Translation not up to date
The translation of this page does not represent the latest version. For the latest updates, see the English version of the documentation.
Last updated: 03 lis 2023
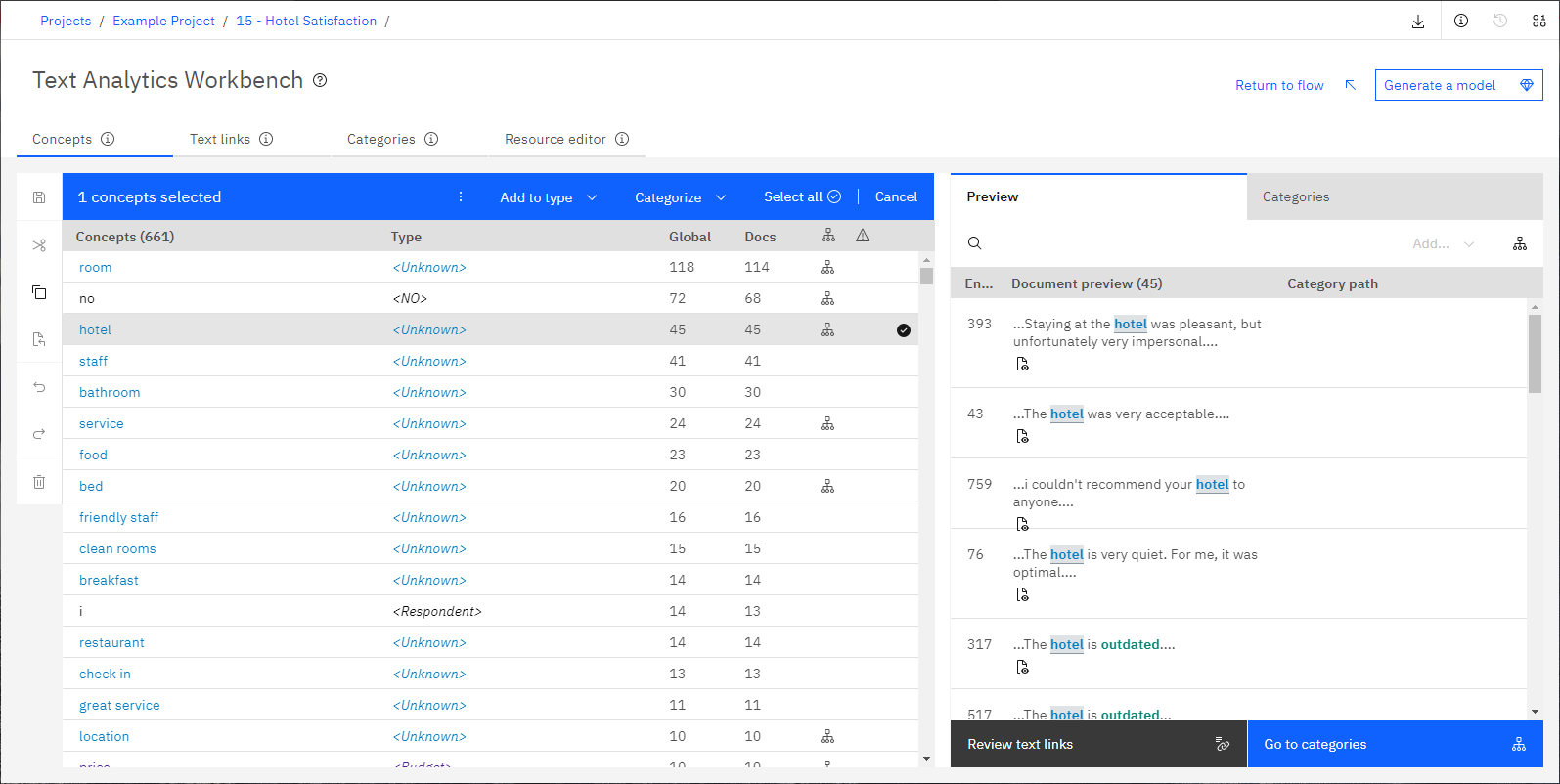
Z poziomu węzła modelowania Text Mining można uruchomić interaktywną sesję środowiska roboczego analizy tekstu po uruchomieniu przepływu. W tym środowisku roboczym można wyodrębniać kluczowe pojęcia z danych tekstowych, budować kategorie, eksplorować wzorce analizy powiązań w tekście i generować modele kategorii.
Ta sekcja zawiera przegląd interfejsu środowiska roboczego analizy tekstu wraz z głównymi elementami, z którymi użytkownik będzie pracować, w tym:
- Pojęcia. Po przeprowadzeniu wyodrębniania są to kluczowe słowa i frazy, które zostały zidentyfikowane i wyodrębnione z danych tekstowych, zwane również wynikami wyodrębniania. Pojęcia te są pogrupowane w typy. Korzystając z tych pojęć i typów, można eksplorować dane i tworzyć kategorie. Są one zarządzane na karcie Pojęcia .
- Odsyłacze tekstowe. Jeśli zasoby lingwistyczne zawierają reguły wzorców powiązań w tekście lub próbujesz używać szablonu zasobów, który zawiera już jakieś reguły TLA, możesz wyodrębniać wzorce z danych tekstowych. Wzorce te pomagają w ujawnianiu interesujących relacji między pojęciami w danych. Można także użyć ich jako deskryptorów w definicjach kategorii. Są one zarządzane na karcie Powiązania tekstowe .
- Kategorie. Korzystając z deskryptorów (takich jak wyniki wyodrębniania, wzorce i reguły) jako definicji, można ręcznie lub automatycznie utworzyć zestaw kategorii, do których będą przypisywane rekordy w zależności od tego, czy zawierają część definicji kategorii, czy nie. Są one zarządzane na karcie Kategorie .
- Zasoby lingwistyczne. Proces wyodrębniania realizowany jest w oparciu o zestaw parametrów i definicji lingwistycznych, które rządzą sposobem wyodrębniania pojęć z tekstu. Są one zarządzane w postaci szablonów i bibliotek na karcie Edytor zasobów .