Translation not up to date
Węzła importu zasobów danych można użyć do pobrania danych ze zdalnych źródeł danych za pomocą połączeń lub z komputera lokalnego. Najpierw należy utworzyć połączenie.
Uwaga: w przypadku połączeń z bazą danych Planning Analytics należy wybrać widok (nie kostka).
Można również pobrać dane z lokalnego pliku danych (obsługiwane są następujące opcje:.csv, .txt, .json, .xls, .xlsx, .savi .sas ). Tylko pierwszy arkusz jest importowany z arkuszy kalkulacyjnych. W obszarze właściwości węzła, w sekcji DATA, wybierz jeden lub więcej plików danych do przesłania. Możesz także po prostu przeciągnąć plik danych z lokalnego systemu plików na kanwę.
Ustawianie opcji formatu danych
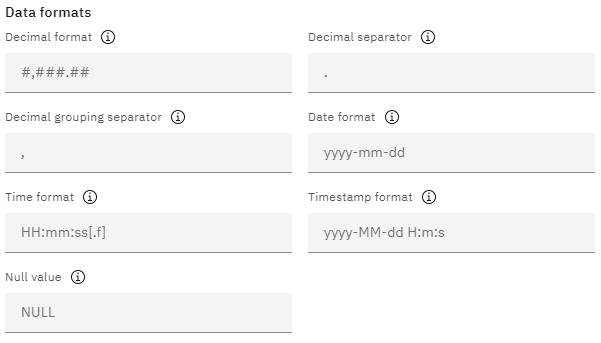
Importowanie danych z pliku SPSS Statistics
Jeśli importowane są dane z pliku SPSS Statistics (.sav), dostępne są następujące opcje:
- Odczytaj nazwy i etykiety. Wybierz tę opcję, aby odczytywać nazwy zmiennych i etykiety w programie SPSS Modeler. Jest to opcja domyślna, a nazwy zmiennych są wyświetlane w węźle Typ. Etykiety mogą być wyświetlane na wykresach, w przeglądarkach modeli i w innych typach danych wyjściowych. Domyślnie opcja wyświetlania etykiet w wynikach jest wyłączona.
- Odczytaj etykiety jako nazwy. Tę opcję należy wybrać, aby odczytywać opisowe etykiety zmiennych z pliku SPSS Statistics .sav , a nie nazwy krótkich pól, i używać tych etykiet jako nazw zmiennych w programie SPSS Modeler.
- Odczytaj dane i etykiety. Wybierz tę opcję, aby odczytywać zarówno wartości rzeczywiste, jak i etykiety wartości w programie SPSS Modeler. Jest to opcja domyślna, a same wartości są wyświetlane w węźle Typ. Etykiety wartości mogą być wyświetlane w konstruktorze wyrażeń, na wykresach, w przeglądarkach modeli i w innych typach danych wyjściowych.
- Odczytaj etykiety jako dane. Tę opcję należy wybrać, jeśli etykiety wartości mają być używane z pliku .sav , a nie z kodami numerycznymi lub symbolicznymi, które są używane do reprezentowania wartości. Na przykład wybranie tej opcji dla danych z polem płci, którego wartości
1i2faktycznie reprezentują odpowiednio mężczyzna i kobieta, przekształcą pole w łańcuch i zaimportuje wartościmaleifemalejako wartości rzeczywiste.Przed wybraniem tej opcji należy wziąć pod uwagę brakujące wartości danych w danych SPSS Statistics . Na przykład, jeśli pole liczbowe używa etykiet tylko dla brakujących wartości (
0= Brak odpowiedzi,–99= Nieznany), wówczas wybranie opcji Odczytaj etykiety jako dane zaimportuje tylko etykiety wartości Brak odpowiedzi i Nieznane i przekształci pole w łańcuch. W takich przypadkach należy importować same wartości i ustawić braki danych w węźle typu.
Użyj informacji o formacie zmiennej w celu wymuszenia typu składowania. W przypadku anulowania wyboru tej opcji wartości pól sformatowane w pliku .sav jako liczby całkowite (tzn. pola określone jako Fn.0 w widoku Zmienne w programie IBM SPSS Statistics) są importowane przy użyciu pamięci całkowitej. Wszystkie pozostałe wartości zmiennych, z wyjątkiem łańcuchów, są importowane jako liczby rzeczywiste.
Jeśli zostanie wybrana ta opcja (wartość domyślna), wszystkie wartości pól z wyjątkiem łańcuchów są importowane jako liczby rzeczywiste, niezależnie od tego, czy są one sformatowane w pliku .sav jako liczby całkowite, czy nie.
Odczyt datownika jako daty. Domyślnie wszystkie wartości znacznika czasu są wyświetlane jako daty. Anuluj wybór tej opcji, aby przesłonić to zachowanie.
Pobieranie danych za pomocą kodu SQL
SELECT w celu pobrania wierszy lub kolumn danych z bazy danych. Należy zauważyć, że pole Ścieżka źródłowa nie ma zastosowania, jeśli używany jest tryb SQL Query .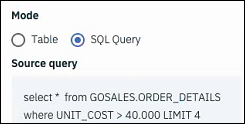
select * from GOSALES.ORDER_DETAILS
where UNIT_COST > 40,000 LIMIT 4select QUANTITY, UNIT_COST, UNIT_PRICE from GOSALES.ORDER_DETAILSselect "Age", "Sex" from testuser.canvas_drugTa funkcja SQL powinna być używana tylko do pobierania danych. Należy zachować ostrożność, aby nie manipulować danymi w bazie danych.
- Amazon Redshift
- Apache Hive
- Cloudera Impala
- Compose for PostgreSQL
- Db2 on Cloud
- Db2 Warehouse
- Google BigQuery
- Informix
- Microsoft SQL Server
- MySQL
- Netezza
- Oracle
- Pivotal Greenplum
- Salesforce.com
- Snowflake
- SAP ASE
- SAP IQ
- Teradata