Go back to the English version of the documentation"资源编辑器" 选项卡
"资源编辑器" 选项卡 (SPSS Modeler)
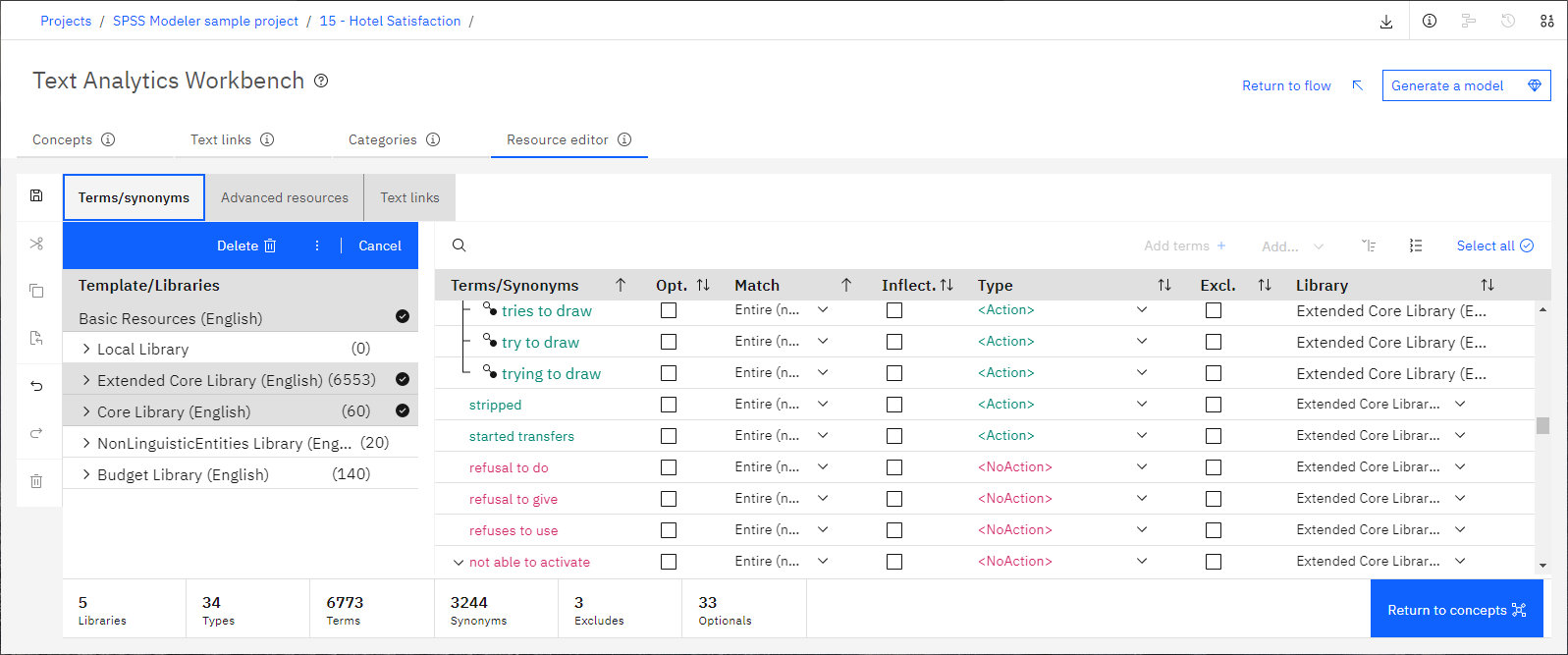
图 1。 "资源编辑器" 选项卡
Last updated: 2024年11月22日
Text Analytics 使用抽取过程快速准确地从文本数据中捕获关键概念。 这一过程依靠语言资源来决定如何分析和解释大量非结构化文本数据。
您可以使用资源编辑器选项卡查看提取过程中使用的语言资源。 这些资源以模板和库的形式存储,这些模板和库用于抽取概念,按类型对它们进行分组,发现文本数据中的模式以及其他过程。 Text Analytics 提供了多个预先配置的资源模板,在某些语言中,您还可以使用文本分析包中的资源。
在 资源编辑器选项卡上,您可以使用术语和类型来确定要从文档中提取的概念。 这些技术术语的定义如下。
- 概念
- 概念是从文本数据中标识和抽取的重要单词和短语。 它们也称为 抽取结果。 这些概念分组到类型。 您可以使用这些概念来浏览数据和创建类别。
- 条款
- 术语是构成概念的特定词。 术语是单词,如
airport或location,以及词组,如airport pick-up。 它们用于识别文本中的概念。 术语可以是词的复数或单数形式,较大词的部分,同义词或拼写变体。 - 类型
- 类型是概念的语义分组。 抽取概念时,会为其分配类型以帮助分组相似概念。 例如,某些缺省类型为
<Location>,<Organization>,<Person>,<Positive>和<Negative>。
您可以使用资源编辑器选项卡自定义和调整语言资源。 您还可以使用这些控件来管理术语与文本数据的匹配方式,并定义文本链接分析 (TLA) 的规则。
术语/同义词窗格
"术语/同义词" 窗格显示在抽取过程中用作语言资源的所有库。 如果要定制如何将特定术语分组到概念中,可以在库中编辑术语。 您还可以向库添加术语。 例如,如果文本数据特定于一个字段或规程,那么可以添加可能缺少的任何技术术语。
定制库和模板
由于这些资源可能并不完全适合您的数据上下文,因此您可以在 资源编辑器选项卡中为特定上下文或域创建和管理自己的资源。
您可以将对库或模板所作的任何更改保存为项目资产,然后可以在其他流中复用这些更改。 您还可以导入定制库或模板,以防您使用本地文件来管理资源。
模糊分组和拐点分组
在分析文本数据时,您可以使用模糊分组和拐点分组技术。 模糊分组技术将常见的拼写错误单词或拼写接近的单词分组,而词根分组技术则根据词根将单词的词根变体分组。
如果您发现在启用这些功能时,拼写相似的两个单词被错误地组合在一起,您可以将这两个单词排除在这些分组技术之外。 您可以将匹配错误的配对添加到 "高级资源"选项卡的 "例外"部分。
注意:处理日文文本数据时,不能使用模糊分组和语气分组技术。 书面日语的语法功能(如数字和性别)依赖于上下文,因此尽管单词的用途不同,但其形式往往相同。 因此,这种技术无法有效发挥作用。