Sources de données prises en charge dans la Data Virtualization
LaData Virtualization prend en charge les sources de données relationnelles et non relationnelles suivantes sur " IBM Cloud Pak for Data as a Service".
Vous ne pouvez pas vous connecter à une source de données en tant que connexion à une connexion de plateforme existante si la connexion de plateforme utilise l'intégration de cloud, Secure Gatewayou Satellite Link. Ces fonctionnalités ne sont pas prises en charge par la Data Virtualization lorsque vous vous connectez aux connexions de la plate-forme. Vous voyez un message d'erreur similaire àCannot reach the network destination of the data source. Vous pouvez configurer la source de données en utilisant l'intégration dans le nuage, Secure Gateway ou Satellite Link et fournir le nom d'hôte ou le point d'extrémité IP directement à la Data Virtualization en tant que nouvelle connexion.
- limites de taille
- Data Virtualization prend en charge la virtualisation des tables avec une taille de ligne allant jusqu'à 1 Mo, et jusqu'à 2048 colonnes dans une table. Cependant, le nombre de colonnes que la Data Virtualization peut prévisualiser dépend de nombreux facteurs, tels que les types de données des colonnes. Actuellement, l'aperçu est limité à 200 colonnes.
- Attributs de commentaire
- Lors de la création de tables virtuelles, Data Virtualization n'inclut pas les attributs de commentaires qui ont été attribués aux objets de la source de données. Cette limitation s'applique à toutes les sources de données.
- Types de données
- Certains types de données de votre source de données peuvent ne pas être pris en charge par la Data Virtualization. Ces limitations sont documentées dans les tableaux suivants. La Data Virtualization peut également faire correspondre certains types de données de votre source de données à d'autres types de données. Ces mappages sont basés sur les mappages Db2® Big SQL sous-jacents. Pour plus d'informations, voir Types de données dans Db2 Big SQL.
Sources de données IBM
Le tableau suivant répertorie les sources de données IBM® auxquelles vous pouvez vous connecter à partir de Data Virtualization.
| Connecteur | Limitations | Plus d'information |
|---|---|---|
| IBM Cloud Databases for MongoDB | IBM Cloud Databases for MongoDB est disponible en tant que bêta. Les types de données " MongoDB suivants sont pris en charge par la Data Virtualization: INT32, INT64, DOUBLE, STRING, BOOLEAN, DATE et BINARY. |
|
| IBM Cloud Databases for MySQL | ||
| IBM Cloud Bases de données pour PostgreSQL | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| IBM Cloud Object Storage | Cette connexion nécessite une attention particulière dans le cadre de la Data Virtualization. Voir Connexion à IBM Cloud Object Storage dans la Data Virtualization. Pour les limitations, voir Sources de données dans le stockage d'objets dans la Data Virtualization. |
|
| IBM Data Virtualization Manager for z/OS | Vous ne pouvez pas vous connecter à Data Virtualization Manager for z/OS si la connexion utilise l'intégration de cloud, Secure Gatewayou Satellite Link. Ces fonctions ne sont pas prises en charge par la Data Virtualization. Un message d'erreur similaire à celui-ci s'affiche.Cannot reach the network destination of the data source. | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| IBM Db2 |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| IBM Db2 Big SQL | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| IBM Db2 for i | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| IBM Db2 for z/OS | ||
| IBM Db2 on Cloud | Les types NCHAR et NVARCHAR ne sont pas pris en charge dans la Data Virtualization. | |
| IBM Db2 Warehouse | ||
| IBM Informix® | Les types de données INTERVAL, BIGINT et BIGSERIAL ne sont pas pris en charge par la Data Virtualization. Pour plus d'informations, voir Des exceptions se produisent lors de l'utilisation de la connectivité du pilote JDBC Informix. | |
| IBM Netezza Performance Server |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| IBM Planning Analytics |
|
|
| IBM Data Virtualization | Il est important de ne pas créer de connexion à votre instance de virtualisation des données : Ne créez pas de connexion à votre instance de Data Virtualization.
|
Sources de données de tiers
Le tableau suivant répertorie les sources de données tierces auxquelles vous pouvez vous connecter à partir de Data Virtualization.
| Connecteur | Limitations | Plus d'information |
|---|---|---|
| Amazon RDS for MySQL |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Amazon RDS for Oracle |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Amazon RDS for PostgreSQL | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| Amazon Redshift | Les types de données SPATIAL, SKETCH et SUPER sont convertis en CLOB dans l' Data Virtualization. | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Amazon S3 | Cette connexion nécessite une attention particulière dans le cadre de la Data Virtualization. Voir Se connecter à Amazon S3 dans Data Virtualization.
|
|
| Apache Derby | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| Apache Hive |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Ceph | Cette connexion nécessite une attention particulière dans le cadre de la Data Virtualization. Voir Connecting to Ceph dans Data Virtualization. Pour les limitations, voir Sources de données dans le stockage d'objets dans Data Virtualization. |
|
| Apache Impala | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| S3 générique | Pour les limitations, voir Sources de données dans le stockage d'objets dans Data Virtualization. |
|
| Google BigQuery | Cette connexion nécessite une attention particulière dans le cadre de la Data Virtualization. Voir Se connecter à Google BigQuery dans Data Virtualization.
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Greenplum | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| MariaDB |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Microsoft Azure Data Lake Storage Gen2 | ||
| Microsoft Azure SQL Database | ||
| Microsoft SQL Server |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| MongoDB |
|
|
| MySQL (Mon édition de communauté SQL) (My SQL Enterprise Edition) |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Oracle |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| PostgreSQL | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| Presto | Si vous avez besoin de connexions en double, la meilleure pratique consiste à les créer d'abord dans Platform Connections, puis à les importer dans Data Virtualization. Si vous suivez cette méthode, vous pourrez restaurer toutes les connexions en double qui pourraient être supprimées de Data Virtualization à l'avenir. Les anciennes tables virtuelles liées à ces connexions sont également restaurées. Cependant, envisagez de limiter l'utilisation des connexions en double, car elles nécessitent plus de gestion et peuvent avoir un impact sur les performances des requêtes. Si vous créez une connexion en double directement dans le Data Virtualization client Web ou en utilisant l'API SETRDBCX , vous ne pouvez pas restaurer la connexion ou les tables virtuelles liées si elles sont supprimées. |
Un catalogue par défaut est sélectionné pour vous lorsque vous créez des connexions à Presto. De plus, vous pouvez accéder aux objets que vous avez virtualisés dans un autre catalogue d' Presto s sans revenir à ce catalogue. |
| API REST | Cette connexion nécessite une attention particulière Data Virtualization. Voir Connexion à l'API REST dans Data Virtualization. | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Salesforce.com | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
|
| SAP ASE | ||
| SAP HANA | Cette connexion nécessite une attention particulière dans le cadre de la Data Virtualization. Voir Se connecter à SAP HANA dans Data Virtualization. |
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| SAP OData | Vous ne pouvez pas prévisualiser ni interroger des tables non lisibles en raison des raisons suivantes :
|
|
| Snowflake | Cette connexion nécessite une attention particulière dans le cadre de la Data Virtualization. Voir Se connecter à Snowflake dans Data Virtualization.
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Spark SQL | Cette connexion nécessite une attention particulière Data Virtualization. Voir Connexion à Spark SQL. | Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
| Teradata Teradata JDBC. Copyright (C) 2024 par. 17.00 Teradata All rights reserved. IBM fournit une utilisation intégrée du pilote Teradata JDBC sous licence d' Teradata, uniquement pour une utilisation dans le cadre de l'offre de services IBM Watson®. |
|
Cette connexion est optimisée pour tirer parti des fonctions de requête de cette source de données. |
Sources de données dans le stockage d'objets dans la Data Virtualization
Vous pouvez utiliser les données stockées sous forme de fichiers sur les sources de données IBM Cloud Object Storage, Amazon S3, Ceph ou MinIO pour créer des tables virtuelles. Pour accéder aux données stockées dans le stockage d'objets cloud, vous devez créer une connexion à la source de données dans laquelle se trouvent les fichiers.
Vous pouvez segmenter ou combiner des données à partir d'un ou de plusieurs fichiers pour créer une table virtuelle. L'accès aux fichiers dans le stockage objet dans la Data Virtualization est basé sur les capacités Db2 Big SQL qui utilisent le support des tables externes Hadoop. Pour plus d'informations, voir l'instruction CREATE TABLE (HADOOP ).
Terminologie
- Une Compartiment est une abstraction logique utilisée pour fournir un conteneur pour les données. Il n'y a pas de concept de dossier dans le stockage des objets ; seuls les seaux et les clés. Les compartiments ne peuvent être créés que dans l'interface de la source de données de stockage d'objets. Ils ne peuvent pas être créés dans le cadre de la Data Virtualization. Les noms des compartiments doivent être uniques et respecter les règles du fournisseur de stockage d'objets. Ces règles incluent souvent la restriction du nom à 3 à 63 caractères avec des lettres minuscules, des chiffres et des tirets uniquement. Les noms de compartiment doivent commencer et se terminer par une lettre minuscule ou un chiffre. Lorsque Data Virtualization données accède à des données dans le stockage d'objets, le nom de l'unité de stockage doit être unique pour toutes les connexions au stockage d'objets.
- Un Chemin du fichier est le chemin d'accès complet au fichier dans lequel vous souhaitez stocker des données. L'implémentation du système de fichiers S3 permet de traiter les fichiers de longueur zéro comme des répertoires, et les noms de fichier contenant une barre oblique (/) sont traités comme des répertoires imbriqués. Le chemin d'accès au fichier inclut le nom de compartiment, un chemin de fichier facultatif et un nom de fichier. Dans le stockage des objets, le chemin d'accès au fichier est utilisé lorsqu'une table est créée. Tous les fichiers du même chemin contribuent aux données de table. Vous pouvez ajouter d'autres données en ajoutant un autre fichier au chemin d'accès au fichier.
- Une partition est une donnée qui est regroupée par un attribut commun dans le schéma. Le partitionnement divise les données en plusieurs chemins de fichier, qui sont traités comme des répertoires. La Data Virtualization peut découvrir et utiliser des partitions pour réduire la quantité de données que les requêtes doivent traiter, ce qui peut améliorer les performances des requêtes qui utilisent des prédicats sur les colonnes de partitionnement.
Meilleures pratiques
- Formats de fichier
- La Data Virtualization prend en charge les formats de fichier PARQUET (ou PARQUETFILE), ORC (optimized row columnar), CSV (comma-separated values), TSV (tab-separated values) et JSON. Aucun autre format de fichier n'est pris en charge.Remarque : Data Virtualization virtualiser des fichiers de données en fonction de leur structure de dossiers ou de hiérarchie. Vous devez vous assurer que tous les fichiers de données du dossier ou de la hiérarchie sont du même type et ont le même format.
- Pour PARQUET (ou PARQUETFILE), les extensions de fichier ne sont pas requises. Les métadonnées sont extraites du fichier de données.
- Pour ORC, les extensions de fichier ne sont pas requises. Les métadonnées sont extraites du fichier de données.
- Pour les fichiers CSV et TSV:
- L'extension de fichier .csv ou .tsv appropriée est requise, comme suit:
- CSV: l'extension de fichier .csv est requise et le contenu du fichier doit suivre les spécifications des valeurs séparées par des virgules.
- TSV: l'extension de fichier .tsv est requise et le contenu du fichier doit respecter les spécifications des valeurs séparées par des tabulations.
- Un paramètre facultatif peut être utilisé pour spécifier un caractère délimiteur de chaîne (
quoteChar- Les performances de l'interrogation des données peuvent être affectées négativement si
quoteChar - La valeur par défaut n'est pas un délimiteur (non spécifié).
- La valeur de
quoteChar\n - Si la valeur de chaîne contient le délimiteur de chaîne (
quoteChar\
- Les performances de l'interrogation des données peuvent être affectées négativement si
- L'extension de fichier .csv ou .tsv appropriée est requise, comme suit:
- Pour les fichiers JSON, l'extension de fichier .json est requise. Les fichiers JSON doivent être codés pour que chaque ligne soit un objet JSON valide. Les lignes doivent être séparées par un caractère de nouvelle ligne (
\n
Remarque: tous les autres formats de fichier renvoient une erreur. Pour plus d'informations, voir Message d'erreur lorsque vous essayez d'utiliser un format de fichier non pris en charge dans Cloud Object Storage. - Organisation des données
- Evitez d'utiliser des caractères alphanumériques dans les noms de colonne car cela pourrait interférer avec la compatibilité Hive . Tout caractère qui n'est pas un caractère alphanumérique ou un trait de soulignement est codé sous la forme _xNNNN, où _xNNNN est la valeur hexadécimale du caractère. Si vous souhaitez afficher correctement les noms de colonne, activez l'option
allownonalphanumeric- Accédez au pod principal dans l'instance de Data Virtualizationc-db2u-dv-db2u-0).
- Exécutez la commande suivante pour éditer la configuration afin d'inclure l'option
allownonalphanumericdb2uctl adm bigsql config --key bigsql.catalog.identifier.mappingrules --value allownonalphanumeric,allowleadingdigits,allowreservedwords - Exécutez la commande suivante pour redémarrer Big SQL:
su - db2inst1 bigsql stop ; bigsql start
- Si vos données de stockage d'objets sont accessibles via une table virtualisée, les fichiers que vous souhaitez virtualiser doivent se trouver dans un chemin de fichier unique et dans un compartiment unique, et le compartiment doit inclure au moins un fichier que vous ajoutez au panier. Tous les fichiers de ce chemin de fichier font partie de la table virtualisée. Lorsque des données supplémentaires sont ajoutées à la table (de nouveaux fichiers sont créés dans le chemin d'accès au fichier), les données sont visibles lorsque vous accédez à la table virtualisée. Tous les fichiers du chemin d'accès au fichier doivent utiliser le même format de fichier afin qu'ils soient virtualisés sous la forme d'une table.
- Si vous souhaitez virtualiser les fichiers dans plusieurs chemins de fichier sous la forme d'une table, vous pouvez virtualiser le compartiment qui contient tous les fichiers. Par exemple, si vous avez des chemins de fichier A/B/C/T1a, A/B/C/T1b, A/B/D/T1c, et A/B/D/T1d, vous pouvez virtualiser le chemin de fichier A/B/. Tous les fichiers de ce chemin et de ce chemin imbriqué font partie de l'objet accessible.
- Ne créez pas deux objets (tables, schémas ou colonnes) portant le même nom, même si vous utilisez des identificateurs délimités et des majuscules et des minuscules. Par exemple, vous ne pouvez pas disposer d'une table t1 et d'une autre table nommée T1. Ces noms sont considérés comme des noms en double dans la mémoire d'objets (Hive). Pour plus d'informations, voir Identificateurs.
- Db2 prend en charge une plage d'identificateurs délimités valides plus large que celle prise en charge par Hive . Certains noms d'identificateur qui sont spécifiés lorsque vous créez des tables virtualisées sur une librairie peuvent être ajustés avant de pouvoir être acceptés dans le catalogue Hive . Le mappage est effectué automatiquement. Pour plus d'informations, voir Identifiants.
- Lorsque de nouvelles données sont ajoutées au chemin de fichier d'une table virtualisée, envisagez d'exécuter la commande suivante pour vous assurer que le cache de métadonnées est mis à jour pour afficher les nouvelles données.
CALL SYSHADOOP.HCAT_CACHE_SYNC(<schema>, <object>)Pour plus d'informations, consultez la procédure stockée HCAT_CACHE_SYNC.
- Lorsque de nouvelles partitions sont ajoutées au chemin de fichier de la table virtualisée, cliquez sur Actualiser les partitions dans le menu déroulant dynamique de la page Données virtualisées pour identifier les nouvelles partitions.
Vous pouvez également exécuter la commande suivante dans l'interface SQL pour identifier les nouvelles partitions qui ont été ajoutées.
MSCK REPAIR TABLE <table-name>Pour plus d'informations, voir TABLEAU DE RÉPARATION MSCK.
- Evitez d'utiliser des caractères alphanumériques dans les noms de colonne car cela pourrait interférer avec la compatibilité Hive . Tout caractère qui n'est pas un caractère alphanumérique ou un trait de soulignement est codé sous la forme _xNNNN, où _xNNNN est la valeur hexadécimale du caractère. Si vous souhaitez afficher correctement les noms de colonne, activez l'option
- Optimisation des performances des requêtes
- Utilisez un format de fichier compact tel que ORC ou Parquet pour réduire le trafic réseau, ce qui améliore les performances des requêtes.
- N'utilisez pas le type de données STRING ou TEXT. Utilisez le type de données VARCHAR (n), avec n défini sur une valeur appropriée pour les données de colonne. Utilisez la commande suivante pour modifier la table afin de définir une longueur appropriée pour la colonne.
ALTER TABLE <schema>.<table> ALTER COLUMN <col> SET DATA TYPE VARCHAR(<size>) - Partitionnez vos données à l'aide du partitionnement de style Hive . Les données partitionnées sont regroupées par attribut commun. La Data Virtualization peut utiliser des partitions pour réduire la quantité de données que les requêtes doivent traiter. Il n'est souvent pas nécessaire, ou même possible, d'interroger la totalité du jeu de données. Vous pouvez utiliser des prédicats dans vos requêtes qui incluent les colonnes de partitionnement pour améliorer les performances.
Par exemple, une table school_records partitionnée sur une colonne d'année sépare les valeurs par année dans des chemins de fichier distincts. Une condition
WHEREYEAR=1993YEAR IN (1996,1995)YEAR BETWEEN 1992 AND 1996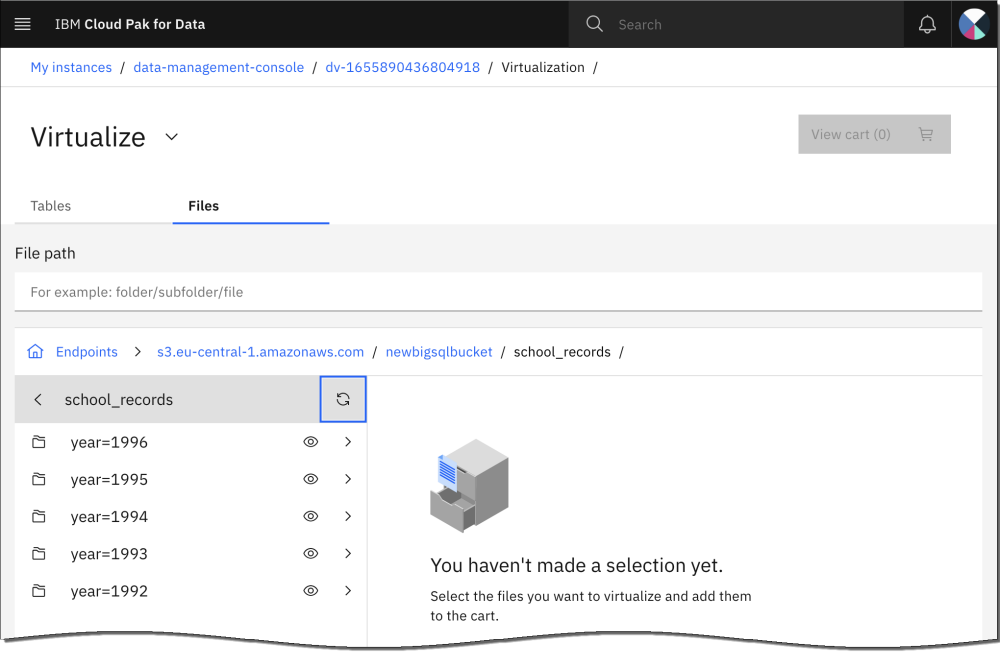
- Définissez les types de colonne partitionnée avec précision. Par défaut, les colonnes de caractères partitionnées sont supposées être de type STRING, ce qui n'est pas recommandé. Redéfinissez les colonnes partitionnées sur un type de données approprié.
- Collectez des statistiques sur les données demandées. Data Virtualization utilise la ANALYZE pour collecter des statistiques sur les tables virtualisées sur le stockage d'objets. Vous pouvez collecter des statistiques dans le client Web ou à l'aide de SQL. Pour plus d'informations, voir Collecte de statistiques dans Data Virtualization.
Limitations
- Seul le codage de caractères UTF-8 est pris en charge dans la Data Virtualization pour les fichiers texte au format CSV, TSV ou JSON. Les formats binaires Cloud Object Storage tels que ORC ou PARQUET ne sont pas affectés car ils codent de manière transparente les types de caractères.
- La Data Virtualization ne prend pas en charge le type de données TIME dans une table virtualisée sur un stockage objet.
- L'aperçu des actifs dans le stockage d'objets cloud affiche uniquement les 200 premières colonnes de la table.
- Avant de supprimer une connexion à Cloud Object Storage, vous devez supprimer toutes les tables virtualisées de la connexion de stockage d'objets. Si une connexion est supprimée et que vous tentez de supprimer une table dans cette connexion, une erreur s'affiche. Voir Message d'erreur Credential lorsque vous supprimez une table virtualisée dans le stockage d'objets.
- Si le compartiment n'est pas spécifié dans les propriétés de connexion, la connexion est globale. Dans ce cas, incluez le nom du compartiment dans le chemin d'accès au fichier. Vous pouvez spécifier jusqu'à une connexion globale dans une instance de Data Virtualization.
Voir également les restrictions
dans l'instruction CREATE TABLE (HADOOP ).