Predict telecommunications churn
This tutorial builds a logistic regression model, which is a statistical technique for classifying records based on values of input fields. It is analogous to linear regression, but takes a categorical target field instead of a numeric field.
For example, suppose that a telecommunications provider is concerned about the number of customers it's losing to competitors. If service usage data can be used to predict which customers are liable to transfer to another provider, offers can be customized to retain as many customers as possible.
Preview the tutorial
 Watch this video to preview the steps in this tutorial. There might
be slight differences in the user interface that is shown in the video. The video is intended to be
a companion to the written tutorial. This video provides a visual method to learn the concepts and
tasks in this documentation.
Watch this video to preview the steps in this tutorial. There might
be slight differences in the user interface that is shown in the video. The video is intended to be
a companion to the written tutorial. This video provides a visual method to learn the concepts and
tasks in this documentation.
Try the tutorial
In this tutorial, you will complete these tasks:
Sample modeler flow and data set
This tutorial uses the Telecommunications Churn flow in the sample project. The data file used is telco.csv. The following image shows the sample modeler flow.

This example focuses on using usage data to predict customer loss (churn). Because the target has two distinct categories, a binomial model is used. If the target has multiple categories, a multinomial model might be created instead.
The following image shows the data set used with this modeler flow.
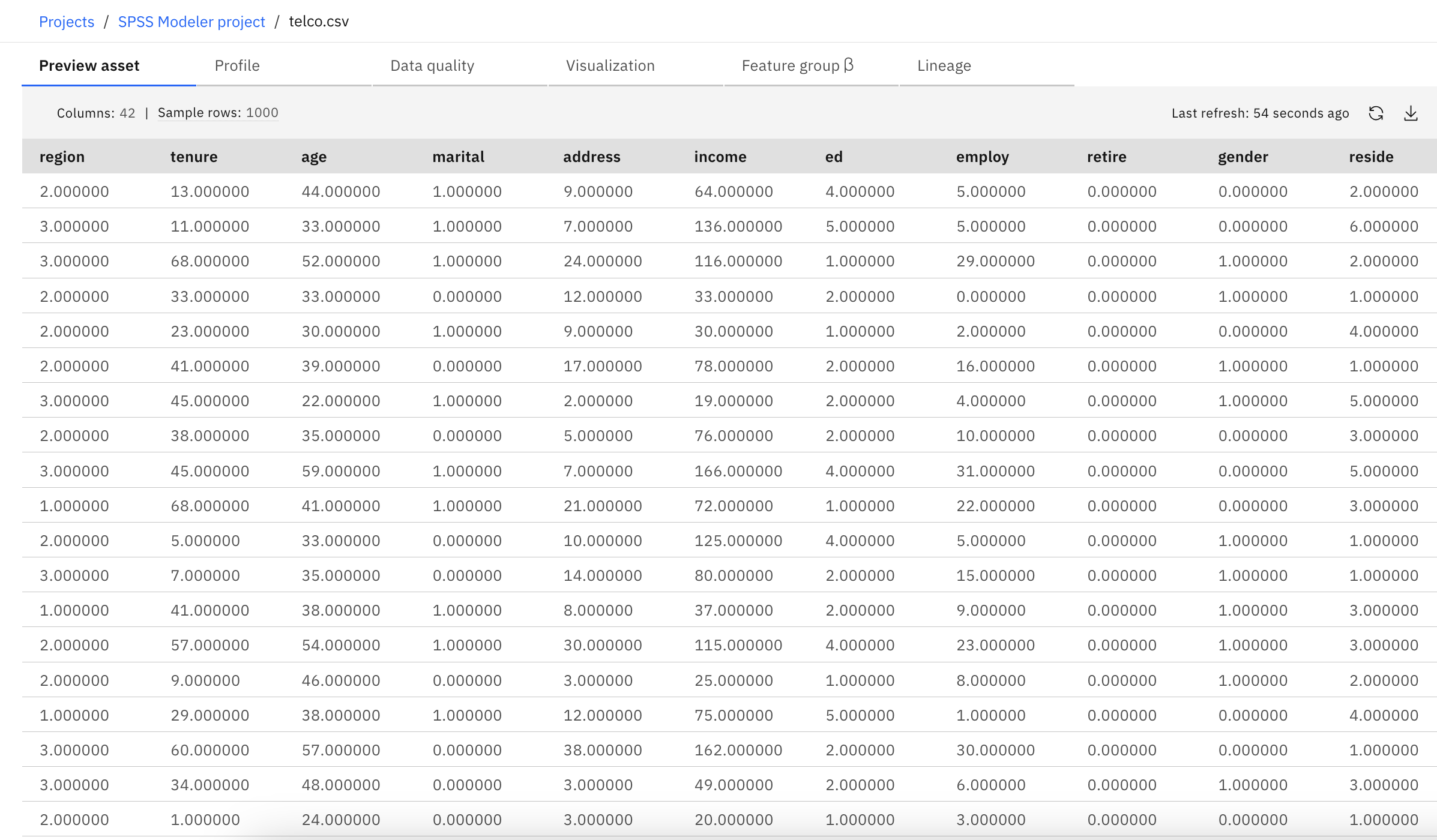
Task 1: Open the sample project
The sample project contains several data sets and sample modeler flows. If you don't already have the sample project, then refer to the Tutorials topic to create the sample project. Then follow these steps to open the sample project:
- In Cloud Pak for Data, from the Navigation menu
 , choose
Projects > View all Projects.
, choose
Projects > View all Projects. - Click SPSS Modeler Project.
- Click the Assets tab to see the data sets and modeler flows.
![]() Check your progress
Check your progress
The following image shows the project Assets tab. You are now ready to work with the sample modeler flow associated with this tutorial.

Task 2: Examine the Data Asset and Type node
Telecommunication Churn includes several nodes. Follow these steps to examine the Data Asset and Type nodes:
- From the Assets tab, open the Telecommunication Churn modeler flow, and wait for the canvas to load.
- Double-click the telco.csv node. This node is a Data Asset node that points to the telco.csv file in the project.
- Review the File format properties.
- Optional: Click Preview data to see the full data set.
- Double-click the Type node. This node specifies field properties, such as measurement
level (the type of data that the field contains), and the role of each field as a target or input in
modeling. Make sure that all measurement levels are set correctly. For example, most fields with
values of
0.01.0Notice thatFigure 3. Measurement levels 
churn - Double-click the churn (Feature Selection) modeling node to see its properties. You can use a Feature Selection node to remove predictors or data that don't add any useful information about the predictor/target relationship.
- Hover over the churn (Feature Selection) node, and click the Run icon
 .
. - In the Outputs and models pane, click the first model in the list with the name churn to view the model details.
![]() Check your progress
Check your progress
The following image shows the model details. You are now ready to check the Filter node.

Task 3: Check the Filter node
Only some of the data in the telco.csv data file are useful in predicting churn. You can use the filter to select just the data that is considered to be important for use as a predictor (the fields marked as Important in the model that is generated in the previous task). Follow these steps to see and check the Filter node:
- Double-click the Important Features (Filter) node to see its properties.
- Notice that this node filters out only selected fields:
tenureageaddressincomeedemployFigure 4. Filter node Important Features 
- Click Cancel.
- Notice that this node filters out only selected fields:
- Double-click the 28 Fields (Data Audit) output node after the Filter node.
- Hover over the Data Audit node, and click the Run icon .
- In the Outputs and models pane, click the results with the name Data Audit to view the output.
- Look at the % Complete column, which you can use to identify any fields
with large amounts of missing data. In this case, the only field you need to amend is
logtollFigure 5. 28 Fields output 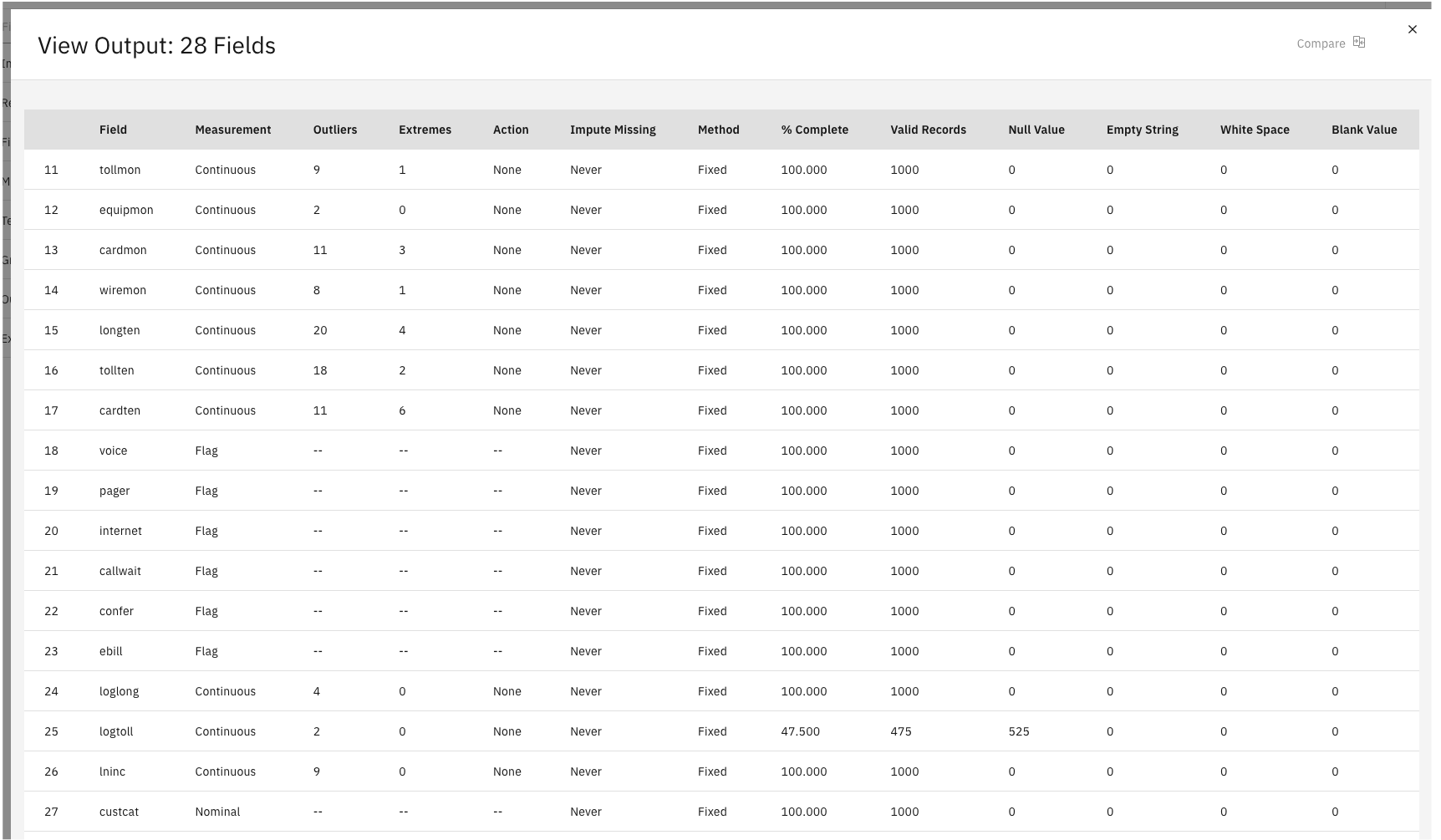
- Close the Output.
- Hover over the Data Audit node, and click the Run icon
- Double-click the Missing Value Imputation supernode.
- Click View supernode.
- Double-click Fill logtoll (Filler) node.
Filler nodes are used to replace
field values and change storage. You can choose to replace values based on a specified CLEM
condition, such as
@BLANK(FIELD)logtollFigure 6. Missing Value Imputation supernode with Filler properties 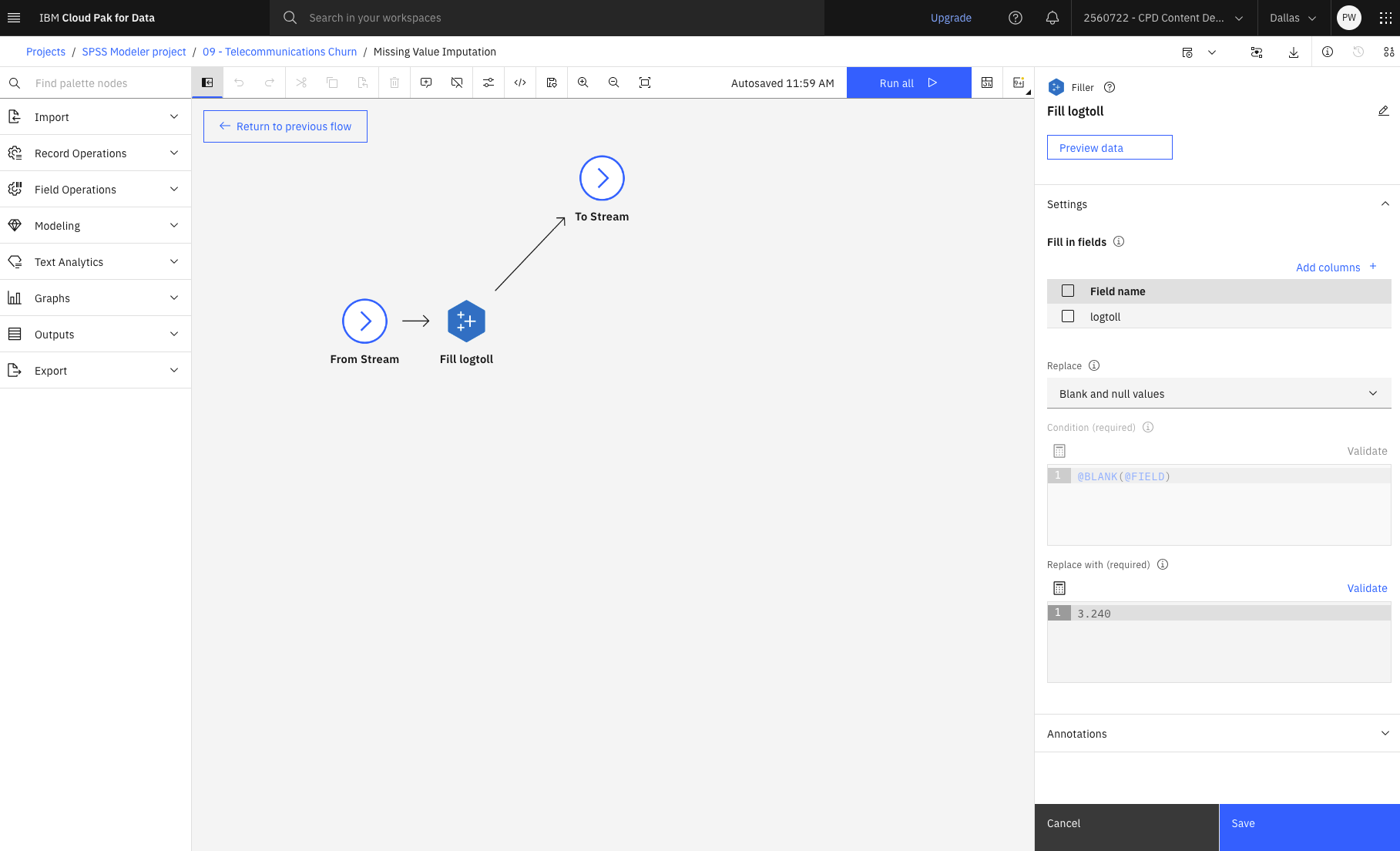
- Click Return to previous flow.
![]() Check your progress
Check your progress
The following image shows the flow. You are now ready to build the model.
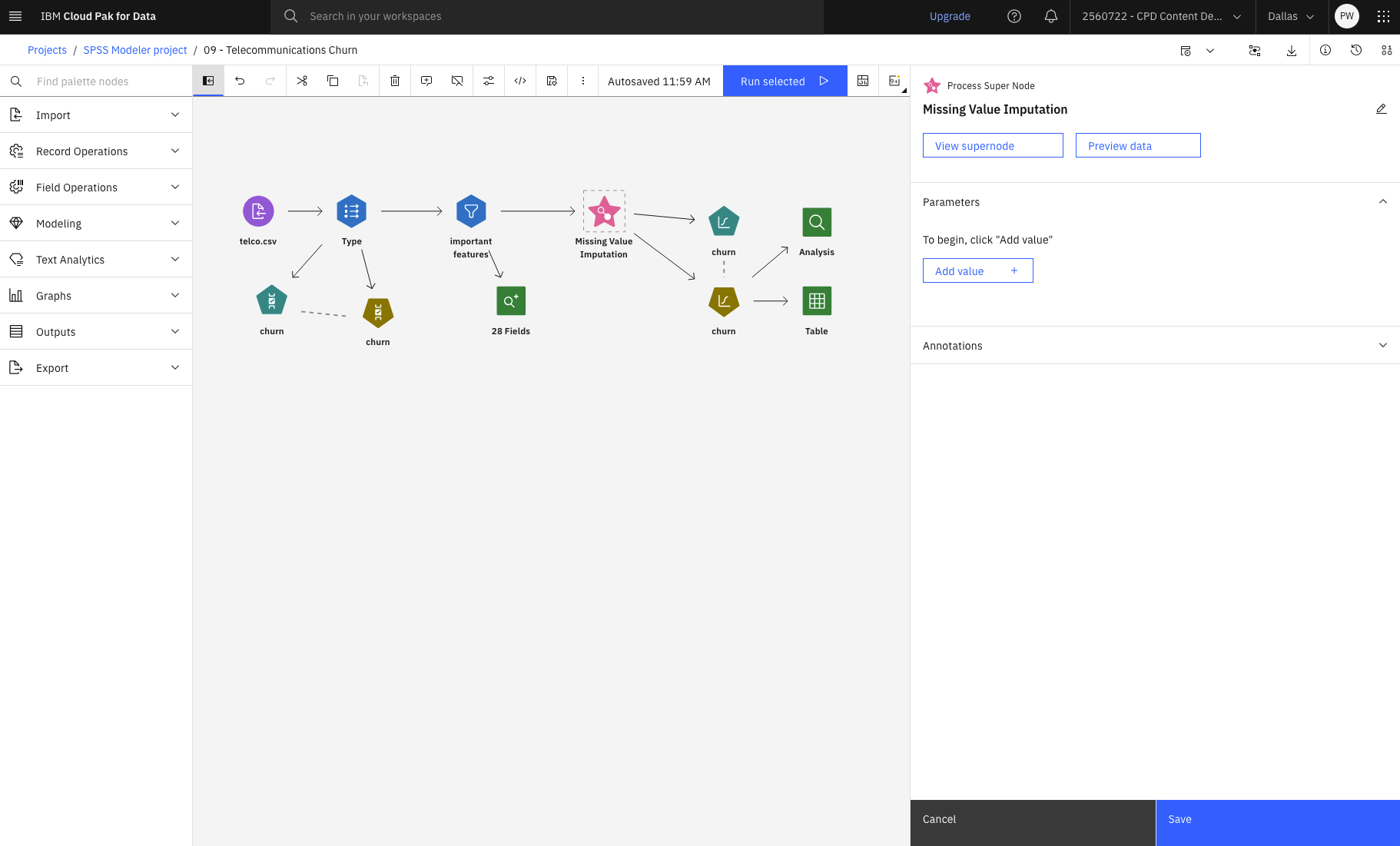
Task 4: Build the model
You build a model that uses the Logistic node. Follow these steps to build the model:
- Double-click the churn (Logistic) node, after the Missing Value Imputation supernode, to view its properties.
- In the Model Settings section, select the Binomial procedure.
- A Binomial model is used when the target field is a flag or nominal field with two discrete values.
- A Multinomial model is used when the target field is a nominal field with more than two values.
- Next, select the Forwards Stepwise method.
- In the Expert Options section, select Expert mode.
- Click Output. Select At each step, Iteration
history, and Parameter estimates, then click
OK.
Figure 7. Logistic node options 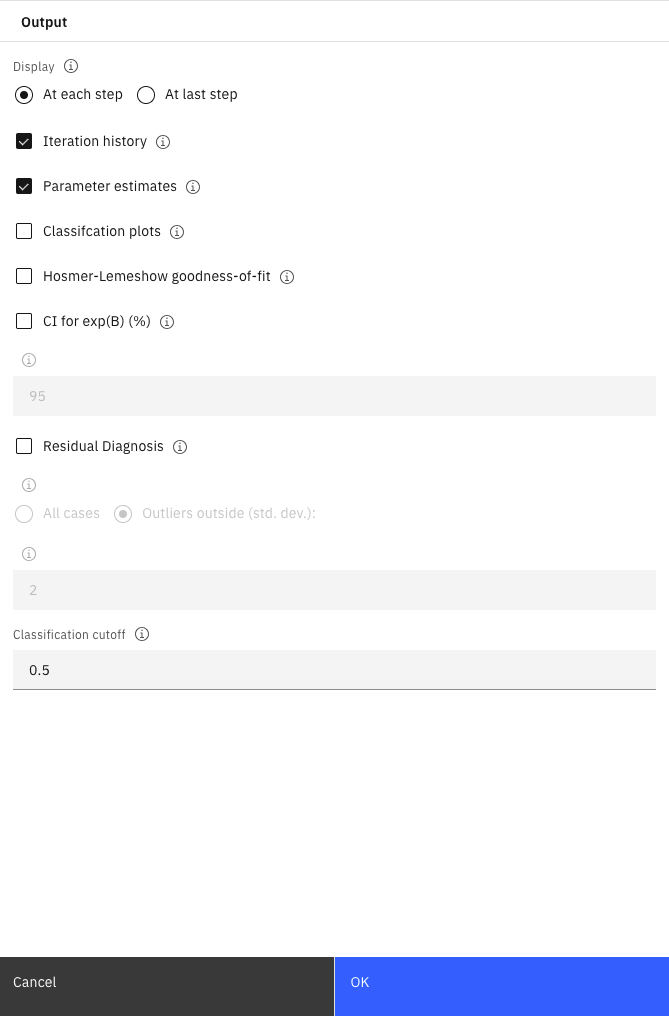
![]() Check your progress
Check your progress
The following image shows the flow. You are now ready to generate the model.
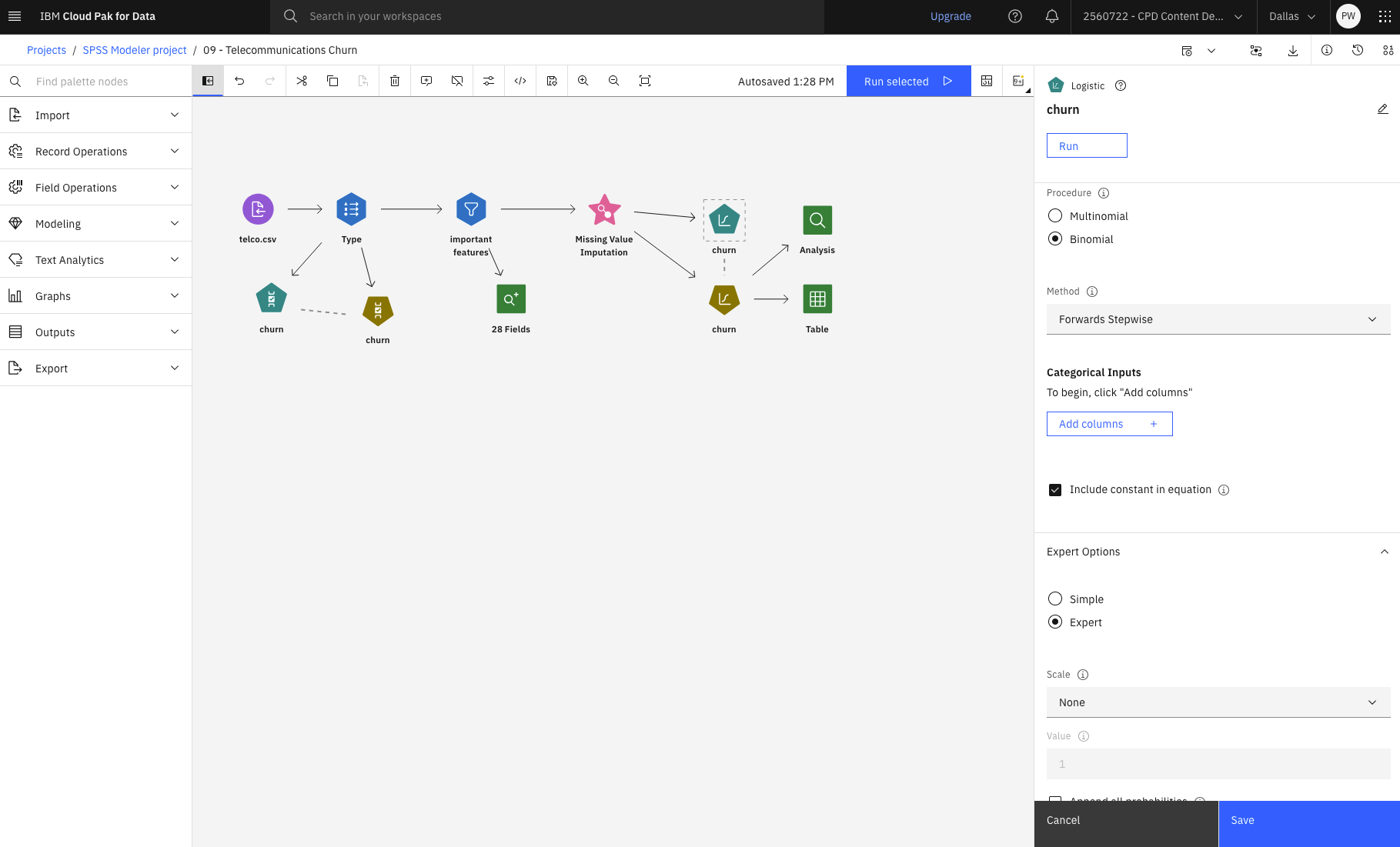
Task 5: Generate the model
Follow these steps to generate a model nugget from the Logistic node:
- Hover over the churn (Logistic) node, and click the Run icon .
- In the Outputs and models pane, click the churn model to view the results.
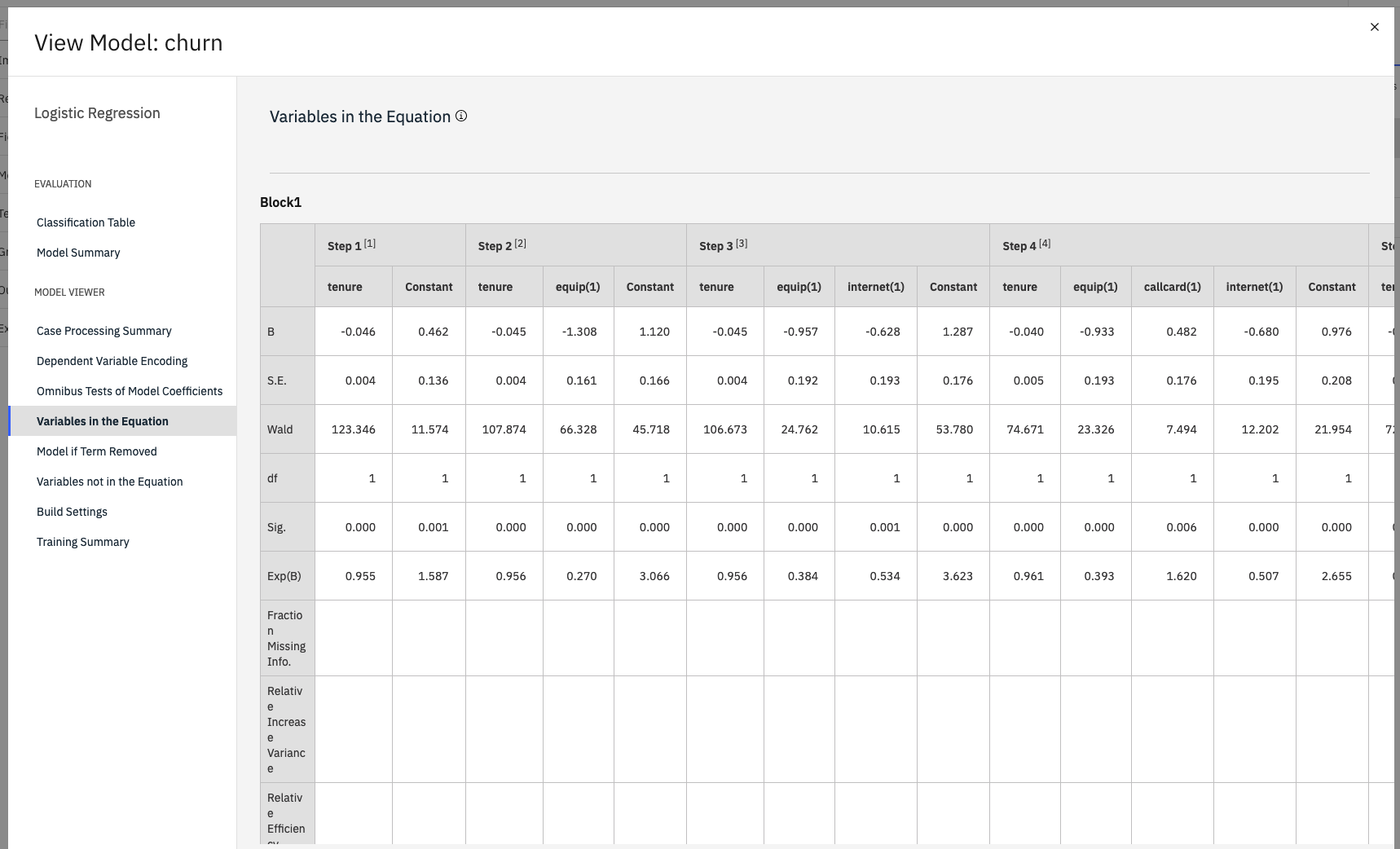
The Variables in the Equation page shows the target (churn) and inputs (predictor fields) used by the model. These fields are chosen based on the Forwards Stepwise method, not the complete list submitted for consideration.
To assess how well the model fits your data, several diagnostics are available in the expert node settings when you're building the flow.
Note also that these results are based on the training data only. To assess how well the model generalizes to other data in the real world, you use a Partition node to hold out a subset of records for purposes of testing and validation.
![]() Check your progress
Check your progress
The following image shows the model results.
Summary
This example showed how to use usage data to predict customer loss (churn) by building a binomial model because the target has two distinct categories.
Next steps
You are now ready to try other SPSS® Modeler tutorials.