Translation not up to date
The translation of this page does not represent the latest version. For the latest updates, see the English version of the documentation.
Last updated: 03. 11. 2023
Z uzlu modelování dolování textu můžete zvolit spuštění interaktivní relace pracovní plochy analýzy textu při spuštění toku. Na této pracovní ploše můžete extrahovat klíčové koncepty z textových dat, sestavit kategorie, prozkoumat vzory analýzy textových odkazů a generovat modely kategorií.
Tento oddíl poskytuje přehled rozhraní produktu Text Analytics Workbench spolu s hlavními prvky, s nimiž budete pracovat, včetně:
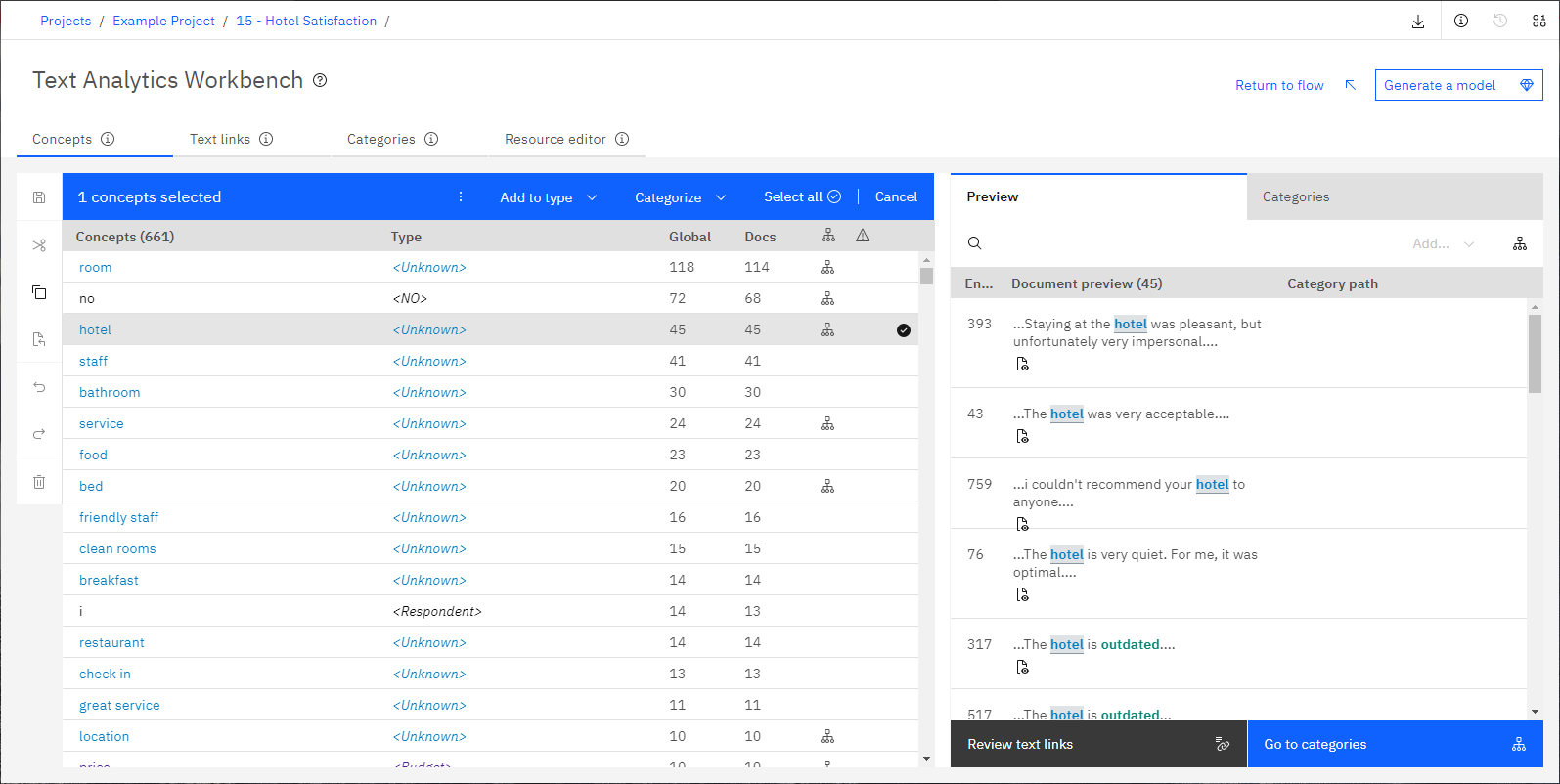
- Koncepce. Po provedení extrakce se jedná o klíčová slova a fráze identifikované a extrahované z textových dat, označované také jako výsledky extrakce. Tyto koncepce jsou seskupeny do typů. Pomocí těchto konceptů a typů můžete zkoumat svá data a vytvářet kategorie. Ty jsou spravovány na kartě Koncepty .
- Textové odkazy. Máte-li ve svých lingvistických prostředcích pravidla pro analýzu textových odkazů (TLA) nebo používáte-li šablonu prostředků, která již obsahuje některá pravidla TLA, můžete extrahovat vzorky z textových dat. Tyto vzory vám mohou pomoci odhalit zajímavé vztahy mezi koncepty ve vašich datech. Tyto vzory můžete také použít jako deskriptory ve svých kategoriích. Ty jsou spravovány na kartě Textové odkazy .
- Kategorie Pomocí deskriptorů (například výsledků extrakce, vzorů a pravidel) jako definice můžete ručně nebo automaticky vytvořit sadu kategorií, ke kterým jsou dokumenty a záznamy přiřazeny na základě toho, zda obsahují část definice kategorie. Ty jsou spravovány na kartě Kategorie .
- Lingvistické prostředky. Proces extrakce se spoléhá na sadu parametrů a lingvistických definic, které řídí způsob extrahování a zpracování textu. Jsou spravovány ve formě šablon a knihoven na kartě Editor prostředků .