A partir d'un noeud Text Mining, vous pouvez choisir de démarrer la session Text Analytics Workbench lors de l'exécution de votre flux. Le plan de travail Text Analytics est une session interactive dans laquelle vous pouvez explorer les résultats de l'extraction et affiner la configuration du noeud Text Mining.
L' exploration de texte est un processus itératif dans lequel les résultats d'extraction sont révisés en fonction du contexte des données texte, affinés pour produire de nouveaux résultats, puis réévalués. Lorsque vous exécutez le noeud Text Mining, le moteur d'extraction lit les données textuelles, identifie les concepts pertinents et affecte un type à chacun d'eux.
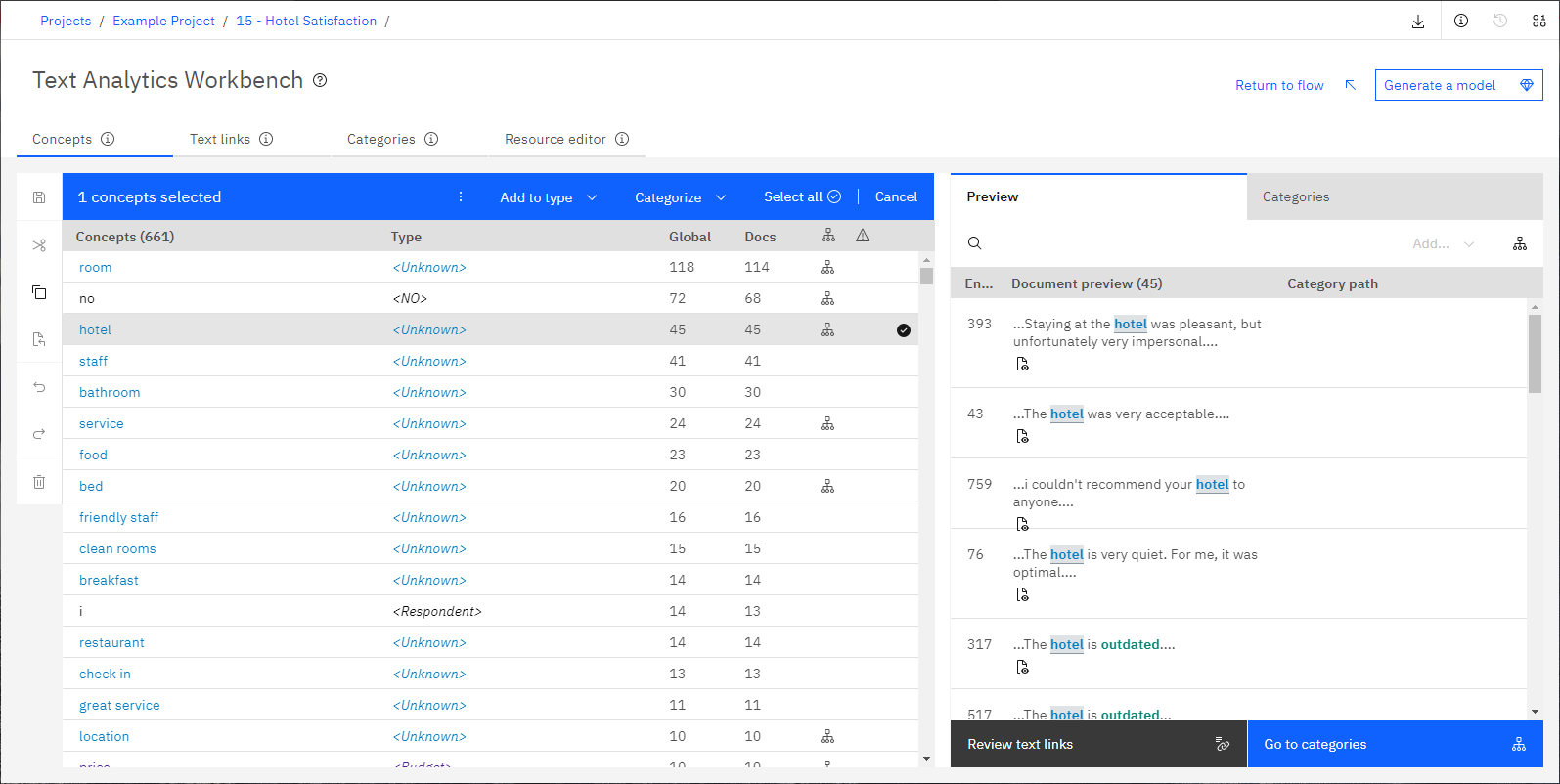
Lorsque le nœud d'analyse de texte est terminé, l'atelier d'analyse de texte s'ouvre pour que vous puissiez examiner les résultats de l'extraction. Le plan de travail Text Analytics est organisé en onglets. Dans chaque onglet, vous pouvez vous concentrer sur différentes zones du processus d'exploration de texte.
- Concepts
- Les concepts sont des mots et des phrases importants qui ont été identifiés et extraits de vos données textuelles. Ils sont également appelés résultats d'extraction. Ces concepts sont regroupés en types. Vous pouvez utiliser ces concepts pour explorer vos données et créer vos catégories. Vous pouvez gérer les concepts dans l'onglet Concepts .
- Liens texte
- Vous pouvez extraire des motifs de vos données texte si vos ressources linguistiques contiennent des règles d'analyse des liens du texte (TLA). Par exemple, votre modèle de ressource comporte déjà des règles TLA. Ces motifs peuvent vous permettre de découvrir des relations intéressantes entre les concepts figurant dans vos données. Vous pouvez également utiliser des motifs comme descripteurs dans vos catégories. Vous pouvez gérer ces modèles dans l'onglet Liens texte .
- Catégories
- En utilisant des descripteurs (tels que les résultats d'extraction, les motifs et les règles) comme définition, vous pouvez créer manuellement ou automatiquement un ensemble de catégories. Les documents et les enregistrements sont affectés à ces catégories selon qu'ils contiennent ou non une partie de la définition de catégorie. Vous pouvez gérer des catégories dans l'onglet Catégories .
- Ressources
- Le processus d'extraction s'appuie sur un ensemble de paramètres et de définitions provenant de ressources linguistiques pour régir la façon dont le texte est extrait et traité. Vous pouvez régler ces ressources linguistiques (telles que les modèles et les bibliothèques) dans l'onglet Éditeur de ressources.
Vous pouvez utiliser l'atelier pour effectuer les tâches de text mining suivantes :
- Extraire des concepts clés de vos données texte
- Créer des catégories
- Explorer les motifs dans l'analyse des liens du texte (TLA)
- Générer des nuggets de modèle de catégories
- Enregistrez les ressources que vous avez accordées ou utilisées au cours du processus d'extraction en tant que package d'analyse de texte (TAP).