Last updated: Oct 09, 2024
- Right-click each Logistic node and run it to create the model nuggets, which are added to the
flow. Results are also added to the Outputs panel.
Figure 1. Attaching the model nuggets 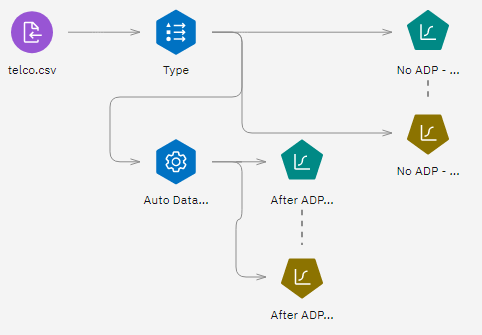
- Attach Analysis nodes to the model nuggets and run the Analysis nodes (using their default
settings).
Figure 2. Attaching the Analysis nodes 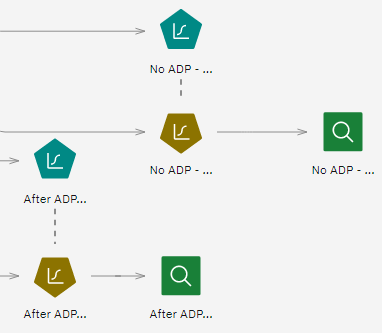 The Analysis of the non Auto Data Prep-derived model shows that just running the data through the Logistic Regression node with its default settings gives a model with low accuracy - just 10.6%.
The Analysis of the non Auto Data Prep-derived model shows that just running the data through the Logistic Regression node with its default settings gives a model with low accuracy - just 10.6%.Figure 3. Non ADP-derived model results  The Analysis of the Auto-Data Prep-derived model shows that by running the data through the default Auto Data Prep settings, you have built a much more accurate model that's 78.3% correct.
The Analysis of the Auto-Data Prep-derived model shows that by running the data through the default Auto Data Prep settings, you have built a much more accurate model that's 78.3% correct.Figure 4. ADP-derived model results 
In summary, by just running the Auto Data Prep node to fine tune the processing of your data, you were able to build a more accurate model with little direct data manipulation.
Obviously, if you're interested in proving or disproving a certain theory, or want to build specific models, you may find it beneficial to work directly with the model settings. However, for those with a reduced amount of time, or with a large amount of data to prepare, the Auto Data Prep node may give you an advantage.
Note that the results in this example are based on the training data only. To assess how well models generalize to other data in the real world, you would use a Partition node to hold out a subset of records for purposes of testing and validation.