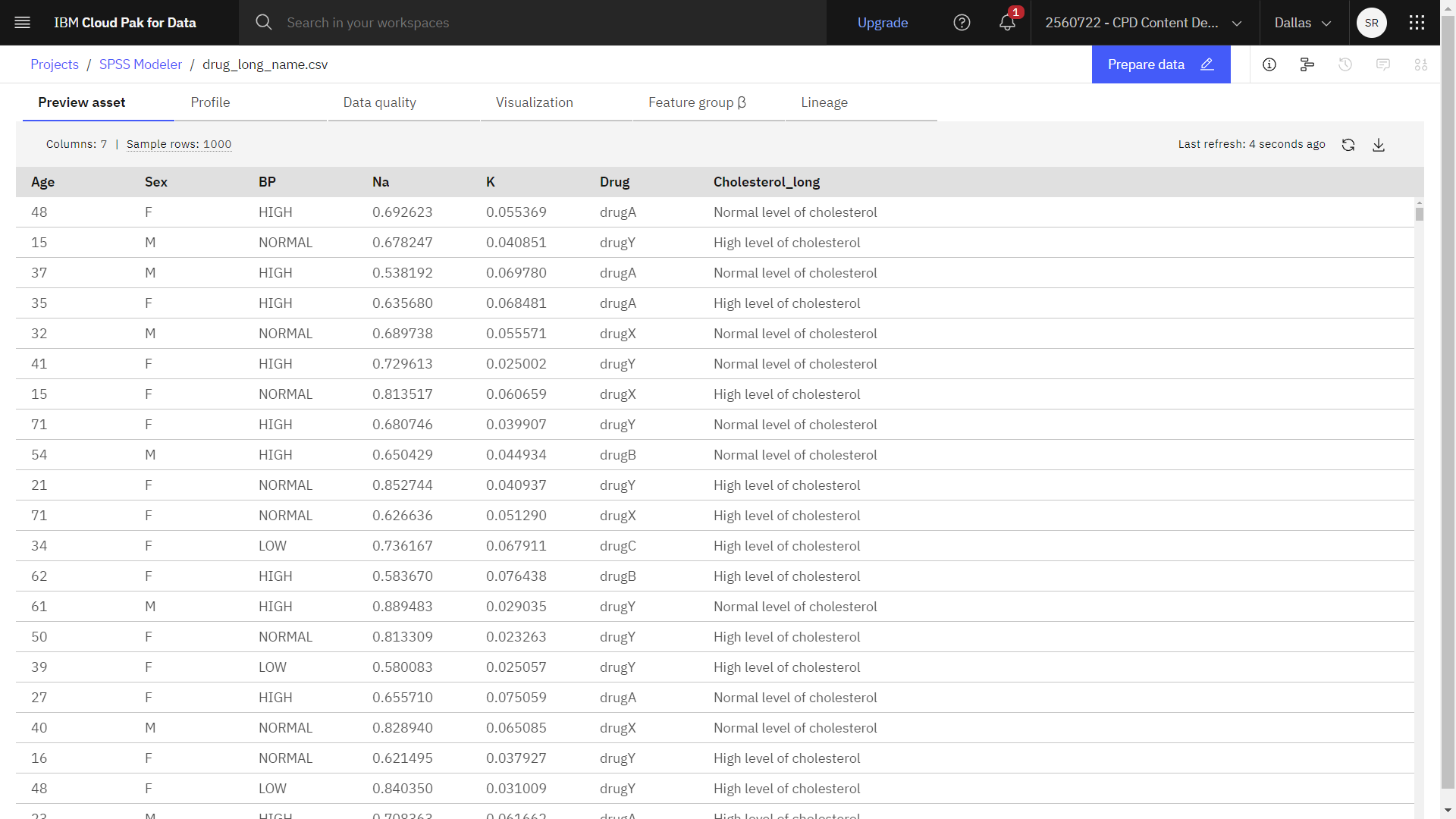
The following image shows the sample data set.Figure 2. Sample data set
Task 1: Open the sample project
The sample project contains several data sets and sample modeler flows. If you don't already have
the sample project, then refer to the Tutorials topic to create the sample project. Then follow these steps to open the sample
project:
In Cloud Pak for Data, from the Navigation menu, choose
Projects > View all Projects.
Click SPSS Modeler Project.
Click the Assets tab to see the data sets and modeler flows.
Check your progress
The following image shows the project Assets tab. You are now ready to work with the sample
modeler flow associated with this tutorial.
Reducing Input Data String Length includes several nodes. Follow these steps to examine the
Data Asset and Type node:
From the Assets tab, open the Reducing Input Data String Length
modeler flow, and wait for the canvas to load.
Double-click the drug_long_name.csv node. This node is a Data Asset node that
points to the drug_long_name.csv file in the project.
Review the File format properties.
Optional: Click Preview data to see the full data set.
Double-click the Type node after the Data Asset node. This node specifies field
properties, such as measurement level (the type of data that the field contains), and the role of
each field as a target or input in modeling. The measurement level is a category that indicates the
type of data in the field. The source data file uses three different measurement levels:
A Continuous field (such as the Age
field) contains continuous numeric values.
A Nominal field (such as the Drug field) has two or more distinct
values; in this case, drugA or drugB.
A Flag field (such as the Sex field) describes data with multiple
distinct values that have an inherent order; in this case, F, and
M.
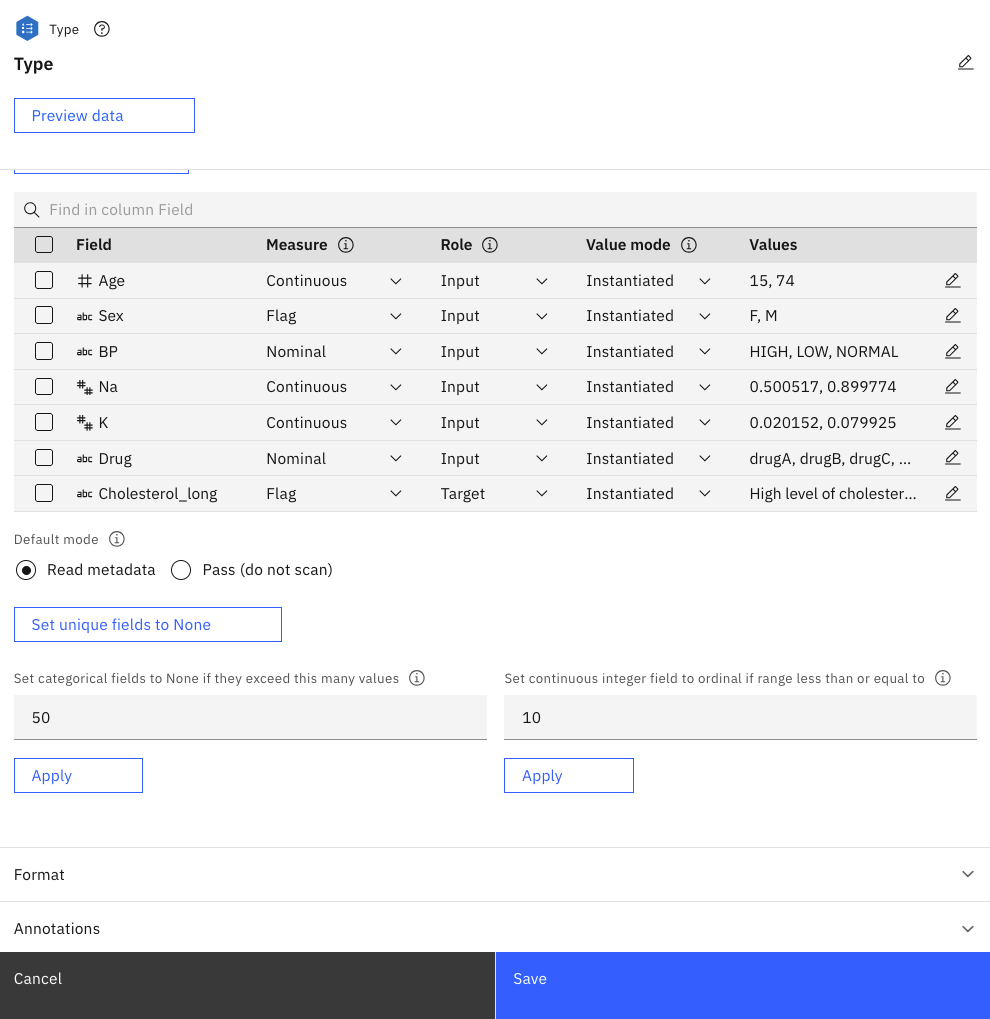
Figure 3. Type node properties
For each field, the Type node also
specifies a role to indicate the part that each field plays in modeling. The Role is set to
Target for the field Cholesterol_long, which is the field that indicates
whether a customer has Normal or High level of cholesterol. The target is the field for
which you want to predict the value.
Role is set to
Input for the other fields. Input fields are sometimes known as predictors, or
fields whose values are used by the modeling algorithm to predict the value of the target
field.
Optional: Click Preview data to see the filtered data set.
Check your progress
The following image shows the Type node. You are now ready to view the Logistic
node.
In this task, you run the model and discover an error, Follow these steps to reclassify the
values to avoid the error:
From the Modeling section in the palette, drag the Logistic node onto the canvas
and connect it to the existing Type node after the Data Asset node.
Double-click the Cholesterol_long node to see its properties.
Select the Binomial procedure (instead of the default Multinomial procedure).
A Binomial model is used when the target field is a flag or nominal field with two
discrete values.
A Multinomial model is used when the target field is a nominal field with more than two
values.
Click Save.
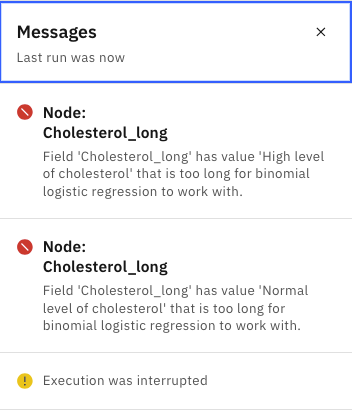
Hover over the Cholesterol_long node, and click the Run icon . An error message warns you that the
Cholesterol_long string values are too long. You can use a Reclassify node
to transform the values to fix this issue. Reclassify node is useful for collapsing
categories or regrouping data for analysis.
Figure 4. Notifications
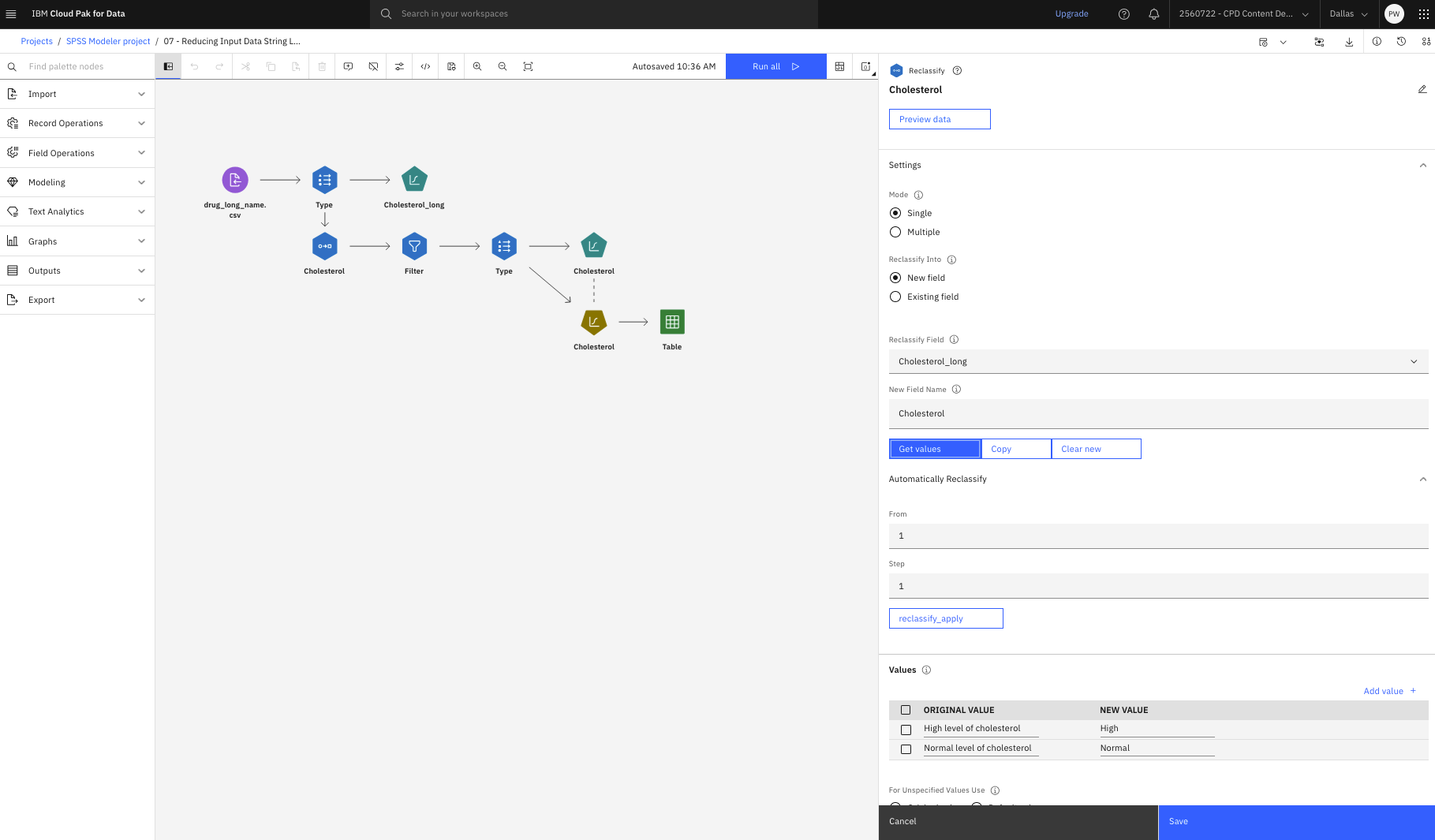
Double-click the Cholesterol (Reclassify) node to see its properties. Notice that the
Reclassify Field is set to Cholesterol_long and the New Field Name is
Cholesterol.
Click Get values and then expand the Automatically Reclassify section. Add the
Cholesterol_long values to the original value column.
In the new value column, for the High level of cholesterol original value, type
High and for the Normal level of cholesterol original value, type
Normal. These settings shorten the values to avoid the error message.
Check your progress
The following image shows the Reclassify node. You are now ready to check the
Filter node.
You can specify field properties in a Type node. Follow these steps to define the target
in the Type node:
Double-click the Type node after the Filter node to view its properties.
Click Read values to read the values from your data source and set the field measurement
types. The Role tells modeling nodes whether fields are Input (predictor fields) or
Target (predicted fields) for a machine-learning process. Both and None are
also available roles, along with Partition, which indicates a field that is used to partition
records into separate samples for training, testing, and validation. The value Split
specifies that separate models are built for each possible value of the field.
For the Cholesterol field, set the role to Target.
Click Save.
Check your progress
The following image shows the Type node. You are now ready to generate the model.
This example showed you the type of errors that might be generated with overlong strings, and
explains how to use the Reclassify node to change the string details to an acceptable length.
Although the example uses a binomial Logistic Regression node, it is equally applicable when
using the Auto Classifier node to generate a binomial Logistic Regression model.
Use this interactive map to learn about the relationships between your tasks, the tools you need, the services that provide the tools, and where you use the tools.
Select any task, tool, service, or workspace
You'll learn what you need, how to get it, and where to use it.
Tasks you'll do
Some tasks have a choice of tools and services.
Tools you'll use
Some tools perform the same tasks but have different features and levels of automation.
Create a notebook in which you run Python, R, or Scala code to prepare, visualize, and analyze data, or build a model.
Automatically analyze your tabular data and generate candidate model pipelines customized for your predictive modeling problem.
Create a visual flow that uses modeling algorithms to prepare data and build and train a model, using a guided approach to machine learning that doesn’t require coding.
Create and manage scenarios to find the best solution to your optimization problem by comparing different combinations of your model, data, and solutions.
Create a flow of ordered operations to cleanse and shape data. Visualize data to identify problems and discover insights.
Automate the model lifecycle, including preparing data, training models, and creating deployments.
Work with R notebooks and scripts in an integrated development environment.
Create a federated learning experiment to train a common model on a set of remote data sources. Share training results without sharing data.
Deploy and run your data science and AI solutions in a test or production environment.
Find and share your data and other assets.
Import asset metadata from a connection into a project or a catalog.
Enrich imported asset metadata with business context, data profiling, and quality assessment.
Measure and monitor the quality of your data.
Create and run masking flows to prepare copies of data assets that are masked by advanced data protection rules.
Create your business vocabulary to enrich assets and rules to protect data.
Track data movement and usage for transparency and determining data accuracy.
Track AI models from request to production.
Create a flow with a set of connectors and stages to transform and integrate data. Provide enriched and tailored information for your enterprise.
Create a virtual table to segment or combine data from one or more tables.
Measure outcomes from your AI models and help ensure the fairness, explainability, and compliance of all your models.
Replicate data to target systems with low latency, transactional integrity and optimized data capture.
Consolidate data from the disparate sources that fuel your business and establish a single, trusted, 360-degree view of your customers.
Services you can use
Services add features and tools to the platform.
Develop powerful AI solutions with an integrated collaborative studio and industry-standard APIs and SDKs. Formerly known as Watson Studio.
Quickly build, run and manage generative AI and machine learning applications with built-in performance and scalability. Formerly known as Watson Machine Learning.
Discover, profile, catalog, and share trusted data in your organization.
Create ETL and data pipeline services for real-time, micro-batch, and batch data orchestration.
View, access, manipulate, and analyze your data without moving it.
Monitor your AI models for bias, fairness, and trust with added transparency on how your AI models make decisions.
Provide efficient change data capture and near real-time data delivery with transactional integrity.
Improve trust in AI pipelines by identifying duplicate records and providing reliable data about your customers, suppliers, or partners.
Increase data pipeline transparency so you can determine data accuracy throughout your models and systems.
Where you'll work
Collaborative workspaces contain tools for specific tasks.
Where you work with data.
> Projects > View all projects
Where you find and share assets.
> Catalogs > View all catalogs
Where you deploy and run assets that are ready for testing or production.
> Deployments
Where you manage governance artifacts.
> Governance > Categories
Where you virtualize data.
> Data > Data virtualization
Where you consolidate data into a 360 degree view.
About cookies on this siteOur websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising.For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
 Watch this video to preview the steps in this tutorial. There might
be slight differences in the user interface that is shown in the video. The video is intended to be
a companion to the written tutorial. This video provides a visual method to learn the concepts and
tasks in this documentation.
Watch this video to preview the steps in this tutorial. There might
be slight differences in the user interface that is shown in the video. The video is intended to be
a companion to the written tutorial. This video provides a visual method to learn the concepts and
tasks in this documentation.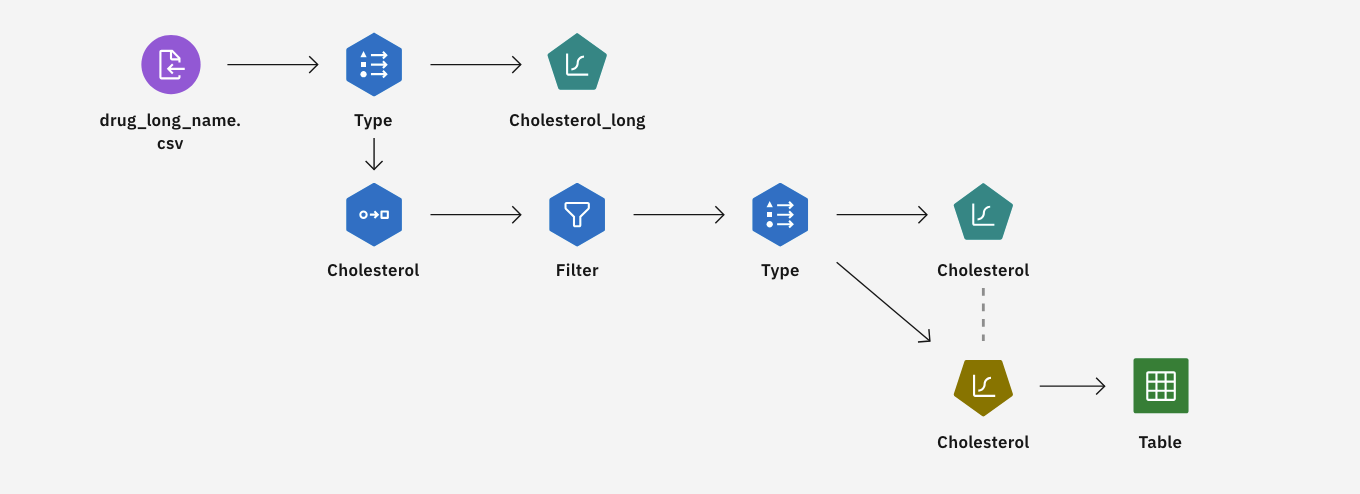
 , choose
Projects > View all Projects.
, choose
Projects > View all Projects.

 . An error message warns you that the
. An error message warns you that the