Data Asset node
You can use the Data Asset node to pull in data from remote data sources that use connections or from your local computer. First, you must create the connection.
Note for connections to a Planning Analytics database, you must choose a view (not a cube).
You can also pull in data from a local data file (.csv, .txt, .json, .xls, .xlsx, .sav, and .sas are supported). Only the first sheet is imported from spreadsheets. In the node's properties, under DATA, select one or more data files to upload. You can also drag-and-drop the data file from your local file system onto your canvas.
Setting data format options
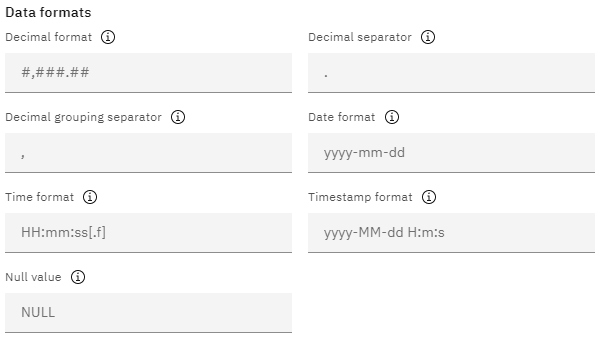
Inferring data structure
SPSS Modeler processes a sample of the records in the data to infer the structure of the data and the types of data. Adjust the number for Infer record count if the first 1000 records are not a good sample for the number of records that you have. Sometimes, SPSS Modeler can make incorrect inferences about the structure of the data. For more information, see Troubleshooting SPSS Modeler.
Importing data from an SPSS Statistics file
If you import data from an SPSS Statistics file (.sav), the following options are available:
- Read names and labels. Select to read both variable names and labels into SPSS Modeler. This option is enabled by default, and variable names are displayed in the Type node. Labels are displayed in charts, model browsers, and other types of output. By default, the display of labels in output is disabled.
- Read labels as names. Select to read the descriptive variable labels from the SPSS Statistics .sav file rather than the short field names, and use these labels as variable names in SPSS Modeler.
- Read data and labels. Select to read both actual values and value labels into SPSS Modeler. This option is enabled by default, and the values themselves are displayed in the Type node. Value labels are displayed in the Expression Builder, charts, model browsers, and other types of output.
- Read labels as data. Select if you want to use the value labels from the
.sav file rather than the numerical or symbolic codes that are used to
represent the values. For example, selecting this option for data with a gender field whose values
of
12malefemaleIt's important to consider missing values in your SPSS Statistics data before you select this option. For example, if a numeric field uses labels only for missing values (
0–99
Use field format information to determine storage. If you deselect this option, field values that are formatted in the .sav file as integers (such as fields that are specified as Fn.0 in the Variable View in IBM SPSS Statistics) are imported using integer storage. All other field values except strings are imported as real numbers.
If you select this option (default), all field values except strings are imported as real numbers, whether formatted in the .sav file as integers or not.
Read timestamp as date. By default, all timestamp values are shown as dates. Deselect this option to override this behavior.
Using SQL to pull in data
SELECT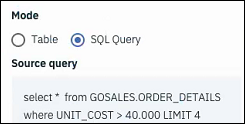
select * from GOSALES.ORDER_DETAILS where UNIT_COST > 40,000 LIMIT 4
select QUANTITY, UNIT_COST, UNIT_PRICE from GOSALES.ORDER_DETAILS
select "Age", "Sex" from testuser.canvas_drug
This SQL feature should only be used to pull in data. Use caution so as not to manipulate the data in your database.
- Amazon Redshift
- Apache Hive
- Apache Impala
- Compose for PostgreSQL
- Db2 on Cloud
- Db2 Warehouse
- Google BigQuery
- Informix
- Microsoft SQL Server
- MySQL
- Netezza
- Oracle
- Pivotal Greenplum
- Salesforce.com
- Snowflake
- SAP ASE
- SAP IQ
- Teradata