本教程提供了一个准备分析数据的示例。 准备数据是任何数据挖掘项目中最重要的步骤之一,也是传统上最耗时的步骤之一。 自动数据准备节点会为您处理任务,分析您的数据并确定修复方案,筛选出有问题或不可能有用的字段,在适当的时候推导出新的属性,并通过智能筛选技术提高性能。
您可以以完全自动化的方式使用自动数据准备节点,让该节点选择并应用修复,也可以在更改前预览更改,并接受或拒绝这些更改。 通过此节点,您可以轻松快捷地准备数据以进行数据挖掘,而无需事先了解涉及到的统计概念。 如果使用默认设置运行节点,模型的构建和得分往往会更快。
预览教程
 观看本视频,预览本教程中的步骤。 视频中显示的用户界面可能略有不同。 该视频旨在作为书面教程的补充。 本视频以可视化的方式介绍了本文件中的概念和任务。
观看本视频,预览本教程中的步骤。 视频中显示的用户界面可能略有不同。 该视频旨在作为书面教程的补充。 本视频以可视化的方式介绍了本文件中的概念和任务。
试用教程
在本教程中,您将完成这些任务:
建模流程和数据集样本
本教程使用示例项目中的自动数据准备流程。 使用的数据文件是telco.csv。 本例演示了在构建模型时使用默认的自动数据准备节点设置可以提高精确度。 下图显示了建模流程示例。


任务 1:打开示例项目
任务 2:检查数据资产和类型节点
自动数据准备包括几个节点。 按照以下步骤检查数据资产和类型节点:
- 从 "资产"选项卡打开 "自动数据准备"建模流程,等待画布加载。
- 双击telco.csv节点。 该节点是数据资产节点,指向项目中的telco.csv文件。
- 查看文件格式属性。
- 可选:单击 "预览数据"查看完整数据集。
- 双击类型节点。 请注意,"
churn字段的度量值设置为"标志",角色设置为 "目标"。 确保所有其他字段的角色都设置为输入。图 3。 设置测量级别和角色 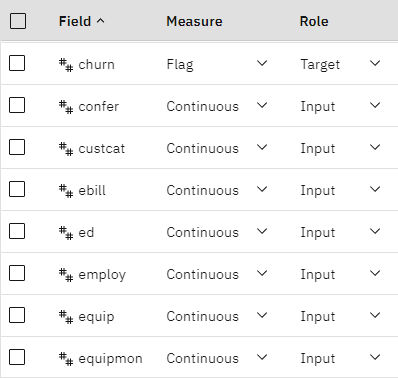
- 可选:单击预览数据,查看应用了类型属性的数据集。
![]() 查看进度
查看进度
下图显示了类型节点。 现在您可以开始制作模型了。

任务 3:建立模型
您将建立两个模型,一个是不带自动数据准备功能的模型,另一个是带自动数据准备功能的模型。 请按照以下步骤制作模型:
- 双击与 "类型"节点相连的 "无 ADP--流失"节点,查看其属性。
- 展开 "模型设置"部分
- 确认程序设置为二项式。
- 确认 "模型名称 "设置为 "自定义",且名称为 "No ADP - churn。
图 4: 逻辑节点模型设置部分 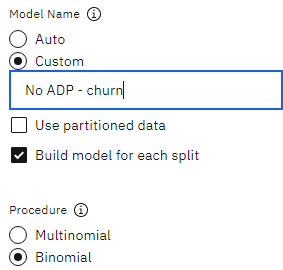
- 将鼠标悬停在 “无ADP - 流失 ”节点上,点击 “运行”图标
 。
。 - 在 "输出和模型"窗格中,单击名称为 "无 ADP-流失 "的模型查看结果。
- 查看模型摘要页面,其中显示了模型使用的预测字段以及预测正确率。
- 查看案件处理摘要,其中显示了纳入分析的记录数量和百分比。 另外,此摘要还列出了其中有一个或多个输入字段不可用的缺失个案数(如果有的话)以及所有未选定的个案数。
- 关闭模型详细信息。
- 双击与类型节点相连的自动数据准备节点,查看其属性。 自动数据准备功能可为您处理数据准备任务,分析您的数据并确定修复方案,筛选出有问题或不可能有用的字段,在适当的时候推导出新的属性,并通过智能筛选技术提高性能。
- 在"目标"部分,请保留默认设置,以便通过平衡速度和准确性来分析和准备数据。 其他"自动数据准备"节点属性可让您选择是更注重准确性、更注重处理速度,还是对数据准备的许多处理步骤进行微调。注意:如果要调整节点属性并在将来再次运行流程,由于模型已经存在,必须首先单击Objectives(目标)下的Clear old analysis(清除旧分析),然后才能再次运行流程。
- 可选:单击预览数据,查看应用了自动数据准备属性的数据集。
- 单击取消。
- 在"目标"部分,请保留默认设置,以便通过平衡速度和准确性来分析和准备数据。 其他"自动数据准备"节点属性可让您选择是更注重准确性、更注重处理速度,还是对数据准备的许多处理步骤进行微调。
- 双击与自动数据准备节点相连的After ADP - churn节点,查看其属性。
- 展开 "模型设置"部分
- 确认程序设置为二项式。
- 确认 "模型名称 "设置为 "自定义",且名称为 "After ADP - churn。
- 将鼠标悬停在 “After ADP - churn”节点上 ,点击 “运行”图标 。
- 在 "输出和模型"窗格中,单击名称为 "After ADP - churn"的模型查看结果。
- 查看模型摘要页面,其中显示了模型使用的预测字段以及预测正确率。
- 查看案件处理摘要,其中显示了纳入分析的记录数量和百分比。 另外,此摘要还列出了其中有一个或多个输入字段不可用的缺失个案数(如果有的话)以及所有未选定的个案数。
- 关闭模型详细信息。
![]() 查看进度
查看进度
下图显示了模型的详细信息。 现在您可以对模型进行比较了。

任务 4:比较模型
现在两个模型都已配置,请按照以下步骤生成和比较模型:
- 将鼠标悬停在 “No ADP - LogReg (分析) ”节点上,点击 “运行”图标 。
- 将鼠标悬停在 “ADP之后—— LogReg (分析) ”节点上,点击 “运行”图标 。
- 在 "输出和模型"窗格中,单击名称为No ADP -LogReg的输出结果查看结果。
- 比较模型:
- 点击比较。
- 在选择输出字段中,选择After ADP -LogReg。
对非衍生自动数据准备模型的分析表明,仅通过 逻辑回归节点的默认设置运行数据,就能得到准确率较低的模型,仅为10.6。图 5. 非 ADP 派生模型结果  对自动数据准备衍生模型的分析表明,通过默认的自动数据准备设置运行数据,您建立的模型要准确得多,正确率达到78.3。
对自动数据准备衍生模型的分析表明,通过默认的自动数据准备设置运行数据,您建立的模型要准确得多,正确率达到78.3。图 6. ADP 派生模型结果 
![]() 查看进度
查看进度
下图为模型对比图。

目录
通过运行 "自动数据准备"节点对数据处理进行微调,您只需对数据进行少量的直接操作,就能建立一个更精确的模型。
显然,如果你有兴趣证明或反驳某个理论,或者想建立特定的模型,你可能会发现直接使用模型设置会很有帮助。 不过,如果您时间有限或需要准备大量数据,自动数据准备节点可能会给您带来优势。
本例中的结果仅基于训练数据。 要评估模型对真实世界中其他数据的泛化程度,可以使用分区节点来保留记录子集,以便进行测试和验证。
后续步骤
现在您可以尝试其他 SPSS® Modeler 教程了。