Text Analytics capture rapidement et précisément des concepts clés à partir de données texte à l'aide d'un processus d'extraction. Ce processus s'appuie sur des ressources linguistiques pour dicter la manière dont de grandes quantités de données textuelles non structurées sont analysées et interprétées.
Vous pouvez utiliser l'onglet Éditeur de ressources pour visualiser les ressources linguistiques utilisées dans le processus d'extraction. Ces ressources sont stockées sous la forme de modèles et de bibliothèques, qui sont utilisés pour extraire des concepts, les regrouper sous des types, reconnaître des motifs dans les données texte et d'autres processus. Text Analytics offre plusieurs modèles de ressources préconfigurés et, dans certaines langues, vous pouvez également utiliser les ressources dans des packs d'analyse de texte.
Dans l'onglet Éditeur de ressources, vous travaillez avec des termes et des types pour identifier les concepts à extraire d'un document. Ces termes techniques sont définis comme suit.
- Concepts
- Les concepts sont des mots et des phrases importants qui ont été identifiés et extraits de vos données textuelles. Ils sont également appelés résultats d'extraction. Ces concepts sont regroupés en types. Vous pouvez utiliser ces concepts pour explorer vos données et créer vos catégories.
- Termes
- Les termes sont les mots spécifiques qui composent un concept. Les termes sont des mots simples tels que
airportoulocationet des groupes de mots tels queairport pick-up. Ils servent à identifier des concepts dans le texte. Les termes peuvent être des formes plurielles ou singulières de mots, des parties de mots plus grands, des synonymes ou des variations orthographiques. - Types
- Les types sont des regroupements sémantiques de concepts. Quand les concepts sont extraits, un type leur est affecté pour regrouper les concepts similaires. Par exemple, certains des types par défaut sont
<Location>,<Organization>,<Person>,<Positive>et<Negative>.
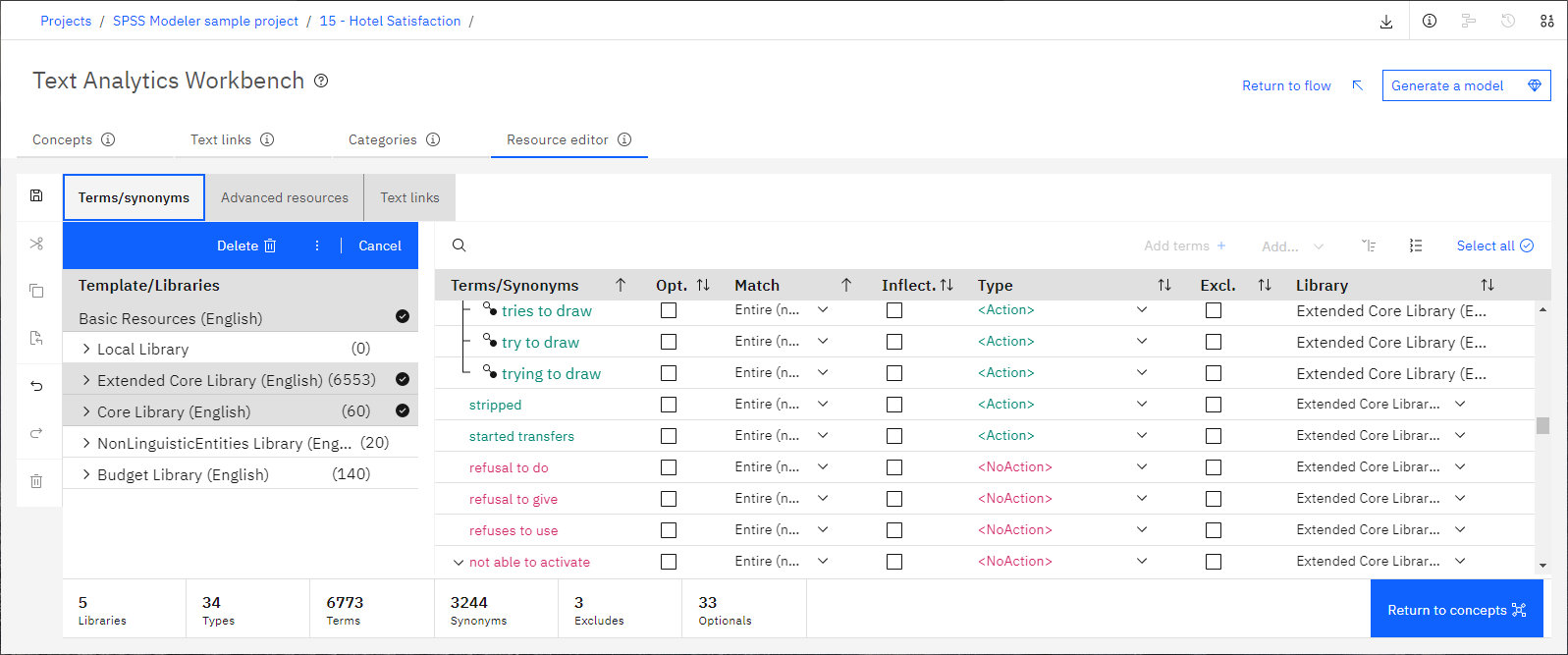
Vous pouvez utiliser l'onglet Éditeur de ressources pour personnaliser et ajuster les ressources linguistiques. Vous pouvez également utiliser les contrôles pour gérer la façon dont les termes sont mis en correspondance avec les données texte et définir des règles pour l'analyse des liens du texte (TLA).
Sous-fenêtre Termes / synonymes
Le panneau Termes / synonymes affiche toutes les bibliothèques utilisées en tant que ressources linguistiques lors du processus d'extraction. Si vous souhaitez personnaliser la façon dont les termes spécifiques sont regroupés en concepts, vous pouvez éditer les termes dans les bibliothèques. Vous pouvez également ajouter des termes aux bibliothèques. Par exemple, si vos données textuelles sont spécifiques à un champ ou à une discipline, vous pouvez ajouter des termes techniques qui peuvent être manquants.
Bibliothèques et modèles personnalisés
Comme ces ressources peuvent ne pas correspondre parfaitement au contexte de vos données, vous pouvez créer et gérer vos propres ressources pour un contexte ou un domaine particulier dans l'onglet Éditeur de ressources.
Vous pouvez sauvegarder les modifications que vous apportez à une bibliothèque ou à un canevas en tant qu'actif de projet, que vous pouvez ensuite réutiliser dans d'autres flux. Vous pouvez également importer des bibliothèques ou des modèles personnalisés si vous gérez vos ressources à l'aide de fichiers locaux.
Regroupement flou et regroupement par inflexion
Vous pouvez utiliser les techniques de regroupement flou et de regroupement par inflexion lors de l'analyse de données textuelles. La technique de regroupement flou regroupe les mots communément mal orthographiés ou les mots à l'orthographe proche, et la technique de regroupement de l'inflexion regroupe les variantes infléchies des mots sur la base de la racine.
Si vous constatez que deux mots à l'orthographe similaire sont regroupés de manière incorrecte lorsque vous activez ces fonctions, vous pouvez exclure ces mots de ces techniques de regroupement. Vous pouvez ajouter les paires incorrectement appariées dans la section Exceptions de l'onglet Ressources avancées.