本教程将建立逻辑回归模型,这是一种根据输入字段值对记录进行分类的统计技术。 它类似于线性回归,但采用的是分类目标字段而不是数字字段。
例如,假设一家电信运营商担心自己的客户数量被竞争对手抢走。 如果可以使用服务使用情况数据预测有可能转移到其他提供商的客户,则可通过定制服务来尽可能多地保留这些客户。
预览教程
 观看本视频,预览本教程的步骤。 视频中显示的用户界面可能略有不同。 该视频旨在作为书面教程的补充。 本视频以直观的方式介绍了本文件中的概念和任务。
观看本视频,预览本教程的步骤。 视频中显示的用户界面可能略有不同。 该视频旨在作为书面教程的补充。 本视频以直观的方式介绍了本文件中的概念和任务。
试用教程
在本教程中,您将完成这些任务:
建模流程和数据集样本
本教程使用示例项目中的电信流失流程。 使用的数据文件是telco.csv。 下图显示了建模流程示例。

本示例主要讲述利用使用情况数据来预测客户流失(顾客流失率)。 由于目标具有两个截然不同的类别,因此将使用二项模型。 如果目标有多个类别,则可以创建一个多二项模型。
下图显示了该建模流程所使用的数据集。

任务 1:打开示例项目
任务 2:检查数据资产和类型节点
电信流失包括几个节点。 按照以下步骤检查数据资产和类型节点:
- 从 "资产"选项卡,打开 "电信流失"建模流程,等待画布加载。
- 双击telco.csv节点。 该节点是数据资产节点,指向项目中的telco.csv文件。
- 查看文件格式属性。
- 可选:单击 "预览数据"查看完整数据集。
- 双击类型节点。 该节点指定字段属性,如测量级别(字段包含的数据类型),以及每个字段在建模中作为目标或输入的作用。 确保所有测量级别设置正确。 例如,大多数值为 "
0.0和 "1.0的字段可被视为标志,但某些字段(如性别)被视为具有两个值的名义字段更为准确。请注意,"图 3。 测量级别 
churn被设置为具有目标角色的标志。 所有其他字段的角色都设置为输入。 - 双击搅动(特征选择)建模节点,查看其属性。 您可以使用 "特征选择"节点来删除那些不能为预测因子/目标关系添加任何有用信息的预测因子或数据。
- 将鼠标悬停在 “功能选择”节点上 ,点击 “运行”图标
 。
。 - 在 "输出和模型"窗格中,单击列表中第一个名称为churn的模型,查看模型详细信息。
![]() 查看进度
查看进度
下图显示了模型的详细信息。 现在您可以检查过滤器节点了。

任务 3:检查过滤器节点
telco.csv数据文件中只有部分数据有助于预测客户流失率。 您可以使用筛选器只选择被认为重要的数据作为预测指标(在上一个任务中生成的模型中标记为重要的字段)。 请按照以下步骤查看和检查过滤器节点:
- 双击重要特征(筛选器)节点,查看其属性。
- 请注意,该节点只筛选出所选字段:"
tenure、"age、"address、"income、"ed、"employ等。 本分析不包括其他字段。图 4: 过滤节点重要功能 
- 请单击取消。
- 请注意,该节点只筛选出所选字段:"
- 双击过滤器节点后的28 字段(数据审核)输出节点。
- 将鼠标悬停在 “数据审核”节点上 ,点击 “运行”图标 。
- 在 "输出和模型"窗格中,单击名称为 "数据审计"的结果以查看输出。
- 查看 "完成百分比"列,您可以用它来识别有大量缺失数据的字段。 在此情况下,需要修改的唯一字段是
logtoll,其完成率低于 50%。图 5. 28 字段输出 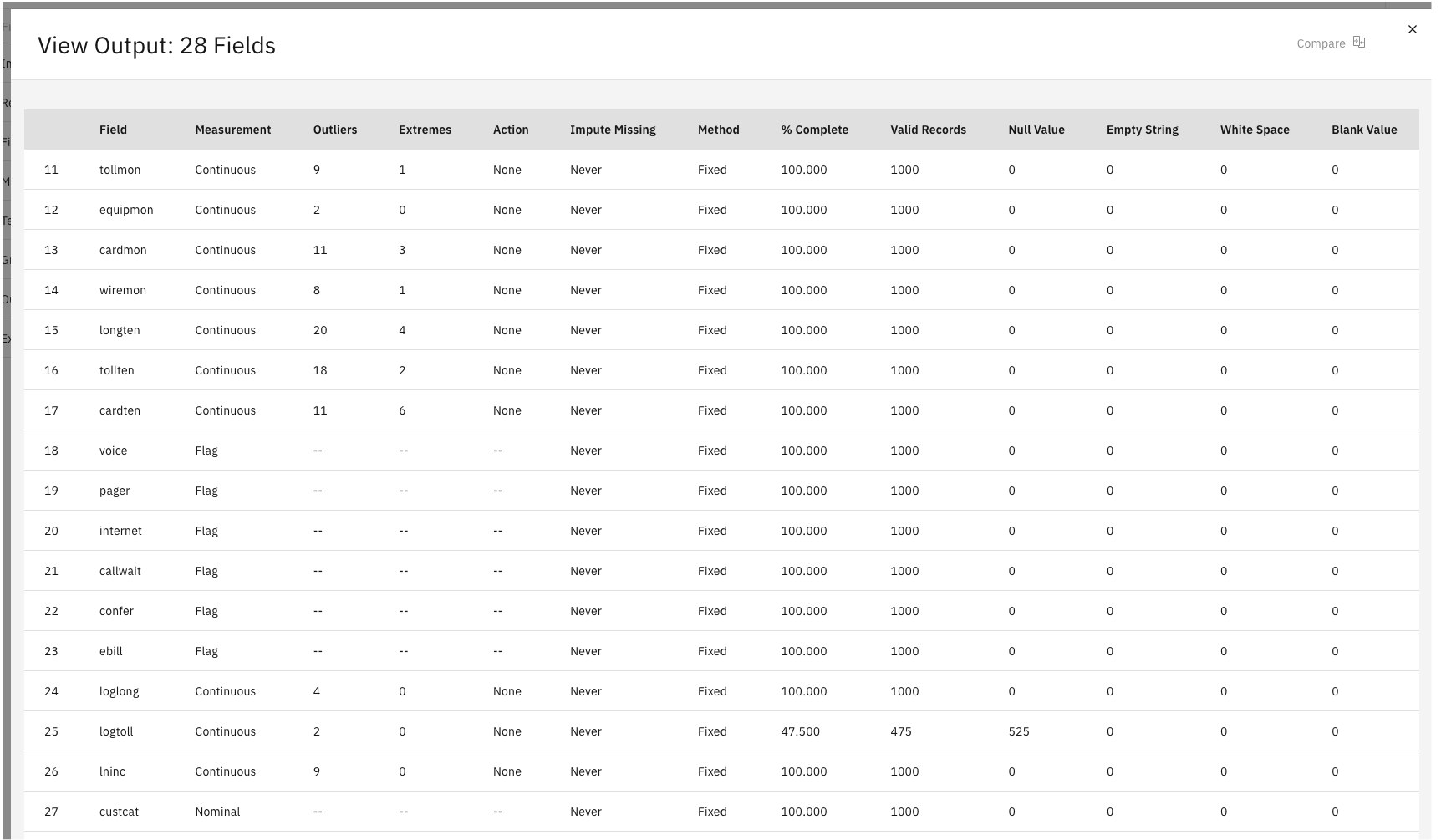
- 关闭输出。
- 将鼠标悬停在 “数据审核”节点上 ,点击 “运行”图标
- 双击缺失值估算超级节点。
- 单击查看超级节点。
- 双击Fill logtoll (Filler)节点。填充节点用于替换字段值和更改存储。 您可以选择基于指定的 CLEM 条件(如
@BLANK(FIELD))替换值。 或者,也可以选择将所有空白值或空值替换为特定值。 填充节点通常与类型节点一起用于替换缺失值。在 "填写字段 "部分,您可以指定要检查和替换其值的数据集中的字段。 在本例中,"logtoll列与 "替换"部分下的 "空白 "和 "空值"选项一起指定。图 6. 具有填充属性的缺失值处理超级节点 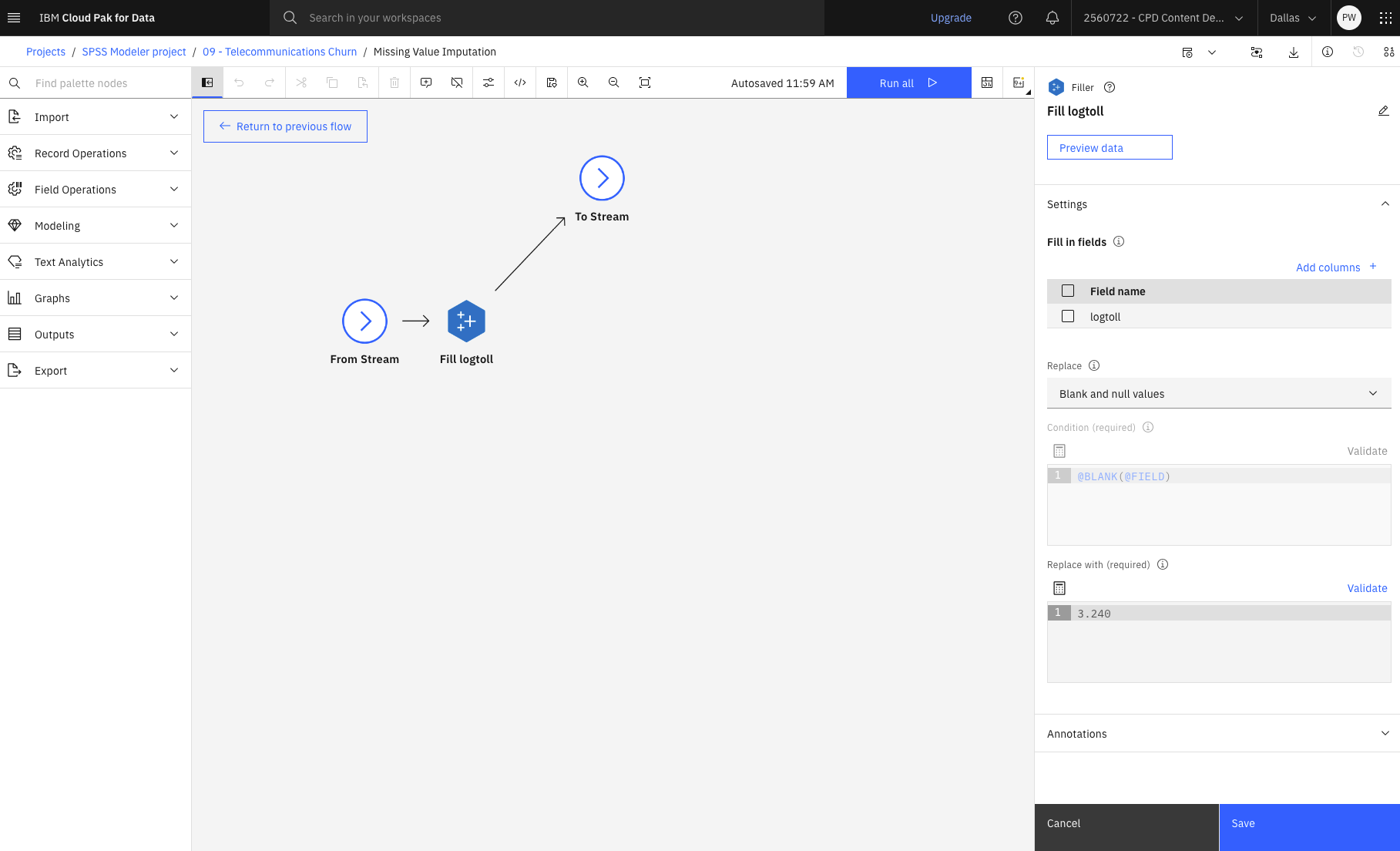
- 单击返回上一流程。
![]() 查看进度
查看进度
下图说明了该流。 现在您可以开始制作模型了。

任务 4:建立模型
您建立了一个使用Logistic节点的模型。 请按照以下步骤建立模型:
- 双击 "缺失值输入"超级节点后的 "流失(逻辑)"节点,查看其属性。
- 在模型设置部分,选择二叉程序。
- 当目标字段是具有两个离散值的标志字段或名义字段时,就会使用二项式模型。
- 当目标字段是一个具有两个以上值的名义字段时,就会使用多项式模型。
- 接下来,选择向前逐步法。
- 在专家选项部分,选择专家模式。
- 单击输出。 选择每个步骤、迭代历史记录和参数估计,然后单击确定。
图 7. 逻辑节点选项 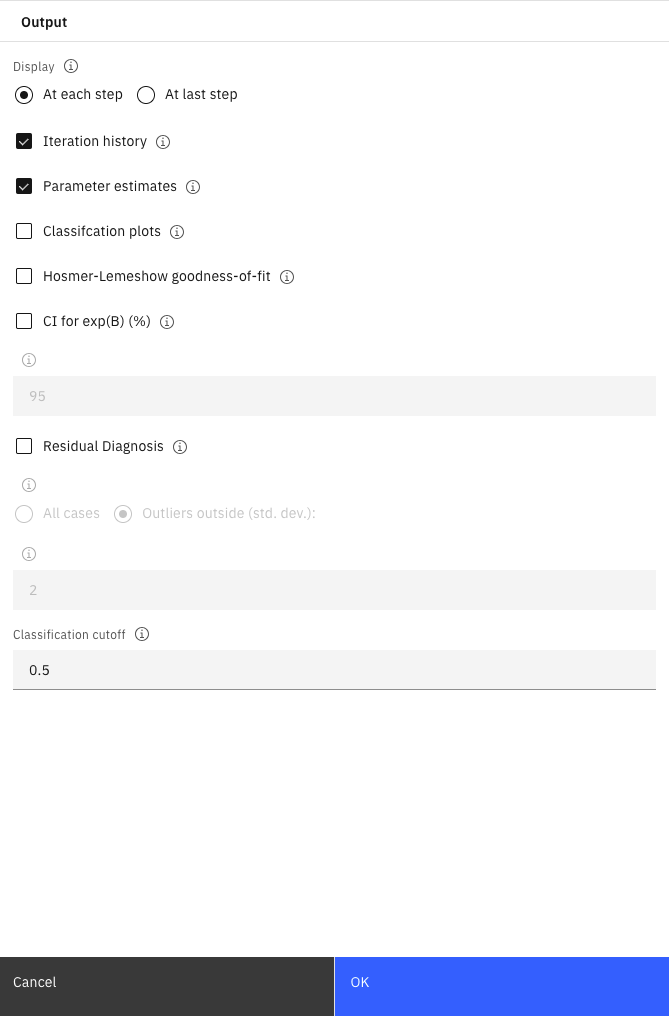
![]() 查看进度
查看进度
下图说明了该流。 现在就可以生成模型了。

任务 5:生成模型
请按照以下步骤从Logistic 节点生成模型金块:
- 将鼠标悬停在 “物流”节点上 ,点击 “运行”图标 。
- 在 "输出和模型"窗格中,单击 "流失模型 "查看结果。
方程中的变量页面显示了模型使用的目标(流失率)和输入(预测字段)。 这些字段是根据 "向前逐步法 "选择的,而不是提交审议的完整清单。
为了评估模型与数据的拟合程度,在构建流程时,专家节点设置中提供了几种诊断方法。
另请注意,这些结果仅基于训练数据。 为了评估模型对现实世界中其他数据的泛化程度,您可以使用分区节点来保留记录子集,以便进行测试和验证。
![]() 查看进度
查看进度
下图显示了模型结果。

目录
本例展示了如何使用使用数据通过建立二叉模型来预测客户流失(流失),因为目标客户有两个不同的类别。
后续步骤
现在您可以尝试其他 SPSS® Modeler 教程了。