“评估”节点为您提供了一个评估并比较预测模型,以选择最适合模型的便捷方法。 评估图表显示模型在预测特定结果方面的性能。 评估图表的工作原理是:根据预测值及预测的置信度排序记录、将记录分割为大小相等的组(分位数)并按由高到低顺序为每个分位数绘制业务标准值。 在点线图中,将以单独的线条显示多个模型。
通过将具体值或值的范围定义为匹配来处理结果。 通常,匹配表示相关的某类别(如向顾客销售)或某事件(如某项医疗诊断)成功执行。 您可以在节点属性的选项部分下定义匹配标准,或使用以下描述的缺省匹配标准:
- 标志输出字段是正向的,即匹配表现为 true 值。
- 对于名义输出字段,集合中的第一个值确定是否匹配。
- 对于连续输出字段,大于字段范围中点的值即为匹配。
有六种类型的评估图表,每一种类型侧重于不同的评估标准。
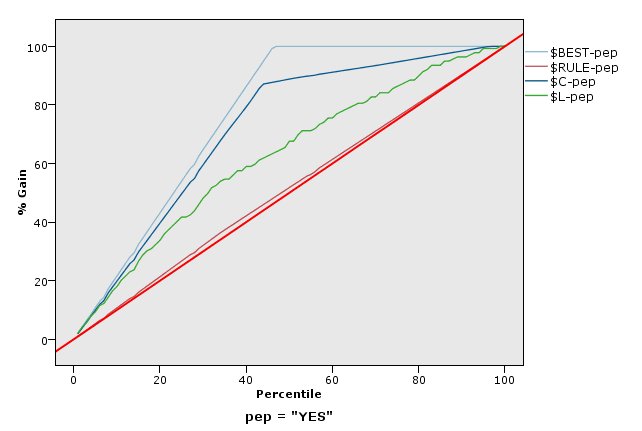
增益图
收益的定义是相对于全部匹配,发生于每个分位数中的匹配的百分比。 增益计算为 (number of hits in quantile / total number of hits) ×
100%。
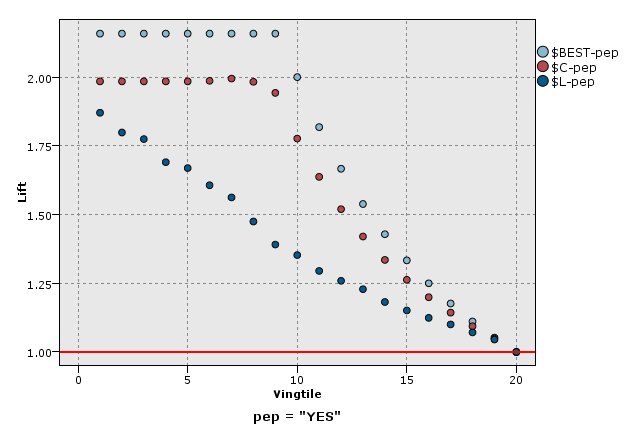
提升图
提升将每个分位数中匹配记录的百分比与在训练数据中匹配的总体百分比进行比较。 计算方法为 (hits in quantile /
records in quantile) / (total hits / total records)。
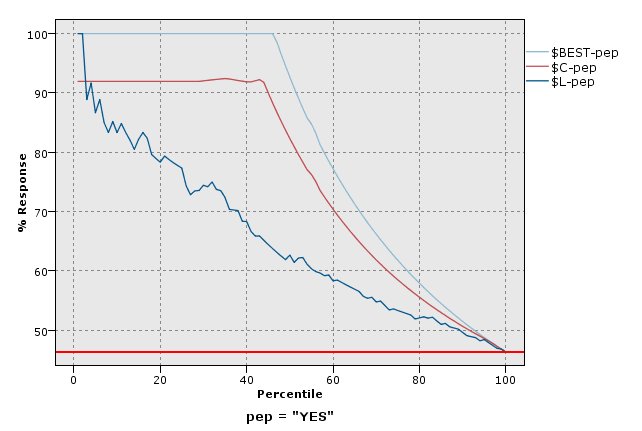
响应图
响应即分位数中匹配记录的比例。 响应计算方式为 (hits in quantile / records in quantile) × 100%。
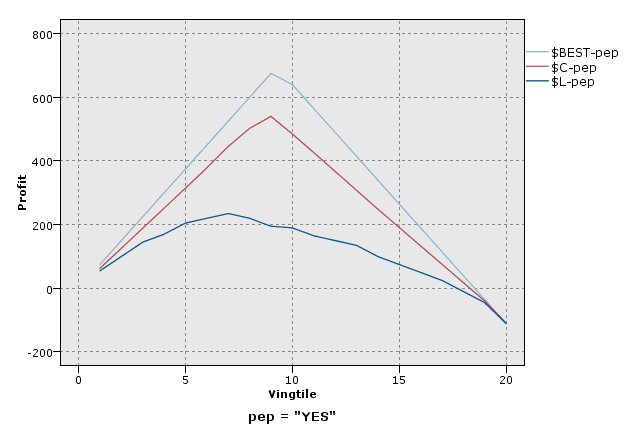
利润图
利润等于每个记录的收入减去该记录的成本。 也就是说,分位数的利润就是位于该分位数内的所有记录的利润总和。 这里假定收入仅应用于匹配项,但成本可应用于所有的记录。 利润及成本都可以是固定的,也可以由数据中的字段决定。 利润计算方式为 (sum of revenue for records in quantile − sum of costs for records in
quantile)。
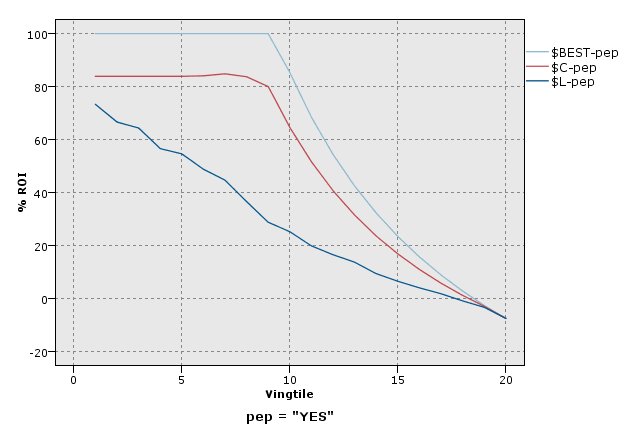
投资回报率图
投资回报 (ROI) 也需要确定收入和成本,从这一点上来说,它与利润相同。 ROI 将分位数的成本和利润进行比较。 ROI 计算为 (profits for quantile / costs for quantile) × 100%。
ROC 图表
只能将 ROC(受试者工作特征)与二元分类器配合使用。 ROC 可用于根据性能显示、组织和选择分类器。 ROC 图表绘制分类器的真阳性率(或灵敏度)与假阳性率的比率。 ROC 图表描述了收益(真阳性)与成本(假阳性)之间的相对平衡。 真阳性是一个匹配实例,并且分类为匹配项。 因此,真阳性率按照真阳性数/实际匹配的实例数进行计算。 假阳性是一个未匹配实例,并且分类为匹配项。 因此,假阳性率按照假阳性数/实际未匹配的实例数进行计算。
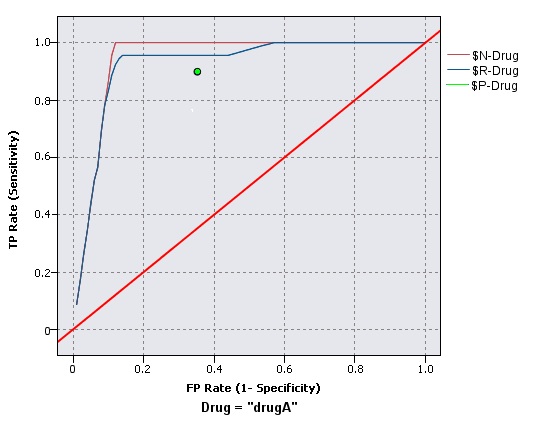
评估图表也可以累积,因此每个点等于相应分位数的值加上所有更高分位数的值。 累积图表通常能够更好地表现模型性能,而非累积图则更有利于指出模型中可能存在问题的地方。