About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
資料の 英語版 に戻る
帯域幅利用率の予測
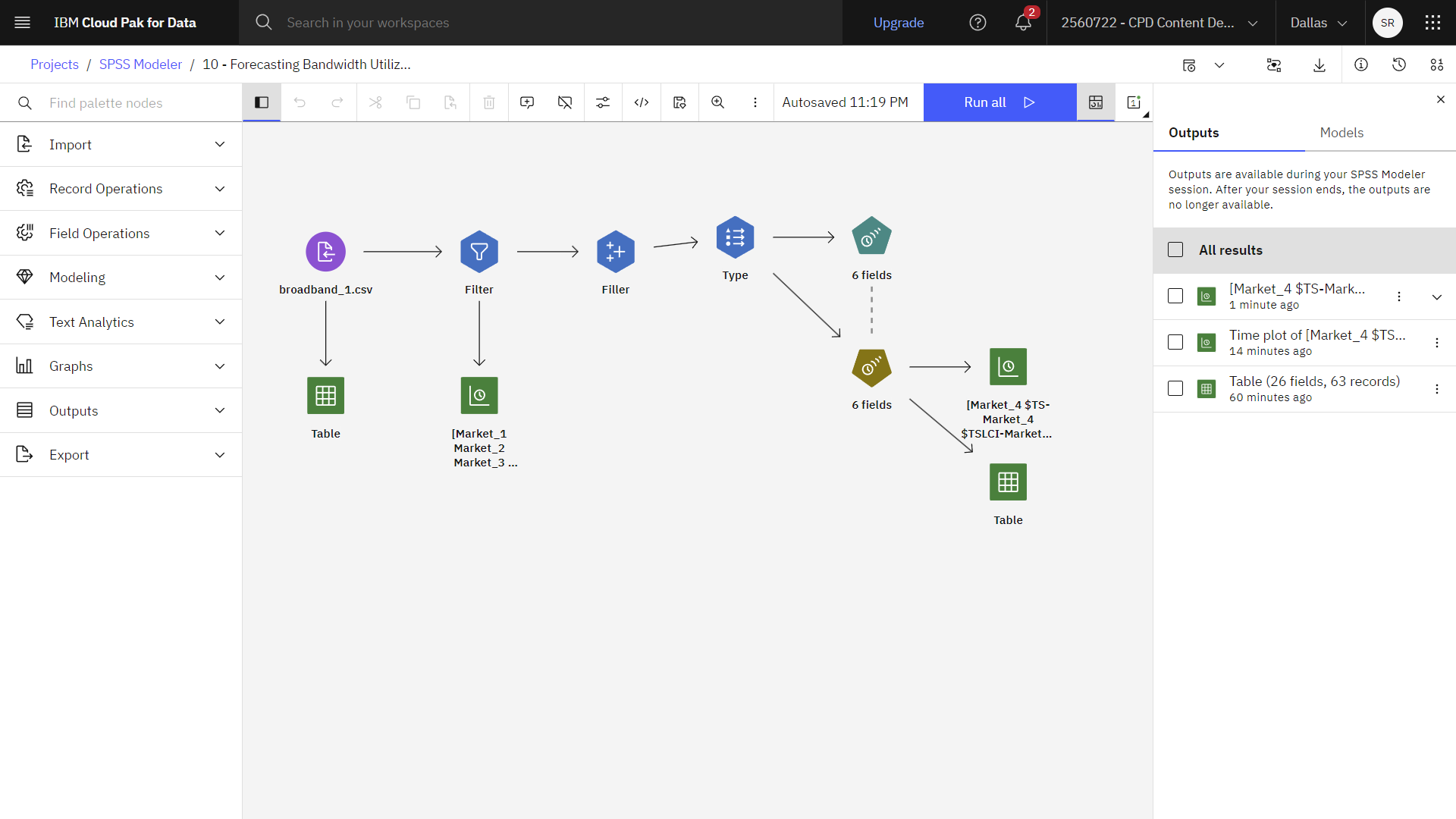
図1: サンプルモデラーの流れ 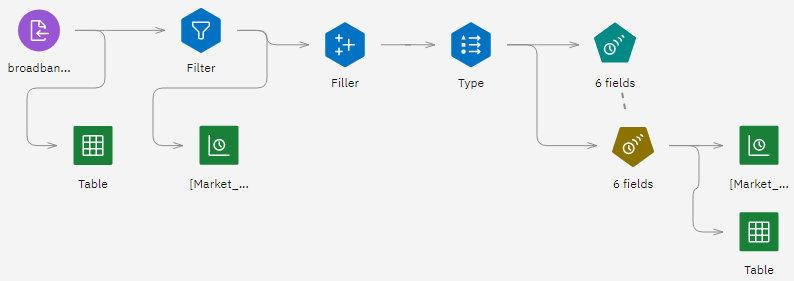


帯域幅利用率の予測
最終更新: 2025年2月11日
このチュートリアルでは、全国的なブロードバンドプロバイダーのアナリストが、帯域幅の利用を予測するために、ユーザー契約を予測する例を示す。 全国の加入者ベースを構成する各地域市場の予測が必要なのだ。
チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、このドキュメントの概念とタスクを視覚的に学習する方法を提供しています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、このドキュメントの概念とタスクを視覚的に学習する方法を提供しています。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
このチュートリアルでは、サンプルプロジェクトの帯域幅使用率の予測フローを使用します。 あなたは時系列モデリングを使って、いくつかの地方市場の向こう3ヶ月の予測を作成する。 使用したデータファイルはbroadband_1.csvである。 次の図は、モデラーのフロー例を示しています。
SPSS® Modelerでは、1回の操作で複数の時系列モデルを作成することができます。 broadband_1.csvデータファイルには、85のローカル市場ごとの月間利用データがある。 この例では、最初の5つの系列のみが使用される。これら5つの系列それぞれについて別々のモデルが作成され、さらに合計も作成される。
このファイルには、それぞれのレコードの月と年を示す日付フィールドも含まれています。 このフィールドはレコードにラベルを付けるために使用される。 日付フィールドは文字列としてSPSS Modelerに読み込まれますが、SPSS Modelerでフィールドを使用するには、フィラーノードを使用してストレージタイプを数値の日付形式に変換します。
TimeSeriesノードでは、各系列が別々の列になり、各区間の行があることが必要である。 SPSS Modelerには、必要に応じてこの形式に合わせてデータを変換するメソッドが用意されています。
次の画像はサンプルデータセットです。図2: サンプルデータセット 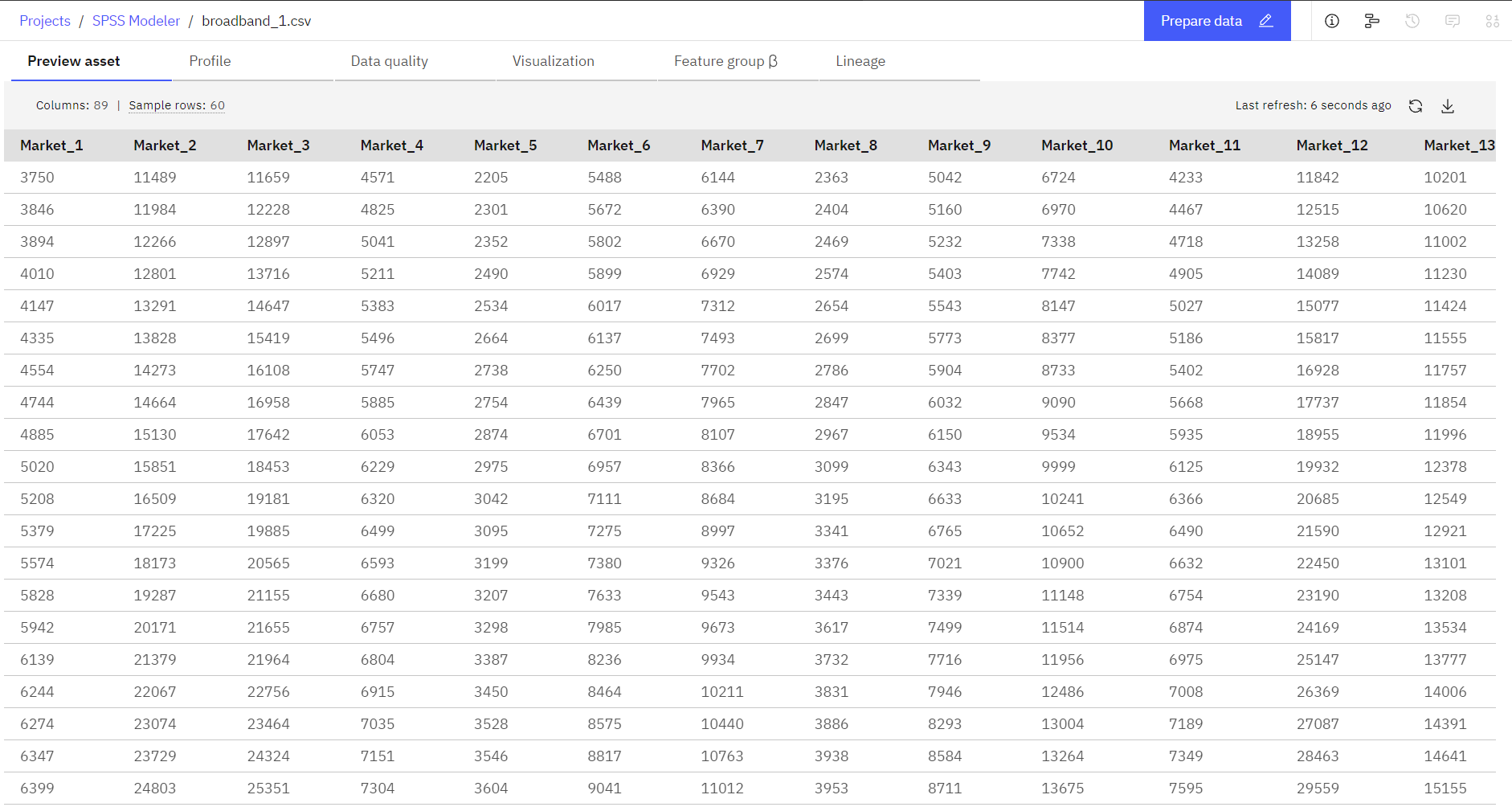
タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプルプロジェクトをまだお持ちでない場合は、 チュートリアルのトピックを参照してサンプルプロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataナビゲーションメニューから
 、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。
、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。 - SPSS ModelerProjectをクリックします。
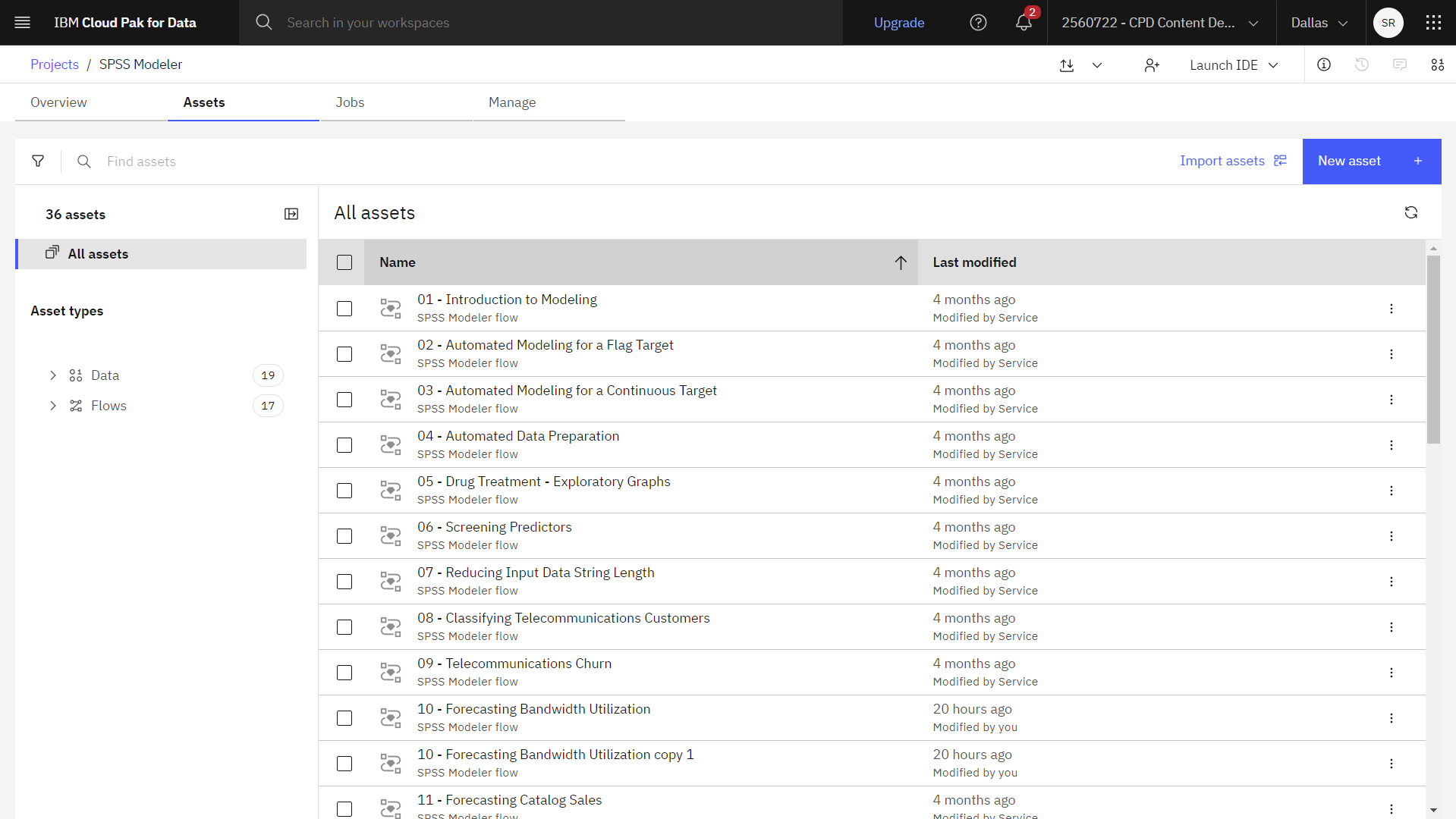
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。
タスク 2: データアセットとフィルタノードの確認
帯域幅利用の予測モデラーフローにはいくつかのノードがある。 以下の手順に従って、データ・アセットおよびフィルタ・ノードを調べます:
- Assetsタブから、予測帯域幅利用モデラーフローを開き、キャンバスがロードされるのを待つ。
- broadband_1.csvノードをダブルクリックする。 このノードは、プロジェクト内のbroadband_1.csvファイルを指すData Assetノードである。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
- フィルター ノードをダブルクリックしてください。 このノードは、'
Market_6Market_85MONTH_YEAR_ - オプション:フィルタリングされたデータセットを表示するには、データのプレビューをクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はFilterノードを示している。 これでデータを視覚化する準備が整いました。
タスク3:データを視覚化する
モデルを構築する前にデータを視覚化するのは常に良いアイデアだ。 そのデータには季節変動が見られるでしょうか。 SPSS Modelerは、各系列に最適な季節性モデルまたは非季節性モデルを自動的に見つけることができますが、データに季節性が存在しない場合は、非季節性モデルに限定して検索することで、より迅速な結果を得られることがよくあります。 各市場のデータを調べなくとも、5つの市場全体の加入者数をプロットすれば、季節性の有無を大まかに把握することができる。 以下の手順でデータを可視化する:
- Market_1 Market_2 Market_3 Market_4 Market_5]ノードをダブルクリックします。 次の図は、このTime plotノードのプロパティを示しています。
図3: 総加入者数のプロット 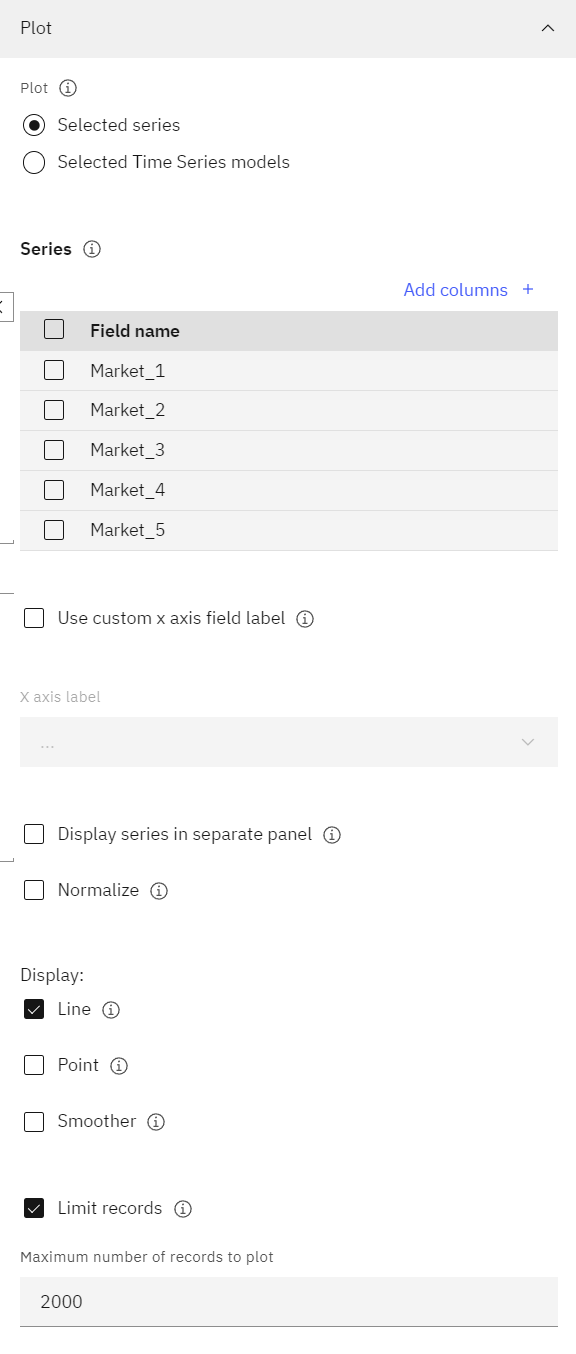
Total- 列の追加をクリックする。
- 合計フィールドを選択する。
Market_- 「OK」をクリックします。
- 別パネルでシリーズを表示」と「正規化」オプションをクリアする。
- 保存 をクリックします。
- タイムプロットノードの上にカーソルを移動し、 実行アイコン
 をクリックします。
をクリックします。 - 出力とモデル]ペインで、[合計]という名前の出力結果をクリックしてグラフを表示します。 同シリーズは滑らかな上昇傾向を示しており、季節変動は見られない。 季節性を持つ個々の系列はあるかもしれないが、どうやらデータ全般において季節性は顕著な特徴ではないようだ。
図4: 総加入数データグラフ 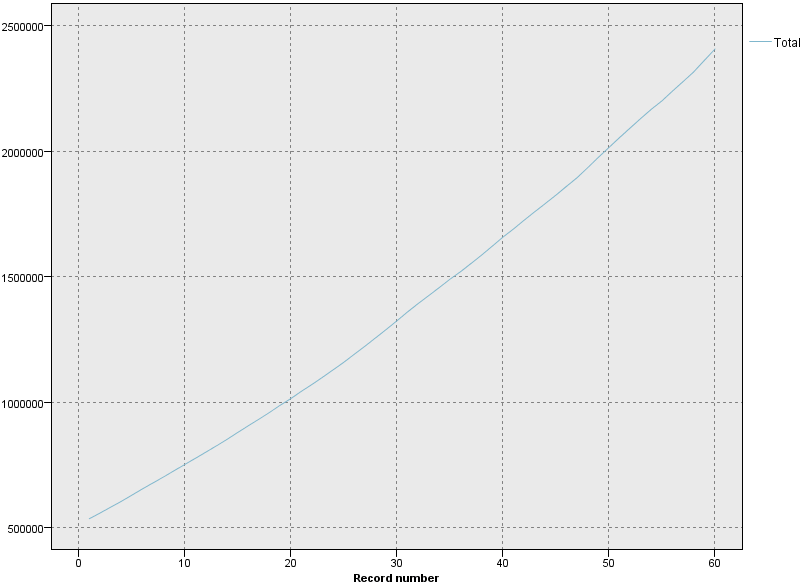
- 全市場のデータをグラフにする。 季節モデルを除外する前に、各シリーズを点検すること。 そして、季節性を示す系列を分離し、別々にモデル化することができる。
- Total]ノードをダブルクリックする。
- 合計」フィールドを選択し、「削除」アイコンをクリックする。
- 列の追加をクリックする。
Market_- 「OK」をクリックします。
- 別パネルでシリーズを表示」と「正規化」オプションをクリアする。
- 保存 をクリックします。
- タイムプロットノードの上にカーソルを移動し、 実行アイコン をクリックします。
- Outputs and models]ペインで、[Market_1 Market_2 Market_3 Market_4 Market_5]という名前の出力結果をクリックすると、グラフが表示されます。 それぞれの市場を調べると、各ケースにおける安定した上昇傾向が見られます。 いくつかの市場は他の市場より若干不安定ではあるが、季節性を示す証拠はない。
図 5. 市場購読データグラフ 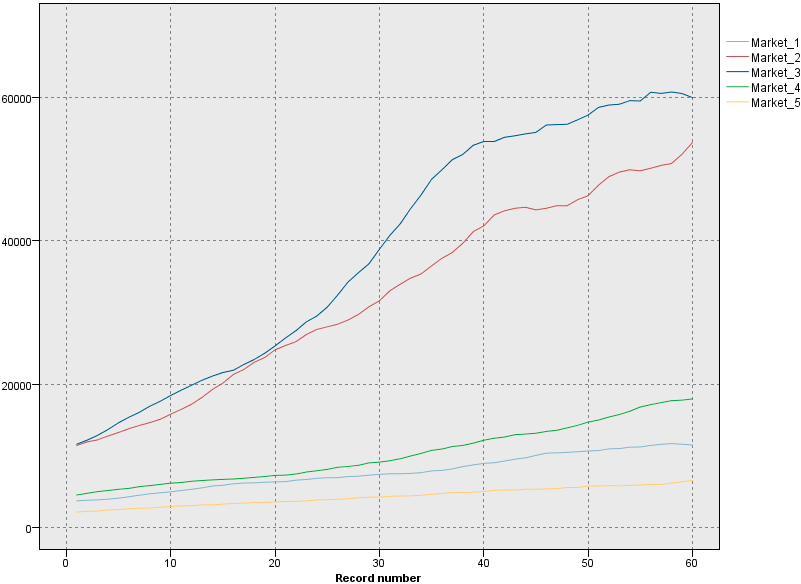
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、このフローを示しています。 これで日付を定義する準備ができた。
タスク4:日程を決める
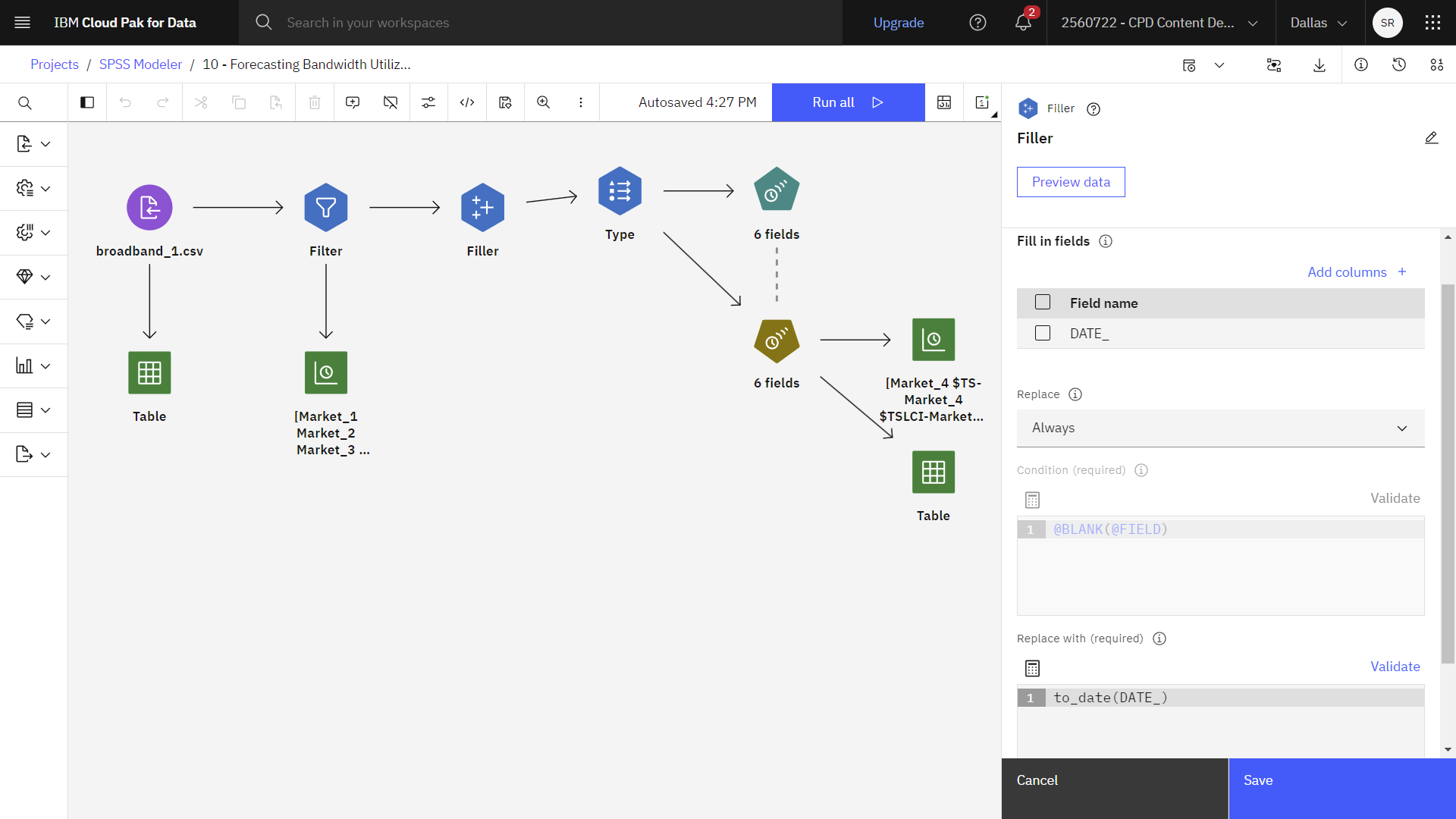
フィラー・ノードは、フィールド値の置換やストレージの変更に使用される。 @BLANK(FIELD)DATE_
- Fillerノードをダブルクリックしてプロパティを表示します。
DATE_- ReplaceオプションがAlways に設定されていることを確認する。 デフォルトの動作は、条件式と置換式を使用して、条件に基づいて値を置換することです。
- Replace withvalueが'
to_date(DATE_)DATE_ - 完成した'
DATE_ - 保存 をクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はFillerノードを示している。 これでターゲットを定義する準備ができた。
タスク5:ターゲットの定義
Typeノードでフィールドのプロパティを指定できます。 以下の手順に従って、Typeノードでターゲットを定義する:
- タイプ ノードをダブルクリックして、そのプロパティーを表示します。
- Read values をクリックすると、データソースから値が読み込まれ、フィールドの測定タイプが設定されます。
役割は、フィールドが機械学習プロセスの入力(予測フィールド)かターゲット(予測フィールド)かをモデリング・ノードに指示する。 トレーニング、テスト、検証のためにレコードを別々のサンプルに分割するために使用されるフィールドを示すPartitionとともに、Bothと Noneも利用可能なロールである。 値の分割は、フィールドの取り得る値ごとに別々のモデルを構築することを指定する。 DATE_- 他のすべてのフィールド('
Market_nTotal - 保存 をクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はTypeノードを示している。 これで時間間隔を設定する準備ができた。
タスク6:時間間隔の設定
時系列ノードでは、適切な時間間隔を持つ日付/時刻フィールドを使用するオブザベーションを定義できます。 以下の手順に従って、Times Seriesノードで時間間隔を設定してください:
- 時系列(6フィールド)ノードをダブルクリックして、そのプロパティを表示する。
- Observations and time intervalセクションを展開する。 使用可能なオプションは次のとおりです。
- 日付/時刻フィールドによって指定されるオブザベーション:日付、時刻、またはタイムスタンプ・フィールドによってオブザベーションを定義するように指定できます。 観測を定義するフィールドに加えて、観測を記述する適切な時間区分を選択します。 指定した時間区分によっては、観測間の区分 (増分) や週当たりの日数などの他の設定も指定できます。
- 期間または周期的期間として定義される観測:観測値は、任意の数の周期レベルまで、周期または周期の繰り返し周期を表す1つ以上の整数フィールドによって定義される。 この構造を使えば、標準的な時間間隔のいずれにも当てはまらない一連の観測を記述することができる。 例えば、月数が 10 カ月のみの会計年度を、年を表す循環フィールドと月を表す期間フィールドで記述できます (1 つの循環の長さは 10)。
- 時間/日付フィールドで「
DATE_ - 時間間隔フィールドで「
Months
- 時間/日付フィールドで「
- モデルオプションのセクションを展開します。
- Extend records into the futureフィールドを選択します。 このフィールドは、推定期間の終わりを越えて予測する区間数を設定する。 この場合の時間間隔は分析の時間間隔です。 予測が要求されると、自動回帰モデルはターゲットでもない入力系列に対して自動的に構築される。 次にこれらのモデルは、予測期間のこれらの入力系列の値を生成するために使用されます。
- 時間間隔の数には「
3
![]() 進捗状況を確認する
進捗状況を確認する
次の図はTypeノードを示している。 これでモデルを作る準備ができた。
タスク7:モデルの構築
時系列ノードでは、時系列の指数平滑化、一変量自己回帰統合移動平均(ARIMA)、または多変量ARIMA(または伝達関数)モデルを推定して構築し、時系列データに基づいて予測を作成することを選択できます。
タスク7a:モデルオプションの指定
以下の手順に従って、Times Seriesノードでモデルオプションを指定してください:
- 時系列(6 フィールド)ノードのプロパティを表示して、ターゲットと 候補入力を指定します。
- Targetsテーブルに5つの市場フィールドと「
Total - 候補者入力テーブルに5つの市場フィールドがすべて含まれていることを確認する。
- Targetsテーブルに5つの市場フィールドと「
- Build options- generalセクションを展開する。 使用可能なオプションは次のとおりです。
- 指数平滑化は、前の時系列の観測結果に重み付けされた値を使用して将来の値を予測する方法です。 指数平滑法自体は、データの理論的解釈に基づいてはいません。 一度に 1 つのポイントを予測し、新しいデータが投入されるごとに予測を調整します。 この方法は、トレンド、季節性、またはその両方を示す時系列を予測する場合に役立ちます。 トレンドと季節性の処理方法が異なる、各種の指数平滑化モデルから選択できます。
- ARIMA モデルには、トレンドおよび季節性のコンポーネントのモデル作成に指数平滑法モデルよりも洗練された方法が用意されています。特に、モデル内に独立 (予測フィールド) 変数を含むことが可能になりました。 このアプローチでは、自己回帰次数と移動平均次数を差分の程度とともに明示的に指定する。 予測変数を含んでその変数のいくつかまたはすべてに伝達関数を定義し、外れ値または明示した外れ値セットの自動検出を指定できます。
- Expert Modelerは、1つまたは複数のターゲット変数に最も適合するARIMAまたは指数平滑化モデルを自動的に特定し、推定しようとするもので、試行錯誤によって適切なモデルを特定する必要がなくなります。 確信が持てない場合は、エキスパート モデラー オプションを使用してください。
- エキスパートモデラー法が選択されていることを確認する。 この方法により、エキスパートモデラーは各時系列に使用する最も適切なモデルを決定することができる。
- Model TypeフィールドでAll modelsが選択されていることを確認する。 このオプションは、ARIMAと指数平滑化モデルの両方を考慮する。
- Expert Model considers seasonal modesフィールドが選択されていることを確認する。 このオプションがオンの場合、エキスパート・モデラーは季節性および非季節性の両方のモデルを検討します。
次の画像は「ビルド・オプション - 一般設定を示している。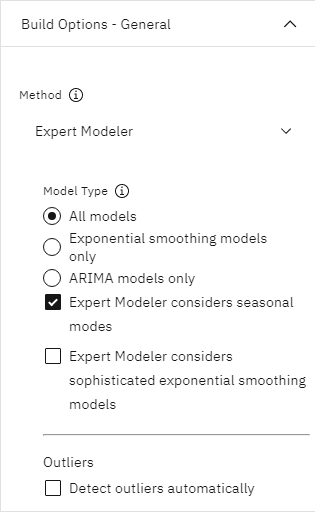
- 保存 をクリックします。
- 時系列 (6フィールド)ノードにマウスを移動し、 実行アイコンをクリックします。 。
タスク7b:モデルの出力を見る
モデル出力を表形式で表示するには、以下の手順に従ってください:
- モデルナゲットに接続されているテーブルノードの上にカーソルを移動し、 実行アイコン をクリックします。
- 出力とモデル]ペインで、[テーブル]という名前の出力結果をクリックして、テーブル出力を表示します。
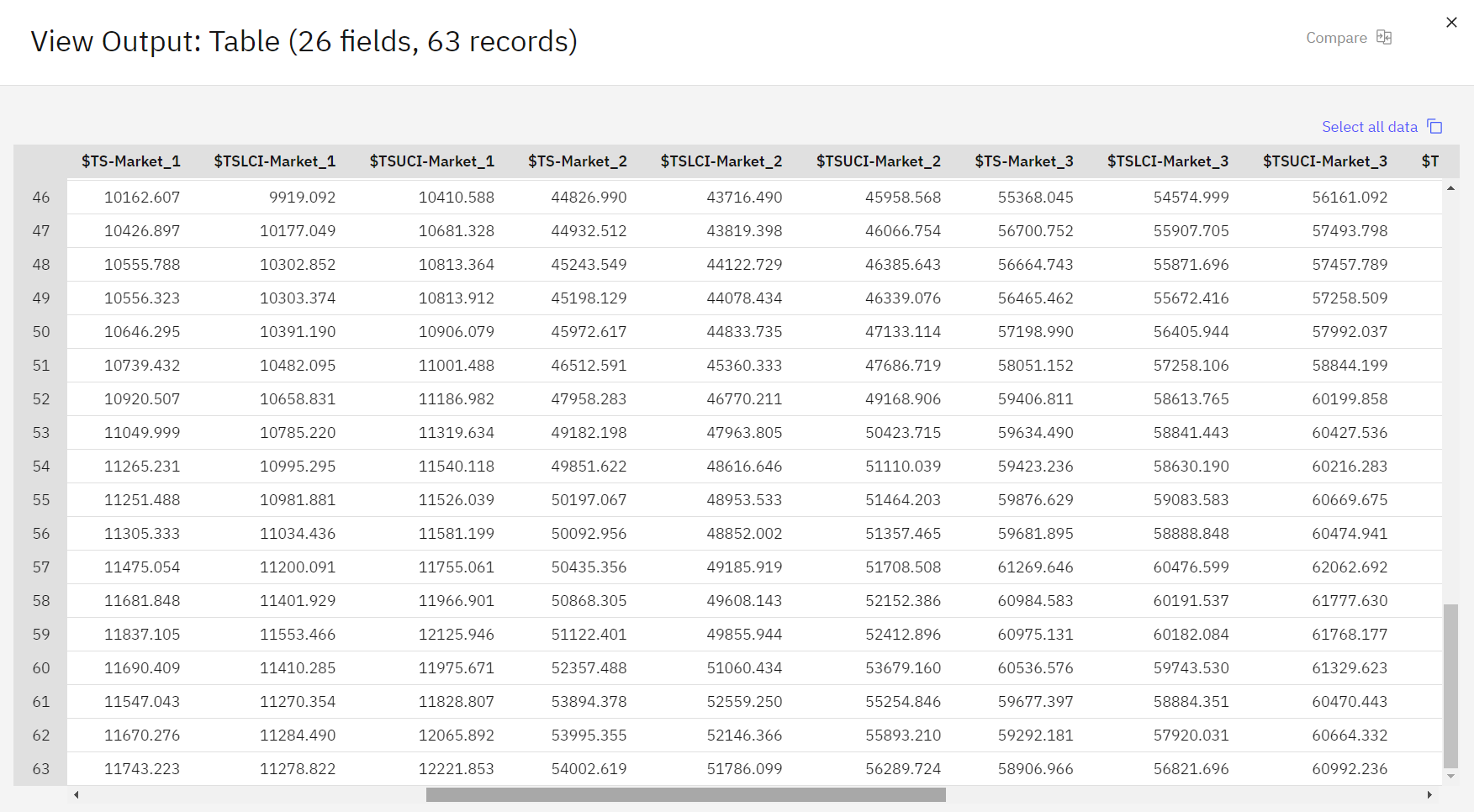
元のデータの最後に3つの新しい行が追加されていることに注目してほしい。 これらの行は予測期間のもので、この場合は2004年1月から3月までのものである。
図 6. 予想行を示す表出力 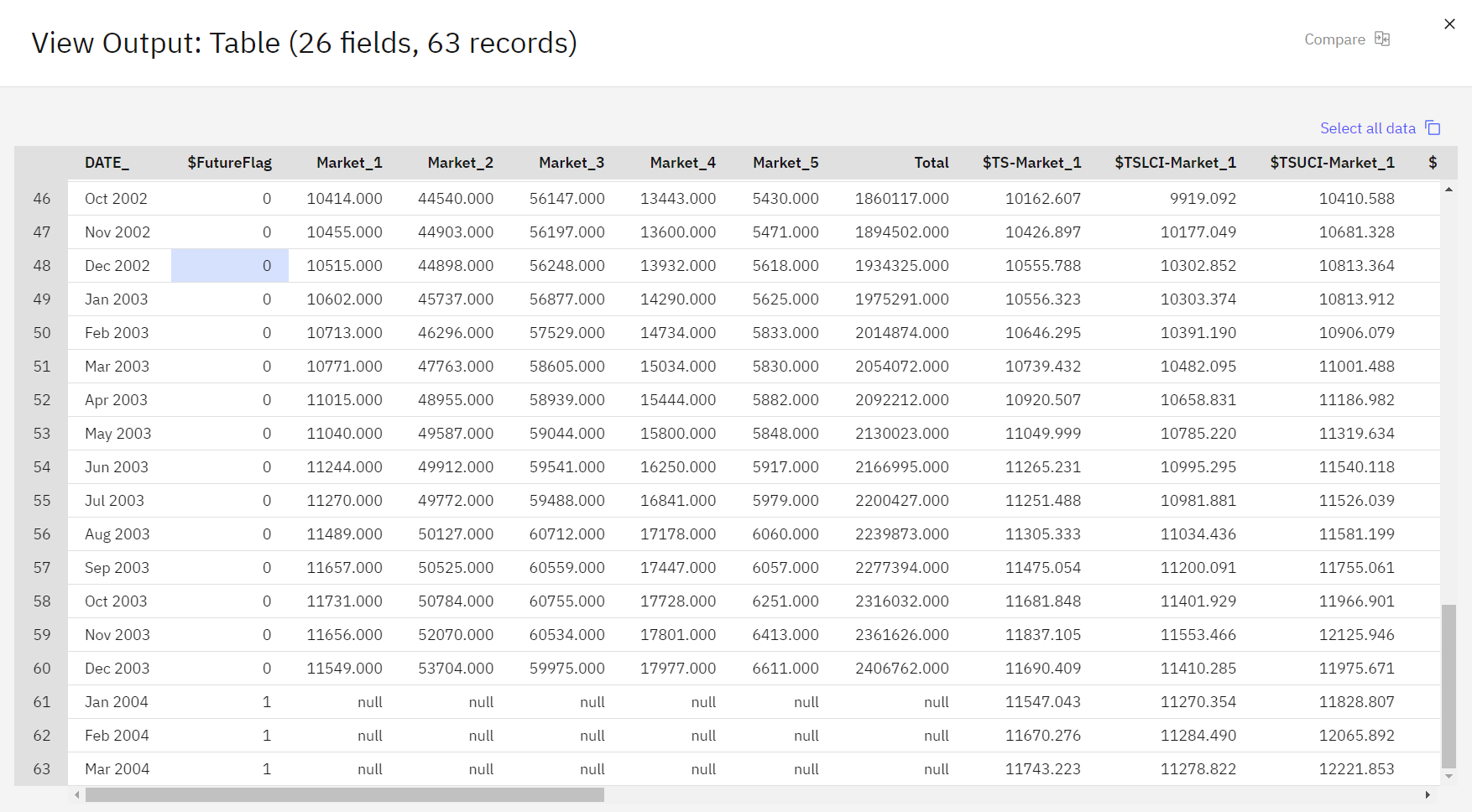
いくつかの新しい列が見える。 時系列ノードに'
$TS-表 1. 時系列 mmodel で生成される列 列 説明 TS-コルネーム 元のデータの各列に対して生成されたモデル・データ。 TSLCIコルネーム 生成されたモデル・データの各列の信頼区間の下限値。 TSUCIコルネーム 生成されたモデル・データの各列の信頼区間の上限値。 $TS-Total この行の $TS-colname 値の合計。 $TSLCI-Total この行の $TSLCI-colname 値の合計。 $TSUCI-Total この行の $TSUCI-colname 値の合計。 予測操作で最も重要な列は、
$TS-Market_n$TSLCI-Market_n$TSUCI-Market_n
![]() 進捗状況を確認する
進捗状況を確認する
次の画像は出力表である。 これでモデルを調べる準備ができた。
タスク8:モデルの検証
これで、モデル情報と予測結果を調べる準備ができた。
タスク8a:モデル情報を見る
モデル情報を表示するには、以下の手順に従ってください:
- 時系列モデルのナゲットにカーソルを合わせ、 オーバーフローメニュー
 をクリックし、 View Model(モデルの表示 )を選択します。
をクリックし、 View Model(モデルの表示 )を選択します。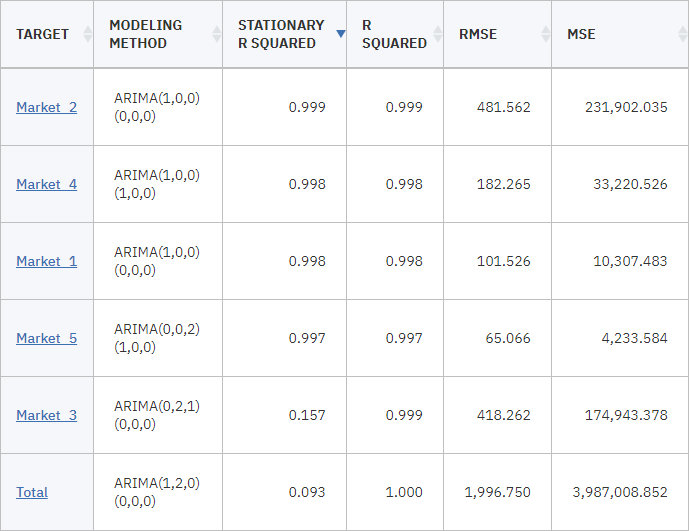
- TARGET]列で[Market_2をクリックする。
- モデル情報をクリックします。 「予測値の数」行に、ターゲットごとに予測値として使用されたフィールドの数が表示されます。
モデル情報表のその他の行には、各モデルのさまざまな適合度指標が表示されます。 定常 R2 乗は、ベースライン・モデルよりモデルがどのように優れているかを測定します。 最終モデルが ARIMA(p,d,q)(P,D,Q) の場合、ベースライン・モデルは ARIMA(0,d,0)(0,D,0) です。 最終モデルが指数平滑法モデルの場合、Brown および Holt モデルでは、d は 2 でほかのモデルでは 1 で、季節の長さが 1 より大きい場合は D が 1で, それ以外の場合は、D は 0 です。. 負の定常R二乗は、検討中のモデルがベースラインモデルより悪いことを意味する。 定常R2乗がゼロであれば、そのモデルはベースラインモデルと同じかそれ以下であることを意味し、正の定常R2乗であれば、そのモデルはベースラインモデルよりも優れていることを意味する。
統計やdf 線、またパラメーター推定値にある重要度は、Ljung-Box 分析、モデルの残差エラーのランダム性に関連します。 エラーがランダムであるほど、そのモデルは良好です。 統計量はLjung-Box統計量そのものであり、df(自由度)は特定のターゲットを推定する際に変化させることが可能なモデルパラメータの数を示す。
重要度 は、Ljung-Box 統計量の有意確率値を示し、モデルが正しく指定されているかどうかを示す別の指標を提供します。 0.05 未満の有意確率値は、残差エラーがランダムではないことを示し、モデルでは考慮されていない構造が観測対象の系列にあるということを意味しています。
定常R二乗と 有意値の両方を考慮すると、エキスパートモデラーが「
Market_3Market_4Market_1Market_2Market_5ディスプレイには、いくつかの適合度指標が表示される。 R-Squared 値を使用すると、モデルによって説明される時系列の合計バリエーションを推定します。 この統計量の最大値は1.0なので、この点ではあなたのモデルは問題ない。
RMSEとは二乗平均平方根誤差のことで、ある系列の実際の値が、モデルによって予測された値からどれだけ異なるかを示す尺度であり、系列そのものに使用されるのと同じ単位で表される。 この誤差は誤差の測定であるため、この値はできるだけ小さくしたい。 一見したところ、「
Market_2Market_3これらの追加の適合度指標には、平均絶対パーセント誤差 (MAPE) とその最大値 (MAXAPE) が含まれます。 絶対パーセント誤差は、モデル予測レベルから対象系列が変動する量に関する尺度で、パーセント値で表されます。 すべてのモデルで平均値および最大値を検証することで、予測の不確定性についての目安を得ることができます。
MAPE値を見ると、どのモデルも平均不確実性は1%前後と低い。 MAXAPE 値は、最大絶対パーセント誤差を表示し、予測の最悪のシナリオを想定するために役立ちます。 それによると、ほとんどのモデルで誤差の割合が最も大きいのは、おおよそ「
Market_4MAE (平均値絶対エラー) の値は、予測エラーの絶対値の平均値を示します。 RMSE値と同様に、この値も系列自体に使用されているのと同じ単位で表される。 MAXAEは同じ単位で最大の予測誤差を示し、予測の最悪のシナリオを示す。
これらの絶対値は興味深いものですが、対象系列がさまざまなサイズの市場の加入者数を表しているため、このケースで役立つパーセント・エラー (MAPE および MAXAPE) の値が役立ちます。
MAPE および MAXAPE の値は、モデルに対して許容できる不確実性因の量を表していますか。 非常に低い。 このような状況では、許容できるリスクは問題によって変わってくるため、ビジネスセンスが問われる。 適合度統計量が許容範囲内に収まっていると仮定し、残差誤差を見るために前進します。
モデル残差に対する自己相関関数 (ACF) および偏自己相関関数 (PACF) の値を検証すると、適合度統計を単に表示するだけでなく、モデルに対するより定量的な洞察が得られます。
よく仕様化された時系列モデルは、季節性、トレンド、周期性、その他の重要な要因を含むすべての非ランダム変動を捉える。 これに該当する場合、どの誤差についても、経時的にそれ自体と相関 (自己相関) させるべきではありません。 自己相関関数のいずれかに有意な構造がある場合、基礎となるモデルが不完全であることを示唆している可能性がある。
- Market_2のウィンドウを閉じる。
- モデル情報をクリックします。 「予測値の数」行に、ターゲットごとに予測値として使用されたフィールドの数が表示されます。
- Market_4モデルをクリックする。
- モデルの残差誤差の自己相関関数(ACF)と偏自己相関関数(PACF)の値を表示するには、相関図をクリックします。
図 7. 相関曲線 
これらのプロットでは、エラー変数のラグ(「BUILD OPTIONS」-「OUTPUT」)のオリジナル値をデフォルト値の24期間まで表示し、オリジナル値と比較して経時的な相関を確認する。 理想的には、ACFとPACFのすべてのラグを表す棒グラフが、斜線領域内にあることである。 しかし実際には、斜線部分の外側に広がるラグがあるかもしれない。 このような状況は、例えば、計算時間を節約するために、より大きなラグをモデルに含めようとした場合に起こりうる。 一部のラグは、有意ではなく、モデルから削除されます。 このモデルを今後さらに改善し、これらのラグが冗長であるかどうかを問題にしない場合、これらのプロットは、どのラグが潜在的な予測値であるかに関するヒントとなります。
このような状況が発生した場合は、下部(PACF)プロットをチェックし、そこで構造が確認されているかどうかを確認する必要がある。 PACF プロットは、時間ポイント間で系列値を制御した後で相関を確認します。
Market_4 - Market_4のウィンドウを閉じる。
- モデルの残差誤差の自己相関関数(ACF)と偏自己相関関数(PACF)の値を表示するには、相関図をクリックします。
- それぞれの他の市場および合計について、相関曲線 を開きます。
他の市場の値はすべて、陰影のある領域の外側にいくつかの値を示しており、先ほどSignificanceの値からあなたが疑ったことを裏付けている。 しかし、この例の残りの部分では、「
Market_4 - モデルウィンドウを閉じて、フローキャンバスに戻ります。
課題8b:予測を視覚化する
以下の手順に従って、予測を視覚化してください:
実績と予測の比較
- 時系列モデル・ナゲットに接続されているTime Plotノードをダブルクリックします。
- 別のパネルにシリーズを表示するオプションをクリアする。
- シリーズ」リストで、「
Market_4$TS-Market_4 - 保存 をクリックします。
- 時間プロット [ Market_4 $TS-Market_4 $TSLCI-Market_4 $TSUCI-Market_4 ] ノードの上にカーソルを移動し、 実行アイコン をクリックします。
- 出力とモデル]ペインで、[Market_4 $TS-Market_4 $TSLCI-Market_4 $TSUCI-Market_4]という名前の出力結果をクリックしてグラフを表示します。 予測 (
$TS-Market_4図 8. Market_4 の実際のデータと予測データの時系列 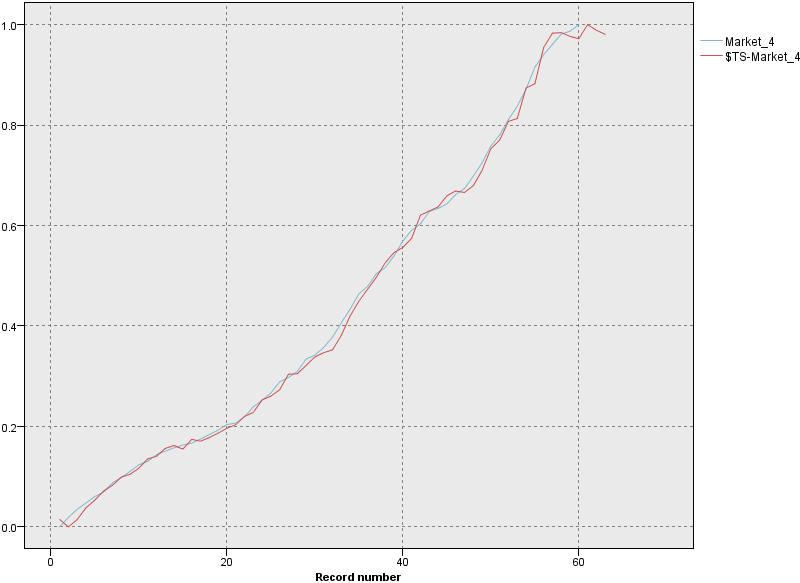
信頼区間をプロットする
- Time Plot [Market_4 $TS-Market_4 $TSLCI-Market_4 $TSUCI-Market_4]ノードをダブルクリック。 この特定の市場に対して信頼できるモデルが得られましたが、その予測はどのような誤差の許容範囲を持つでしょうか。 信頼区間を調べることで、誤差の範囲を知ることができる。
- シリーズ」セクションで、「
Market_4$TS-Market_4 - 列の追加をクリックする。
$TSLCI-Market_4$TSUCI-Market_4- 「OK」をクリックします。
- 保存 をクリックします。
- 時間プロット [ Market_4 $TS-Market_4 $TSLCI-Market_4 $TSUCI-Market_4 ] ノードの上にカーソルを移動し、 実行アイコン をクリックします。
- 出力とモデル]ペインで、[Market_4 $TS-Market_4 $TSLCI-Market_4 $TSUCI-Market_4]という名前の出力結果をクリックしてグラフを表示します。 さて、前と同じグラフができましたが、信頼区間の上限(
$TSUCI$TSLCI図 9. 信頼区分が追加された時系列 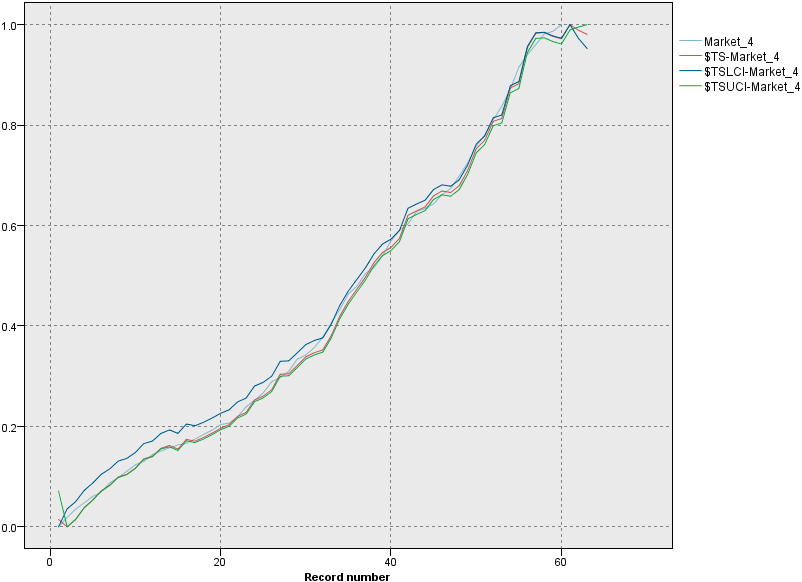
- グラフウィンドウを閉じる。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、完成したフローを示している。
サマリー
この例では、エキスパートモデラーを使用して複数の時系列の予測を作成する方法を示しました。 実際のシナリオでは、非標準の時系列データを時系列ノードへの入力に適した形式に変換することがある。
次のステップ
これで、他の SPSS Modeler チュートリアルを試す準備ができました。
トピックは役に立ちましたか?
0/1000