当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
電気通信の顧客を分類する
最終更新: 2025年2月11日
このチュートリアルでは、入力フィールドの値に基づいてレコードを分類する統計手法であるロジスティック回帰モデルを構築します。 線型と似ていますが、数値型対象フィールドではなくカテゴリー対象フィールドを取ります。
たとえば、ある電気通信事業者が、顧客ベースをサービス利用パターンでセグメント化し、顧客を4つのグループに分類したとする。 人口統計データを使用して顧客がどのグループに所属するかを予測できれば、個々の見込み客にあわせてサービスをカスタマイズすることができます。
チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料となることを目的としています。 このビデオでは、このドキュメントのコンセプトとタスクを視覚的に学習する方法を提供しています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料となることを目的としています。 このビデオでは、このドキュメントのコンセプトとタスクを視覚的に学習する方法を提供しています。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
このチュートリアルでは、サンプル・プロジェクトのClassifying Telecommunications Customerフローを使用します。 使用するデータファイルはtelco.csvである。 次の図は、モデラーのフロー例を示しています。

次の画像は、このモデラーフローで使用されるデータセットである。
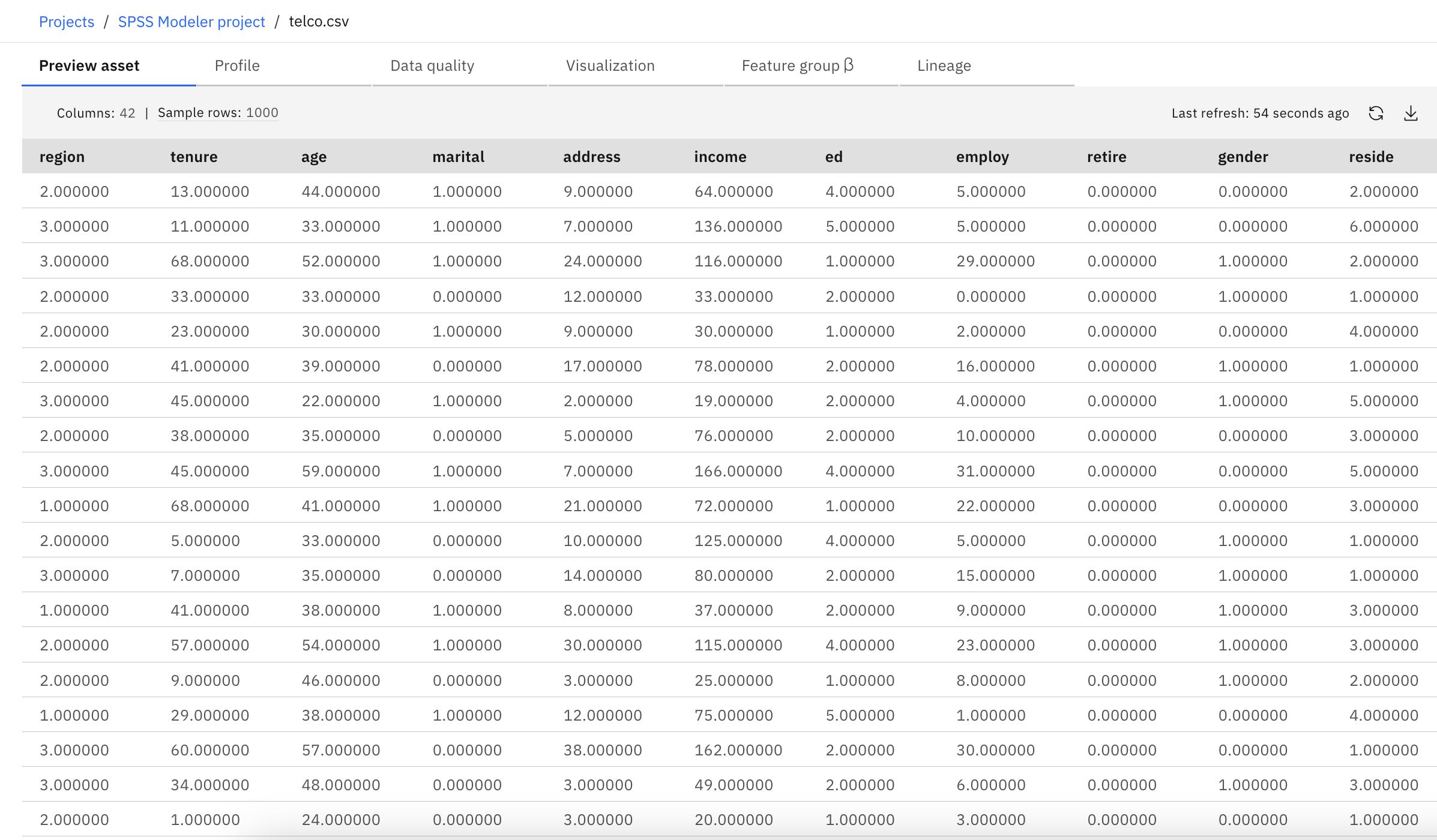
この例は、使用パターンを予測するための人口統計データの使用方法に注目します。 以下のように、対象フィールド
custcat| 値 | ラベル |
|---|---|
| 1 | 基本サービス |
| 2 | E-サービス |
| 3 | プラス・サービス |
| 4 | トータル・サービス |
対象に複数のカテゴリーがあるために、多項モデルを使用します。 対象が、はい/いいえ、真/偽、解約する/しないのような2つの異なるカテゴリーを持つ場合、代わりに2項モデルが作成されるかもしれない。
タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプルプロジェクトをまだお持ちでない場合は、 チュートリアルのトピックを参照してサンプルプロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataナビゲーションメニューから
 、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。
、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。 - SPSS ModelerProjectをクリックします。
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。

タスク 2: データ資産、タイプ、およびフィルタのノードを調べる
Classifying Telecommunication Customersモデラーのフローにはいくつかのノードがあります。 以下の手順に従って、3つのノードを調べる:
- Assetsタブから、Classifying Telecommunication Customersモデラー・フローを開き、キャンバスがロードされるのを待ちます。
- telco.csvノードをダブルクリックする。 このノードは、プロジェクト内のtelco.csvファイルを指すData Assetノードです。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
- Typeノードをダブルクリックし、Read Valuesをクリックする。 このノードは、測定レベル(フィールドが含むデータのタイプ)などのフィールド・プロパティや、モデリングにおけるターゲットまたは入力としての各フィールドの役割を指定する。 すべての測定レベルが正しく設定されていることを確認する。 例えば、
0.01.0図3: 尺度 
gender - 「
custcat - Filterノードをダブルクリックしてプロパティを表示します。
- このノードは、関連するフィールド('
regionagemaritaladdressincomeedemployretiregenderresidecustcat
![]() 進捗状況を確認する
進捗状況を確認する
次の図はFilterノードを示している。 これでロジスティック・ノードを表示する準備ができました。

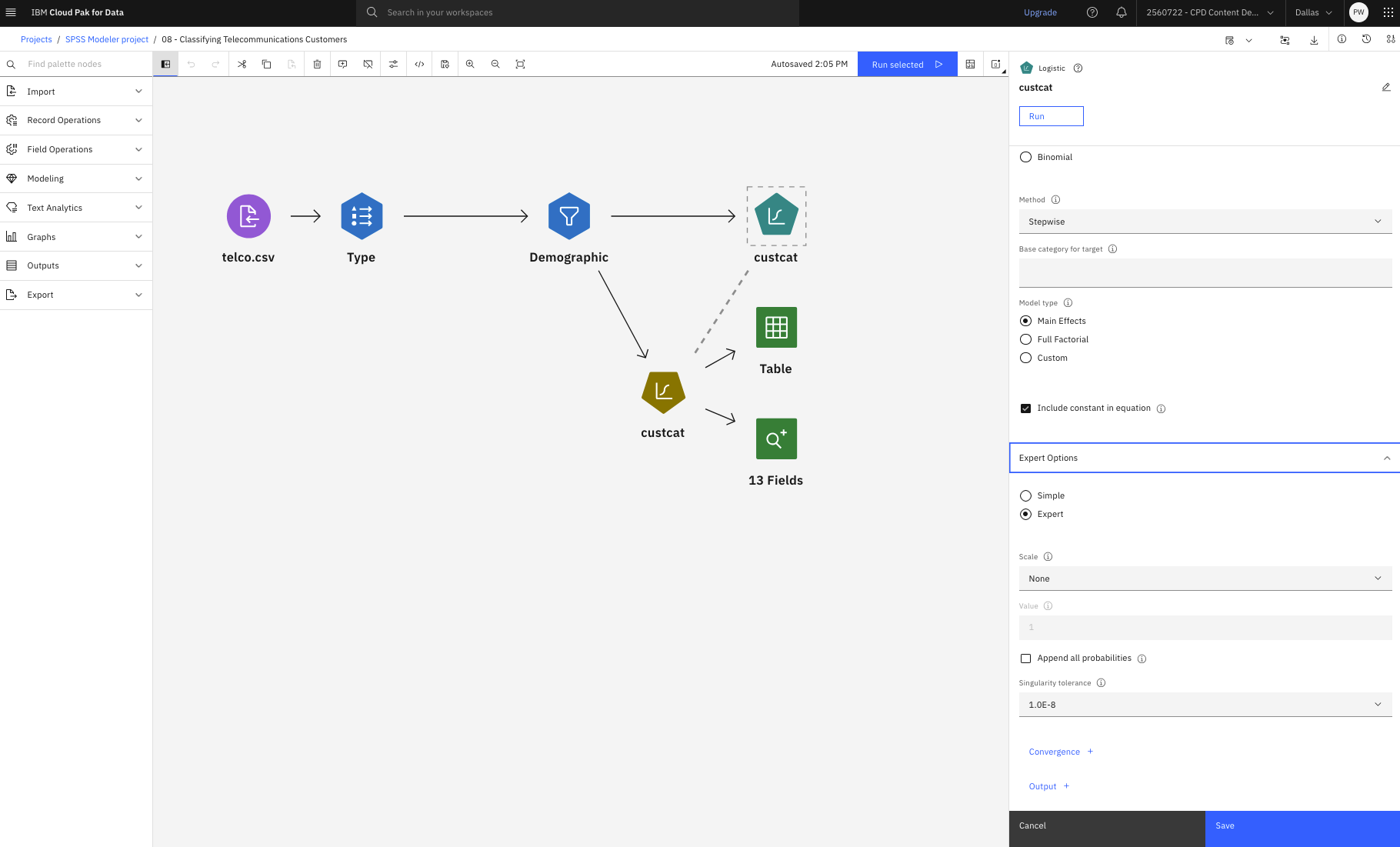
タスク3:ロジスティック・ノードの表示
多項ロジスティック回帰を使用して顧客を分類するには、以下の手順に従ってください:
- custcat (Logistic)ノードをダブルクリックしてプロパティを見る。
- モデル設定セクションで、多項式手順を選択する。
- 二項モデルは、対象フィールドが2つの離散値を持つフラグフィールドまたはノミナルフィールドである場合に使用される。
- 多項モデルは、対象フィールドが2つ以上の値を持つ名義フィールドである場合に使用される。
- 次に、ステップワイズ法と主効果モデルタイプを選択します。 また、方程式に定数を含めるチェックボックスを選択します。
図4: ロジスティック・ノード・モデルの設定 
- Expert Optionsセクションで、Expertモードを選択する。
- 出力をクリックする。 分類表を選択し、OKをクリックする。
図 5. ロジスティック・ノード 出力オプション 
![]() 進捗状況を確認する
進捗状況を確認する
次の図はLogisticノードを示しています。 これでモデルをブラウズする準備が整いました。
タスク4:モデルのブラウズ
以下の手順に従ってモデルをブラウズしてください:
- custcat(ロジスティクス)ノードの上にカーソルを移動し、 実行アイコン
 をクリックします。
をクリックします。 - Outputs and models(出力とモデル)ペインで、custcatモデルをクリックして結果を表示する。
図 6. モデルの特徴 重要度チャート 
その後、モデル情報、特徴量 (予測値) の重要度、およびパラメーター推定値情報を検討できます。
これらの結果はトレーニングデータのみに基づいている。 モデルが実世界の他のデータにどの程度一般化されるかを評価するために、Partitionノードを使用して、テストと検証の目的でレコードのサブセットを保持することができます。
![]() 進捗状況を確認する
進捗状況を確認する
サマリー
この例では、入力フィールドの値に基づいてレコードを分類するロジスティック回帰モデルを構築することで、人口統計データを使用して利用パターンを予測する方法を示しました。
次のステップ
これで、他の SPSS® Modeler チュートリアルを試す準備ができました。
トピックは役に立ちましたか?
0/1000