薬物治療のグラフを見る
チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、この文書で説明する概念と作業を視覚的に学習する方法を提供しています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、この文書で説明する概念と作業を視覚的に学習する方法を提供しています。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
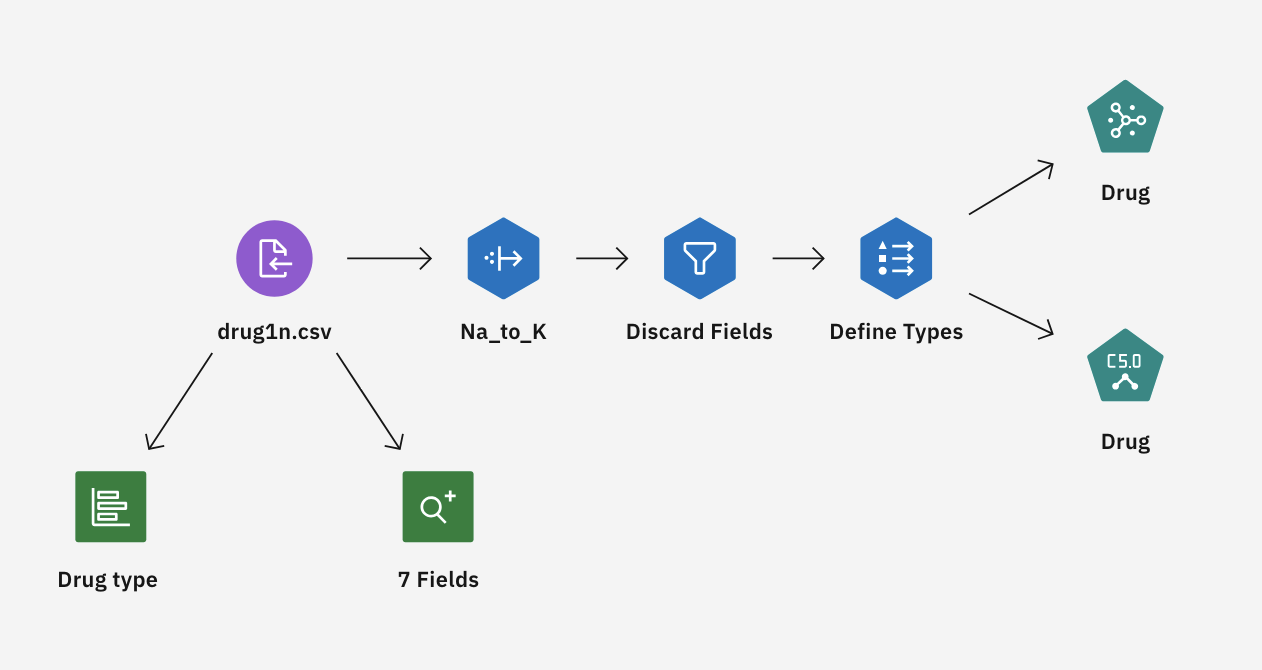
このチュートリアルでは、サンプル・プロジェクトの「Drug Treatment - Exploratory Graphs」フローを使用します。 使用したデータファイルはdrug1n.csvである。 次の図は、モデラーのフロー例を示しています。
| データ・フィールド | 説明 |
|---|---|
|
患者の年齢 (数値) |
|
|
|
血圧: |
|
血中コレステロール: |
|
血液中のナトリウム濃度 |
|
血液中のカリウム濃度 |
|
患者に効果があった処方薬 |
タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプルプロジェクトをまだお持ちでない場合は、 チュートリアルのトピックを参照してサンプルプロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataナビゲーションメニュー から
 、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。
、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。 - SPSS ModelerProjectをクリックします。
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。

タスク2:データ資産の調査
薬物治療 - 探索的グラフにはいくつかのノードがあります。 以下の手順に従って、Data Assetノードを調べます:
- Assetsタブから、Drug Treatment - Exploratory Graphsモデラーフローを開き、キャンバスがロードされるのを待つ。
- drug1n.csvノードをダブルクリックします。 このノードは、プロジェクト内のdrug1n.csvファイルを指すData Assetノードです。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、Data Assetノードを示しています。 これで、分布図とデータ監査図を調べる準備ができた。
タスク3:分布図とデータ監査図を調べる
データ・マイニングの際は、多くの場合、視覚的な要約を作成してデータを検討すると便利です。 SPSS Modelerには、要約したいデータの種類に応じて、さまざまな種類のグラフが用意されています。 例えば、各薬剤に反応した患者の割合を調べるには、薬剤タイプ(分布)ノードを探索します。 以下の手順でチャートをいくつか見てみよう:
- Drug type (Distribution)ノードをダブルクリックしてプロパティを表示します。
- 「キャンセル」をクリックします。
- 薬剤タイプ(Distribution)ノードにカーソルを合わせ、実行アイコン「
 」をクリックする。
」をクリックする。 - 出力とモデル」ペインで、薬剤タイプ出力をクリックして結果を表示します。
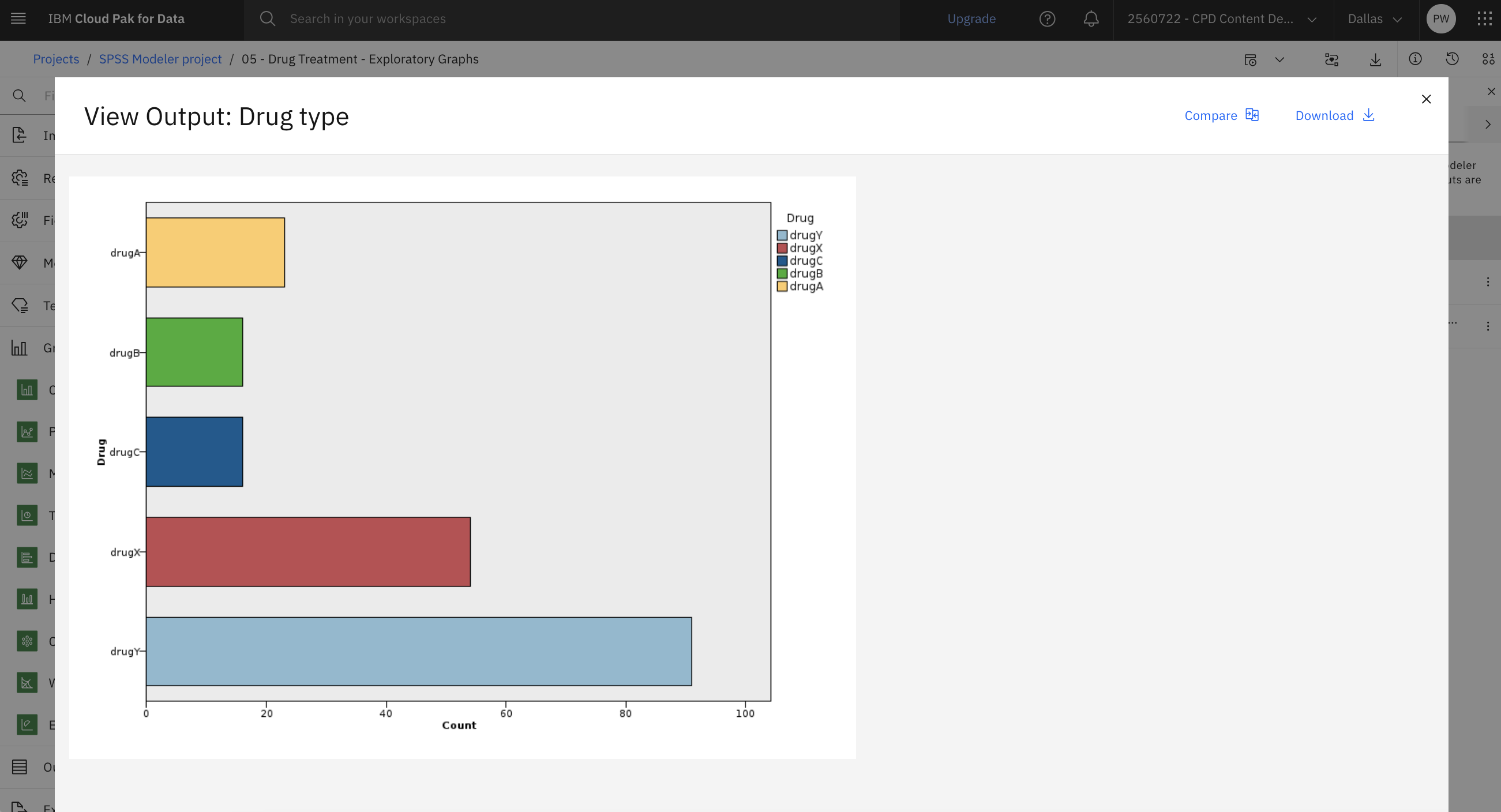
チャートはデータの形を見るのに役立つ。 薬品 YBC
あるいは、7 Fields (Data Audit)ノードをアタッチして実行すると、すべてのフィールドの分布とヒストグラムを一度に見ることができます。
- データ資産」ノードの後にある「7 フィールド(データ監査)」出力ノードをダブルクリックします。
- 7 フィールド(データ監査)ノードにカーソルを合わせ、実行アイコン「」をクリックする。
- 出力とモデル]ペインで、[7 フィールド(データ監査)]出力をクリックして結果を表示します。

![]() 進捗状況を確認する
進捗状況を確認する
次の図は、このフローを示しています。 これで散布図を作成して調べる準備ができました。
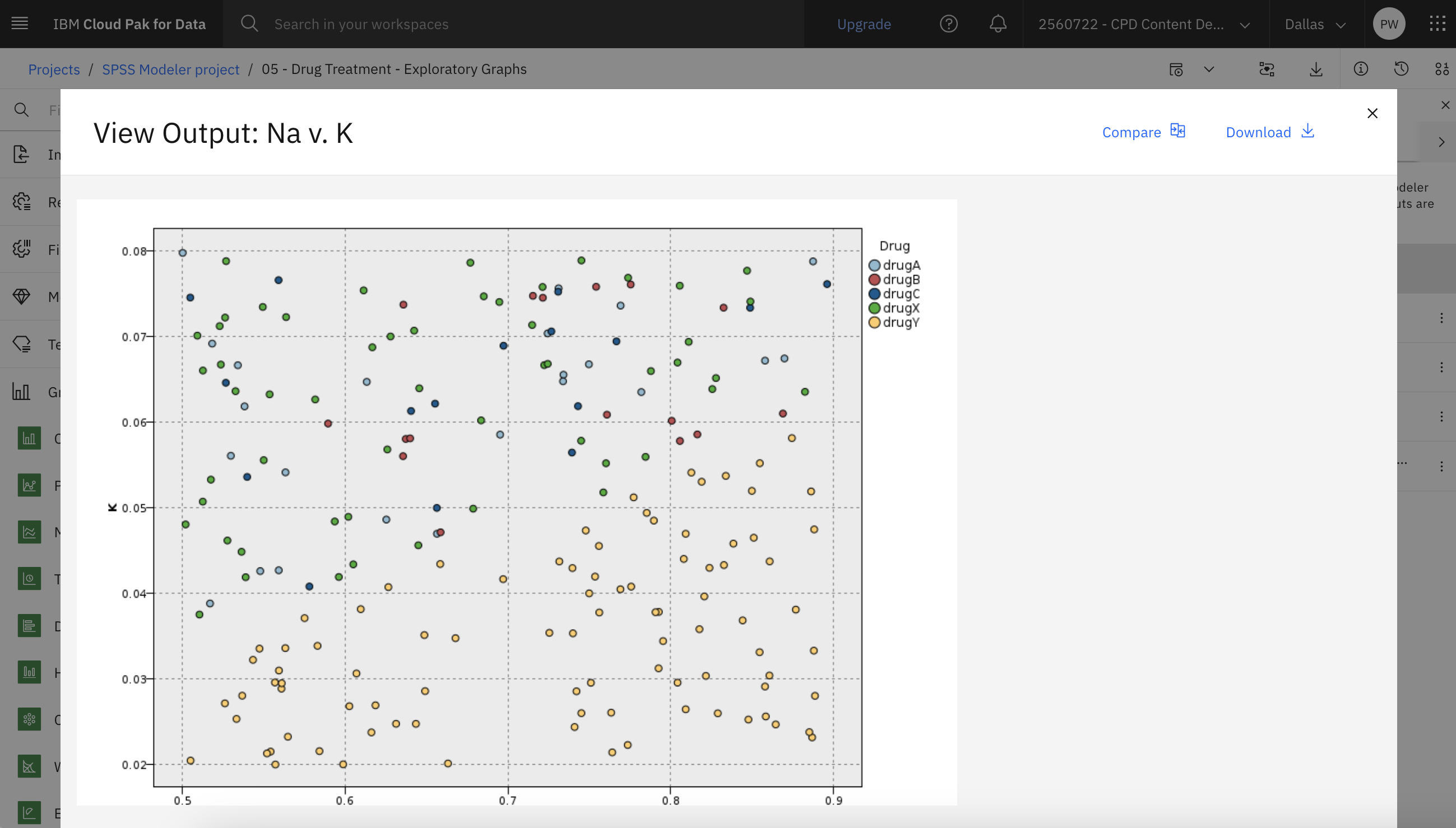
課題4:散布図の作成と探求
ターゲット変数である'Drug
- パレットのGraphsセクションから、Plotノードをキャンバス上にドラッグします。
- ノードにカーソルを合わせ、Edit Titleボタンをクリックし、名前を'Na vに変更する。 K.
- Plotノードをdrug1n.csvデータアセットノードに接続します。
- をダブルクリックする Na v. K (Plot)ノードのプロパティを編集する。
- プロット・セクションで、Xフィールドとして'
NaKDrug - 保存 をクリックします。
- にカーソルを合わせる Na v. K(プロット)ノードをクリックし、実行アイコン'をクリックする。
- 出力とモデル」ペインで、「Na vをクリックする。 K出力で結果を見る。
プロットは明らかに閾値を示している。 閾値より高い値では、薬剤「YYNaK
![]() 進捗状況を確認する
進捗状況を確認する
次の図は散布図である。 これでウェブ・チャートの作成と探索の準備は整った。
タスク5:ウェブ・チャートの作成と探索
データ・フィールドの多くがカテゴリーであるため、異なるカテゴリー間の関連性をマッピングするウェブ・チャートをプロットしてみることもできる。 以下の手順に従って、ウェブチャートを探索してください:
- パレットのグラフセクションから、Webノードをキャンバス上にドラッグし、drug1n.csvデータアセットノードに接続します。
- Webノードをダブルクリックしてプロパティを編集します。
- Fieldsセクションで、Add columnsをクリックする。
BPDrug - 保存 をクリックします。
- Webノードにカーソルを合わせ、実行アイコン「」をクリックする。
- アウトプットとモデルペインで、「ウェブ出力をクリックして結果を表示する。
プロットから、明らかに薬物「YY
しかし、薬品 YABCXXABCX
![]() 進捗状況を確認する
進捗状況を確認する
以下の画像は、ウェブ・プロットを示している。 これで高度なビジュアライゼーションを探求する準備が整いました。

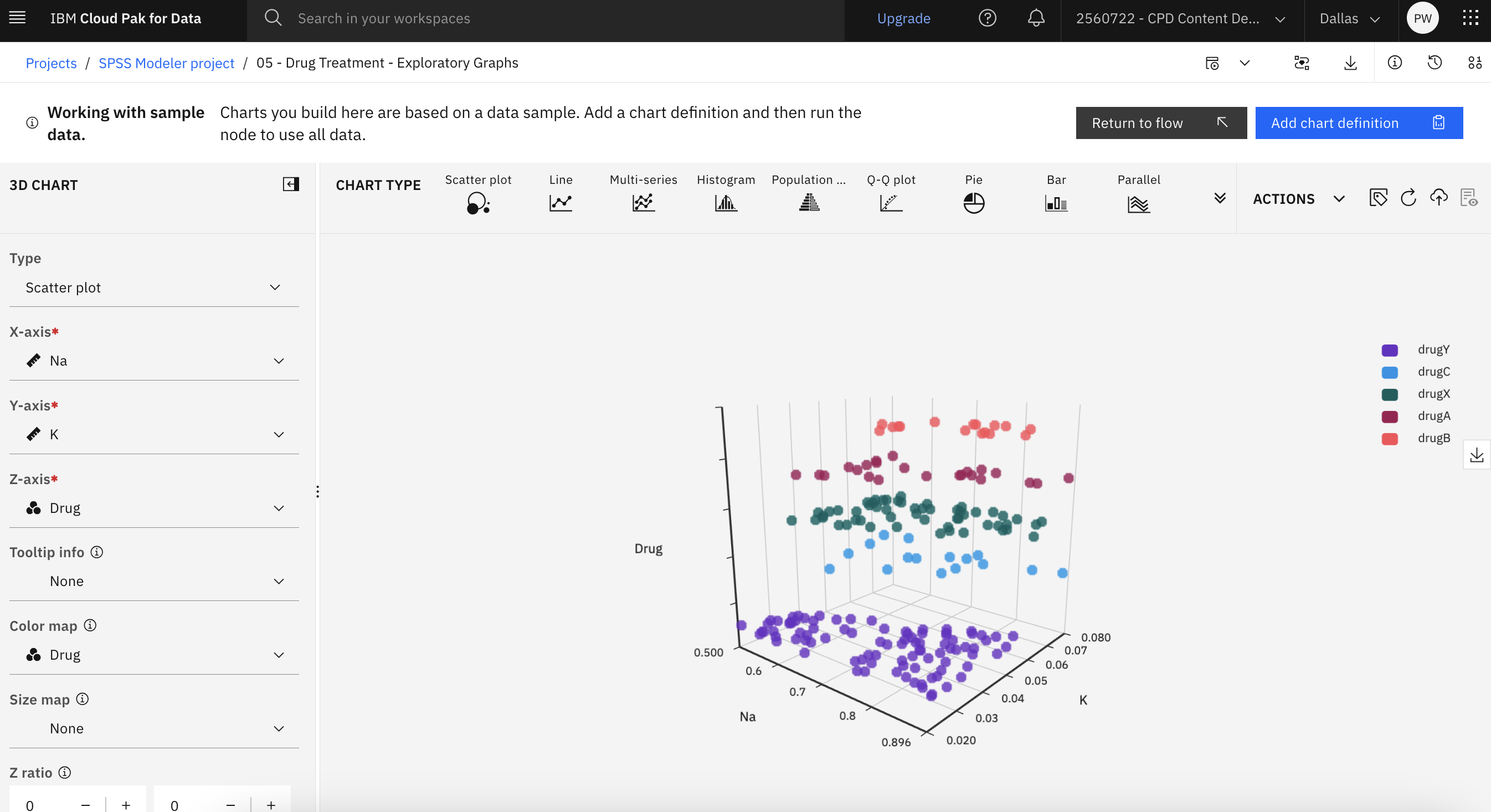
課題6:高度なビジュアライゼーションを探求する
これまでのセクションでは、さまざまなタイプのグラフ・ノードを使用した。 データを調べるもう 1 つの方法は、高度な視覚化機能を使用することです。 以下の手順に従って、高度なチャートを作成し、探索してください:
- パレットのGraphsセクションから、Chartsノードをキャンバス上にドラッグし、drug1n.csvデータアセットノードに接続します。
- Chartsノードをダブルクリックしてプロパティを表示します。
- Launch Chart Builderボタンをクリックします。
ここでは、さまざまな視点からデータを探索し、データ内のパターン、接続、および関係を識別するための高度なグラフを選択して作成することができます。 モデラーのフローに戻る前に、いくつかのグラフを作成してみる。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は3Dチャートの例である。 これでDeriveノードを探索する準備が整いました。
タスク 7: Derive ノードの探索
課題4の散布図で見たように、ナトリウムとカリウムの比率は、薬剤Yを使用するタイミングを予測するようです。 各レコードについて、この比率の値を含むフィールドを導き出すことができる。 このフィールドは、後で 5 つの薬品のそれぞれを使用するタイミングを予測するモデルを構築する際に役立つこともあります。
以下の手順に従って、Derive ノードを探索してください:
- Na_to_K (Derive)ノードをダブルクリックしてプロパティを編集する。
- エクスプレッションのセクションを見てください。 Na/Kは、ナトリウムの値をカリウムの値で割って新しい面積を求めるので、この式になります。また、 電卓アイコンをクリックして
 、 式ビルダー を開くことで、式を作成することもできます。これは、組み込みの関数、オペランド、フィールドおよびそれらの値のリストを使用して、対話的に式を作成する方法です。
、 式ビルダー を開くことで、式を作成することもできます。これは、組み込みの関数、オペランド、フィールドおよびそれらの値のリストを使用して、対話的に式を作成する方法です。 - キャンセルをクリックしてプロパティに戻り、キャンセルをもう一度クリックしてフローに戻る。
- パレットのGraphsセクションから、Histogramノードをキャンバス上にドラッグし、それをNa_to_K (Derive)ノードに接続する。
- ヒストグラム・ノードをダブルクリックしてプロパティを表示します。
- ヒストグラム・ノードのプロパティで、プロットするフィールドとしてNa_to_K を指定し、カラー・オーバーレイ・フィールドとしてDrug を指定する。
- 保存 をクリックします。
- ヒストグラム・ ノードにカーソルを合わせ、実行アイコン「」をクリックする。
- 出力とモデル]ペインで、[ヒストグラム]出力をクリックして結果を表示します。
このグラフから、「Na_to_KY
![]() 進捗状況を確認する
進捗状況を確認する
次の画像はヒストグラムである。 これでFilterノードとTypeノードを探索する準備が整いました。

タスク 8: フィルタノードとタイプノードの探索
データを探索し、操作することによって、いくつかの仮説を立てることができる。 血中のカリウムに対するナトリウムの比率が、血圧と同様に薬品の選択に影響するようです。 ただし、これですべての関係性を完全に説明することはできません。 モデリングはいくつかの答えを与えてくれる。 まず、以下の手順に従って、FilterノードとTypeノードを探索します:
- Discard Fields (Filter)ノードをダブルクリックしてプロパティを表示します。
- 派生フィールド'
Na_to_KNaK図4: filter ノードのプロパティー 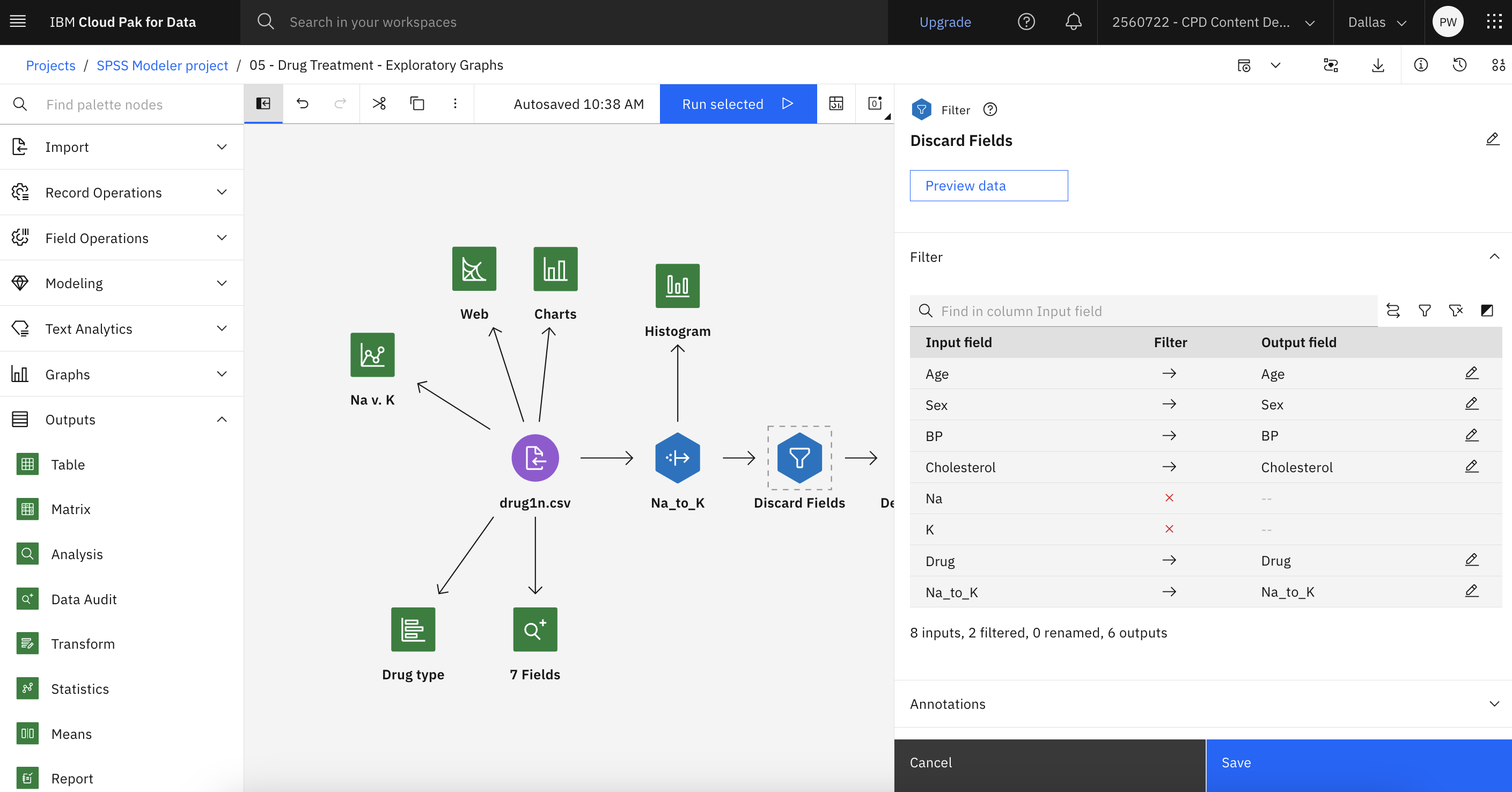
- 「キャンセル」をクリックします。
- Define Types (Type)」ノードをダブルクリックしてプロパティを表示します。
- Typeノードでは、使用するフィールドのタイプと、それらがどのように結果の予測に使用されるかを示すことができる。
DrugDrug図 5. type ノードのプロパティー 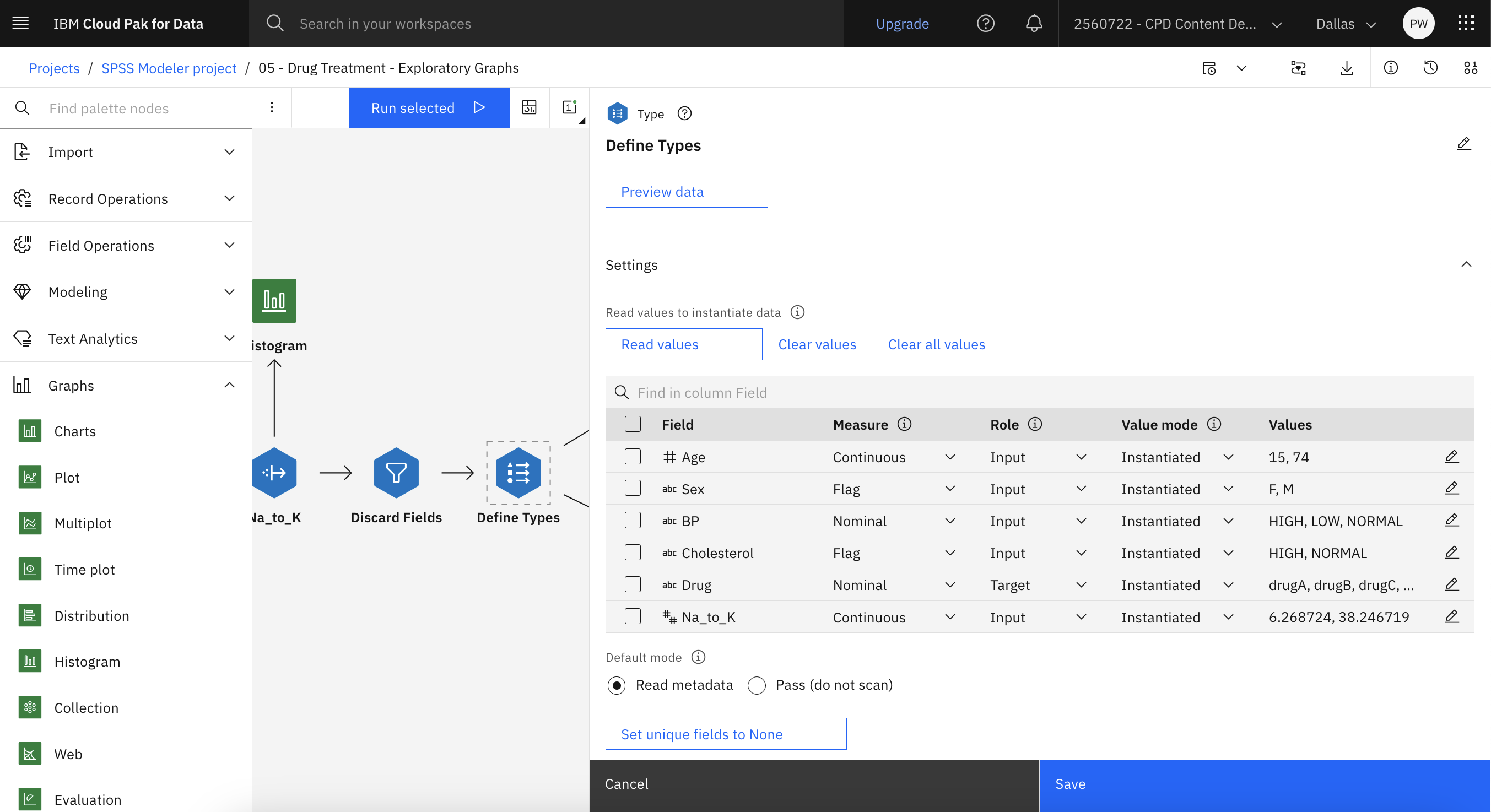
- 「キャンセル」をクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、このフローを示しています。 これでモデルを生成する準備が整いました。
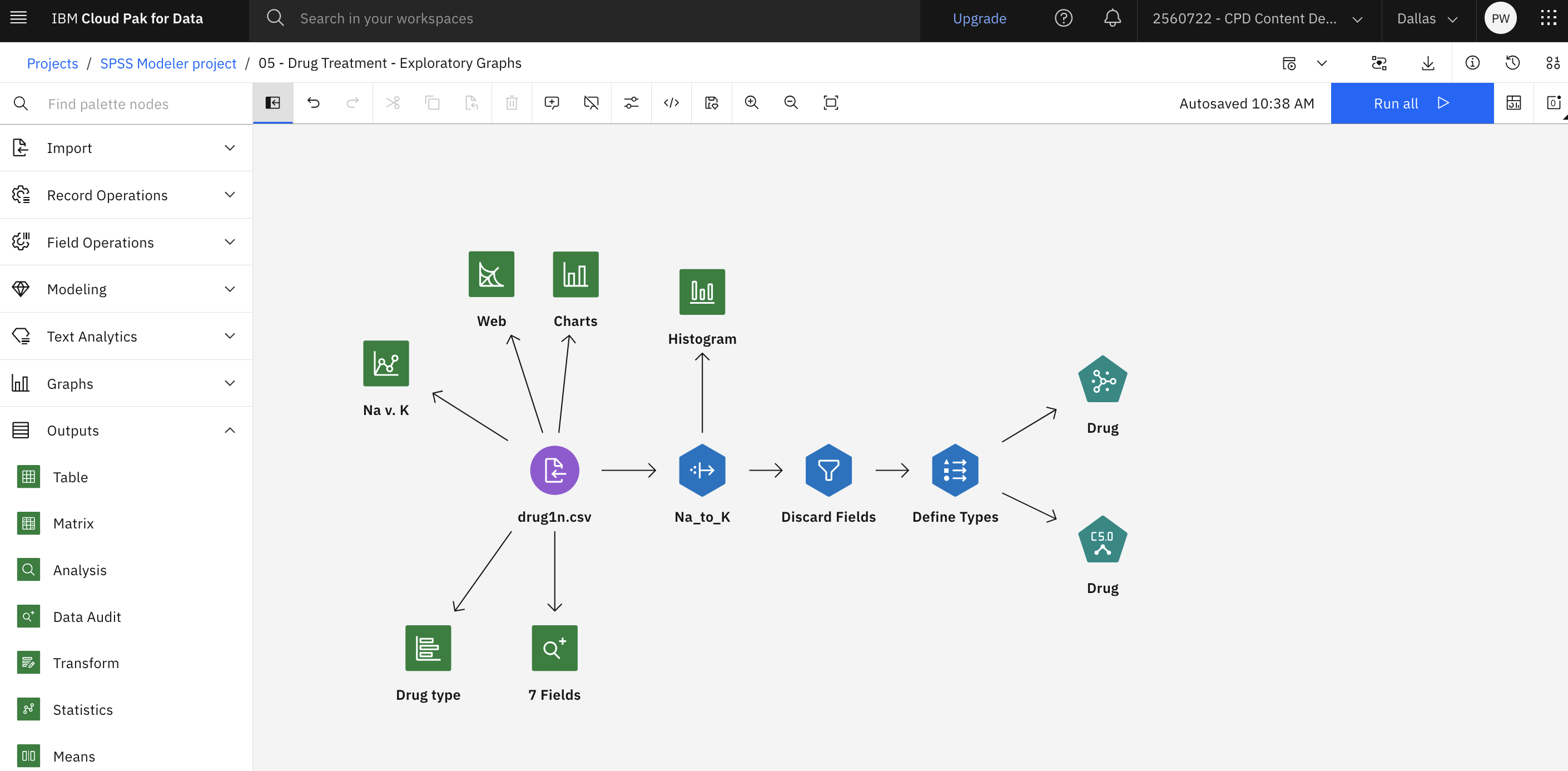
タスク9:モデルの生成
以下の手順に従って、C5.0ノードを使用してモデルを生成してください:
- Drug (C5.0)ノードにカーソルを合わせ、実行アイコン'をクリックします。
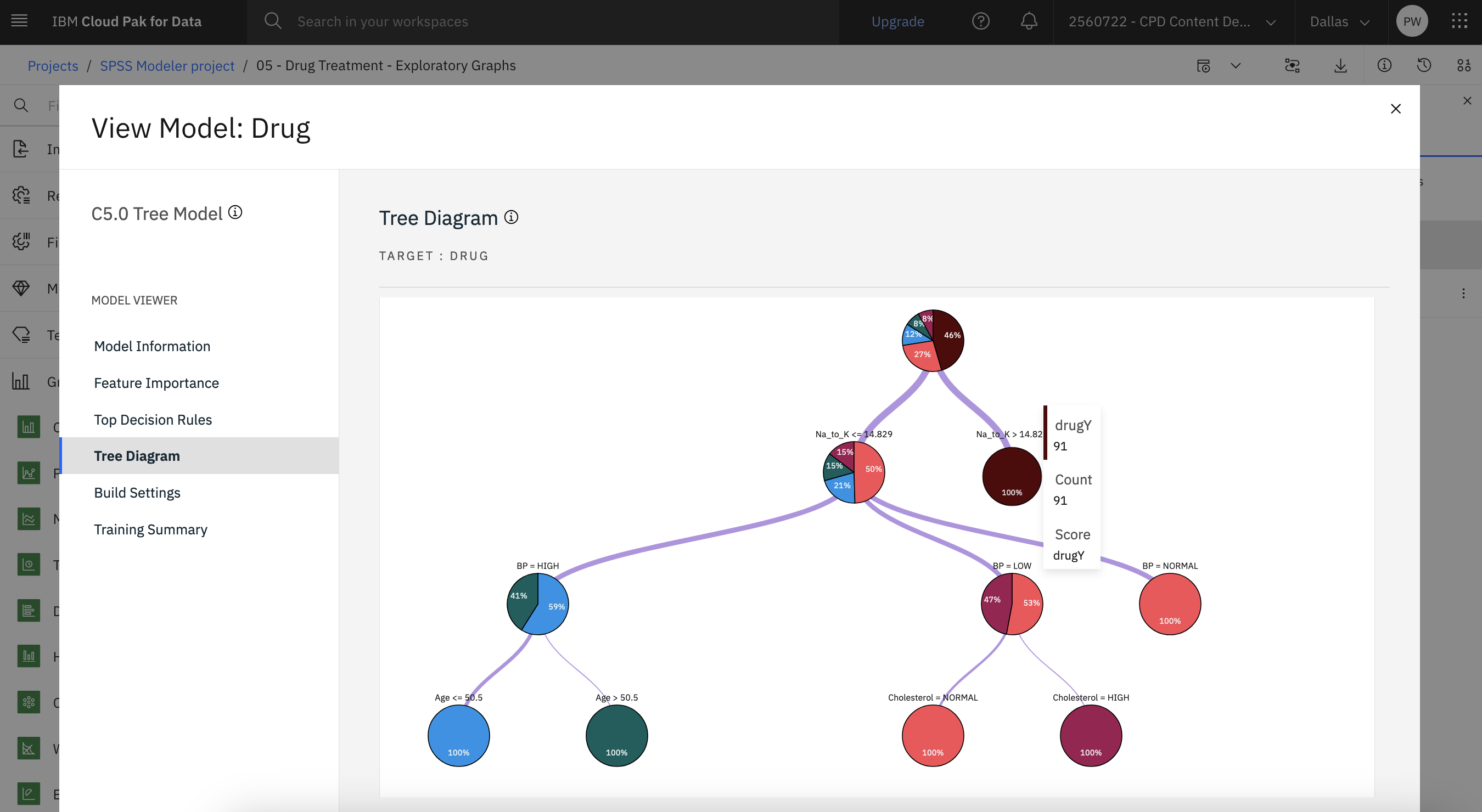
- Outputs and models(出力とモデル)ペインで、Drugモデルをクリックして結果を表示します。
ツリーダイアグラムは、C5.0ノードによって生成されるルールのセットをツリー形式で表示します。 さて、パズルの欠けているピースが見えてきただろう。 Na-to-K 比が
14.829ツリー内のノードにカーソルを合わせると、血圧カテゴリーごとのケース数およびケースの信頼度パーセントなどの詳細を確認できます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はツリー図である。 これで分析ノードを作成する準備ができました。
タスク10:分析ノードの作成
分析ノードを使用してモデルの精度を評価するには、以下の手順に従ってください:
- パレットのOutputs(出力)セクションから、Analysis(分析)ノードをキャンバス上にドラッグし、Drug(C5.0)モ デルのナゲットに接続します。
- 分析ノードにカーソルを合わせ、実行アイコン「」をクリックします。
- アウトプットとモデルペインで、「薬剤]の分析出力をクリックして結果を表示する。
Analysisノードの出力は、この人工データセットで、モデルがデータセット内のすべてのレコードについて薬剤の選択を正しく予測したことを示している。 実際のデータセットで100%の精度を見ることはまずありませんが、分析ノードを使用することで、モデルが特定のアプリケーションで許容できる精度かどうかを判断することができます。
![]() 進捗状況を確認する
進捗状況を確認する
次の画像は分析出力を示している。

サマリー
この例では、薬物治療に関するグラフを作成し、それを使って、将来同じ病気の患者にどの薬が適切かを調べる方法を紹介した。
次のステップ
これで、他の SPSS® Modeler チュートリアルを試す準備ができました。