About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
資料の 英語版 に戻る
フラッグ・ターゲットのモデリングを自動化
図1: サンプルモデラーの流れ
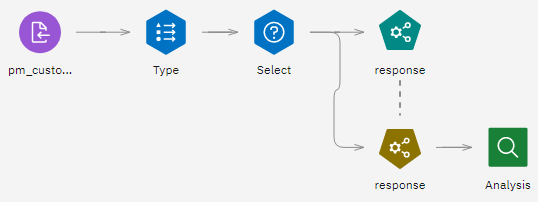

フラッグ・ターゲットのモデリングを自動化
最終更新: 2025年2月11日
このチュートリアルでは、Auto Classifier(自動分類器)ノードを使用して、フラグ(特定の顧客が貸し倒れになる可能性が高いかどうか、または特定のオファーに反応するかどうかなど)またはノミナル(設定された)ターゲットについて、多数の異なるモデルを自動的に作成し、比較します。
この例では、フラグ(イエスかノーか)の結果を検索する。 比較的単純なフローで、ノードは候補モデル・セットを生成およびランク付けし、最善のモデルを選択して、単一の集計済み (アンサンブル) モデルに結合します。 この方法は自動化の容易さと複数モデルの結合の利点を組み合わせるため、多くの場合、単一のモデルから取得するよりも精度が高い予測が得られます。
この例は、該当するオファーを各顧客にマッチングすることで、より収益性の高い結果を達成したいと考えている架空の会社に基づいています。 この方法では、自動化の利点を強調します。 連続(数値範囲)ターゲットを使用する同様の例については、他のSPSS® Modelerチュートリアルを参照してください。
チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、このドキュメントの概念とタスクを視覚的に学習する方法を提供しています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、このドキュメントの概念とタスクを視覚的に学習する方法を提供しています。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
このチュートリアルでは、サンプル・プロジェクトの「Automated Modeling for a Flag Target」フローを使用します。 使用するデータファイルはpm_customer_train1.csv です。 次の図は、モデラーのフロー例を示しています。
この例では、データ・ファイル pm_customer_train1.csv を使用します。このデータ・ファイルには、過去のキャンペーンで特定の顧客に行った提案を追跡する履歴データが含まれており、campaign
次の画像はサンプルデータセットです。図2: サンプルデータセット 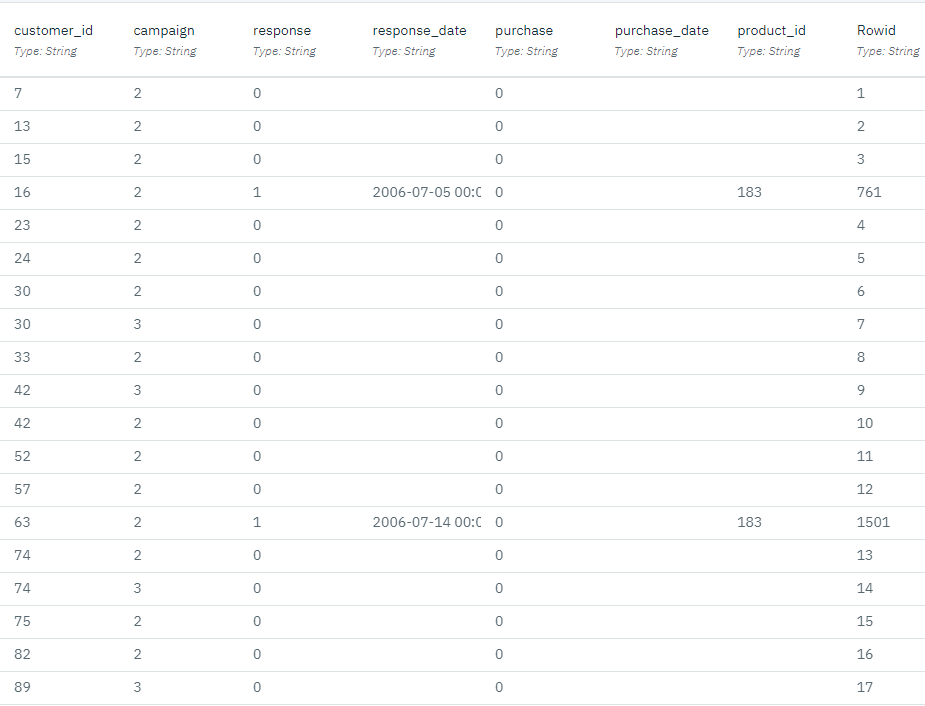
タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプルプロジェクトをまだお持ちでない場合は、 チュートリアルのトピックを参照してサンプルプロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataナビゲーションメニュー から
 、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。
、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。 - SPSS ModelerProjectをクリックします。
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。
タスク2:データ資産ノードを調べる
フラッグ・ターゲットの自動モデリングにはいくつかのノードがある。 以下の手順に従って、Data Assetノードを調べます。
- Assets]タブで[Automated Modeling for a Flag Target]モデラー・フローを開き、キャンバスがロードされるのを待つ。
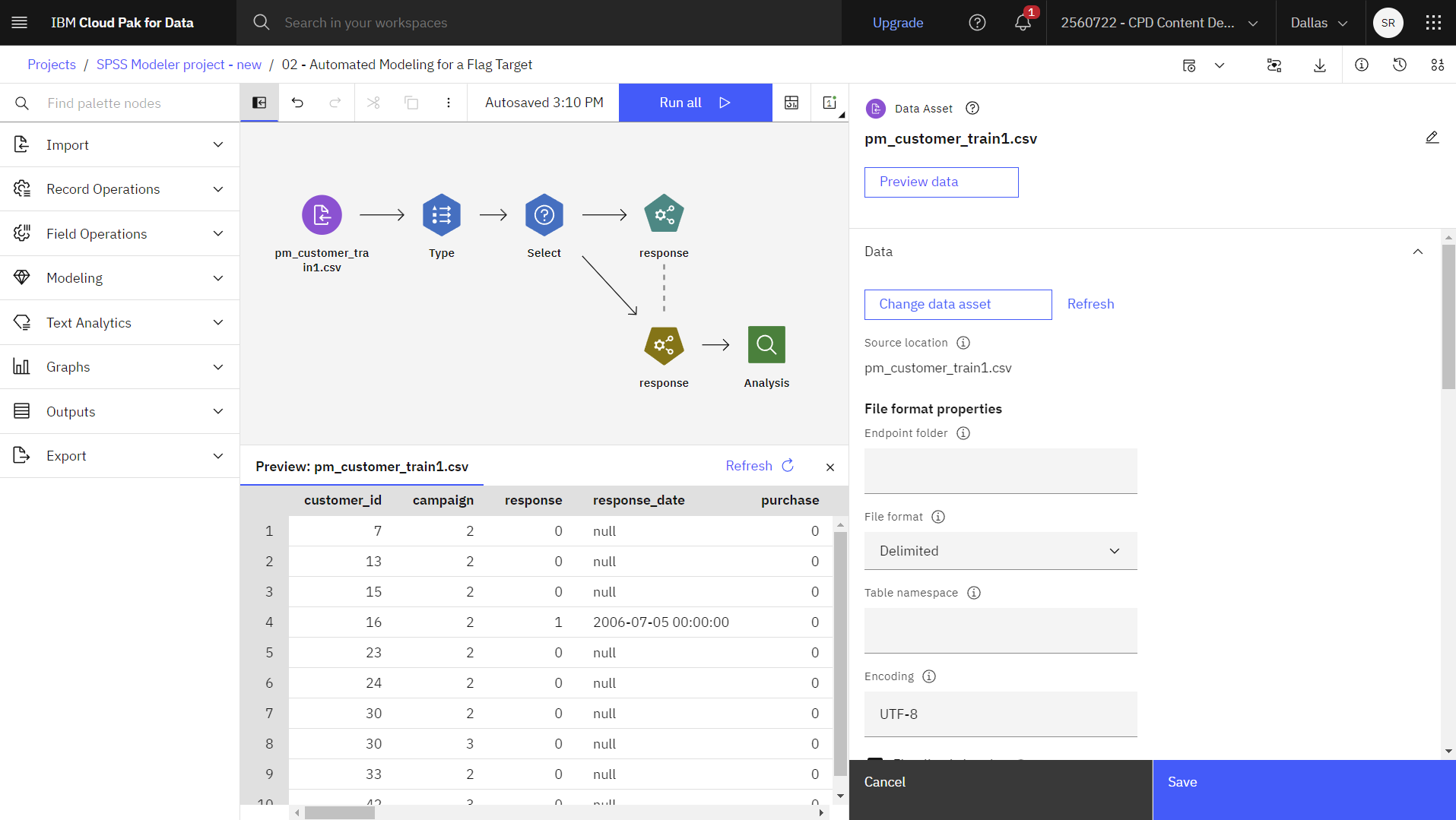
- pm_customer_train1.csvノードをダブルクリックします。 このノードは、プロジェクト内のpm_customer_train1.csvファイルを指すData Assetノードです。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
最大多数のレコードが Premium account キャンペーンに分類されています。
campaign2 = Premium accountこのファイルには、オファーが受け入れられたかどうかを示す「
response0 = no1 = yesresponse
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、Data Assetノードを示しています。 これでTypeノードを編集する準備が整いました。
タスク3:Typeノードを編集する
データ・アセットを探索したので、以下の手順に従ってタイプ・ノードのプロパティを表示および編集します:
- Typeノードをダブルクリックする。 このノードは、測定レベル(フィールドが含むデータのタイプ)などのフィールド・プロパティや、モデリングにおけるターゲットまたは入力としての各フィールドの役割を指定する。 測定の尺度は、フィールドのデータの種類を示すカテゴリーです。 ソース・データ・ファイルは、3つの異なる測定レベルを使用する:
- 連続フィールド('
Age - nominalフィールド('
EducationCollegeHigh school - 順序フィールド('
Income levelLowMediumHigh
- 連続フィールド('
- # レスポンスフィールドがターゲット・フィールド(Role = 'ターゲット )であり、このフィールドのメジャーが 'フラッグ であることを確認する。
図3: 測定レベルと役割を設定する 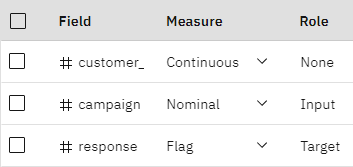
- 以下のフィールドのrole toがNoneに設定されていることを確認する。 これらのフィールドはモデル構築時には無視される。
- customer_id
- キャンペーン
- 応答日
- 購入
- 購入日
- product_id
- ROWID
- X_random
- TypeノードのRead Valuesをクリックし、値がインスタンス化されていることを確認する。
先ほど見たように、ソースデータには4つの異なるキャンペーンに関する情報が含まれており、それぞれが異なるタイプの顧客アカウントを対象としています。 これらのキャンペーンは、データ上では整数としてコード化されているため、各整数がどのアカウントタイプを表しているかを覚えておくために、各整数にラベルを定義する。
図4: フィールドの値を指定する 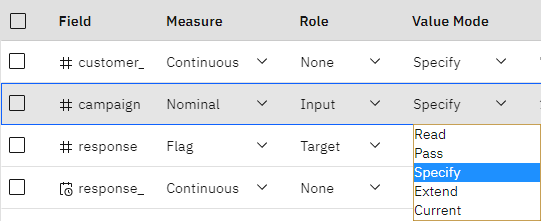
- キャンペーンの行とバリューモードの列で、リストから「指定」を選択します。
- #キャンペーンフィールドの行にある編集アイコン
 をクリックします。
をクリックします。- 4つの値それぞれについて、表示されているラベルを確認する。
図 5. フィールド値のラベルを定義する 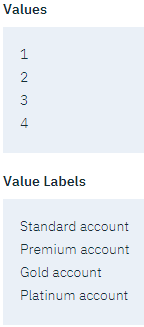
- 「OK」をクリックします。 これで、整数の代わりにラベルが出力ウィンドウに表示されるようになった。
- 4つの値それぞれについて、表示されているラベルを確認する。
- 保存 をクリックします。
- オプション:データ・プレビューをクリックすると、タイプ・プロパティが適用されたデータ・セットが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はTypeノードを示している。 これで、分析するキャンペーンを1つ選択する準備ができました。
タスク4:分析するキャンペーンを1つ選ぶ
データには4つの異なるキャンペーンの情報が含まれていますが、一度に1つのキャンペーンに絞って分析を行います。 以下の手順に従って、プレミアムアカウントキャンペーンのみを分析するノードを選択します:
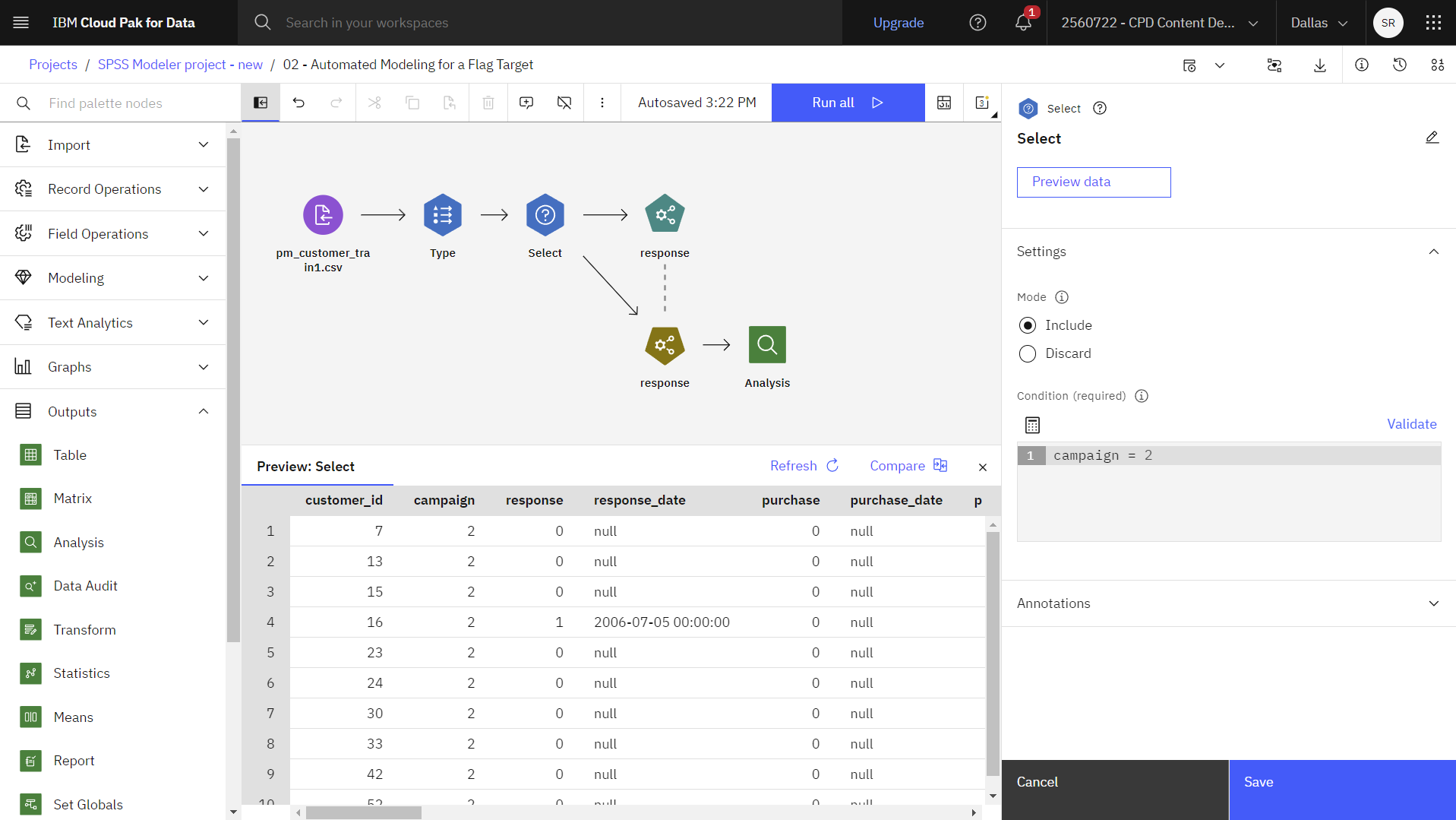
- Selectノードをダブルクリックしてプロパティを表示します。
- コンディションに注目。 最も多くのレコードがプレミアムアカウントキャンペーン(データでは「
campaign=2 - オプション:選択プロパティを適用したデータセットを見るには、データのプレビューをクリックします。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はSelectノードを示している。 これでモデルを作る準備ができた。
タスク5:モデルの構築
分析する1つのキャンペーンを選択したので、以下の手順に従って、Auto Classifierノードを使用するモデルを構築します:
- Response (Auto Classifier)ノードをダブルクリックしてプロパティを表示します。
- Build Optionsセクションを展開する。
- Rank models byフィールドで、モデルのランク付けに使用する指標としてOverall accuracyを選択します。
- 使用するモデルの数 を
3図 6. 自動分類ノードの作成オプション 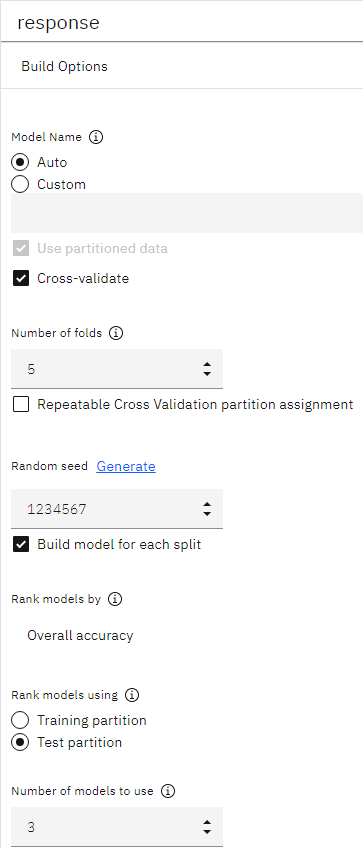
- エキスパートセクションを展開すると、さまざまなモデリングアルゴリズムを見ることができます。
- Discriminant、SVM、Random Forestのモデルタイプをクリアする。 これらのモデルは、このデータで学習するのに時間がかかるため、これらを排除することで例を早くすることができる。
Build Options(ビルド・オプション)」の「Number of models to use(使用するモデルの数)」プロパティを「
3図 7. 自動分類ノードのエキスパート・オプション 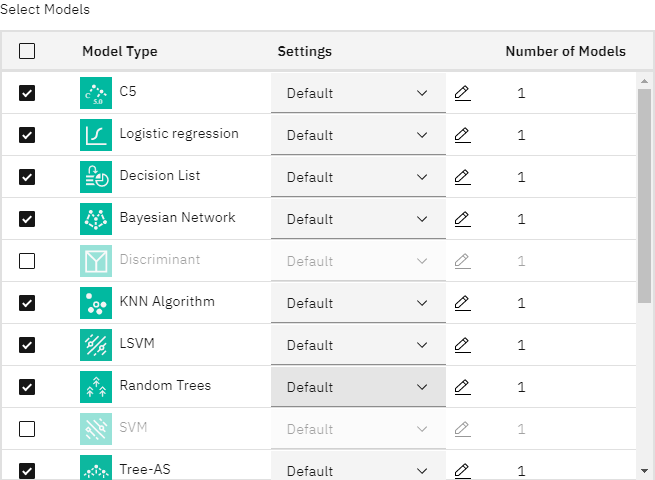
- Ensembleオプションで、Set Targetsと Flag Targetsの両方のアンサンブルメソッドにConfidence-weighted votingを選択します。 この設定は、各レコードに対してどのように1つの集計スコアを作成するかを決定する。
単純な投票では、 3 つのモデルのうち 2 つが yes を予測している場合、 yes は 2 対 1 で勝利します。 確信度-重み付き票決の場合は、各予測の確信度値に基づいて投票が重み付けされます。 そのため、2 つの「はい」の予測を組み合わせたものより高い確信度で 1 つのモデルが「いいえ」と予測する場合、「いいえ」が勝利します。
図 8. 自動分類ノードのアンサンブル・オプション 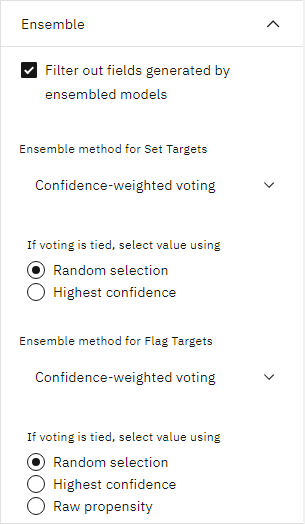
- 保存 をクリックします。
- 応答 分類器 ) ノードにカーソルを合わせ、 実行 アイコン
 をクリックします。
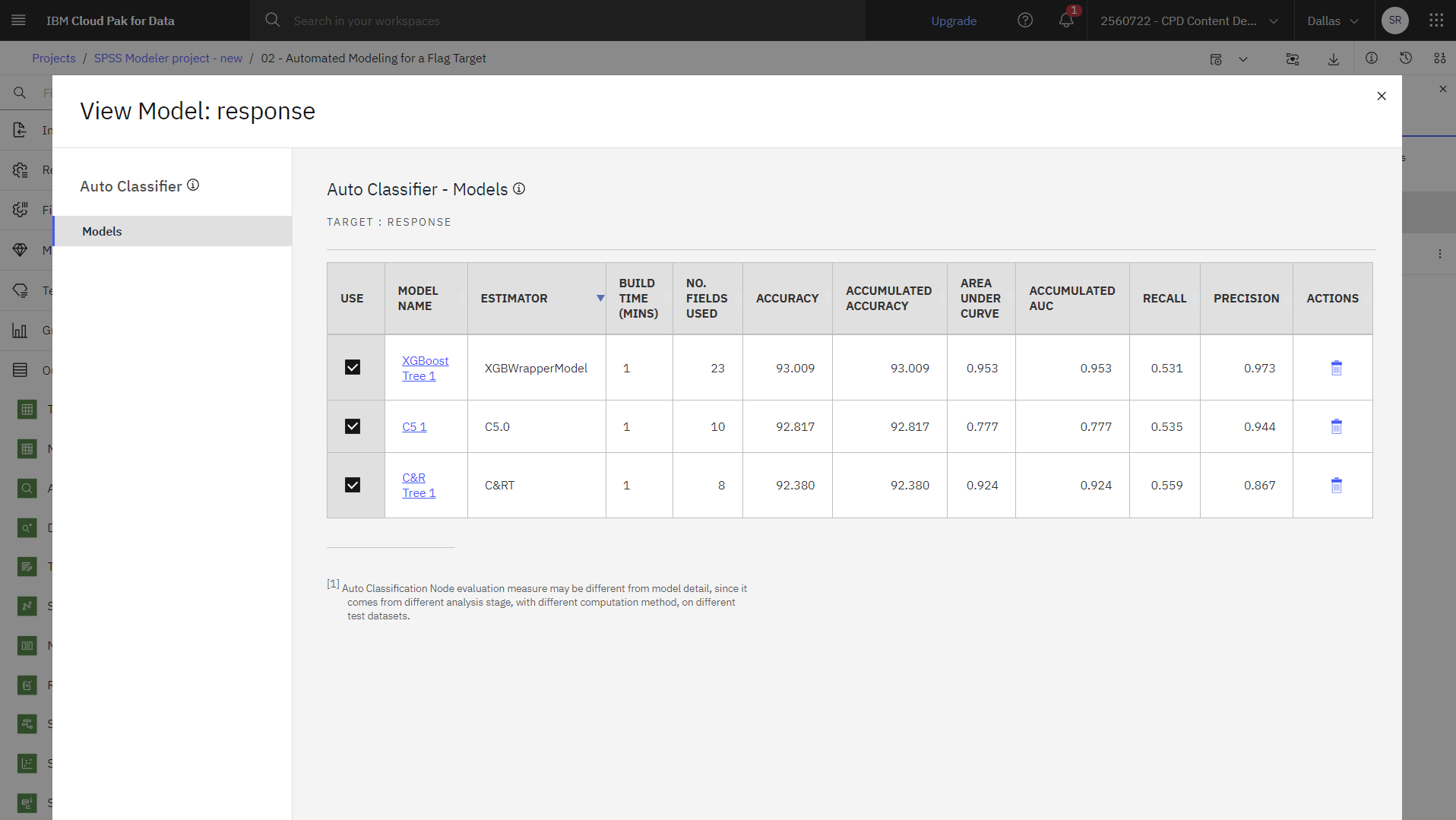
をクリックします。 - Outputs and modelsペインで、responseという名前のモデルをクリックして結果を表示します。 実行中に作成された各モデルの詳細が表示されます。 (大規模なデータセットに対して何百ものモデルが作成されるような実際の状況では、フローを実行するのに何時間もかかるかもしれない)
- モデル名をクリックすると、各モデルの結果が表示されます。
デフォルトでは、Auto Classifierノードのプロパティでその尺度を選択したため、モデルは全体的な正確さに基づいて並べ替えられます。 XGBoost Tree モデルはこの指標では最も優れていますが、C5.0 および C&RT モデルも同じくらい正確です。
これらの結果に基づいて、3 つの最も正確なモデルをすべて使用するように指定します。 複数のモデルからの予測を組み合わせることで、個々のモデルの限界を回避し、結果として全体的な精度を高めることができるかもしれない。
- USEの欄で、3つのモデルがすべて揃っていることを確認し、モデルウィンドウを閉じる。
![]() 進捗状況を確認する
進捗状況を確認する
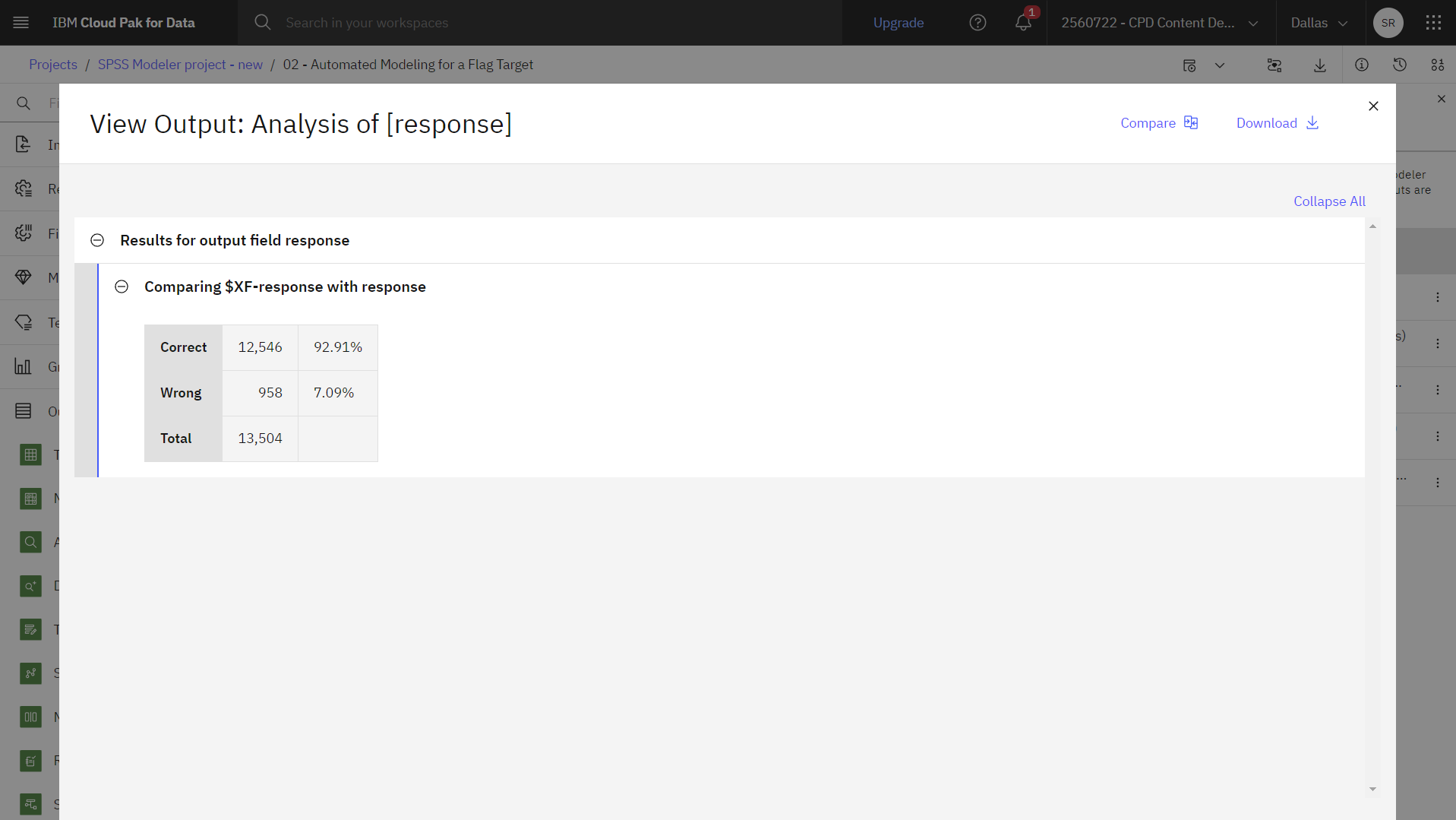
以下の画像はモデル比較表です。 これでモデル分析を実行する準備が整いました。
タスク6:モデル分析の実行
生成されたモデルを確認したので、以下の手順に従ってモデルの分析を実行します:
- 「分析」ノードにカーソルを合わせ 、「実行」アイコン をクリックします。
- 出力とモデル]ペインで、[分析]出力をクリックして結果を表示します。
アンサンブルモデルによって生成されたスコアは、「
$XF-responseresponse
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、Analysisノードを使用したモデル比較を示しています。
サマリー
この例の'フラッグ・ターゲットの自動モデリングフローでは、'自動分類器ノードを使用して複数の異なるモデルを比較し、最も正確な3つのモデルを使用し、それらをアンサンブルされたAuto Classifierモデルナゲット内のフローに追加した。
- 全体の精度に基づいて、XGBoost Tree、C5.0、および C&R Tree モデルが学習データにおいて最も良い結果を出しました。
- アンサンブルされたモデルは、個々のモデルの中で最も優れたものとほぼ同等の性能を発揮し、他のデータセットに適用した場合、より優れた性能を発揮する可能性がある。 可能な限りプロセスを自動化することが目標であれば、このアプローチは、どのモデルの詳細についても深く掘り下げることなく、ほとんどの状況下でロバストなモデルを得るのに役立つ。
次のステップ
これで、他の SPSS Modeler チュートリアルを試す準備ができました。
トピックは役に立ちましたか?
0/1000