Data Virtualizationでサポートされるデータソース
Data Virtualizationは、'IBM Cloud Pak for Data as a Service上の以下のリレーショナルおよび非リレーショナル・データ・ソースをサポートする。
プラットフォーム接続でクラウド統合、 Secure Gateway、または Satellite Linkが使用されている場合、既存のプラットフォーム接続への接続としてデータ・ソースに接続することはできません。 これらの機能は、プラットフォーム接続に接続する場合、Data Virtualizationではサポートされません。 次のようなエラー・メッセージが表示されます。Cannot reach the network destination of the data source.クラウド統合、Secure Gateway、またはSatellite Linkを使用してデータソースをセットアップし、ホスト名または IP エンドポイントを新しい接続としてData Virtualizationに直接提供できます。
- サイズ制限
- Data Virtualizationは、行のサイズが1MBまで、テーブルのカラム数が2048までのテーブルの仮想化をサポートする。 しかし、Data Virtualizationがプレビューできる列の数は、列のデータ型など多くの要因に依存する。 現在、プレビューは 200 列に制限されています。
- コメント属性
- 仮想テーブルが作成されるとき、Data Virtualizationはデータ・ソース・オブジェクトに割り当てられていたコメント属性を含めません。 この制限は、すべてのデータ・ソースに適用されます。
- データ・タイプ
- データソースのデータ型によっては、Data Virtualizationでサポートされていない場合があります。 これらの制限は、以下の表に記載されています。 Data Virtualizationによって、データ・ソースのデータ型が別のデータ型にマッピングされることもある。 これらのマッピングは、基礎となる Db2® Big SQL マッピングに基づいています。 詳しくは、 Db2 Big SQLのデータ・タイプを参照してください。
IBM データ・ソース
次の表は、Data Virtualization から接続できるIBM®データソースの一覧です。
| コネクター | 制限 | 詳細情報 |
|---|---|---|
| IBM Cloud Databases for MongoDB | IBM Cloud Databases for MongoDB はベータ版として使用できます。 Data Virtualizationでは、以下の 'MongoDBデータ型がサポートされている:INT32、INT64、DOUBLE、STRING、BOOLEAN、DATE、BINARY。 |
|
| IBM Cloud Databases for MySQL | ||
| IBM Cloud Databases for PostgreSQL | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| IBM Cloud Object Storage | この接続は、Data Virtualizationにおいて特別な配慮を必要とする。 Data Virtualizationの'IBM Cloud Object Storageへの接続 を参照。 制限事項については、 Data Virtualization化のオブジェクト・ストレージのデータ・ソースを参照。 |
|
| IBM Data Virtualization Manager for z/OS | 接続でクラウド統合、 Secure Gateway、または Satellite Linkが使用されている場合は、 Data Virtualization Manager for z/OS に接続できません。 これらの機能はData Virtualizationではサポートされていない。 以下のようなエラー・メッセージが表示されます。Cannot reach the network destination of the data source. | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| IBM Db2 |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| IBM Db2 Big SQL | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| IBM Db2 for i | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| IBM Db2 for z/OS | ||
| IBM Db2 on Cloud | NCHAR型とNVARCHAR型はData Virtualizationではサポートされていません。 | |
| IBM Db2 Warehouse | ||
| IBM Informix® | INTERVAL、BIGINT、および BIGSERIAL データ型は、Data Virtualizationではサポートされていません。 詳しくは、 JDBC Informix ドライバーを使用するときに例外が発生するを参照してください。 | |
| IBM Netezza Performance Server |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| IBM Planning Analytics |
|
|
| IBM Data Virtualization | 重要 Data Virtualizationインスタンスへの接続を作成しないでください。
|
サード・パーティーのデータ・ソース
次の表は、Data Virtualization から接続できるサードパーティのデータソースの一覧です。
| コネクター | 制限 | 詳細情報 |
|---|---|---|
| Amazon RDS for MySQL |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Amazon RDS for Oracle |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Amazon RDS for PostgreSQL | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| Amazon Redshift | Data Virtualization では、SPATIAL、SKETCH、SUPER の各データ型は CLOB に変換されます。 | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Amazon S3 | この接続Data Virtualization特において別な配慮を必要とする。は Amazon S3 に接続する Data Virtualization を参照してください。
|
|
| Apache Derby | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| Apache Hive |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Ceph | この接続Data Virtualization特において別な配慮を必要とする。は Cephへの接続 Data Virtualization を参照してください。 制限については、 オブジェクトストレージ内のデータソース Data Virtualization をご覧ください。 |
|
| Apache Impala | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| 汎用 S3 | 制限については、 オブジェクトストレージ内のデータソース Data Virtualization をご覧ください。 |
|
| Google BigQuery | この接続Data Virtualization特において別な配慮を必要とする。は Google BigQuery に接続する Data Virtualization を参照してください。
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Greenplum | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| MariaDB |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Microsoft Azure Data Lake Storage Gen2 | ||
| Microsoft Azure SQL Database | ||
| Microsoft SQL Server |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| MongoDB |
|
|
| MySQL (My SQL Community Edition) (My SQL Enterprise Edition) |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Oracle |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| PostgreSQL | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| Presto | 重複した接続が必要な場合は、まずプラットフォーム接続で作成し、その後、 Data Virtualization にインポートするのが最善の方法です。 この方法に従えば、今後 Data Virtualization から削除される可能性のある重複した接続を復元することができます。 それらの接続に関連付けられている古い仮想テーブルも復元されます。 ただし、重複接続は管理に手間がかかり、クエリーのパフォーマンスに影響を与える可能性があるため、その使用は制限することを検討してください。 Data Virtualization ウェブクライアントで直接、または SETRDBCX APIを使用して重複した接続を作成した場合、接続またはリンクされた仮想テーブルが削除された場合、それらを復元することはできません。 |
Presto への接続を作成する際には、デフォルトのカタログが選択されます。 また、別の Presto カタログで仮想化したオブジェクトにアクセスする際には、そのカタログに切り替える必要はありません。 |
| REST API | この接続には、 Data Virtualization において特別な配慮が必要です。 REST APIへの接続 Data Virtualization を参照してください。 | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Salesforce.com | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
|
| SAP ASE | ||
| SAP HANA | この接続Data Virtualization特において別な配慮を必要とする。は SAP HANA に接続する Data Virtualization を参照してください。 |
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| SAP OData | 以下の理由により、読めない表をプレビューまたは照会することはできません。
|
|
| Snowflake | この接続Data Virtualization特において別な配慮を必要とする。は Snowflake に接続する Data Virtualization を参照してください。
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Spark SQL | この接続には、 Data Virtualization において特別な配慮が必要です。 Spark SQLへの接続を参照してください。 | この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
| Teradata Teradata JDBC ドライバー 著作権 © 2024 による。 17.00 Teradata All rights reserved. IBM Teradata ドライバーを組み込み用途で提供します。これは、 からのライセンスに基づき、 サービス提供の一部としてのみ使用することを目的としています。 JDBC Teradata IBM Watson® |
|
この接続は、このデータ・ソースの照会機能を利用するように最適化されています。 |
Data Virtualizationにおけるオブジェクトストレージのデータソース
IBM Cloud Object Storage、 Amazon S3、 Ceph、または MinIO のデータソースにファイルとして保存されているデータを使用して、仮想テーブルを作成することができます。 クラウド・オブジェクト・ストレージに保存されているデータにアクセスするには、ファイルが置かれているデータ・ソースへの接続を作成する必要があります。
1 つ以上のファイルのデータをセグメント化または結合して、仮想表を作成できます。 Data Virtualizationにおけるオブジェクトストレージ内のファイルへのアクセスは、Hadoopの外部テーブルサポートを使用するDb2 Big SQL機能に基づいて構築されている。 詳細は CREATE TABLE (HADOOP) ステートメントを参照してください。
用語
- バケット は、データのコンテナーを提供するために使用される論理抽象化です。 Object Storage にはフォルダーの概念はありません。バケットとキーのみです。 バケットは、オブジェクト・ストレージ・データ・ソースのインターフェースでのみ作成できます。 Data Virtualizationでは作成できない。 バケット名は一意でなければならず、オブジェクトストレージプロバイダーのルールに従う必要があります。 多くの場合、これらの規則には、名前を小文字、数字、およびダッシュのみの 3 文字から 63 文字に制限することが含まれます。 バケット名の先頭と末尾は、小文字か数値でなければなりません。 Data Virtualizationがオブジェクトストレージのデータにアクセスする場合、バケット名はすべてのオブジェクトストレージ接続で一意でなければなりません。
- ファイル・パス は、データを保管するファイルへの完全パスです。 S3 ファイル・システム実装では、長さゼロのファイルをディレクトリーのように扱うことができ、スラッシュ (/) を含むファイル名はネストされたディレクトリーのように扱われます。 ファイル・パスには、バケット名、オプションのファイル・パス、およびファイル名が含まれます。 Object Storageでは、表の作成時にファイル・パスが使用されます。 同じパスにあるすべてのファイルが表データに寄与します。 ファイル・パスに別のファイルを追加することで、さらにデータを追加できます。
- パーティション とは、スキーマ内の共通属性によってグループ化されたデータのことです。 パーティショニングにより、データは複数のファイル・パスに分割され、これらのパスはディレクトリーのように扱われます。 Data Virtualizationはパーティションを発見し、使用することで、クエリが処理しなければならないデータ量を削減することができるため、パーティション列に対する述語を使用するクエリのパフォーマンスを向上させることができる。
ベスト・プラクティス
- ファイル・フォーマット
- Data Virtualizationは、PARQUET(またはPARQUETFILE)、ORC(最適化された行カラム)、CSV(カンマ区切り値)、TSV(タブ区切り値)、JSONファイル形式をサポートしています。 その他のファイル形式はサポートされません。注: Data Virtualization フォルダや階層構造に基づいてデータファイルを仮想化します。 フォルダまたは階層内のすべてのデータファイルが同じデータ型であり、同じフォーマットに従っていることを確認してください。
- PARQUET (または PARQUETFILE) の場合、ファイル拡張子は必要ありません。 メタデータはデータ・ファイルから抽出されます。
- ORC の場合、ファイル拡張子は必要ありません。 メタデータはデータ・ファイルから抽出されます。
- CSV ファイルおよび TSV ファイルの場合:
- 以下のように、適切な .csv または .tsv ファイル拡張子が必要です。
- CSV: .csv ファイル拡張子は必須であり、ファイルの内容はコンマ区切り値の指定に従う必要があります。
- TSV: .tsv ファイル拡張子が必要です。ファイルの内容は、タブ区切り値の指定に従う必要があります。
- オプション・パラメーターを使用して、CSV ファイルおよび TSV ファイル内のフィールド値を囲むストリング区切り文字 (
quoteCharquoteChar- デフォルト値は区切り文字なし (指定されていない) です。
quoteChar\n- ストリング値にストリング区切り文字 (
quoteChar\
- 以下のように、適切な .csv または .tsv ファイル拡張子が必要です。
- JSON ファイルの場合、.jsonファイル拡張子が必要です。 JSON ファイルは、各行が有効な JSON オブジェクトになるようにコーディングする必要があります。 行は改行文字 (
\n
注: 他のすべてのファイル・フォーマットはエラーを返します。 詳細は、 Cloud Object Storage の「サポートされていないファイル形式を使用しようとした際に表示されるエラーメッセージ 」を参照してください。 - データの編成
- 列名に英数字を使用すると、 Hive との互換性が損なわれる可能性があるため、使用しないでください。 英数字でもアンダー_xNNNNでもない文字は、_xNNNN,としてエンコードされます。 列名を正しく表示するには、以下の手順を実行して
allownonalphanumeric- Data Virtualizationインスタンスc-db2u-dv-db2u-0)のヘッドポッドにアクセスする。
- 以下のコマンドを実行して、
allownonalphanumericdb2uctl adm bigsql config --key bigsql.catalog.identifier.mappingrules --value allownonalphanumeric,allowleadingdigits,allowreservedwords - 以下のコマンドを実行して、 Big SQLを再始動します。
su - db2inst1 bigsql stop ; bigsql start
- 仮想化された表を介してオブジェクト・ストレージ・データにアクセスする場合、仮想化するファイルは単一のファイル・パス内と単一のバケット内になければならず、そのバケットにはカートに追加するファイルが少なくとも 1 つ含まれている必要があります。 このファイル・パス内のすべてのファイルは、仮想表の一部です。 表にさらにデータが追加されると (ファイル・パスに新規ファイルが作成されます)、仮想化された表にアクセスしたときにそのデータが表示されます。 ファイル・パス内のすべてのファイルは、1 つの表として仮想化されるように、同じファイル・フォーマットを使用する必要があります。
- 複数のファイル・パスにあるファイルを 1 つの表として仮想化する場合は、すべてのファイルを含むバケットを仮想化できます。 例えば、ファイル・パス A/B/C/T1a、A/B/C/T1b、A/B/D/T1c、および A/B/D/T1dがある場合、ファイル・パス A/B/を仮想化できます。 そのパスとネストされたパス内のすべてのファイルは、アクセス可能なオブジェクトの一部になります。
- 区切り ID と大/小文字混合を使用する場合でも、同じ名前の 2 つのオブジェクト (表、スキーマ、または列) を作成しないでください。 例えば、表 t1 と、 T1という名前の別の表を持つことはできません。 これらの名前は、Object Storage (Hive) 内で重複する名前と見なされます。 詳しくは、 識別子を参照してください。
- Db2 は、 Hive がサポートするよりも広い範囲の有効な区切り ID をサポートします。 オブジェクト・ストアに対して仮想表を作成するときに指定される一部の ID 名は、 Hive カタログに受け入れられる前に調整される可能性があります。 マッピングは自動的に行われます。 詳細は 「識別子」 を参照してください。
- 仮想表のファイル・パスに新規データが追加されたら、以下のコマンドを実行して、新規データを表示するようにメタデータ・キャッシュが更新されるようにすることを検討してください。
CALL SYSHADOOP.HCAT_CACHE_SYNC(<schema>, <object>)詳細については、HCAT_CACHE_SYNC ストアドプロシージャを参照してください。
- 仮想表のファイル・パスに新規パーティションが追加されたら、 「仮想化データ」 ページのオーバーフロー・メニューで 「パーティションのリフレッシュ」 をクリックして、新規パーティションを識別します。
SQL インターフェースで以下のコマンドを実行して、追加された新規パーティションを識別することもできます。
MSCK REPAIR TABLE <table-name>詳細は、 MSCK REPAIR TABLE を参照してください。
- 列名に英数字を使用すると、 Hive との互換性が損なわれる可能性があるため、使用しないでください。 英数字でもアンダー_xNNNNでもない文字は、_xNNNN,としてエンコードされます。 列名を正しく表示するには、以下の手順を実行して
- クエリーのパフォーマンスの最適化
- ORC や Parquet などのコンパクトなファイル・フォーマットを使用して、ネットワーク・トラフィックを最小限に抑えます。これにより、照会のパフォーマンスが向上します。
- STRING または TEXT データ型は使用しないでください。 n を列データに適した値に設定して、VARCHAR (N) データ・タイプを使用します。 以下のコマンドを使用して表を変更し、列の適切な長さを定義します。
ALTER TABLE <schema>.<table> ALTER COLUMN <col> SET DATA TYPE VARCHAR(<size>) - Hive スタイルのパーティション化を使用してデータをパーティション化します。 パーティション化されたデータは、共通属性によってグループ化されます。 Data Virtualizationでは、パーティションを使ってクエリが処理しなければならないデータ量を減らすことができる。 データ・セット全体を照会することは、不可能であったり、場合によっては不要であったりします。 パーティション列を含む照会で述部を使用して、パフォーマンスを向上させることができます。
例えば、年の列にパーティション化されている school_records 表では、年ごとに値が別々のファイル・パスに分離されます。
YEAR=1993YEAR IN (1996,1995)YEAR BETWEEN 1992 AND 1996WHERE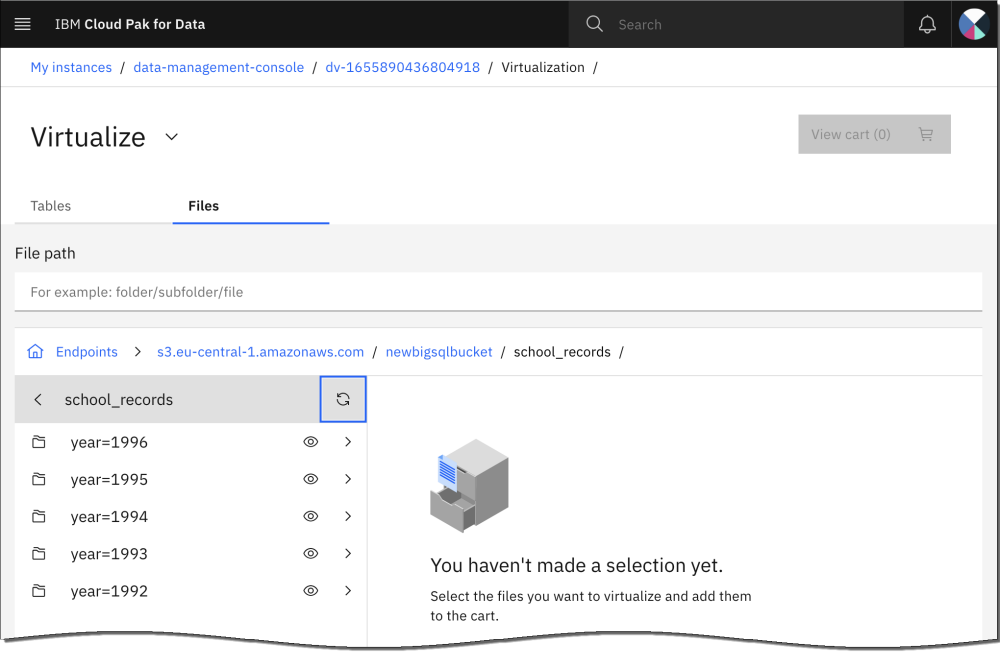
- パーティション化された列タイプを正確に定義します。 デフォルトでは、パーティション化文字列は STRING タイプであると想定されますが、これは推奨されません。 パーティション化された列を適切なデータ・タイプに再定義してください。
- 照会されているデータに関する統計を収集します。 Data Virtualization ANALYZE コマンドを使用して、オブジェクトストレージ上の仮想テーブルの統計情報を収集します。 統計は、Web クライアントで収集することも、SQL を使用して収集することもできます。 詳細については、 統計の収集 Data Virtualization をご覧ください。
制限
- Data Virtualizationでは、CSV、TSV、またはJSON形式のテキストファイルに対して、UTF-8文字エンコーディングのみがサポートされています。 ORC や PARQUET などの Cloud Object Storageバイナリー・フォーマットは、文字タイプを透過的にエンコードするため、影響を受けません。
- Data Virtualizationは、オブジェクト・ストレージ上の仮想化テーブルのTIMEデータ型をサポートしない。
- クラウド・オブジェクト・ストレージ内の資産のプレビューには、表の最初の 200 列のみが表示されます。
- Cloud Object Storageへの接続を削除する前に、オブジェクト・ストレージ接続内のすべての仮想表を削除する必要があります。 接続が削除され、その接続内の表を削除しようとすると、エラーが表示されます。 オブジェクトストレージで仮想テーブルを削除すると、資格情報エラーメッセージが表示されます。
- バケットが接続プロパティーで指定されていない場合、接続はグローバルです。 この場合は、ファイル・パスにバケット名を含めます。 Data Virtualizationインスタンスでは、最大1つのグローバル接続を指定できます。
CREATE TABLE (HADOOP) ステートメントの制限事項
も参照してください。