You can browse the model to understand how scoring works. However, to evaluate how accurately the model works, you need to score some records. Scoring records is the process of comparing the actual results to the responses that the model predicted. To evaluate the model, you can score the same records that were used to estimate the model. Comparing the same records allows you to compare the observed and predicted responses.

- To see the scores or predictions, attach the Table
node to the model nugget. Hover over the Table node and click the
Run icon
 . A table is
generated and added to the Outputs panel. Double-click it to open it.
. A table is
generated and added to the Outputs panel. Double-click it to open it.The table displays the predicted scores in the
$R-Credit ratingfield, which the model created. You can compare these values to the originalCredit ratingfield that contains the actual responses.By convention, the names of the fields that were generated during scoring are based on the target field, but with a standard prefix.$Gand$GEare prefixes for predictions that the Generalized Linear Model generates$Ris the prefix for predictions that the CHAID model generates$RCis for confidence values$Xis typically generated by using an ensemble$XR,$XS,$XFare used as prefixes in cases where the target field is a Continuous, Categorical, Set, or Flag field
A confidence value is the model's own estimation, on a scale from 0.0 to 1.0, of how accurate each predicted value is.
Figure 2. Table showing generated scores and confidence values 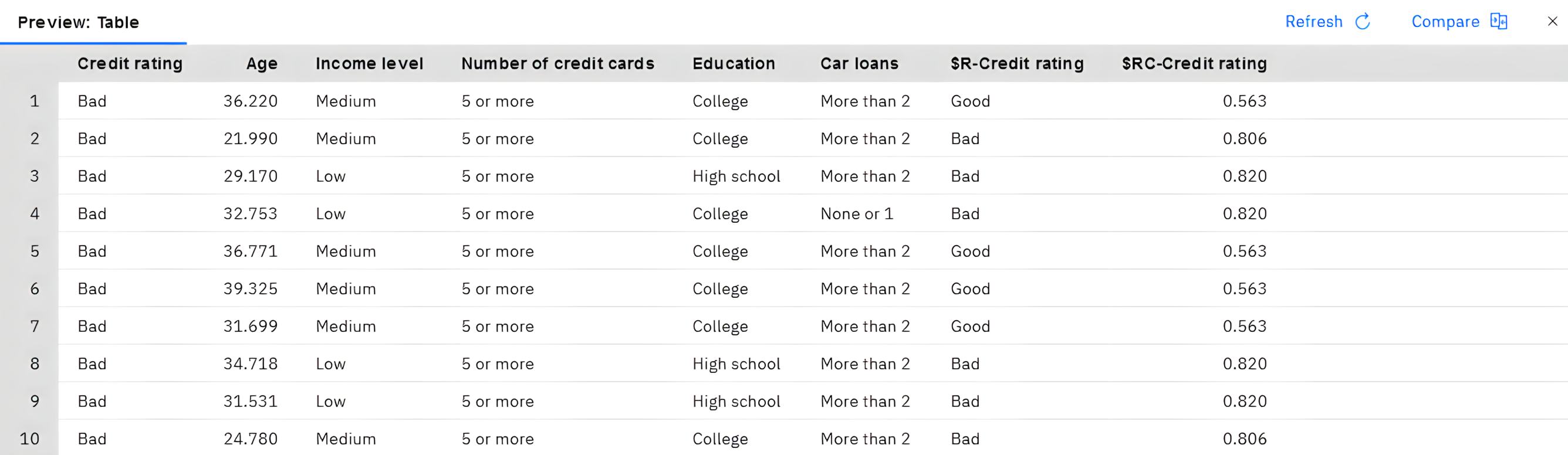
As expected, the predicted value matches the actual responses for many records, but not all. The reason for this is that each CHAID terminal node has a mix of responses. The prediction matches the most common one, but it is wrong for all the others in that node. (Recall the 18% minority of low-income customers who did not default.)
To avoid this issue, you could continue splitting the tree into smaller and smaller branches until every node was 100% pure—all Good or Bad with no mixed responses. But such a model is complicated and is unlikely to generalize well to other data sets.
To find out exactly how many predictions are correct, you could read through the table and tally the number of records where the value of the predicted field
$R-Credit ratingmatches the value ofCredit rating. However, it is easiest to use an Analysis node, which automatically tracks records where these values match. - Connect the model nugget to the Analysis node.
- Hover over the Analysis node and click
the Run icon . An
Analysis entry is added to the Outputs panel.
Double-click it to open it.
The analysis shows that for 1960 out of 2464 records—over 79%—the value that the model predicted matched the actual response.
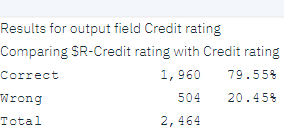
This result is limited by the fact that the records that you scored are the same ones that you used to estimate the model. In a real situation, you could use a Partition node to split the data into separate samples for training and evaluation. By using one sample partition to generate the model and another sample to test it, you can get a better indication of how well it generalizes to other data sets.
The Analysis node can be used to test the model against records for which you already know the actual result. The next stage illustrates how you can use the model to score records for which you don't know the outcome. For example, this data set might include people who are not currently customers of the bank, but who are prospective targets for a promotional mailing.