Ce tutoriel construit un modèle de régression logistique, qui est une technique statistique permettant de classer les enregistrements en fonction des valeurs des champs de saisie. Elle est analogue à la régression linéaire, mais prend un champ cible catégoriel au lieu d'un champ numérique.
Supposons, par exemple, qu'un fournisseur de télécommunications s'inquiète du nombre de clients qu'il perd au profit de ses concurrents. Si les données d'utilisation du service permettent de prédire les clients susceptibles de passer à un autre fournisseur, les offres peuvent être personnalisées afin de retenir autant de clients que possible.
Essayez le tutoriel
Dans ce tutoriel, vous exécutez les tâches suivantes :
Exemple de flux de modélisateurs et d'ensembles de données
Ce tutoriel utilise le flux de désabonnement des télécommunications dans le projet d'exemple. Le fichier de données utilisé est telco.csv. L'image suivante montre un exemple de flux de modélisation.

Cet exemple explique comment se servir des données d'utilisation pour prédire la perte de clients (attrition). Etant donné que la cible présente deux catégories distinctes, un modèle binomial est utilisé. Si la cible comporte plusieurs catégories, un modèle multinomial peut être créé à la place.
L'image suivante montre l'ensemble des données utilisées avec ce flux de modélisation.

Tâche 1 : Ouvrir le projet d'exemple
L'exemple de projet contient plusieurs ensembles de données et des exemples de flux de modélisation. Si vous n'avez pas encore le projet exemple, reportez-vous à la rubrique Tutoriels pour créer le projet exemple. Suivez ensuite les étapes suivantes pour ouvrir l'exemple de projet :
- Dans Cloud Pak for Data, à partir du menu de navigation '
 , choisissez Projets > Voir tous les projets.
, choisissez Projets > Voir tous les projets. - Cliquez sur SPSS Modeler Project.
- Cliquez sur l'onglet Actifs pour voir les ensembles de données et les flux du modélisateur.
![]() Vérifier votre progression
Vérifier votre progression
L'image suivante montre l'onglet Actifs du projet. Vous êtes maintenant prêt à travailler avec l'exemple de flux du modeleur associé à ce tutoriel.
Tâche 2 : Examiner le nœud Actif et Type de données
Le taux d'attrition des télécommunications comprend plusieurs nœuds. Procédez comme suit pour examiner les nœuds Data Asset et Type:
- Dans l'onglet Actifs, ouvrez le flux de modélisation du taux d'attrition des télécommunications et attendez que le canevas se charge.
- Double-cliquez sur le nœud telco telco.csv. Ce nœud est un nœud de ressources de données qui pointe vers le fichier telco telco.csv du projet.
- Examinez les propriétés du format de fichier.
- Facultatif : cliquez sur "Aperçu des données" pour voir l'ensemble des données : Cliquez sur Aperçu des données pour voir l'ensemble des données.
- Double-cliquez sur le nœud Type. Ce nœud spécifie les propriétés des champs, telles que le niveau de mesure (le type de données que le champ contient), et le rôle de chaque champ en tant que cible ou entrée dans la modélisation. Assurez-vous que tous les niveaux de mesure sont correctement réglés. Par exemple, la plupart des champs dont les valeurs sont "
0.0et "1.0peuvent être considérés comme des drapeaux, mais certains champs, tels que le sexe, sont plutôt considérés comme des champs nominaux à deux valeurs.Notez que 'Figure 3 Niveaux de mesure 
churnest défini comme un drapeau avec un rôle de cible. Le rôle de tous les autres champs est défini sur Entrée. - Double-cliquez sur le nœud de modélisation churn (Feature Selection) pour afficher ses propriétés. Vous pouvez utiliser un nœud de sélection de caractéristiques pour supprimer les prédicteurs ou les données qui n'ajoutent aucune information utile sur la relation prédicteur/cible.
- Survolez le nœud churn (Feature Selection) et cliquez sur l'icône Run "
 .
. - Dans le volet Sorties et modèles, cliquez sur le premier modèle de la liste portant le nom churn pour afficher les détails du modèle.
![]() Vérifier votre progression
Vérifier votre progression
L'image suivante montre les détails du modèle. Vous êtes maintenant prêt à vérifier le nœud Filtre.

Tâche 3 : Vérifier le nœud Filtre
Seules certaines données du fichier telco telco.csv sont utiles pour prédire le taux de désabonnement. Vous pouvez utiliser le filtre pour sélectionner uniquement les données considérées comme importantes pour une utilisation en tant que prédicteur (les champs marqués comme importants dans le modèle généré dans la tâche précédente). Suivez les étapes suivantes pour voir et vérifier le nœud Filtre:
- Double-cliquez sur le nœud Caractéristiques importantes (Filtre) pour afficher ses propriétés.
- Notez que ce nœud ne filtre que les champs sélectionnés : "
tenure, "age, "address, "income, "ed, "employ, etc. Les autres champs sont exclus de cette analyse.Figure 4 Caractéristiques importantes du nœud de filtre 
- Cliquez sur Annuler.
- Notez que ce nœud ne filtre que les champs sélectionnés : "
- Double-cliquez sur le nœud de sortie 28 Fields (Data Audit) après le nœud Filter.
- Survolez le nœud Audit de données et cliquez sur l'icône Exécuter " .
- Dans le volet Sorties et modèles, cliquez sur les résultats portant le nom Audit de données pour afficher la sortie.
- Examinez la colonne % Complete, qui vous permet d'identifier les champs présentant un grand nombre de données manquantes. Dans notre exemple, le seul champ à amender est
logtoll, qui est complet à moins de 50 %.Figure 5. 28 Champs de sortie 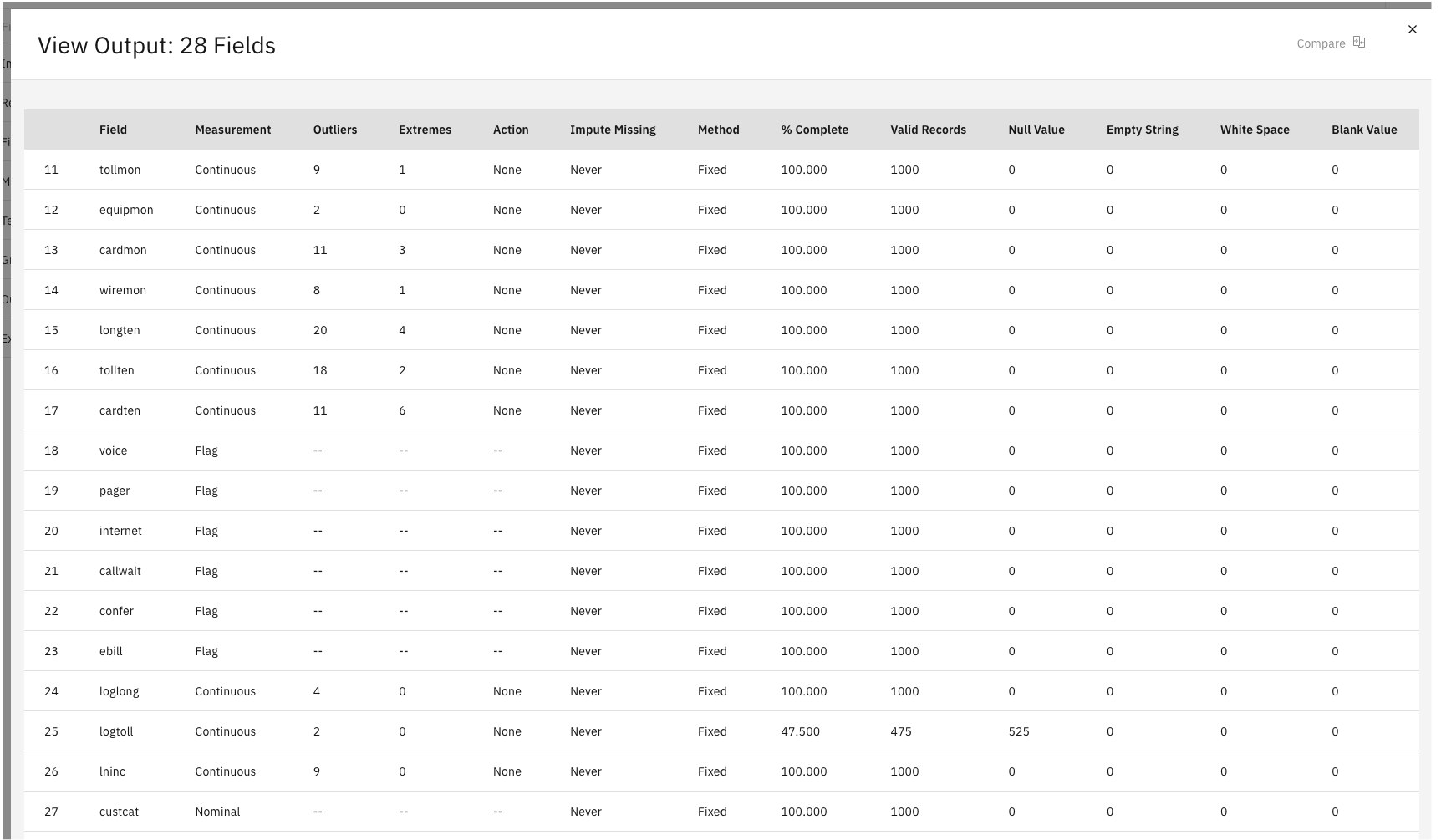
- Fermer la sortie.
- Survolez le nœud Audit de données et cliquez sur l'icône Exécuter "
- Double-cliquez sur le supernœud Imputation des valeurs manquantes.
- Cliquez sur View supernode.
- Double-cliquez sur le nœud Fill logtoll (Filler).Les nœuds de remplissage sont utilisés pour remplacer les valeurs des champs et modifier le stockage. Vous pouvez choisir de remplacer les valeurs sur la base d'une condition CLEM spécifiée, telle que '
@BLANK(FIELD). Vous pouvez également choisir de remplacer tous les blancs ou toutes les valeurs nulles par une valeur précise. Les nœuds de remplissage sont souvent utilisés avec le nœud Type pour remplacer les valeurs manquantes.Dans la section Remplir les champs, vous pouvez spécifier les champs de l'ensemble de données dont les valeurs doivent être examinées et remplacées. Dans ce cas, la colonne "logtollest spécifiée avec une option Valeurs vides et nulles dans la section Remplacer.Figure 6 Supernœud d'imputation des valeurs manquantes avec propriétés de remplissage 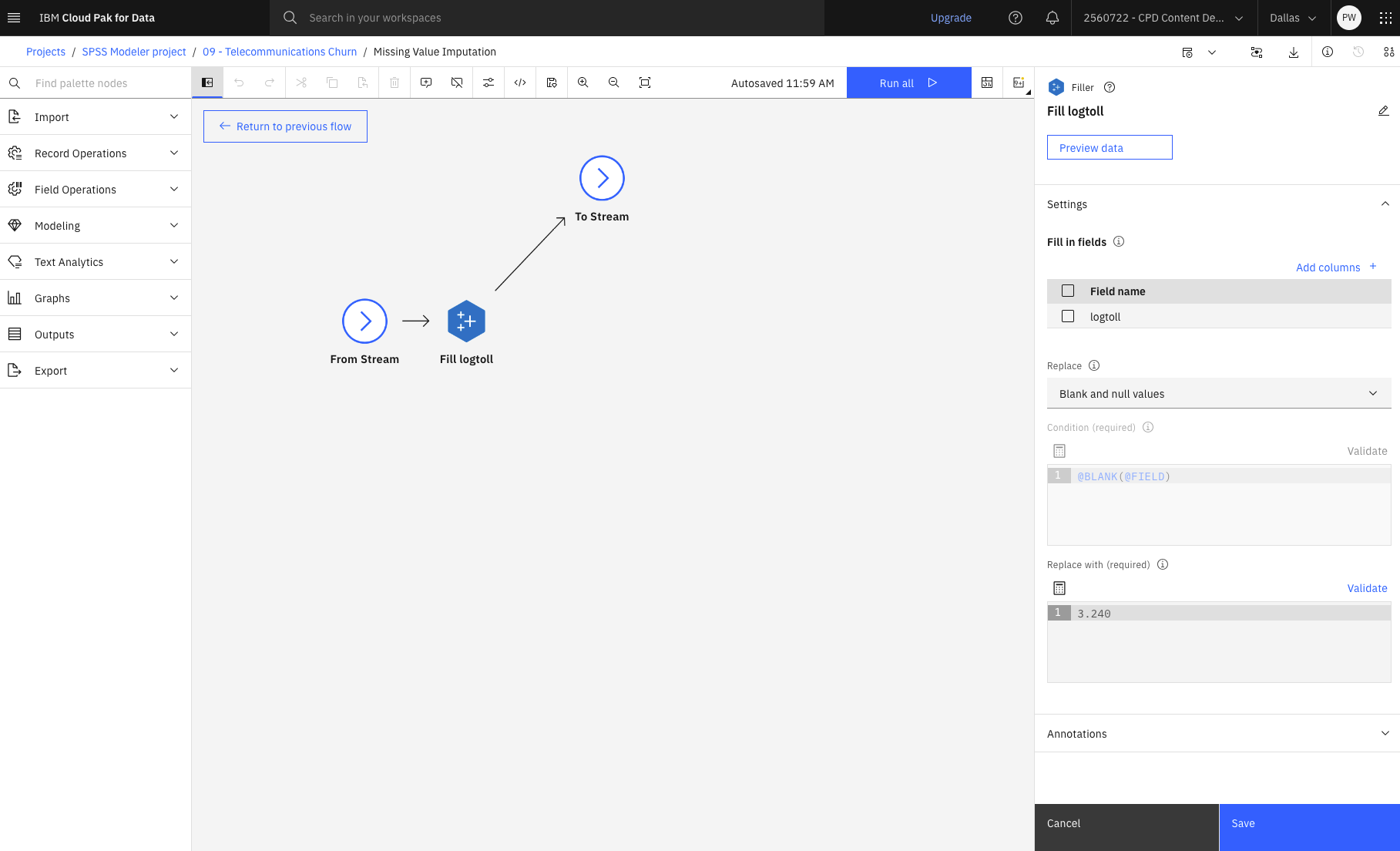
- Cliquez sur Retour au flux précédent.
![]() Vérifier votre progression
Vérifier votre progression
L'image suivante illustre le flux. Vous êtes maintenant prêt à construire le modèle.

Tâche 4 : Construire le modèle
Vous construisez un modèle qui utilise le nœud logistique. Suivez les étapes suivantes pour construire le modèle :
- Double-cliquez sur le nœud churn (Logistic), après le supernœud Missing Value Imputation, pour afficher ses propriétés.
- Dans la section Paramètres du modèle, sélectionnez la procédure binomiale.
- Un modèle binomial est utilisé lorsque le champ cible est un drapeau ou un champ nominal avec deux valeurs discrètes.
- Un modèle multinomial est utilisé lorsque le champ cible est un champ nominal comportant plus de deux valeurs.
- Sélectionnez ensuite la méthode Pas à pas.
- Dans la section Options de l'expert, sélectionnez le mode Expert.
- Cliquez sur Output. Sélectionnez A chaque étape, Historique des itérations et Estimations des paramètres, puis cliquez sur OK.
Figure 7 Options de nœuds logistiques 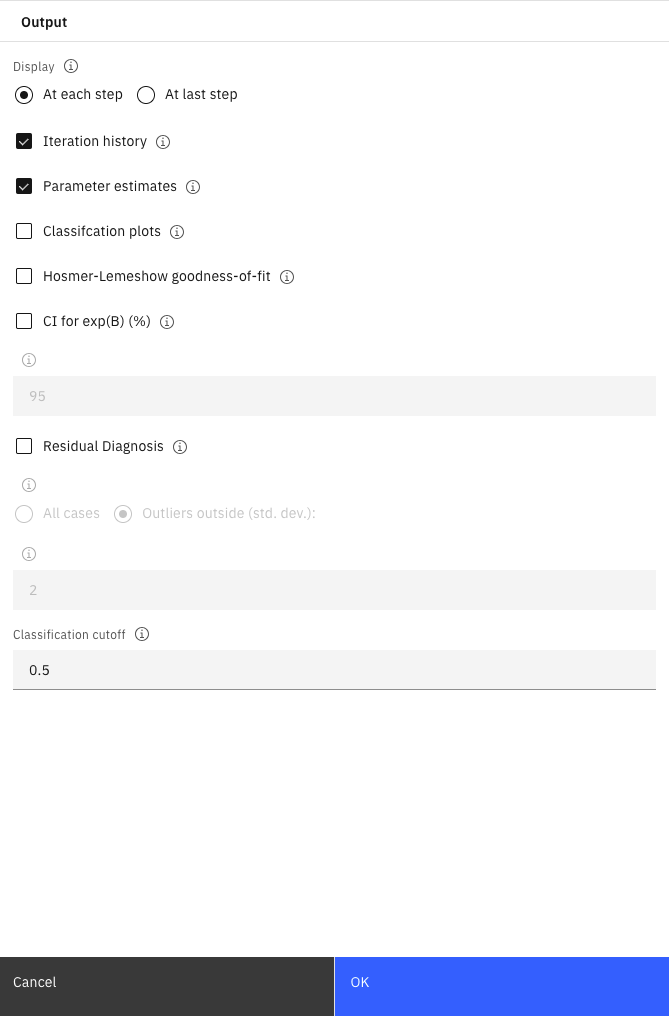
![]() Vérifier votre progression
Vérifier votre progression
L'image suivante illustre le flux. Vous êtes maintenant prêt à générer le modèle.

Tâche 5 : Générer le modèle
Procédez comme suit pour générer une pépite de modèle à partir du nœud Logistic :
- Survolez le nœud churn (Logistic ) et cliquez sur l'icône Run '.
- Dans le volet Sorties et modèles, cliquez sur le modèle de désabonnement pour afficher les résultats.
La page Variables de l'équation indique la cible (taux de désabonnement) et les entrées (champs de prédiction) utilisées par le modèle. Ces champs sont choisis sur la base de la méthode "Pas à pas" et non sur la base de la liste complète soumise à l'examen.
Pour évaluer dans quelle mesure le modèle s'adapte à vos données, plusieurs diagnostics sont disponibles dans les paramètres du nœud expert lorsque vous construisez le flux.
Sachez également que ces résultats sont établis uniquement d'après les données d'apprentissage. Pour évaluer le degré de généralisation du modèle à d'autres données du monde réel, vous utilisez un nœud Partition pour conserver un sous-ensemble d'enregistrements à des fins de test et de validation.
![]() Vérifier votre progression
Vérifier votre progression
L'image suivante montre les résultats du modèle.

Récapitulatif
Cet exemple montre comment utiliser les données d'utilisation pour prédire la perte de clients (churn) en construisant un modèle binomial parce que la cible a deux catégories distinctes.
Etapes suivantes
Vous êtes maintenant prêt à essayer d'autres didacticielsSPSS® Modeler.