预览教程
 观看视频,预览本教程的步骤。 视频中显示的用户界面可能略有不同。 该视频旨在作为书面教程的补充。 本视频提供了学习本文档中的概念和任务的直观方法。
观看视频,预览本教程的步骤。 视频中显示的用户界面可能略有不同。 该视频旨在作为书面教程的补充。 本视频提供了学习本文档中的概念和任务的直观方法。
试用教程
在本教程中,您将完成这些任务:
建模流程和数据集样本
本教程使用示例项目中的建模入门流程。 使用的数据文件是tree_credit.csv。 下图显示了建模流程示例。

预测结果的能力是预测分析的核心目标,而了解建模过程是使用SPSS Modeler流程的关键。
此示例中的模型显示了银行如何预测未来贷款申请人是否可能拖欠贷款。 这些客户此前从银行获得贷款,因此客户的数据存储在银行的数据库中。 该模型使用客户的数据来确定其缺省值的可能性。
任何模型的一个重要部分是进入其中的数据。 银行维护客户的历史信息数据库,包括他们是偿还贷款 (信用评级 = 良好) 还是违约 (信用评级 = 不良)。 银行希望使用此现有数据来构建模型。 使用了下列字段:
| 字段名称 | 描述 |
|---|---|
| Credit_rating | 信用评级:0 = 不良,1 = 优良,9 = 缺少值 |
| 年龄 | 年龄 |
| 收入 | 收入水平:1 = 低,2 = 中等,3 = 高 |
| Credit_cards | 持有的信用卡数量:1 = 少于五张,2 = 五张或更多 |
| 教育机构 | 教育程度:1 = 高中,2 = 大学 |
| Car_loans | 已申请的汽车贷款数:1 = 没有或者一项,2 = 两项以上 |
此示例使用 决策树 模型,该模型通过使用一系列决策规则对记录进行分类 (并预测响应)。

例如,当收入在中等范围内且信用卡数量小于 5 时,此决策规则会将记录分类为具有良好的信用评级。
IF income = Medium
AND cards <5
THEN -> 'Good'通过使用决策树模型,您可以分析两组客户的特征,并预测发生拖欠贷款的可能性。
虽然此示例使用 CHAID (卡方自动交互检测) 模型,但它旨在作为一般介绍,并且大多数概念广泛适用于 SPSS Modeler中的其他建模类型。
任务 1:打开示例项目
任务 2:检查数据资产和类型节点
建模简介 建模流程包括几个节点。 按照以下步骤检查数据资产和类型节点。
- 从 "资产"选项卡打开 "建模入门"建模流程,等待画布加载。
- 双击tree_credit.csv节点。 该节点是一个数据资产节点,指向项目中的tree_credit.csv文件。 如果在源节点中指定测量值,则无需在流程中包含单独的类型节点。
- 查看文件格式属性。
- 可选:单击 "预览数据"查看完整数据集。
- 双击类型节点。 该节点指定字段属性,如测量级别(字段包含的数据类型),以及每个字段在建模中作为目标或输入的作用。 测量级别是指示字段中数据的类型的类别。 源数据文件使用三种不同的测量级别:
- 连续字段(如 "
Age字段)包含连续的数值。 - 标称字段(如 "
Education字段)有两个或多个不同的值:在本例中为 "College或 "High school"。 - 序数字段(如 "
Income level字段)描述的是具有多个不同值的数据,这些值具有固有的顺序:本例中为 "Low、"Medium"和 "High。
图 3。 类型节点 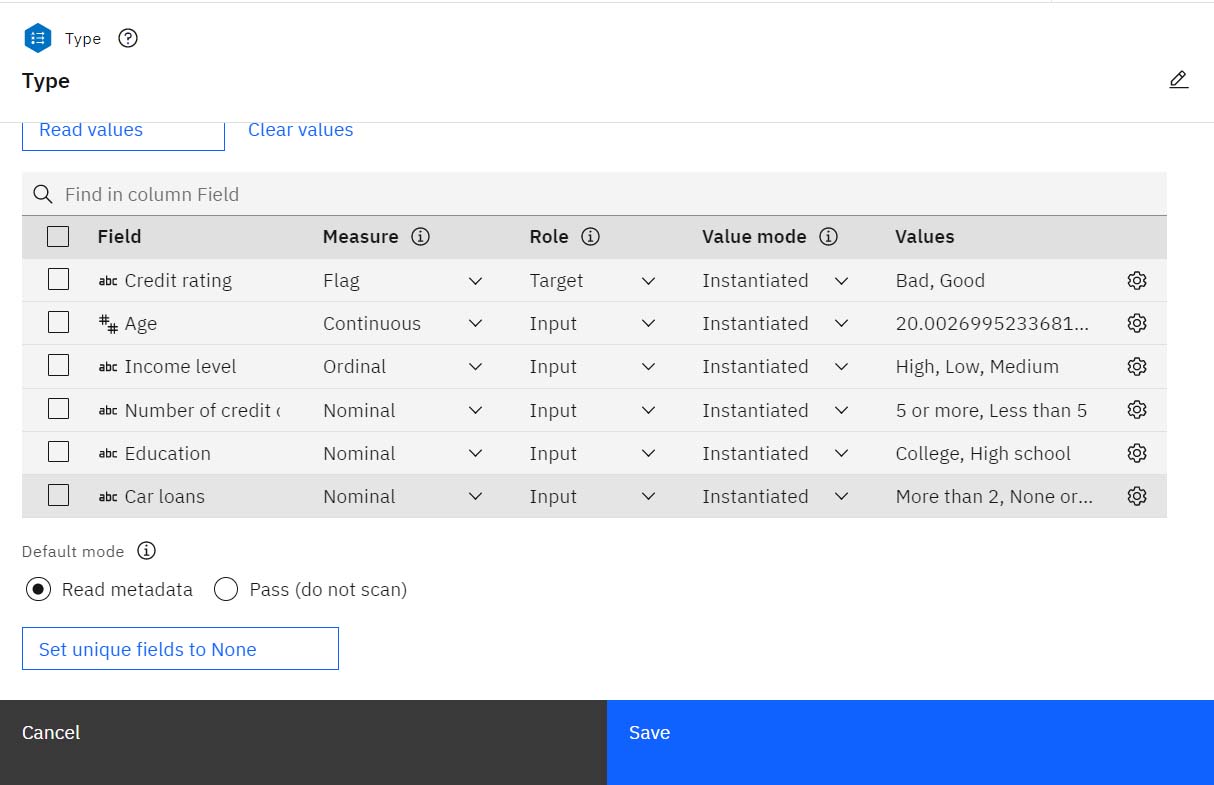
对于每个字段,"类型"节点还指定了一个角色,以表明每个字段在建模中的作用。
Credit rating字段的角色设置为 "目标",该字段表示客户是否拖欠贷款。 目标是要预测值的字段。其他字段的角色设置为输入。 输入字段有时也称为预测变量,或者是建模算法要使用其值来预测目标字段值的字段。
- 连续字段(如 "
- 可选:单击预览数据,查看应用了类型属性的数据。
![]() 检查您的进度
检查您的进度
下图显示了类型节点。 现在您可以配置建模节点了。

任务 3:配置建模节点
建模节点会在流程运行时生成模型金块。 本例使用CHAID节点。 CHAID,即 "卡方自动交互检测",是一种分类方法,它通过使用一种特殊的统计类型(即卡方统计)来构建决策树。 该节点使用卡方统计来确定决策树中的最佳分割位置。 请按照以下步骤配置建模节点:
- 双击信用等级 (CHAID)节点,查看其属性。
- 在字段部分,请注意 "使用此节点中定义的设置"选项。 该选项指示节点使用此处指定的目标和字段,而不是使用 "类型"节点中的字段信息。 在本教程中,请关闭 "使用此节点中定义的设置"选项。
- 展开 "目标"部分。 在这种情况下,默认值是合适的。 您的目标是建立新模型、创建标准模型并在运行后生成模型节点。
- 展开 "停止规则"部分。 在本例中,为使树形结构相当简单,可通过提高父节点和子节点的最小案例数来限制树形结构的增长。
- 选择使用绝对值。
- 将父分支中的最少记录设为 "
400。 - 将子分支中的最少记录设为 "
200。
- 单击保存。
- 将鼠标悬停在信用等级 (CHAID)节点上,然后单击运行图标 "
 。
。
![]() 检查您的进度
检查您的进度
下图显示了模型结果的流程。 现在您可以探索模型了。

任务 4:探索模型
运行建模流程后,会在画布上添加一个模型金块,并带有一个指向建模节点的链接。 按照以下步骤查看型号详细信息:
- 在 "输出和模型"窗格中,单击名称为 "信用评级"的模型以查看该模型。
- 单击 "模型信息"查看模型的基本信息。
- 单击 "特征重要性"查看每个预测因子在估计模型时的相对重要性。 从图表中可以看出,收入水平是最重要的因素,其次是信用卡数量。
图 4: 特征重要性图表 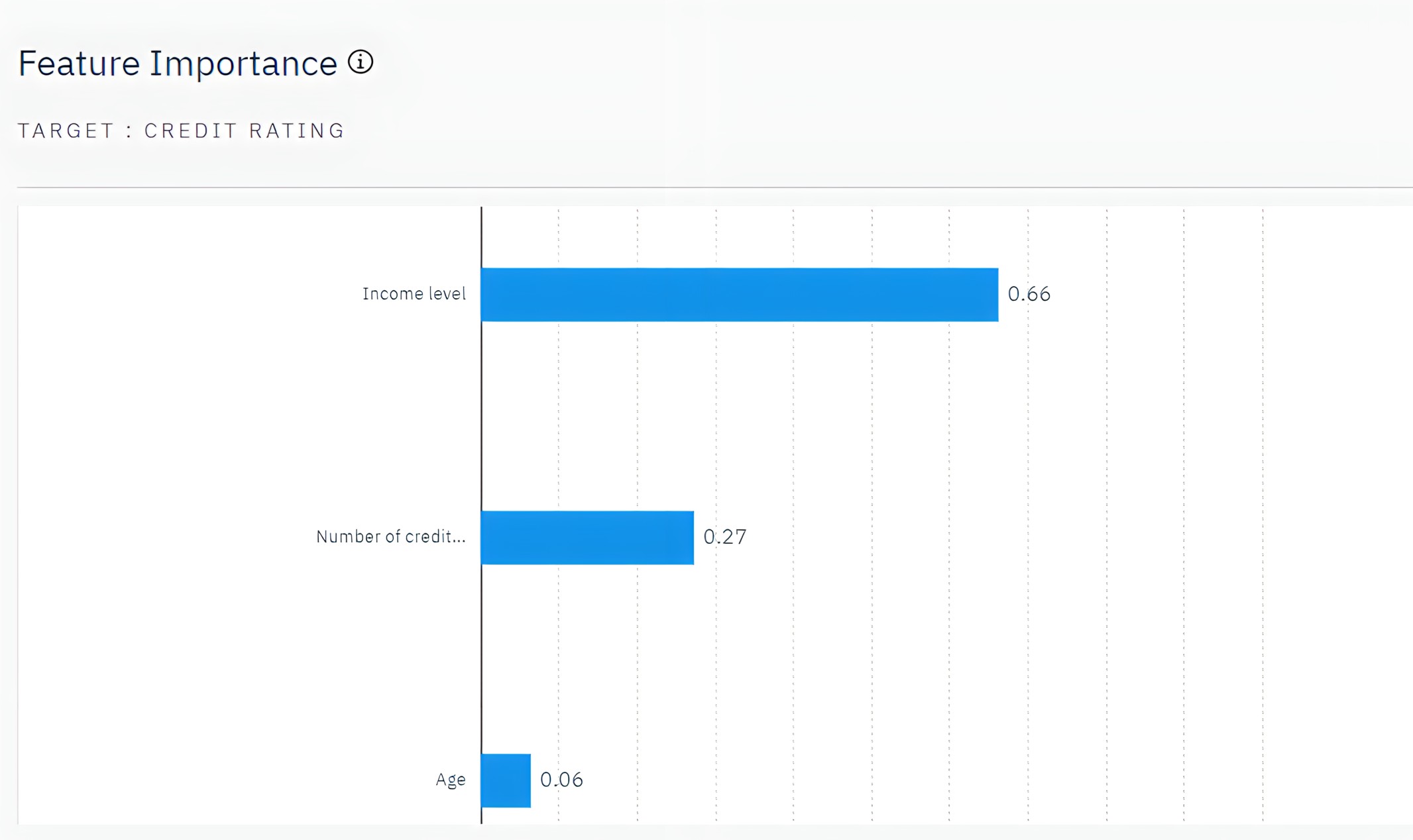
- 单击 "顶部判定规则"查看规则集形式的详细信息;规则集实质上是一系列规则,可用于根据不同输入字段的值将单个记录分配给子节点。 决策树中的每个终端节点都会返回 "好"或 "坏"的预测结果。 终端节点是指不再进一步分割的树节点。 在每种情况下,预测都是由该节点内记录的模式或最常见的响应决定的。
图 5. CHAID 模型块,规则集 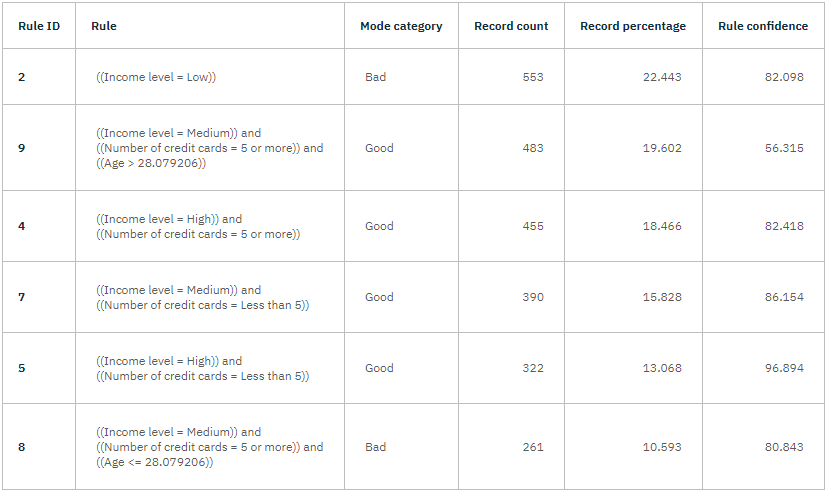
- 单击 "树形图",以树形形式查看同一模型,每个决策点都有一个节点。 将鼠标悬停在分支和节点上可探索详细信息。
图 6. 模型块中的树形图 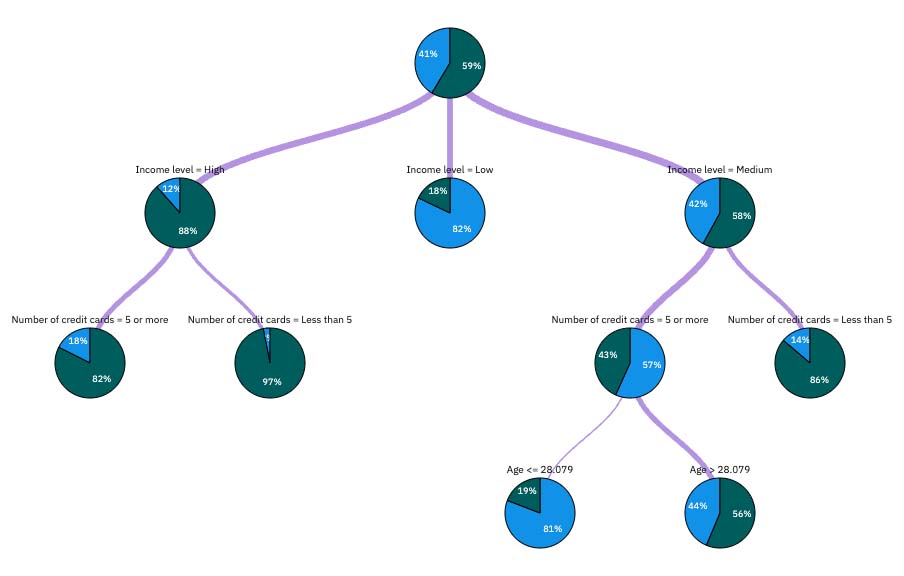
在树的起点,第一个节点(节点 0)给出了数据集中所有记录的摘要。 数据集中超过 40% 的个案分类为风险较高。 40% 是一个相当高的比例,但这棵树可能会提供一些线索,说明可能是哪些因素造成的。
第一种是按收入水平划分。 收入级别处于低类别的记录将分配给节点 2,意料之中的是,此类别包含最高的贷款违约者百分比。 显然,向此类别的客户贷款风险很高。 不过,这类客户中有近 18%没有违约,因此预测并不总是正确的。 任何模型都不可能预测出每种反应,但一个好的模型应该能让您根据现有数据预测出每条记录最有可能出现的反应。
同样,如果观察高收入客户(节点 1),可以发现大多数客户(超过 88%)的风险都很高。 但在这些客户中,每 10 人中仍有 1 人以上违约。 能否进一步完善贷款标准,将风险降至最低?
请注意模型是如何根据持有信用卡的数量将这些客户分为两个子类别(节点 4 和 5)的。 对于高收入客户,如果银行只向持有少于 5 张信用卡的客户贷款,则成功率可从 88% 提高到近 97%;这是一个更加令人满意的结果。
图 7. 少于五张信用卡的高收入客户 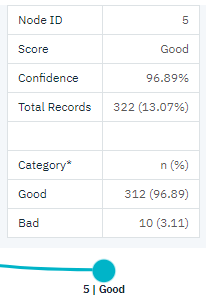
但是,中等收入类别(节点 3)的这些客户又如何? 他们更平均地划分为优良和不良评级。 同样,子类别(本例中为节点 6 和 7)也可以提供帮助。 此时,仅向少于五张信用卡的中等收入客户提供贷款,使得优良评级的百分比从 58% 提高到 86%,有了显著改善。
图 8. 中等收入客户的树形视图 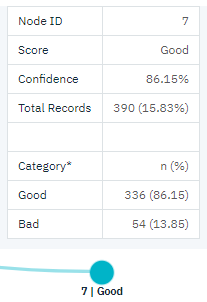
![]() 检查您的进度
检查您的进度
下图显示了模型的详细信息。 现在您可以对模型进行评估了。

任务 5:评估模型
您可以浏览模型,了解评分的工作原理。 不过,要评估该模型的准确性,需要对一些记录进行评分。 记录评分是将实际结果与模型预测的反应进行比较的过程。 要对模型进行评估,可以对用于估算模型的相同记录进行评分。 您可以通过比较相同的记录来比较观察到的反应和预测到的反应。 请按照以下步骤评估模型:
- 将表节点附加到模型金块上。
- 将鼠标悬停在表格节点上,然后单击运行图标 "。
- 在 "输出和模型"窗格中,单击名称为 "表"的输出结果以查看结果。
表格显示了模型创建的 "
$R-Credit rating字段中的预测分数。 您可以将这些值与包含实际回复的原始 "Credit rating字段进行比较。按照惯例,评分过程中生成的字段名称以目标字段为基础,但带有标准前缀。$G和 "$GE是广义线性模型生成的预测结果的前缀$R是 CHAID 模型生成的预测结果的前缀$RC用于置信度值$X通常是通过使用一个集合$XR,$XS,$XFare used as prefixes in cases where the target field is a Continuous, Categorical, Set, or Flag field
置信度值是模型自己对每个预测值的准确性的估计,范围为 0.0 到 1.0。
图 9. 显示已生成的评分和置信度值的表 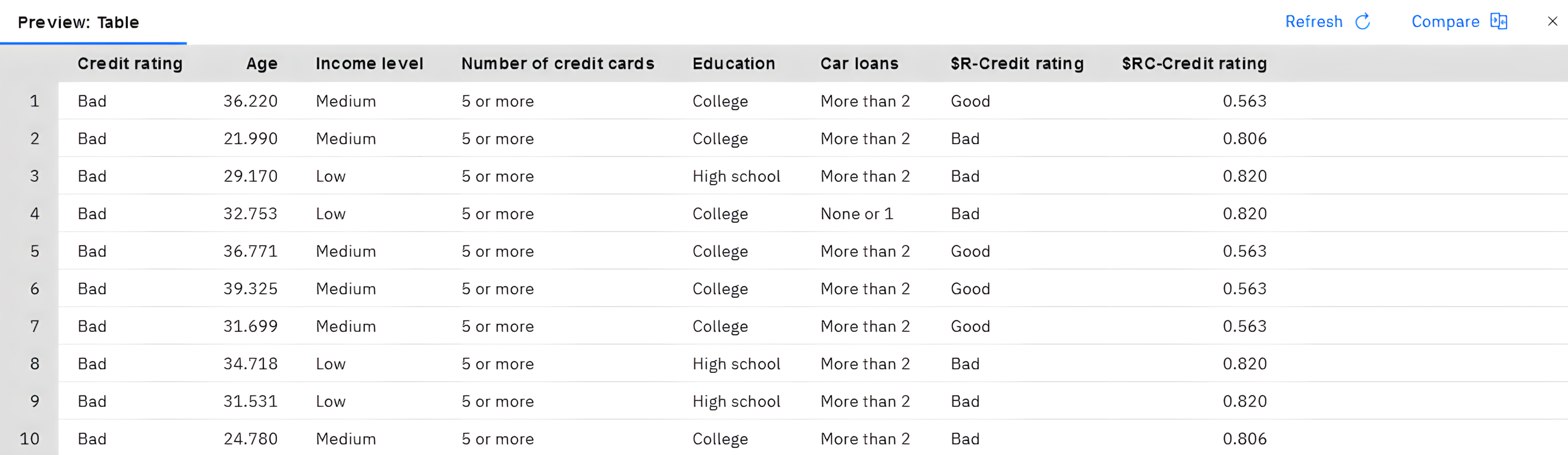
不出所料,许多记录的预测值与实际答案相符,但并非所有记录都是如此。 出现此情况的原因是每个 CHAID 终端节点都具有混合响应。 该预测符合最常见的预测,但对该节点中的所有其他预测都是错误的。 (回忆一下未违约的 18% 少数低收入客户)
为了避免这个问题,你可以继续把树分成越来越小的分支,直到每个节点都是 100%纯粹的;都是好的或坏的,没有混合的反应。 但这种模型很复杂,不太可能很好地推广到其他数据集。
要想知道到底有多少条预测是正确的,您可以阅读表格,统计预测字段 "
$R-Credit rating的值与 "Credit rating的值相匹配的记录数。 不过,最简单的方法是使用分析节点,它可以自动跟踪这些值匹配的记录。 - 将模型金块连接到分析节点。
- 将鼠标悬停在分析节点上,点击运行图标 "。
- 在 "输出和模型"窗格中,单击名称为 "分析 "的输出结果以查看结果。
分析表明,在 2464 条记录中,1960 条记录(超过 79%)的模型预测值与实际响应相吻合。
图 10. 观察到的响应与预测响应的比较分析结果 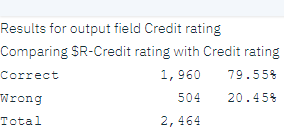
这一结果受到以下事实的限制,即您评分的记录与您用来估计模型的记录相同。 在实际情况中,你可以使用分区节点将数据分成不同的样本,分别用于训练和评估。 使用一个样本分区生成模型,再使用另一个样本对模型进行测试,就能更好地了解模型对其他数据集的泛化程度。
您可以使用分析节点,针对已经知道实际结果的记录测试模型。 下一阶段将说明如何使用该模型为不知道结果的记录评分。 例如,该数据集可能包括目前不是银行客户但可能成为促销邮件目标的人。
![]() 检查您的进度
检查您的进度
下图显示了流程和输出结果。 现在您可以使用新数据对模型进行评分了。

任务 6:利用新数据对模型进行评分
之前,您对用于估算模型的记录进行了评分,以便评估模型的准确性。 该示例使用的记录与创建模型时使用的记录不同。 评估精度是利用目标区域建模的目标之一。 你要研究你知道结果的记录,找出规律,从而预测你还不知道的结果。
您可以更新现有的数据资产或导入节点,使其指向不同的数据文件。 或者,您也可以添加一个数据资产或导入节点,读入您要评分的数据。 无论采用哪种方式,新数据集都必须包含模型使用的相同输入字段(Age"、"Income level"、"Education"等),但不包括目标字段 "Credit rating。
或者,您也可以将模型金块添加到任何包含预期输入字段的流程中。 无论是从文件还是数据库中读取,只要字段名称和类型与模型使用的字段名称和类型一致,源类型就无关紧要。
![]() 检查您的进度
检查您的进度
下图显示了已完成的流程。

目录
建模入门示例流程演示了创建、评估和评分模型的基本步骤。
- 建模节点通过研究已知结果的记录来估算模型,并创建模型金块。 这一过程有时被称为模型训练。
- 可以将模型块添加到具有预期字段的任何流中,以对记录进行评分。 通过对已知其结果的记录(例如现有客户)进行评分,可以评估模型的运行情况。
- 在您对模型的表现感到满意后,您可以对新数据(如潜在客户)进行评分,以预测他们的反应。
- 用于训练或估计模型的数据可称为分析数据或历史数据。 评分数据也可称为运行数据。
后续步骤
现在您可以尝试其他SPSS Modeler教程了。