About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
資料の 英語版 に戻る
モデル作成の概要
図1: サンプルモデラーの流れ

図2: ディシジョン・ツリー・モデル






モデル作成の概要
最終更新: 2025年2月11日
このチュートリアルでは、SPSS® Modelerを使用したモデリングの入門を提供します。 モデルとは、一連の入力フィールドまたは変数に基づいて結果を予測するために使用できるルール、数式、または方程式のセットである。 例えば、金融機関は、ローン申込者について既に知られている情報に基づいて、ローン申込者が良いリスクになりそうか悪いリスクになりそうかを予測するモデルを使うかもしれない。
チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオで紹介されているユーザーインターフェースには若干の違いがあるかもしれません。 このビデオは、文書によるチュートリアルに付随するものです。 このビデオは、このドキュメントのコンセプトとタスクを学ぶための視覚的な方法を提供します。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 ビデオで紹介されているユーザーインターフェースには若干の違いがあるかもしれません。 このビデオは、文書によるチュートリアルに付随するものです。 このビデオは、このドキュメントのコンセプトとタスクを学ぶための視覚的な方法を提供します。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
このチュートリアルでは、サンプル・プロジェクトの「モデリング入門」フローを使用します。 使用したデータファイルはtree_credit.csvである。 次の図は、モデラーのフロー例を示しています。
結果を予測する能力は予測分析の中心的な目標であり、モデリングプロセスを理解することがSPSS Modelerフローを使用する鍵です。
この例のモデルは、銀行が、将来のローン申請者がローンで債務不履行になる可能性があるかどうかを予測する方法を示しています。 これらの顧客は以前に銀行から融資を受けていたため、顧客のデータは銀行のデータベースに保管されています。 このモデルは、顧客のデータを使用して、顧客がデフォルトになる可能性を判別します。
モデルの重要な部分は、そのモデルに入るデータです。 銀行は、顧客がローンを返済したか (信用格付け = 良好)、債務不履行になったか (信用格付け = 不良) など、顧客に関する履歴情報のデータベースを保持しています。 銀行は、この既存のデータを使用してモデルを作成したいと考えています。 次のフィールドが使用されています。
| フィールド名 | 説明 |
|---|---|
| Credit_rating | 信用格付け: 0=悪い、1=良い、9=欠損値 |
| Age | 年齢 |
| Income | 収入レベル: 1=低、2=中、3=高 |
| Credit_cards | 所有するクレジット・カード数: 1=5 枚未満、2=5 枚以上 |
| Education | 学歴: 1=高校、2=大学 |
| Car_loans | 利用中のカー・ローン数: 1=1 件以下、2=2 件以上 |
この例では、一連のデシジョン・ルールを使用してレコードを分類 (および応答を予測) する デシジョン・ツリー ・モデルを使用します。
例えば、このデシジョン・ルールは、収入が中程度の範囲にあり、クレジット・カードの数が 5 未満の場合に、良好な信用格付けを持つレコードとして分類します。
IF income = Medium AND cards <5 THEN -> 'Good'
ディシジョン・ツリー・モデルを使用して、顧客の 2 つのグループの特性を分析し、債務不履行の尤度を予測できます。
この例では、一般的な概要を説明するために CHAID (カイ 2 乗自動反復検出) モデルを使用しますが、ほとんどの概念は SPSS Modelerの他のモデル・タイプにも広く適用されます。
タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプル・プロジェクトをまだお持ちでない場合は、チュートリアル・トピックを参照してサンプル・プロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataの ナビゲーションメニュー「
 」から、Projects > View all Projetsをc選択します。
」から、Projects > View all Projetsをc選択します。 - SPSS ModelerProjectをクリックします。
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。
タスク 2: データアセットとタイプノードを調べる
モデリング入門モデラー・フローにはいくつかのノードがある。 以下の手順に従って、データ・アセットと タイプ・ノードを調べます。
- アセット」タブで「モデリング入門」フローを開き、キャンバスがロードされるのを待ちます。
- tree_credit.csvノードをダブルクリックします。 このノードは、プロジェクト内のtree_credit.csvファイルを指すData Assetノードです。 ソース・ノードで測定を指定する場合、フローに別のTypeノードを含める必要はない。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
- Typeノードをダブルクリックする。 このノードは、測定レベル(フィールドが含むデータのタイプ)などのフィールド・プロパティや、モデリングにおけるターゲットまたは入力としての各フィールドの役割を指定する。 測定の尺度は、フィールドのデータの種類を示すカテゴリーです。 ソース・データ・ファイルは3つの異なる測定レベルを使用する:
- 連続フィールド('
Age - 公称フィールド('
EducationCollegeHigh school - 順序フィールド('
Income levelLowMediumHigh
図3: データ型ノード 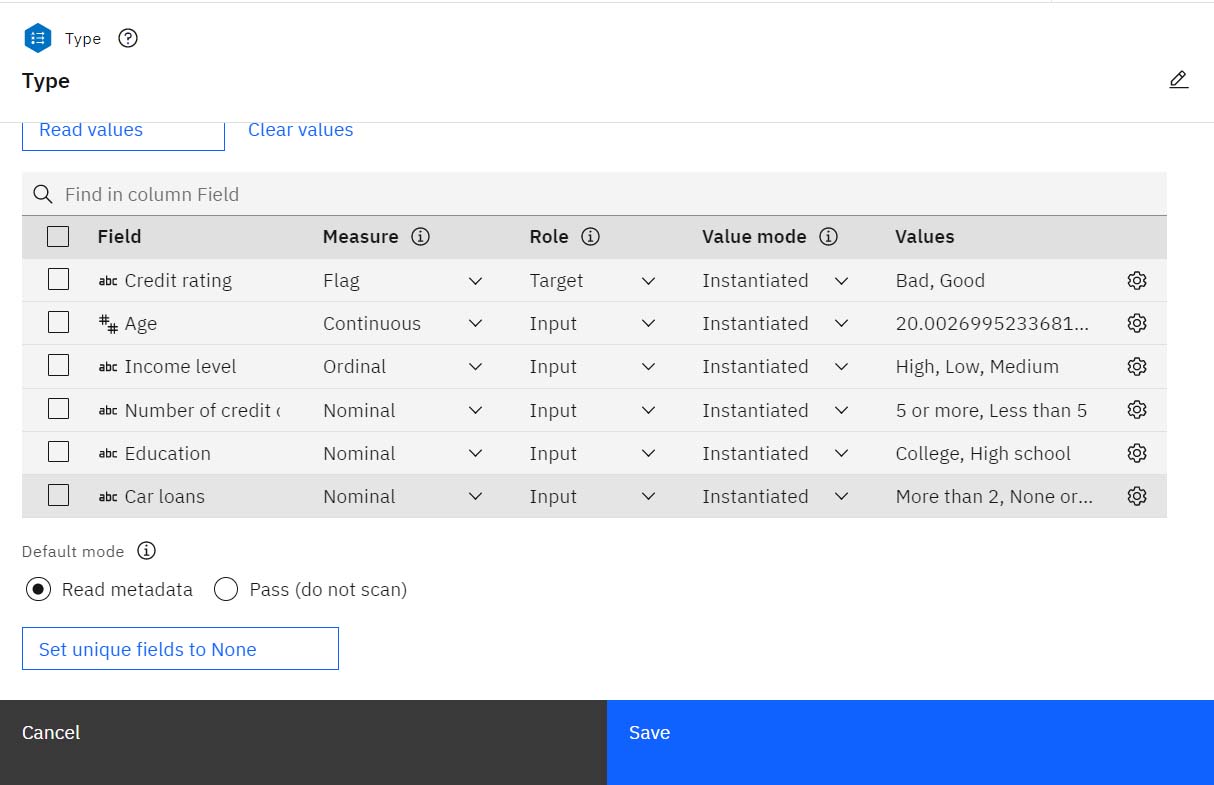
各フィールドについて、Typeノードは、各フィールドがモデリングで果たす役割を示す役割も指定する。 The role is set to ターゲット for the field
Credit rating他のフィールドの役割は Inputに設定されている。 入力フィールドは、予測フィールドと呼ばれる場合があります。モデル作成アルゴリズムは、このフィールドの値を使用して対象フィールドの値を予測します。
- 連続フィールド('
- オプション:データのプレビューをクリックすると、タイプ・プロパティが適用されたデータが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はTypeノードを示している。 これでModelingノードの設定は完了です。
タスク3: モデリングノードの構成
モデリング・ノードは、フローが実行されるとモデル・ナゲットを生成する。 この例ではCHAIDノードを使用している。 CHAID(カイ二乗自動相互作用検出)は、カイ二乗統計として知られる特定の統計量を用いて決定木を構築する分類手法である。 このノードはカイ二乗統計を使って、決定木の分割に最適な場所を決定する。 以下の手順に従って、モデリング・ノードを設定する:
- Credit rating (CHAID)」ノードをダブルクリックしてプロパティを表示します。
- Fieldsセクションで、Use settings defined in this nodeオプションに注目してください。 このオプションは、Typeノードのフィールド情報を使用する代わりに、ここで指定されたターゲットとフィールドを使用するようにノードに指示します。 このチュートリアルでは、Use settings defined in this nodeオプションはオフのままにしておきます。
- 目的」セクションを展開する。 この場合、デフォルト値が適切である。 あなたの目的は、新しいモデルを構築し、標準モデルを作成し、実行後にモデルノードを生成することです。
- 停止ルールセクションを展開する。 この例では、ツリーをかなりシンプルに保つために、親ノードと子ノードの最小ケース数を上げて、ツリーの成長を制限します。
- 絶対値を使用する」を選択する。
- 親ブランチの最小レコード数を「
400 - 子ブランチの最小レコード数を「
200
- 保存 をクリックします。
- 信用格付け(CHAID)ノードにカーソルを合わせ、実行アイコン「
 」をクリックする。
」をクリックする。
![]() 進捗状況を確認する
進捗状況を確認する
次の画像は、モデル結果と流れを示している。 これでモデルを探求する準備は整った。
タスク4:モデルの探究
モデラー・フローを実行すると、作成元のモデリング・ノードへのリンクを持つモデル・ナゲットがキャンバスに追加されます。 モデルの詳細を表示するには、以下の手順に従ってください:
- Outputs and models(出力とモデル)ペインで、Credit rating(信用格付け)という名前のモデルをクリックして、モデルを表示します。
- モデル情報をクリックすると、モデルの基本情報が表示されます。
- モデルの推定における各予測変数の相対的な重要性を見るには,Feature Importanceをクリックする. このグラフから、このケースでは収入レベルが最も重要であり、クレジットカードの枚数が次に重要な要因であることがわかる。
図4: フィールドの重要度グラフ 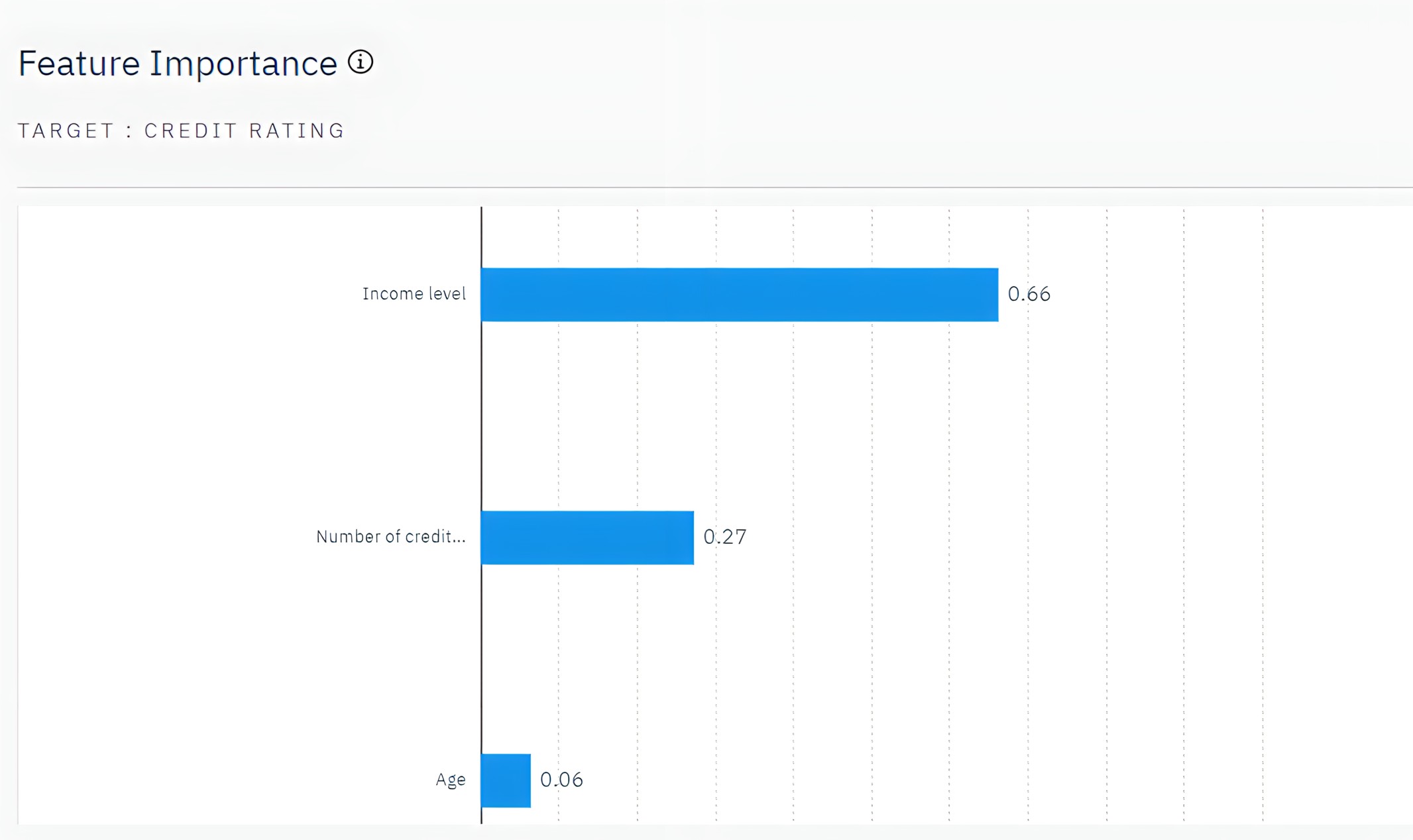
- トップ決定ルールクリックすると、ルールセットの形式で詳細が表示されます。基本的には、さまざまな入力フィールドの値に基づいて子ノードに個々のレコードを割り当てるために使用できる一連のルールです。 決定木の各末端ノードに対して、GoodまたはBadの予測が返される。 終端ノードは、それ以上分割されないツリーノードである。 それぞれの場合において、予測は、そのノードに該当するレコードのモード、つまり最も一般的なレスポンスによって決定される。
図 5. CHAID モデル・ナゲット、ルール・セット 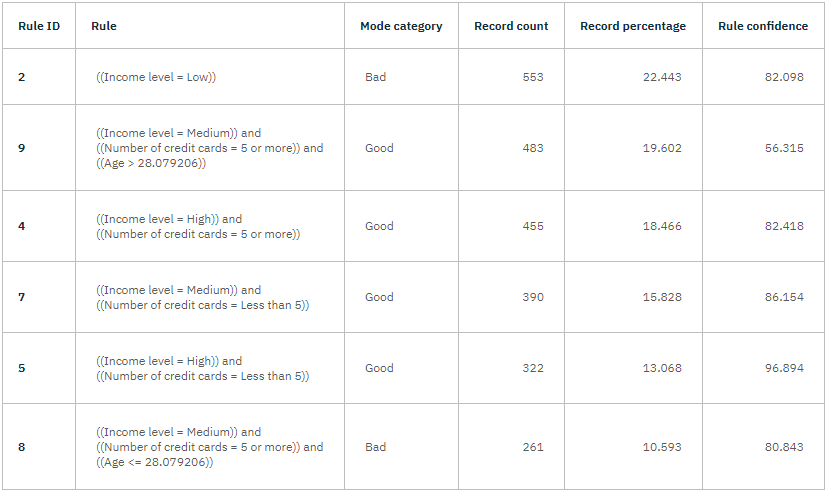
- ツリーダイアグラムをクリックすると、同じモデルがツリー形式で表示され、各決定ポイントにノードが表示されます。 詳細を調べるには、ブランチおよびノードにカーソルを移動します。
図 6. モデル・ナゲット内のツリー図 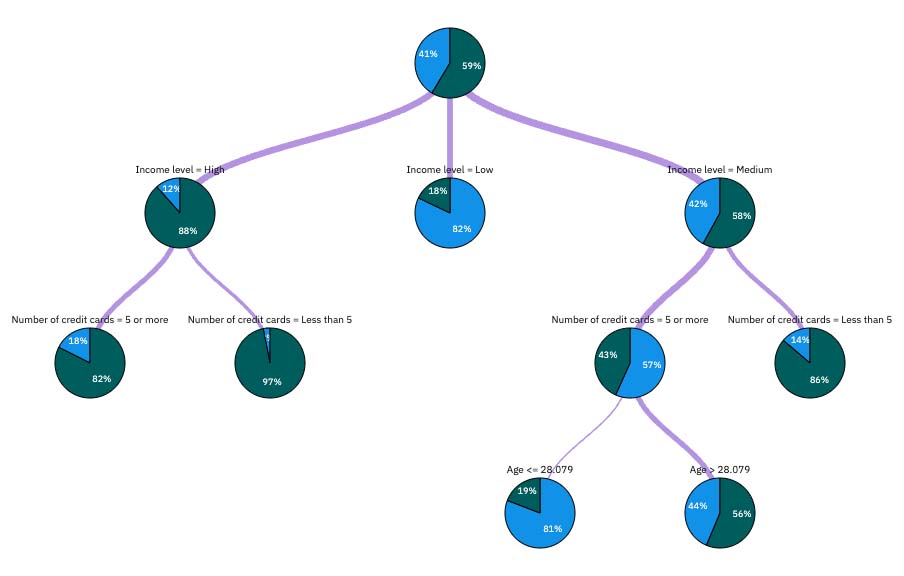
ツリーの最初を見ると、最初のノード(ノード 0)はデータセット内の全レコードの要約を示す。 データ・セット内の 40% を少し超えるケースが、高リスクと分類されています。 40%というのはかなり高い割合だが、この樹木がどのような要因によるものかを知る手がかりになるかもしれない。
最初の分け方は所得レベル別である。 収入レベルが「低」のカテゴリーのレコードは、ノード 2 に割り当てられています。このカテゴリーに高い割合の債務不履行者が含まれているのが分かりますが、驚くことではありません。 当然、このカテゴリーの顧客に融資することは、高いリスクを有します。 しかし、このカテゴリーに属する顧客の18%近くはデフォルトしなかったので、予測が常に正しいとは限らない。 どんなモデルでもすべての反応を予測することは不可能だが、優れたモデルであれば、利用可能なデータに基づいて、各記録について最も可能性の高い反応を予測することができるはずだ。
同じように、高所得の顧客(ノード1)を見ると、ほとんどの顧客(88%以上)が良いリスクを持っていることがわかる。 それでも10人に1人以上が債務不履行に陥った。 このリスクを最小限に抑えるために、融資基準をさらに改善することは可能か?
このモデルが、クレジットカードの保有枚数に基づいて、これらの顧客を2つのサブカテゴリー(ノード4とノード5)に分けたことに注目してください。 高所得の顧客に対しては、クレジットカード保有枚数が5枚以下の顧客だけに融資すれば、成功率は88%から97%近くまで引き上げられる。
図 7. クレジット・カード数が 5 枚未満の高収入の顧客 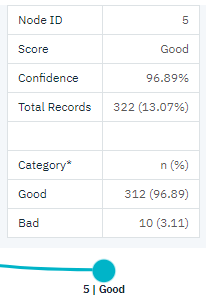
しかし、中程度の収入カテゴリー (ノード 3) の顧客についてはどうでしょうか。 「良い」評価と「悪い」評価に、均等に分かれています。 ここでも、サブカテゴリー(この場合はノード6と7)が役に立つ。 今度は、クレジット・カード数が 5 枚未満の中程度の収入の顧客にのみ融資すると、「良い」の評価のパーセンテージが 58% から 86% に上昇し、大幅な改善が示されます。
図 8. 中程度の収入の顧客のツリー・ビュー 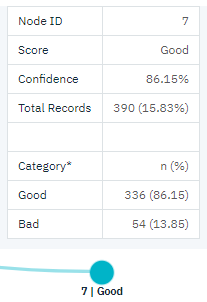
![]() 進捗状況を確認する
進捗状況を確認する
以下の画像はモデルの詳細を示している。 これでモデルを評価する準備ができた。
タスク5:モデルの評価
採点の仕組みを理解するために、モデルを閲覧することができる。 しかし、モデルがどれだけ正確に機能するかを評価するには、いくつかの記録を採点する必要がある。 記録を採点することは、モデルが予測した回答と実際の結果を比較するプロセスである。 モデルを評価するには、モデルの推定に使われたのと同じレコードを採点すればよい。 同じ記録を比較することで、観測された反応と予測された反応を比較することができる。 以下の手順でモデルを評価する:
- テーブル・ノードをモデル・ナゲットにアタッチします。
- テーブル・ノードにカーソルを合わせ、実行アイコン「」をクリックする。
- 出力とモデル]ペインで、[テーブル]という名前の出力結果をクリックして結果を表示します。
この表は、モデルが作成した'
$R-Credit ratingCredit rating慣例として、採点中に生成されたフィールドの名前は、ターゲット・フィールドをベースにしているが、標準的な接頭辞がついている。$G$GE$R$RC$X$XR$XS$XF
信頼度値 は、各予測値がどれだけ正確であるかに関するモデル独自の推定であり、スケールは 0.0 から 1.0 です。
図 9. 生成されたスコアおよび信頼度値を示すテーブル 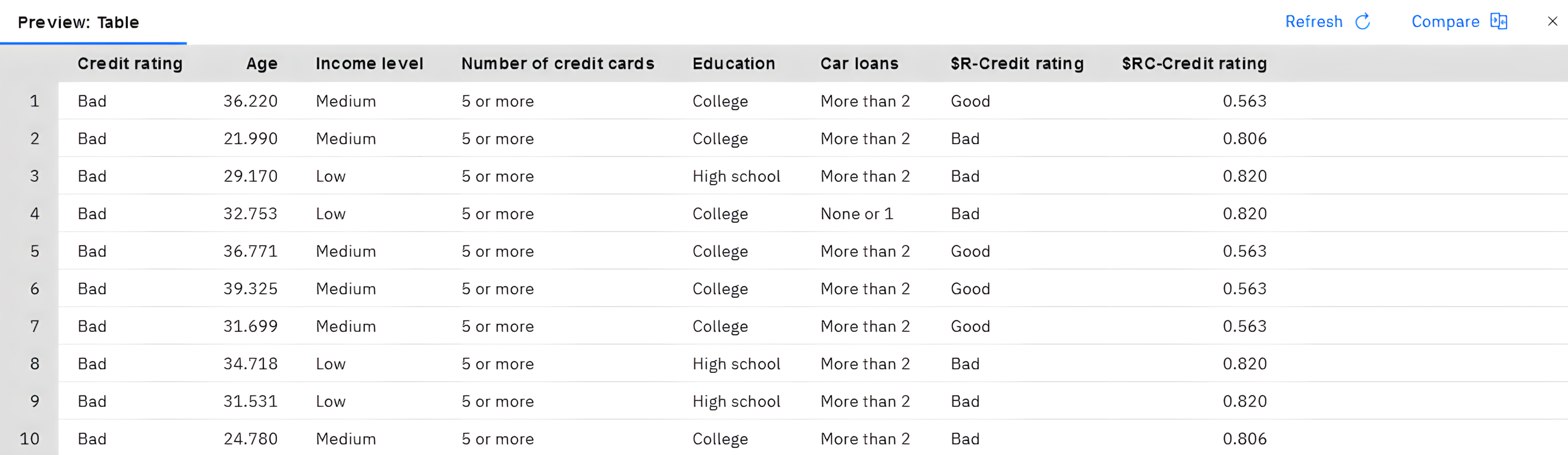
予想通り、予測値は多くのレコードで実際の回答と一致したが、すべてではなかった。 各 CHAID ターミナル・ノードにレスポンスが混在しているのが理由です。 予測は最も一般的なものと一致するが、そのノードの他のすべてのものについては間違っている。 (低収入の顧客の、債務不履行に陥っていない 18% の少数派を思い出してください)。
To avoid this issue, you could continue splitting the tree into smaller and smaller branches until every node was 100% pure; all グッド or 悪い with no mixed responses. しかし、このようなモデルは複雑で、他のデータセットにうまく一般化できそうにない。
正確にいくつの予測が正しいかを知るには、テーブルを読み、予測されたフィールド「
$R-Credit ratingCredit rating - モデルナゲットを分析ノードに接続します。
- 分析ノードにカーソルを合わせ、実行アイコン「」をクリックする。
- Outputs and models"ペインで、"Analysis "という名前の出力結果をクリックして結果を表示します。
分析によると、2464レコードのうち1960レコード(79%以上)において、モデルが予測した値が実際のレスポンスと一致した。
図 10. 観測レスポンスと予測レスポンスの比較の分析結果 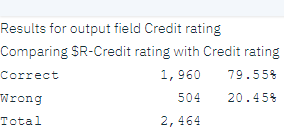
この結果は、採点した記録がモデルの推定に使用したものと同じであるという事実によって制限される。 実際の状況では、Partitionノードを使用して、データをトレーニングと評価のための別々のサンプルに分割することができる。 あるサンプル分割を使ってモデルを生成し、別のサンプルを使ってそれをテストすることで、そのモデルが他のデータセットにどの程度一般化できるかをよりよく知ることができる。
分析ノードを使って、すでに実際の結果を知っているレコードに対してモデルをテストすることができます。 次のステージでは、結果がわからない記録を採点するためにモデルをどのように使うかを説明する。 例えば、このデータセットには、現在銀行の顧客ではないが、販促のためのメーリングのターゲットになりそうな人々が含まれているかもしれない。
![]() 進捗状況を確認する
進捗状況を確認する
次の画像は、出力結果とともにフローを示したものである。 これで、新しいデータを使ってモデルを採点する準備ができた。
タスク6:新しいデータでモデルを採点する
先に、モデルの推定に使われた記録を採点し、モデルの正確さを評価できるようにした。 この例では、モデルを作成するために使用されたものとは異なるレコードのセットを採点している。 精度を評価することは、ターゲットフィールドを使ったモデリングの目的のひとつである。 結果を知っている記録を研究してパターンを特定し、まだ知らない結果を予測できるようにするのだ。
既存のデータアセットまたはインポートノードを更新して、別のデータファイルを指すようにすることができます。 あるいは、採点したいデータを読み込むデータアセットや インポートノードを追加することもできる。 いずれにせよ、新しいデータセットには、モデルで使われているのと同じ入力フィールド(AgeIncome levelEducationCredit rating
あるいは、予想される入力フィールドを含むフローにモデルナゲットを追加することもできます。 ファイルから読み込もうがデータベースから読み込もうが、フィールド名と型がモデルで使われるものと一致していれば、ソースの型は問題ではありません。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、完成したフローを示している。
サマリー
モデリング入門のサンプルフローは、モデルを作成し、評価し、採点するための基本的な手順を示しています。
- Modelingノードは、結果が既知のレコードを調査することによってモデルを推定し、モデルナゲットを作成する。 このプロセスは、モデルのトレーニングと呼ばれることもある。
- モデル・ナゲットは、レコードのスコアリングを行う予定のフィールドを含む任意のフローに追加できます。 既に結果が分かっているレコード (既存の顧客など) をスコアリングすることによって、そのパフォーマンスを評価できます。
- そのモデルが問題なく機能することを確認したら、新しいデータ(見込み客など)をスコアリングして、彼らがどう反応するかを予測することができる。
- モデルを訓練または推定するために使用されるデータは、分析データまたは履歴データと呼ばれる。 採点データはオペレーションデータとも呼ばれる。
次のステップ
これで、他のSPSS Modelerチュートリアルを試す準備ができました。
トピックは役に立ちましたか?
0/1000