Go back to the English version of the documentation文本分析工作台
文本分析工作台 (SPSS Modeler)
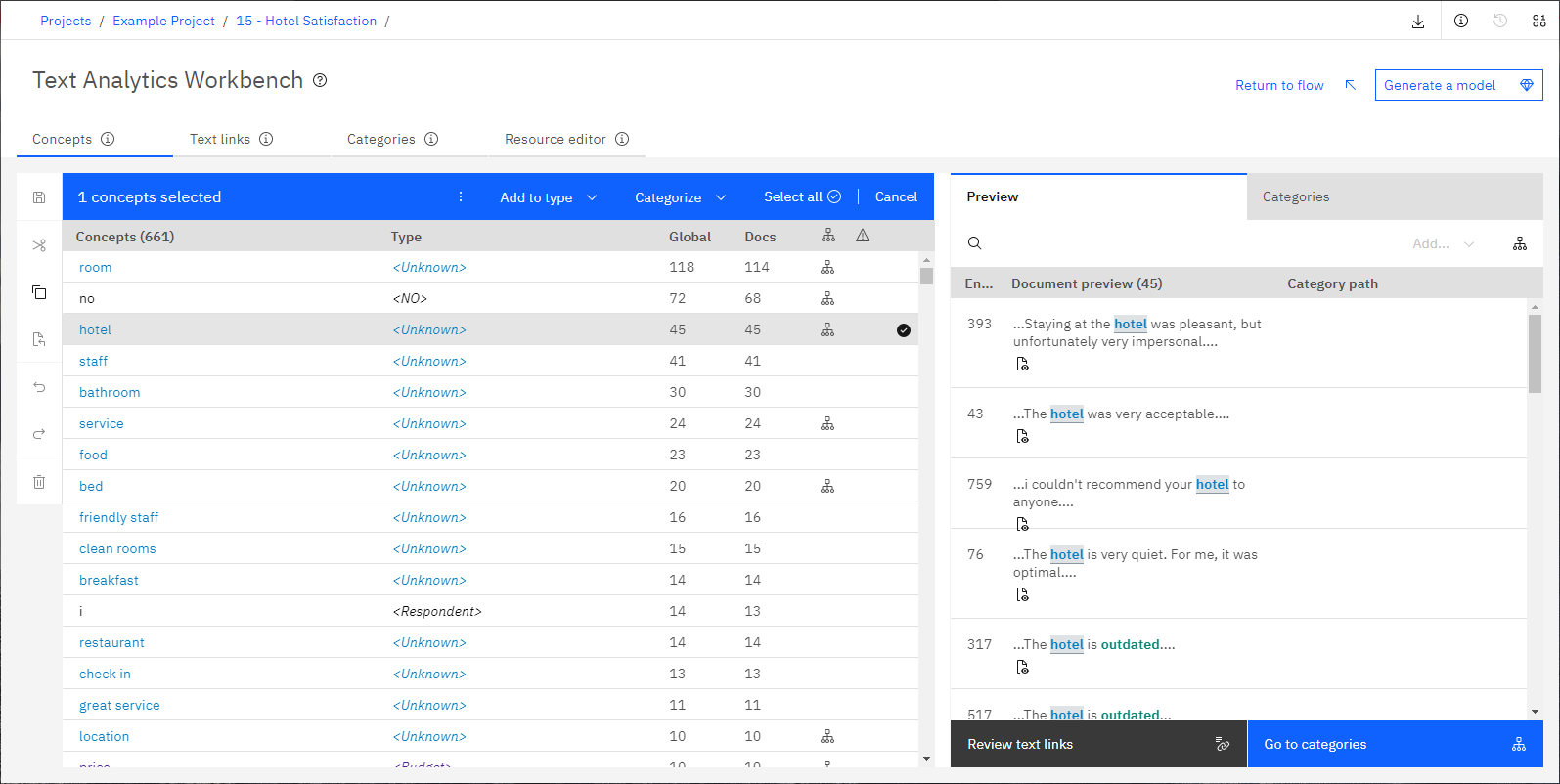
图 1。 文本分析工作台
Last updated: 2024年9月24日
从 "文本挖掘" 节点,您可以选择在流运行时启动 "文本分析工作台" 会话。 Text Analytics Workbench 是一个交互式会话,您可以在其中浏览抽取结果并对 "文本挖掘" 节点的配置进行微调。
文本挖掘 是一个迭代过程,在此过程中,将根据文本数据的上下文复审抽取结果,进行微调以生成新结果,然后重新评估。 运行 "文本挖掘" 节点时,抽取引擎将读取文本数据,识别相关概念,并为每个概念分配类型。
文本挖掘节点运行结束后,文本分析工作台就会打开,您可以查看提取结果。 文本分析工作台组织成选项卡。 在每个选项卡上,您可以关注文本挖掘过程的不同区域。
- 概念
- 概念是从文本数据中标识和抽取的重要单词和短语。 它们也称为 抽取结果。 这些概念分组到类型。 您可以使用这些概念来浏览数据和创建类别。 您可以在 概念 选项卡上管理概念。
- 文本链接
- 如果您在语言资源中具有文本链接分析 (TLA) 规则,那么可以从文本数据中抽取模式。 例如,您的资源模板已有一些 TLA 规则。 这些模式可帮助发现数据中概念之间有意义的关系。 您还可以使用这些模式作为类别中的描述符。 您可以在 文本链接 选项卡上管理这些模式。
- 类别
- 使用 描述符 (例如抽取结果,模式和规则) 作为定义,您可以手动或自动创建一组类别。 根据文档和记录是否包含类别定义的一部分,将这些文档和记录分配给这些类别。 您可以在 类别 选项卡上管理类别。
- 资源
- 抽取过程依赖于一组来自语言资源的参数和定义来管理文本的抽取和处理方式。 您可以在 资源编辑器选项卡上调整这些语言资源(如模板和库)。
您可以使用工作台执行以下文本挖掘任务:
- 从文本数据中抽取关键概念
- 构建类别
- 探索文本链接分析 (TLA) 中的模式
- 生成类别模型块
- 将提取过程中调整或使用的资源保存为文本分析包 (TAP)。