本教程使用自动分类器节点自动创建和比较多个不同的模型,用于标记目标(如特定客户是否可能拖欠贷款或对特定报价作出反应)或名义(设定)目标。
在本例中,您搜索的是标志(是或否)结果。 在相对简单的流程中,该节点会生成一组候选模型并对这些模型进行排名,选择性能最佳的候选模型,然后将它们组合为单个聚集(整体)模型。 此方法将自动化操作的方便性与组合多个模型的优势融为一体,从而产生任何单一模型所不能带来的更为准确的预测。
此示例基于一个虚构的公司,该公司希望通过将相应的报价与每个客户匹配来实现更有利可图的结果。 此方法突出了自动操作的优势。 有关使用连续(数值范围)目标的类似示例,请参阅其他SPSS® Modeler教程。
预览教程
 观看本视频,预览本教程的步骤。 视频中显示的用户界面可能略有不同。 该视频旨在作为书面教程的补充。 本视频以可视化的方式介绍了本文件中的概念和任务。
观看本视频,预览本教程的步骤。 视频中显示的用户界面可能略有不同。 该视频旨在作为书面教程的补充。 本视频以可视化的方式介绍了本文件中的概念和任务。
试用教程
在本教程中,您将完成这些任务:
建模流程和数据集样本
本教程使用示例项目中的 "旗帜目标的自动建模流程。 使用的数据文件是pm_customer_train1.csv。 下图显示了建模流程示例。
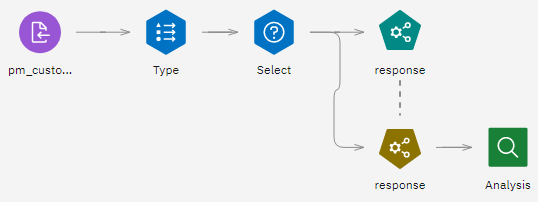
此示例使用数据文件 pm_customer_train1.csv,该文件包含用于跟踪过去营销活动(如 campaign 字段值所指示)中向特定客户提供的报价的历史数据。
任务 1:打开示例项目
任务 2:检查数据资产节点
旗帜目标的自动建模包括几个节点。 按照以下步骤检查数据资产节点。
- 从 "资产"选项卡,打开 "旗标目标自动建模"建模流程,等待画布加载。
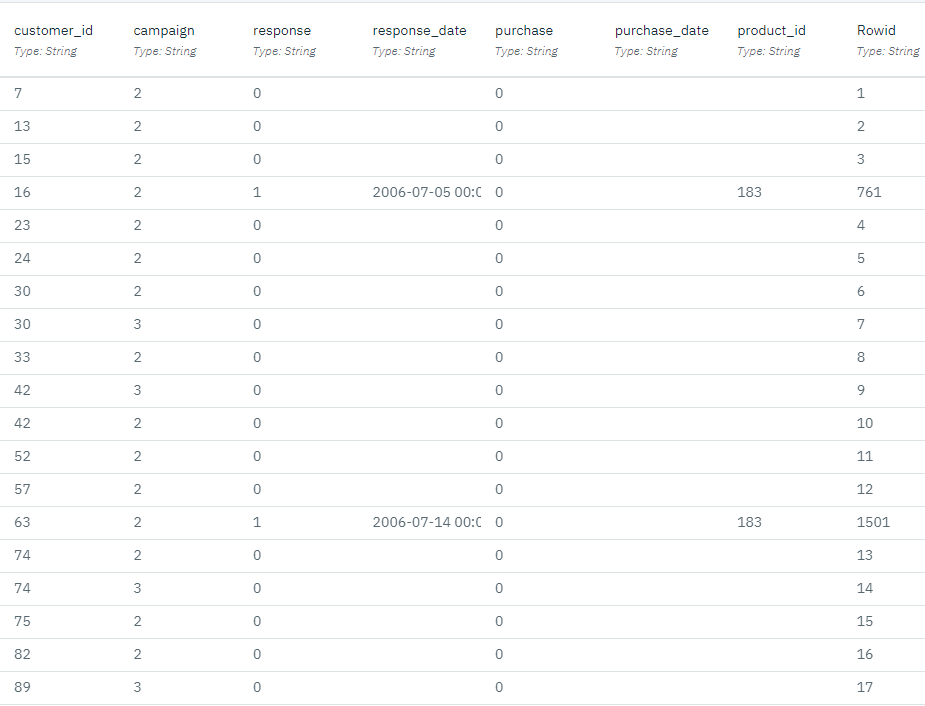
- 双击pm_customer_train1.csv节点。 该节点是一个数据资产节点,指向项目中的pm_customer_train1.csv文件。
- 查看文件格式属性。
- 可选:单击 "预览数据"查看完整数据集。
Premium account 活动中的记录数最大。
campaign字段的值在数据中编码为整数(例如 "2 = Premium account)。 稍后,您可以为这些值定义标签,以提供更有意义的输出。文件中还有一个 "
response字段,表示是否接受要约(0 = no和 "1 = yes)。response字段是您要预测的目标字段或值。 此外,还包括包含每个客户的人口和财务信息的各种字段。 这些字段用于建立或训练一个模型,根据收入、年龄或每月交易次数等特征预测个人或群体的回复率。
![]() 查看进度
查看进度
下图显示了数据资产节点。 现在您可以编辑 "类型"节点了。
任务 3:编辑类型节点
现在您已经探索了数据资产,请按照以下步骤查看和编辑类型节点的属性:
- 双击类型节点。 该节点指定字段属性,如测量级别(字段包含的数据类型),以及每个字段在建模中作为目标或输入的作用。 测量级别是指示字段中数据的类型的类别。 源数据文件使用三种不同的测量级别:
- 连续字段(如 "
Age字段)包含连续的数值。 - 一个标称字段(如 "
Education字段)有两个或多个不同的值;在本例中就是这样。College或 "High school. - 序数字段(如 "
Income level字段)描述的是具有多个不同值的数据,这些值有固有的顺序;在本例中为 "Low、"Medium"和 "High"。
- 连续字段(如 "
- 验证# 响应字段是否为目标字段(角色 =目标),以及该字段的测量值是否为旗形。
图 3。 设置测量级别和角色 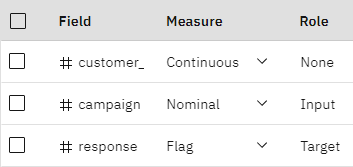
- 确认以下字段的角色设置为 "无"。 在建立模型时,这些字段将被忽略。
- customer_id
- 竞销活动
- 响应日期
- 采购
- 购买日期
- product_id
- RowID
- X_random
- 单击 "类型"节点中的 "读取值",确保值被实例化。
如前所述,源数据包括四个不同营销活动的信息,每个活动都针对不同类型的客户账户。 这些活动在数据中被编码为整数,因此为了帮助记忆每个整数代表哪种账户类型,请为每个整数定义标签。
图 4: 选择为字段指定值 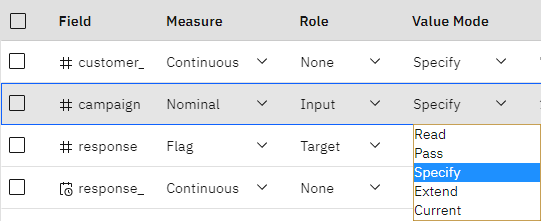
- 在# 活动 行和值模式列中,从列表中选择指定。
- 点击 #活动字段行中的编辑图标
 。
。- 如图所示,验证四个值中每个值的标签。
图 5. 为字段值定义标签 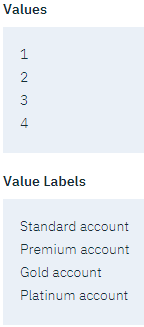
- 单击确定。 现在,输出窗口中显示的是标签而不是整数。
- 如图所示,验证四个值中每个值的标签。
- 单击保存。
- 可选:单击预览数据,查看应用了类型属性的数据集。
![]() 查看进度
查看进度
下图显示了类型节点。 现在您可以选择一个活动进行分析。

任务 4:选择一项活动进行分析
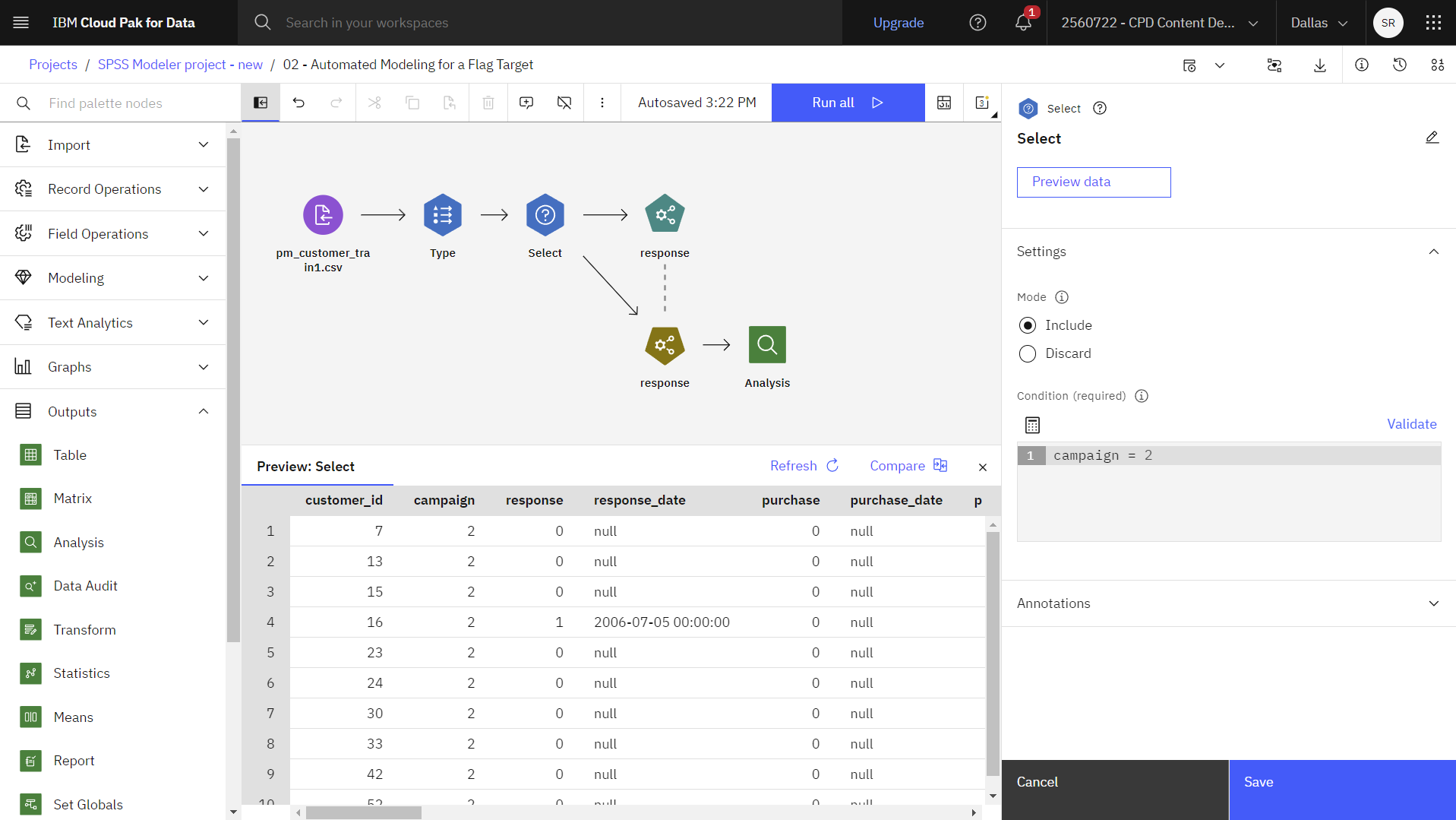
虽然数据包括四个不同活动的信息,但您每次只分析一个活动。 按照以下步骤查看 "选择"节点,只分析高级账户营销活动:
- 双击选择节点,查看其属性。
- 注意条件。 由于属于高级账户营销活动(数据中编码为 "
campaign=2)的记录最多,因此选择节点只选择这些记录。 - 可选:单击预览数据,查看应用了选择属性的数据集。
![]() 查看进度
查看进度
下图显示了选择节点。 现在您可以开始制作模型了。
任务 5:建立模型
现在您已选择了一个要分析的单一营销活动,请按照以下步骤构建使用自动分类器节点的模型:
- 双击响应(自动分类器)节点,查看其属性。
- 展开 "构建选项"部分。
- 在 "按模型排序"字段中,选择 "总体准确度"作为模型排序的指标。
- 将要使用的模型数量设置为 "
3。 该选项意味着在运行节点时会建立三个最佳模型。图 6. “自动分类器”节点,构建选项 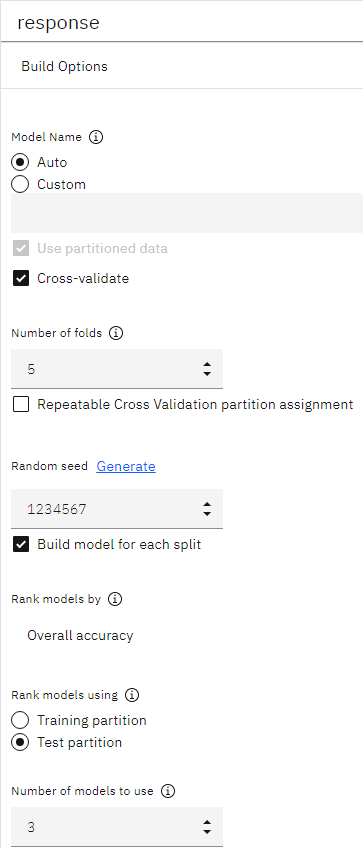
- 展开专家部分,查看不同的建模算法。
- 清除判别式、SVM 和随机森林模型类型。 这些模型在这些数据上的训练时间较长,因此消除这些模型可以加快示例的速度。
由于您将 "构建选项"下的 "要使用的模型数"属性设置为 "
3,因此节点会计算其余算法的精确度,并生成包含三种最精确算法的单一模型块。图 7. “自动分类器”节点,“专家”选项 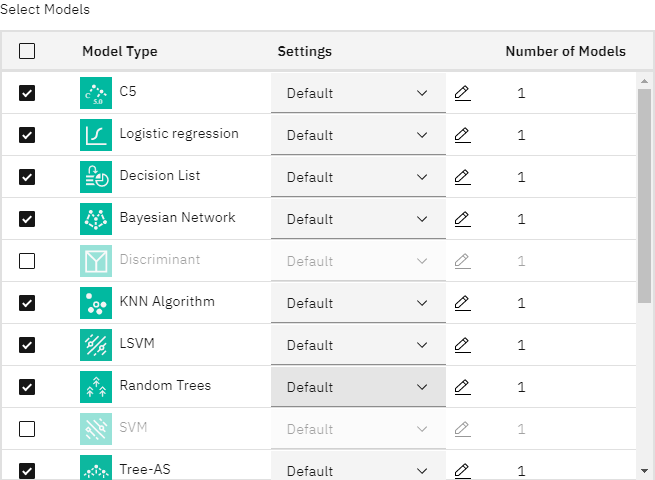
- 在"集合"选项下,为 "设置目标"和 "标记目标 "的集合方法选择 "置信度加权投票"。 此设置决定了如何为每条记录生成一个综合分数。
通过简单投票,如果三分之二的模型预测为 yes,则 yes 以 2 比 1 的投票结果获胜。 在置信度加权投票的情况下,投票根据每个预测的置信度值加权。 因此,如果一个预测 否 的模型的置信度比两个预测 是 的模型合在一起的置信度还高,则 否 取胜。
图 8. “自动分类器”节点,“整体”选项 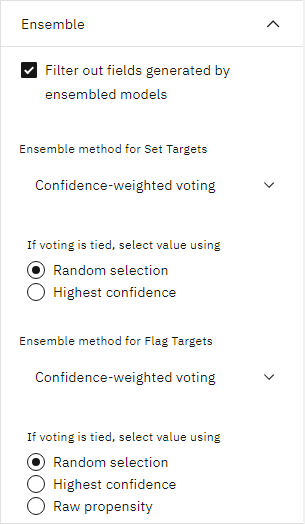
- 单击保存。
- 将鼠标悬停在 “响应(自动分类器)”节点上 ,点击 “运行”图标
 。
。 - 在 "输出和模型"窗格中,单击名称为response的模型以查看结果。 您可以看到运行过程中创建的每个模型的详细信息。 (在实际情况中,可能会在一个大型数据集上创建数百个模型,运行流程可能需要很多小时)
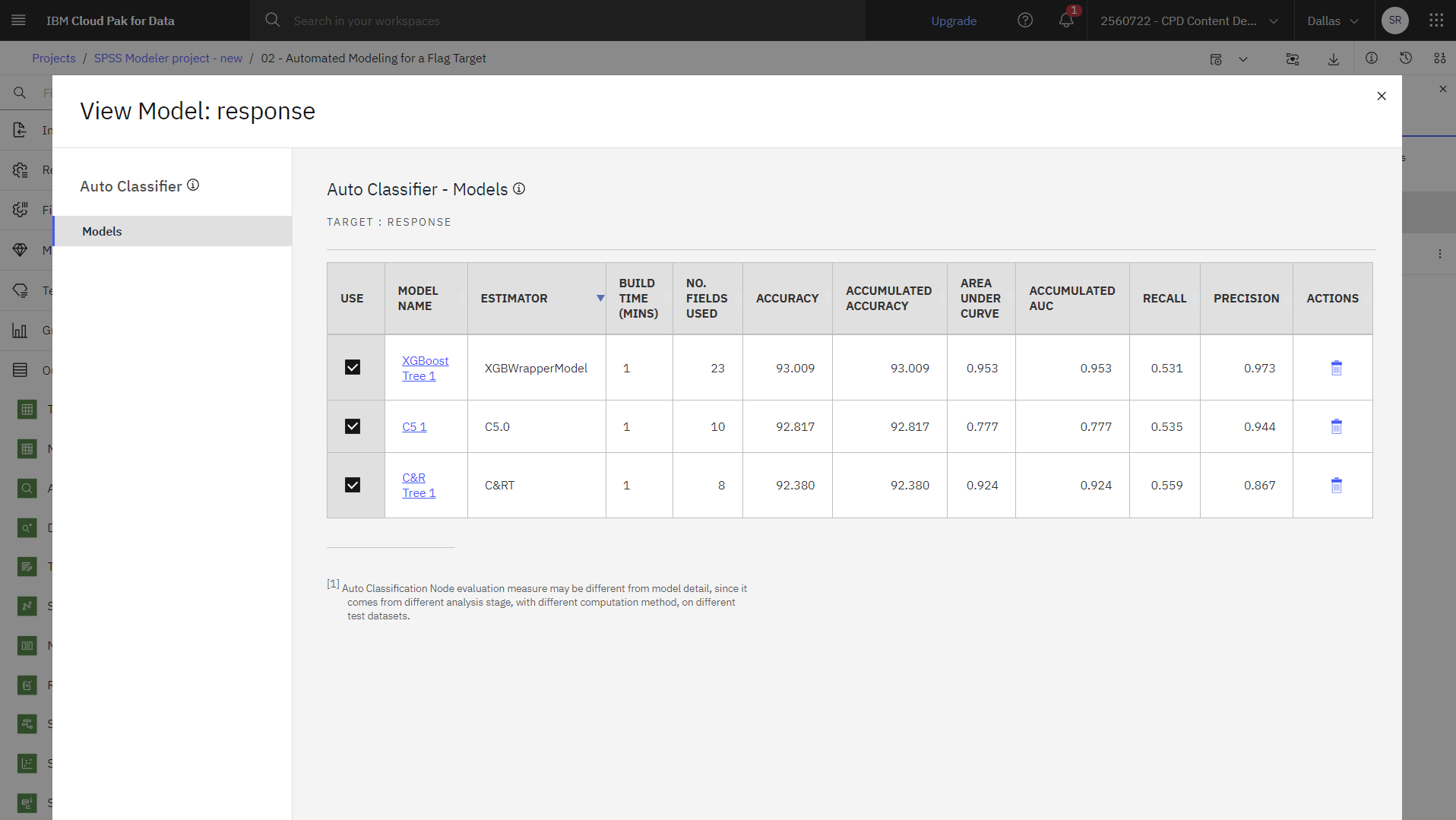
- 单击模型名称可查看任何单个模型的结果。
默认情况下,模型是根据总体准确率排序的,因为您在自动分类器节点属性中选择了该指标。 XGBoost Tree 模型按此度量进行排名最佳,但是 C5.0 和 C&RT 模型几乎一样准确。
基于这些结果,您可以决定使用所有这三个最准确的模型。 通过综合多个模型的预测结果,可以避免单个模型的局限性,从而提高整体准确性。
- 在"使用"栏中,验证所有三个模型,然后关闭模型窗口。
![]() 查看进度
查看进度
下图显示了型号对照表。 现在您可以运行模型分析了。
任务 6:运行模型分析
现在您已经查看了生成的模型,请按照以下步骤对模型进行分析:
- 将鼠标悬停在 “分析”节点上 ,点击 “运行”图标 。
- 在 "输出和模型"窗格中,单击 "分析输出 "查看结果。
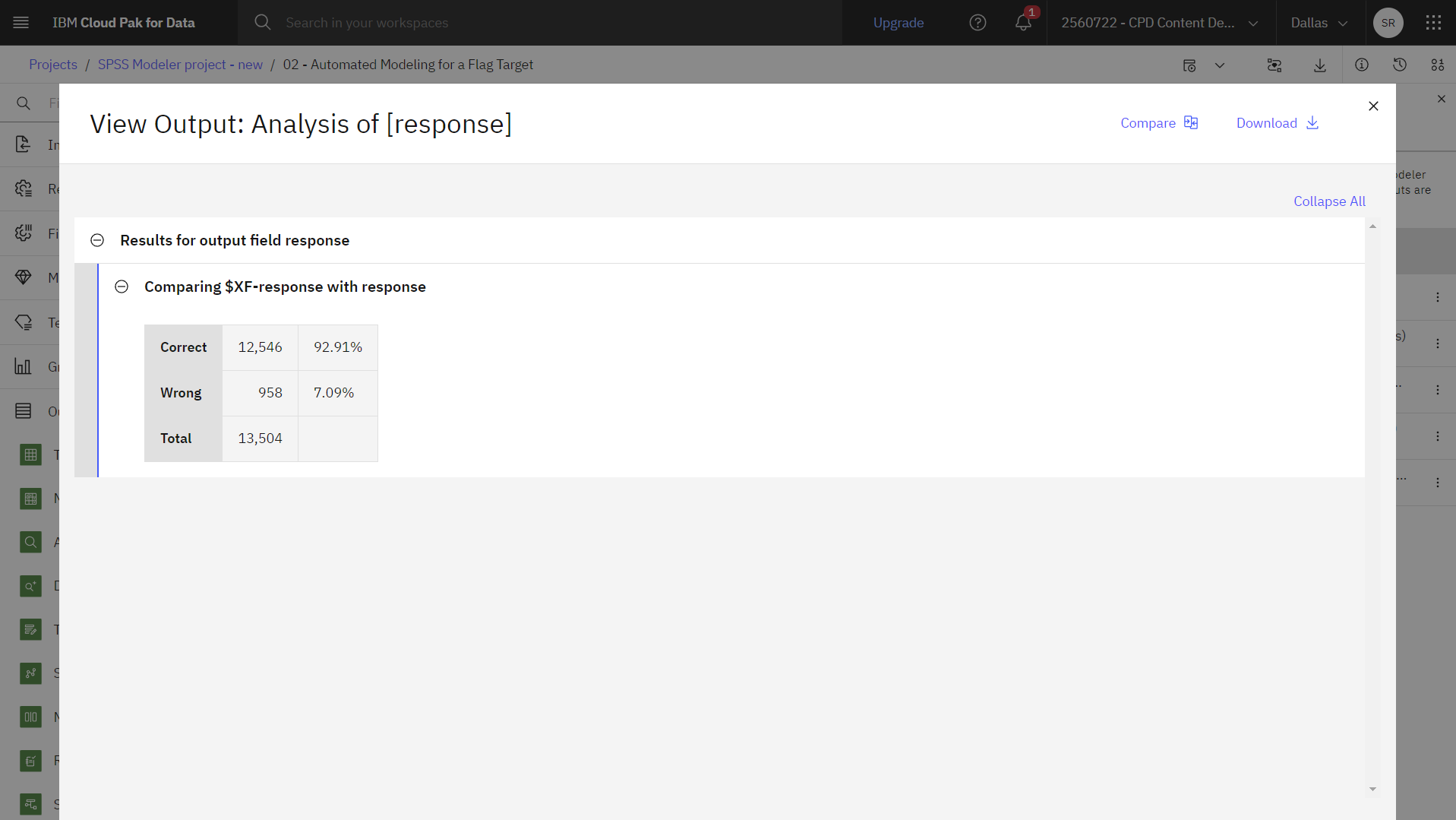
集合模型生成的总分显示在名为 "
$XF-response的字段中。 当对照训练数据进行测量时,预测值与实际响应(记录在原始response字段中)进行匹配,总体准确性为 92.77%。 在这种情况下,虽然没有三个模型中的最佳模型的准确性那么高(C5.0 模型的准确性高达 92.82%),但是它们之间的差异太小,可以忽略不计。 一般来说,将整体模型应用于除训练数据之外的数据集时,通常更有可能效果较好。
![]() 查看进度
查看进度
下图显示了使用分析节点的模型比较。
目录
在这个 "旗帜目标的自动建模流程示例中,您使用 "自动分类器节点比较了几个不同的模型,使用了三个最准确的模型,并将它们添加到流程的集合自动分类器模型小块中。
- 基于整体精确度,XGBoost Tree、C5.0 和 C&R 树模型在训练数据方面的表现最佳。
- 集合模型的表现几乎与单个模型的最佳表现相当,在应用于其他数据集时可能会更好。 如果您的目标是尽可能实现流程自动化,那么这种方法有助于在大多数情况下获得稳健的模型,而无需深入研究任何一个模型的具体细节。
后续步骤
现在您可以尝试其他 SPSS Modeler 教程了。