About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
資料の 英語版 に戻る
データ準備の自動化
図1: サンプルモデラーの流れ 



データ準備の自動化
最終更新: 2025年2月11日
このチュートリアルでは、分析のためにデータを準備する例を示します。 データを準備することは、データマイニング・プロジェクトにおいて最も重要なステップの一つであり、伝統的に最も時間のかかるステップの一つである。 Auto Data Prep(オートデータプレパレーション)ノードは、データを分析し、修正点を特定し、問題のあるフィールドや有用でないフィールドを除外し、必要に応じて新しい属性を導き出し、インテリジェントなスクリーニング技術によってパフォーマンスを向上させます。
Auto Data Prepノードを完全に自動化された方法で使用し、ノードが修正を選択して適用することも、変更が加えられる前にプレビューし、それを受け入れるか拒否することもできます。 このノードを使用すると、関係する統計の概念を事前に把握していなくても、データ・マイニング用のデータを迅速かつ容易に準備できます。 デフォルトの設定でノードを動かすと、モデルの構築と得点が速くなる傾向がある。
チュートリアルをプレビューする
 このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、このドキュメントのコンセプトとタスクを視覚的に学習する方法を提供しています。
このチュートリアルのステップをプレビューするには、このビデオをご覧ください。 動画で表示されているユーザーインターフェースと若干異なる場合があります。 このビデオは、文章によるチュートリアルの補足資料としてご利用いただくことを目的としています。 このビデオでは、このドキュメントのコンセプトとタスクを視覚的に学習する方法を提供しています。
チュートリアルを試す
このチュートリアルでは、以下のタスクを実行します:
モデラーのフローとデータセットのサンプル
このチュートリアルでは、サンプル・プロジェクトの自動データ準備フローを使用します。 使用するデータファイルはtelco.csvである。 この例は、モデルを構築する際にデフォルトのAuto Data Prepノードの設定を使用することで精度が向上することを示しています。 次の図は、モデラーのフロー例を示しています。
次の画像はサンプルデータセットです。図2: サンプルデータセット 
タスク 1:サンプルプロジェクトを開く
サンプル・プロジェクトには、いくつかのデータ・セットとモデラー・フローのサンプルが含まれています。 サンプルプロジェクトをまだお持ちでない場合は、 チュートリアルのトピックを参照してサンプルプロジェクトを作成してください。 次に、以下の手順でサンプルプロジェクトを開きます:
- Cloud Pak for Dataナビゲーションメニューから
 、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。
、 [プロジェクト] > [すべてのプロジェクトを表示] の順に選択します。 - SPSS ModelerProjectをクリックします。
- アセット」タブをクリックすると、データセットとモデラーフローが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図は、プロジェクトのAssetsタブを示しています。 これで、このチュートリアルに関連するサンプルモデラーフローで作業する準備ができました。
タスク 2: データアセットとタイプノードを調べる
自動データ準備にはいくつかのノードがある。 以下の手順に従って、データ・アセットと タイプ・ノードを調べます:
- Assetsタブから、Automated Data Preparationモデラー・フローを開き、キャンバスがロードされるのを待つ。
- telco.csvノードをダブルクリックする。 このノードは、プロジェクト内のtelco.csvファイルを指すData Assetノードです。
- ファイル形式のプロパティを確認します。
- オプション:完全なデータセットを表示するには、データのプレビューをクリックします。
- Typeノードをダブルクリックする。
churn図3: 測定レベルと役割を設定する 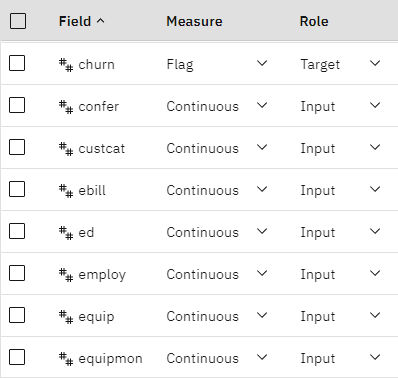
- オプション:データ・プレビューをクリックすると、タイプ・プロパティが適用されたデータ・セットが表示されます。
![]() 進捗状況を確認する
進捗状況を確認する
次の図はTypeノードを示している。 これでモデルを作る準備ができた。
タスク3:モデルの構築
あなたは2つのモデルを構築します。1つはデータ準備を自動化しないモデル、もう1つはデータ準備を自動化したモデルです。 以下の手順でモデルを作成する:
- Type」ノードに接続されている「No ADP - churn」ノードをダブルクリックしてプロパティを表示する。
- モデル設定セクションを展開する
- ProcedureがBinomial に設定されていることを確認する。
- モデル名が カスタムに設定され、名前が'No ADP - churnであることを確認する。
図4: ロジスティック・ノード・モデル設定セクション 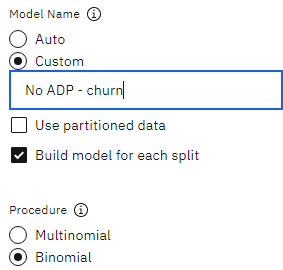
- 「No ADP - churn」ノードにカーソルを合わせ 、「実行」アイコン
 をクリックします。
をクリックします。 - Outputs and modelsペインで、No ADP - churnという名前のモデルをクリックして、結果を表示します。
- モデル概要ページを見る。このページは、モデルによって使用される予測フィールドと、予測の正答率を示す。
- 分析に含まれるレコードの数と割合を示すケース処理サマリーを表示します。 さらに、1 つ以上の入力フィールドが利用不可の場合に、欠損したケースがある場合は、その数もリストします。また選択されなかったケースの数もリストします。
- モデルの詳細を閉じます。
- Typeノードに接続されているAuto Data Prepノードをダブルクリックして、そのプロパティを表示する。 Automated Data Preparationは、お客様に代わってデータ準備タスクを処理し、データを分析して修正点を特定し、問題のあるフィールドや有用でない可能性のあるフィールドを除外し、必要に応じて新しい属性を導き出し、インテリジェントなスクリーニング技術によってパフォーマンスを向上させます。
- Objectives(目的)セクションでは、デフォルト設定のままで、スピードと精度のバランスをとりながらデータを分析し、準備します。 その他の自動データ準備ノード・プロパティでは、精度を重視する、処理速度を重視する、データ準備の処理ステップの多くを微調整するなどのオプションを指定できます。注:既にモデルが存在するため、将来ノードプロパティを調整してフローを再実行する場合は、フローを再実行する前に、まず「Objectives」の「Clear old analysis」をクリックする必要があります。
- オプション:データのプレビューをクリックすると、自動データ準備プロパティが適用されたデータセットが表示されます。
- キャンセル」をクリックする。
- Objectives(目的)セクションでは、デフォルト設定のままで、スピードと精度のバランスをとりながらデータを分析し、準備します。 その他の自動データ準備ノード・プロパティでは、精度を重視する、処理速度を重視する、データ準備の処理ステップの多くを微調整するなどのオプションを指定できます。
- Auto Data Prepノードに接続されているAfter ADP - churnノードをダブルクリックしてプロパティを表示する。
- モデル設定セクションを展開する
- ProcedureがBinomial に設定されていることを確認する。
- モデル名が カスタムに設定され、名前が'After ADP - churnであることを確認する。
- After ADP - churnノードの上にカーソルを移動し、 実行アイコン をクリックします。
- Outputs and modelsペインで、After ADP - churnという名前のモデルをクリックして、結果を表示します。
- モデル概要ページを見る。このページは、モデルによって使用される予測フィールドと、予測の正答率を示す。
- 分析に含まれるレコードの数と割合を示すケース処理サマリーを表示します。 さらに、1 つ以上の入力フィールドが利用不可の場合に、欠損したケースがある場合は、その数もリストします。また選択されなかったケースの数もリストします。
- モデルの詳細を閉じます。
![]() 進捗状況を確認する
進捗状況を確認する
以下の画像はモデルの詳細を示している。 これでモデルを比較する準備は整った。
タスク4:モデルの比較
両方のモデルが設定されたので、以下の手順に従ってモデルを生成し、比較する:
- 「No ADP - LogReg (分析 )」ノードにカーソルを合わせ 、「実行」 アイコン をクリックします。
- After ADP - LogReg (Analysis ) ノードの上にカーソルを移動し、 Run アイコン をクリックします。
- 出力とモデル]ペインで、[No ADP -LogRegという名前の出力結果をクリックして結果を表示します。
- モデルを比較する:
- 比較」をクリックする。
- Select outputフィールドで、ADP後-LogRegを選択する。
派生していないAuto Data Prepモデルの分析は、デフォルト設定の ロジスティック回帰ノードを通してデータを実行するだけで、精度の低いモデル(わずか10.6%)を与えることを示しています。図 5. 非 ADP 派生モデルの結果  オート・データ・プレパレーション由来のモデルの分析によると、デフォルトのオート・データ・プレパレーション設定を通してデータを実行することで、78.3の正答率を誇る、より正確なモデルが構築されたことがわかる。
オート・データ・プレパレーション由来のモデルの分析によると、デフォルトのオート・データ・プレパレーション設定を通してデータを実行することで、78.3の正答率を誇る、より正確なモデルが構築されたことがわかる。図 6. ADP 派生モデルの結果 
![]() 進捗状況を確認する
進捗状況を確認する
以下の画像はモデル比較。
サマリー
データの処理を微調整するためにAuto Data Prepノードを実行することで、データを直接操作することなく、より正確なモデルを構築することができました。
もちろん、ある理論の証明や反証に興味があったり、特定のモデルを作りたい場合は、モデルの設定を直接操作するのが有益かもしれない。 しかし、準備する時間が限られていたり、大量のデータがある場合は、Auto Data Prepノードが有利に働くかもしれない。
この例の結果は、トレーニングデータのみに基づいている。 モデルが実世界の他のデータに対してどの程度一般化されるかを評価するために、パーティション・ノードを使用して、テストと検証の目的でレコードのサブセットを保持することができます。
次のステップ
これで、他の SPSS® Modeler チュートリアルを試す準備ができました。
トピックは役に立ちましたか?
0/1000