Translation not up to date
V důsledku vývoje společnosti IBM a inspirovaných přirozeným výběrem v biologii je pro uzel Automatického klasifikátoru a Automatický numerický uzel k dispozici učení se stálým strojem .
Nepříjemnosti při modelování jsou modely se zastaralými díky změnám vašich dat v čase. To se obvykle označuje jako posun modelu nebo posun koncepce. Produkt SPSS Modeler poskytuje nepřetržité automatické učení se strojem, aby bylo možné efektivně překonat úlet modelu.
Co je modelový posun? Když sestavujete model založený na historických datech, může se stát stagnujícím. V mnoha případech se nová data vždy blíží-nové variace, nové vzory, nové trendy atd.-, že stará historická data nezachytí. K vyřešení tohoto problému se IBM inspirovala slavným jevem v biologii označeným jako přirozený výběr druhů. Představte si modelky jako druh a mysli na data jako přírodu. Stejně jako příroda vybírá druhy, měli bychom nechat data vybrat model. Mezi modelkami a druhy je jeden velký rozdíl: druhy se mohou vyvíjet, ale modely jsou statické po jejich výstavbě.
Existují dva předpoklady pro druhy, které se vyvíjejí; první je genová mutace, a druhá je populace. Nyní, z pohledu modelování, abychom splnili první předběžnou podmínku (genová mutace), bychom měli zavést nové změny dat do stávajícího modelu. Abychom uspokojili druhou předběžnou podmínku (počet obyvatel), měli bychom používat spíše určitý počet modelů než jen jeden. Co může představovat počet modelů? Sada modelů kompletu (EMS)!
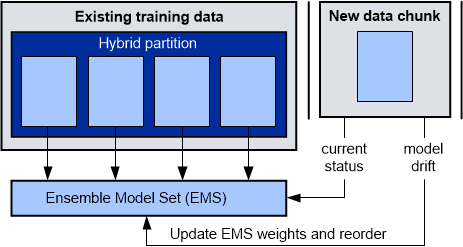
Následující obrázek ukazuje, jak se může EMS vyvíjet. Horní levá část tohoto obrázku reprezentuje historická data s hybridními oblastmi. Hybridní logické části zajišťují bohaté počáteční EMS. Horní pravá část obrázku představuje nový diskový blok dat, který bude k dispozici, se svislými pruhy na každé straně. Levý svislý pruh představuje aktuální stav a pravý svislý pruh je ve stavu, kdy existuje riziko úletu modelu. V každém novém kole celoživotního učení se provedou dva kroky k vývoji vašeho modelu a k zamezení posunu modelu.
Nejprve vytvoříte sadu modelu kompletu (EMS) s použitím existujících údajů o školení. Poté, co bude k dispozici nový diskový blok dat, jsou nové modely postaveny na nových datech a přidány do EMS jako modely komponent. Váhy existujících modelů komponent v EMS se znovu vyhodnotí s použitím nových dat. Výsledkem tohoto přehodnocení je, že modely komponent s vyššími váhami jsou vybrány pro aktuální předpověď, a modely komponent s nižšími váhou mohou být z EMS odstraněny. Tento proces aktualizuje EMS pro obě váhy modelu a instance modelu, čímž se vyvíjí pružným a účinným způsobem, jak řešit nevyhnutelné změny vašich dat v průběhu času.
Sada modelů modelu (EMS) je generovanou automaticky modelem nugget a existuje odkaz na aktualizaci mezi uzlem automatického modelování a vygenerovaným automatickým modelem nuget, který definuje vztah mezi nimi. Když povolíte průběžné učení automatického počítače, jsou nová data aktiv nepřetržitě krmena do uzlů automatického modelování, aby se vygenerovaly nové modely komponent. Model nugget je aktualizován namísto nahrazení.
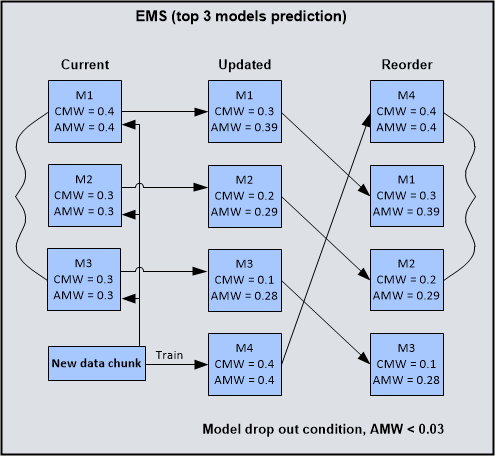
Následující obrázek uvádí příklad vnitřní struktury EMS ve scénáři se stálým studiem počítače. Pro aktuální předpověď jsou vybrány pouze první tři modely komponent. Pro každý model komponenty (označený jako M1, M2a M3) se udržují dva druhy vah. Aktuální váha modelu (CMW) popisuje, jak se model komponenty provádí s novým blokem dat a Akumulovaná váha modelu (AMW) popisuje souhrnný výkon modelu komponenty proti nedávným diskovým blokům dat. AMW je vypočítáno iterativně přes CMW a předchozí hodnoty samotné, a je zde hyperparametr beta k rovnováze mezi nimi. Vzorec pro výpočet AMW se nazývá exponenciální klouzavý průměr.
Jakmile bude k dispozici nový diskový blok dat, produkt SPSS Modeler jej použije k sestavení několika nových modelů komponent. V tomto příkladu je model 4 (M4) sestaven s CMW a AMW vypočítaným během počátečního procesu sestavení modelu. Poté produkt SPSS Modeler použije nový blok dat k přelacování ukazatelů existujících modelů komponent (M1, M2a M3) a aktualizují jejich CMW a AMW na základě výsledků opětovného vyhodnocení. Nakonec produkt SPSS Modeler může přeskupit modely komponent na základě CMW nebo AMW a podle toho vybrat nejlepší tři modely komponent.
Na tomto obrázku se CMW popisuje pomocí normalizované hodnoty (sum = 1) a AMW je vypočítáno na základě CMW. V produktu SPSS Modelerje zvolena absolutní hodnota (rovná se zvolenému hodnotového měřítka-například přesnost) pro znázornění CMW a AMW pro zjednodušení.
- Aktuální váha modelu (CMW) se vypočítá přes vyhodnocení nového datového bloku (například přesnost vyhodnocení na novém diskovém bloku).
- Akumulovaná váha modelu (AMW) se vypočítá pomocí kombinace CMW i existujícího AMW (například exponenciálně vážený klouzavý průměr (EWMA).
Exponenciální klouzavý průměr vzorce pro výpočet AMW:
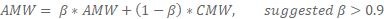
V produktu SPSS Modelerjsou po spuštění uzlu s automatickým klasifikacemi k vygenerování modelu nugget k dispozici následující volby modelu pro průběžné učení se strojem:
- Povolit nepřetržité učení automatického počítače během obnovy modelu. Vyberte tuto volbu, chcete-li povolit průběžné učení počítače. Mějte na paměti, že konzistentní metadata (datový model) musí být použita pro zajištění plynulého automatického modelu. Vyberete-li tuto volbu, budou povoleny další volby.
- Povolit opětovné vyhodnocení vah pro automatické modelování. Tato volba určuje, zda se při aktualizaci modelu vypočítávají a aktualizují vyhodnocovací ukazatele (přesnost, například). Vyberete-li tuto volbu, bude proces automatického vyhodnocení spuštěn po serveru EMS (během aktualizace modelu). Důvodem je obvykle to, že je obvykle nutné znovu vyhodnotit existující modely komponent pomocí nových dat, aby odrážely aktuální stav vašich dat. Váhy modelů komponent EMS se pak přiřazují podle výsledků opětovného vyhodnocení a váhy se používají při rozhodování o podílu, který model komponent přispívá k finální předpovědi kompletu. Tato volba je ve výchozí nastavení vybrána.
Obrázek 3. Nastavení modelu 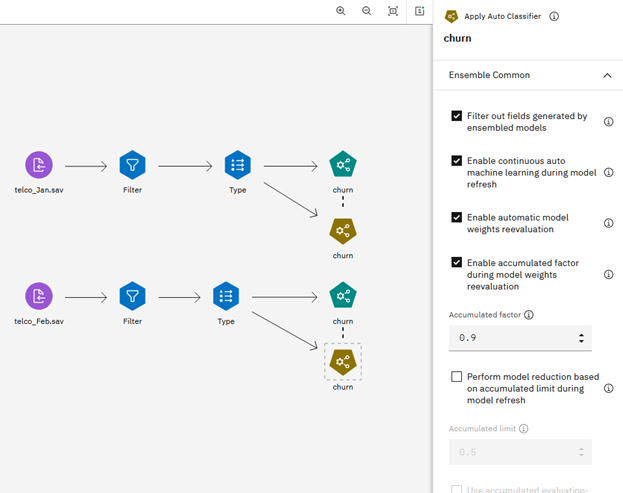
Obrázek 4. Označit cíl příznakem 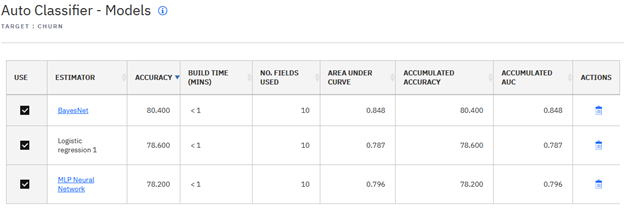 Následující jsou podporované CMW a AMW pro uzel Automatického klasifikátoru:
Následující jsou podporované CMW a AMW pro uzel Automatického klasifikátoru:Tabulka 1. Podporované CMW a AMW Typ cíle CMW AMP cíl příznaku Celková přesnost
Plocha pod křivkouSouhrnná přesnost
Akumulovaná AUCnastavit cíl Celková přesnost Souhrnná přesnost Následující tři volby souvisejí s AMW, který se používá k vyhodnocení, jak se provádí model komponenty během posledních období datových diskových bloků:
- Povolit souhrnný faktor během opětovného vyhodnocení vah modelu. Vyberete-li tuto volbu, bude výpočet AMW povolen během přehodnocení vah modelu. AMW představuje souhrnný výkon modelu komponenty EMS během posledních období datových diskových bloků, souvisejících s akumulovaným faktorem β definovaným ve vzorci AMW, který je již dříve uveden a který je možné upravit ve vlastnostech uzlu. Není-li tato volba vybrána, bude vypočten pouze CMW. Tato volba je ve výchozí nastavení vybrána.
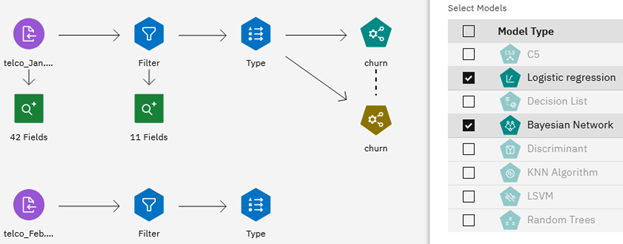
- Provedení redukce modelu na základě akumulovaného limitu během aktualizace modelu. Vyberte tuto volbu, chcete-li, aby byly modely komponent s hodnotou AMW pod zadaným limitem odebrány z automatického modelu EMS během aktualizace modelu. To může být užitečné při vyřazování modelů komponent, které nejsou k ničemu, aby se zabránilo příliš velkému množství automatického modelu EMS.Vyhodnocení akumulovaného limitu se vztahuje k váženému ukazateli, který se používá, když je jako metoda kompletu vybrána volba Hodnocení-vážené hlasování . Viz následující.
Obrázek 5. Nastavit a označit cíle 
Všimněte si, že pokud vyberete volbu Přesnost modelu pro hodnocení s váženými ukazateli, budou odstraněny modely s akumulovanou přesností pod uvedeným limitem. Pokud vyberete volbu Plocha pod křivkou pro vyhodnocuné měřítko, budou odstraněny modely s akumulovanou hodnotou AUC pod uvedeným limitem.
Standardně se Přesnost modelu používá pro ukazatel s váhou vyhodnocení pro uzel Automatického klasifikátoru a v případě cílů příznaku je volitelné hodnota AUC ROC.
- Použít akumulované hlasování-vážené hlasování. Vyberte tuto volbu, pokud chcete, aby se AMW použilo pro aktuální výsledku/předpověď. Jinak bude CMW při výchozím nastavení použit. Tato volba je povolena, když je vybrána volba Hodnocení-vážené hlasování pro metodu kompletu.
Všimněte si, že pro cíle parametrů vyberte tuto volbu, pokud vyberete Přesnost modelu pro vyhodno-vážený ukazatel, pak bude jako AMW použita volba Akumulovaná přesnost pro provedení aktuálního skóre. Nebo vyberete-li hodnotu Plocha pod křivkou pro hodnocení-vážený ukazatel, použije se Akumulovaná hodnota AUC jako AMW k provedení aktuálního skóre. Pokud tuto volbu nevyberete a vyberete Přesnost modelu pro vážený ukazatel hodnocení, bude jako CMW použita hodnota Celková přesnost k provedení aktuálního skóre. If you select Plocha pod křivkou, Plocha pod křivkou will be used as the CMW to perform the current scoring.
Chcete-li nastavit cíle, vyberete-li tuto volbu Použít akumulované hlasování-vážené hlasování , bude jako AMW použita volba Akumulovaná přesnost k provedení aktuálního skóre. Jinak se jako CMW použije Celková přesnost k provedení aktuálního skóre.
S nepřetržitým automatickým strojním zařízením se automaticky model nugget neustále vyvíjí přestavením automodelu, který zajišťuje, že získáte nejnovější verzi odrážející aktuální stav vašich dat. Produkt SPSS Modeler nabízí flexibilitu pro různé špičkové modely komponent N v EMS, které mají být vybrány podle jejich aktuálních vah, což udržuje krok s různými daty během různých období.
Příklad
V tomto příkladu se v odvětví telekomunikací používá nepřetržité učení se strojem k předpovídání chování a udržení zákazníků.
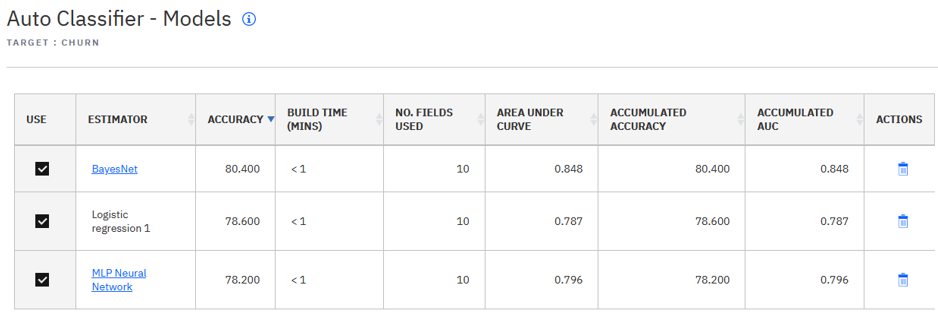
V následujícím toku datové aktivum obsahuje informace o zákaznících, kteří odešli za poslední měsíc (sloupecChurn ). Vzhledem k tomu, že nové údaje budou k dispozici každý měsíc, tento scénář je vhodný pro nepřetržité učení stroje. V tomto příkladu se data z ledna (Jan) používají ke konstrukci počátečního automatického modelu a pak se data z února (Feb) používají ke zlepšení automatického modelu pomocí nepřetržité výuky počítače.
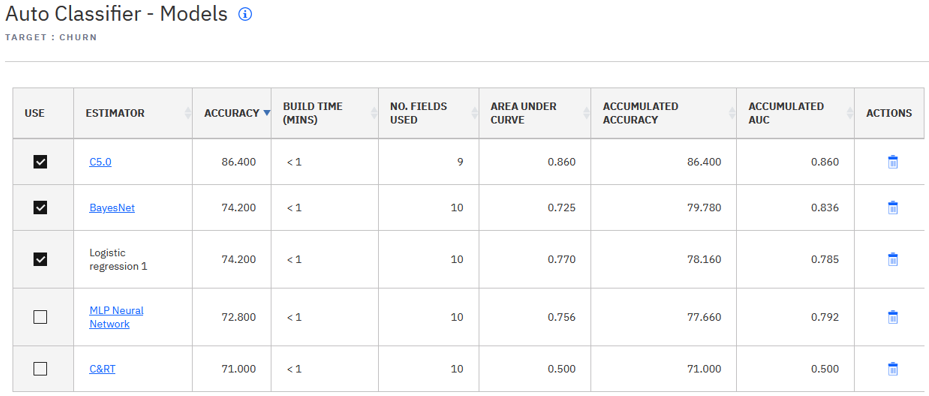
Teď se podívejme na to, co je uvnitř toho auta, co je to auto. Můžeme vidět, že obsahuje tři modely komponent pro tři algoritmy, které jsme vybrali. Pro každý model komponenty je generováno několik vyhodnocovacích ukazatelů (například přesnost a plocha pod křivkou). Tato hodnotící opatření popisují, jak model komponenty pracuje s daty odborné přípravy (datová sada leden). Můžete vybrat modely komponent, které se mají použít v aktuální předpovědi kompletu.
Může se také zobrazit souhrnná hodnotící opatření. Tato akumulovaná opatření jsou určena pro nepřetržité vzdělávání strojů, neboť popisují, jak se model komponenty provádí s posledními změnami dat, takže jste si vědomi celkového výkonu modelu v určitém časovém úseku. Vzhledem k tomu, že se jedná o náš počáteční model aut, vidíme, že počáteční hodnoty pro akumulovaná měřítka jsou stejné jako související aktuální ukazatele. Ve výchozím nastavení jsou vyhodnocovací opatření počítána proti údajům o výcviku, takže by mohl existovat určitý stupeň nadstavby. Aby se tomu zabránilo, uzel Automatického klasifikátoru poskytuje volbu sestavení, která vypočítá stabilnější vyhodnocovací ukazatele přes křížovou validaci.
Dále se podívejme na to, jak je generována konečná prognóza kompletu. Pokud otevřeme vlastnosti modelu automatického modelu, v části Cíle příznaku kompletuje cílové pole výškolování cíle ano/ne. V části Cíle nastavení kompletu (pro nastavení cílových polí, které obsahují více než dvě hodnoty), je rozevírací seznam Metoda kompletu . V rozevírací nabídce je k dispozici několik možností (například Většinové hlasování znamená, že každý model komponenty má jeden tiket k hlasování a Hlasování vážené váženými hlasy znamená, že pole Důvěry pro každou prognózu modelu komponenty se používá jako váhu hlasování-s vyšší důvěrou, která má větší vliv na predikci konečného kompletu). Podobně, aby bylo možné lépe podporovat nepřetržité učení se stroji, je k dispozici Ohodnocení-vážené hlasování , aby bylo jako hlasovací váha použito hodnocení modelu komponenty (například přesnost modelu nebo plocha pod křivkou). V případě cíle vlajky je také možnost vybrat konkrétní hodnotící opatření jako váhu při hlasování, je-li použita volba Hodnocení-vážené hlasování . V případě cíle sady je momentálně podporována pouze Přesnost .
Pod nastavením Ensemble Common můžete zapnout průběžné učení počítače. Potom můžeme použít data z února, abychom zjistili, co se děje. Můžeme zvolit dva různé algoritmy pro rozlišení mezi existujícími algoritmy modelu komponenty. Poté, co znovu sestavíte tok a zobrazíte obsah automatického modelu, vidíme, že jsou přidány dva nové modely komponent (C5 a C & RT). Všimli jsme si také, že byla přepočítána vyhodnocovací opatření pro stávající modely součástí. Opatření CMW i opatření AMW jsou jiná než dříve. Nyní je můžeme porovnat s odpovídajícími ukazateli v původním automatickém modelu.
Nyní co? Díky rozšířenému automatickému modelu můžeme vybrat hodnotící ukazatel s prioritou a získat modely komponent typu top-N uspořádané podle tohoto ukazatele. Poté můžeme použít modely komponent top-N k účasti v konečné předpovědi pro příchozí prediktivní analýzy požadavků. Je-li pro volbu Metoda kompletuvybrána volba Hodnocení-vážené hlasování , můžeme použít akumulovaná měřítka jako váhu při hlasování jednoduše výběrem volby Použít akumulované hlasování-vážené hlasování v rámci nastavení Společné komplet . Pokud není vybráno, CMW budou použita při výchozím nastavení při hodnocení vážených hlasů.
Díky neustálému učení se model se neustále vyvíjí neustále, jak se neustále obnovuje s novými bloky dat a zajišťuje, že váš model je nejaktuálnější verzí, která odráží aktuální stav dat. To umožňuje flexibilitu při výběru různých modelů komponent top-N v EMS podle jejich aktuálních nebo akumulovaných vyhodnocovacích ukazatelů, aby bylo možné držet krok s různými daty během různých období.
Pravidelně se můžete rozhodnout, že do produktu Watson Machine Learning automaticky nasadíte model, který je k dispozici pro snadné použití, pravidelně.