The translation of this page does not represent the latest version. For the latest updates, see the English version of the documentation.
Go back to the English version of the documentationRekomendacje dotyczące pamięci podręcznej w programie Watson Query
Last updated: 31 mar 2023
Rekomendacje dotyczące pamięci podręcznej w programie Watson Query
Korzystając z wejściowego zestawu zapytań, Watson Query zaleca uporządkowane listy pamięci podręcznych danych, które mogą zwiększyć wydajność zapytań wejściowych i potencjalnie pomóc w przyszłych obciążeniach zapytań.
Zapytania wejściowe są zapytaniami, które zostały uruchomione w dowolnym miejscu w ciągu poprzedniego 1 dnia do poprzednich 15 dni i muszą mieć czas wykonywania co najmniej jednej minuty. Zalecenia są uznawane za ważne przez jeden dzień, po którym mogą się zmienić w miarę zmian obciążenia zapytaniami.
Mechanizm rekomendacji pamięci podręcznej używa dwóch modeli do generowania rekomendacji.
Model oparty na regułach korzysta z zaawansowanej heurystyki w celu określenia, które kandydaci na pamięć podręczną pomagają w obciążeniu zapytaniami do danych wejściowych.
Model oparty na uczeniu maszynowym wykorzystuje wstępnie przeszkolony model uczenia maszynowego, który wykrywa podstawowe wzorce zapytań i przewiduje pamięci podręczne, które pomagają w potencjalnym obciążeniu zapytaniami w przyszłości.
Oba modele generują listę rankingową kandydatów do pamięci podręcznej, które są konsolidowane przez mechanizm w celu wygenerowania końcowego zestawu rekomendacji. Użytkownik może włączyć lub wyłączyć rekomendacje dotyczące pamięci podręcznej na podstawie uczenia maszynowego. Domyślnie rekomendacje dotyczące pamięci podręcznej na podstawie uczenia maszynowego są włączone.
Oprócz zaleceń dotyczących tworzenia pamięci podręcznej, mechanizm zaleca również wyłączenie pamięci podręcznej i usunięcie rekomendacji opartych na minionym użyciu i innych pomiarach. Rekomendacje te są wyświetlane na karcie Aktywne i Nieaktywne w przypadku istniejących pamięci podręcznych.
Rekomendacje dotyczące pamięci podręcznej oparte na uczeniu maszynowym uwzględnia podstawowe wzorce zapytań i przewidywania pamięci podręcznych, które są ważne przez 1 dzień.
Program Watson Query korzysta z wcześniej wyszkolonego modelu, który został przeszkolony w oparciu o standardowy zestaw danych w branży.
Użytkownik może włączyć lub wyłączyć rekomendacje dotyczące pamięci podręcznej na podstawie uczenia maszynowego.
Mechanizm rekomendacji konsoliduje i klasyfikuje ostateczny zestaw rekomendacji z obu modeli. Menedżer może następnie dodawać pamięci podręczne danych z tych rekomendacji.
Program Watson Query udostępnia mechanizm generowania listy rekomendacji w rankingu. Ranking rekomendacji dotyczących tworzenia pamięci podręcznej jest określany przez czas wykonywania zapytań, częstotliwość tych zapytań w obciążeniu wejściowym oraz wagę tych dwóch modeli. Silnik jest w pełni świadomy i nie poleca tworzenia pamiętników, które istnieją. Dodatkowo, silnik nie zaleca tworzenia zduplikowanych pamięci podręcznych.
Proces generowania rekomendacji dotyczących pamięci podręcznej składa się z pięciu etapów, jak przedstawiono na poniższym obrazku:
Rysunek 1. Przegląd procesu rekomendacji pamięci podręcznej
Przedziały
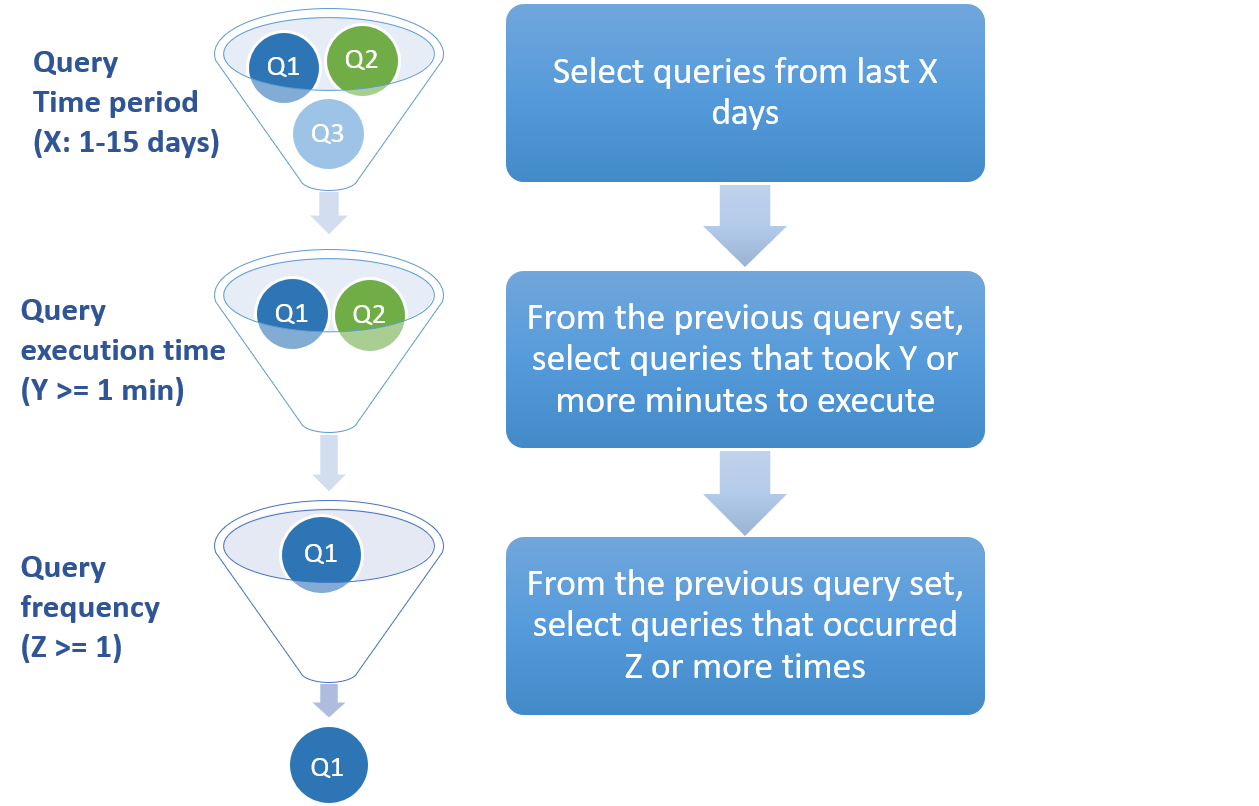
Mechanizm rekomendacji pamięci podręcznej gromadzi informacje, takie jak tekst zapytania, czas wykonania, liczność, znacznik czasu i częstotliwość dla podanego okresu.
Na poniższym obrazku przedstawiono sposób filtrowania zapytań z obciążenia historycznego w celu dotarcia do końcowego zestawu danych wejściowych zapytań dla mechanizmu rekomendacji:Rysunek 2. Etap gromadzenia danych w procesie rekomendacji pamięci podręcznej.
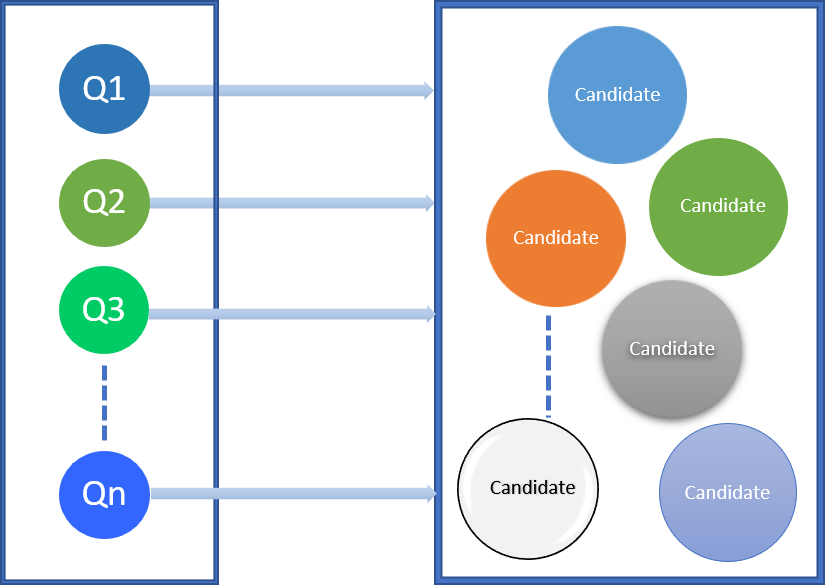
Mechanizm rekomendacji generuje potencjalne bufory pamięci podręcznej dla obciążenia zapytaniami wejściowymi.
Tłumacz
Mechanizm rekomendacji przekształca i konsoliduje kandydatów, aby upewnić się, że są one składniowo i semantycznie poprawne, unikalne oraz wszystkie ograniczenia Db2® .
Oceń
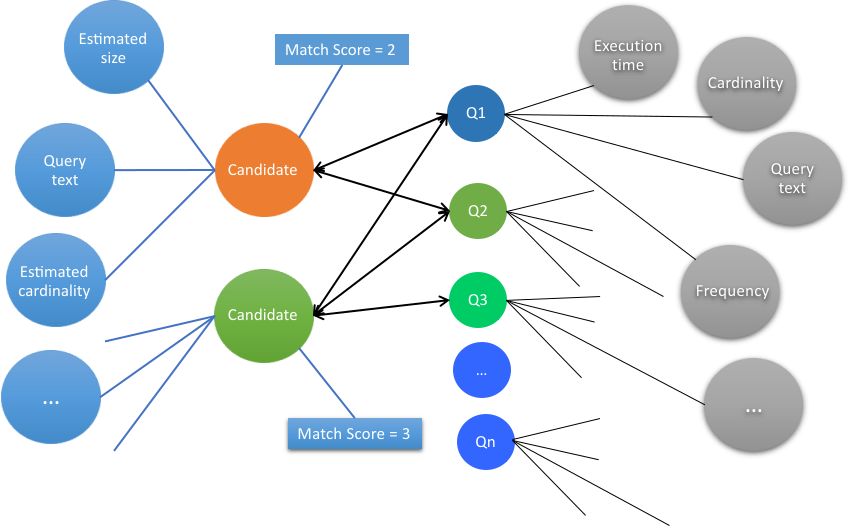
Mechanizm ocenia przekształcone definicje przez dopasowanie każdego kandydata pamięci podręcznej do obciążenia zapytaniami wejściowymi. Ponadto, dla oceny modelu uczenia maszynowego, dla każdego kandydata tworzony jest wysokowydajny wektor predyktorów.Rysunek 3. Etap wartościowania w procesie rekomendacji pamięci podręcznej.
W wyniku tej oceny mechanizm rekomendacji generuje wynik zgodności dla każdego kandydata pamięci podręcznej. Ocena każdego kandydata opiera się na następujących kryteriach.
Matchability Liczba zapytań zgodnych z kandydatem pamięci podręcznej.
Różnorodność Różne zapytania, które są zgodne z kandydatem pamięci podręcznej.
Liczność Wielkość tabeli wynikowej, która jest pobierana przez kandydata pamięci podręcznej.
Wydajność Czas wykonania zapytań, które były zgodne z kandydatem pamięci podręcznej.
Rangowanie i sortowanie
Mechanizm rekomendacji szereguje i sortuje kandydatów do pamięci podręcznej w celu wygenerowania ostatecznej listy rekomendacji. Ostateczna lista rekomendacji jest tworzona w oparciu o następujące kryteria.
Sortowanie kandydatów przy użyciu ważonej wielkości mierzonej w dopasowanej godzinie wykonania zapytania i częstotliwości.
Każdy remis między kandydatami jest zerwany za pomocą częstotliwości zapytań i liczności.
Rysunek 4. Etap oceniania i sortowania w procesie rekomendacji pamięci podręcznej.
Was the topic helpful?
0/1000
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Cloud Pak for Data relationship map
Use this interactive map to learn about the relationships between your tasks, the tools you need, the services that provide the tools, and where you use the tools.
Select any task, tool, service, or workspace
You'll learn what you need, how to get it, and where to use it.
Tasks you'll do
Some tasks have a choice of tools and services.
Tools you'll use
Some tools perform the same tasks but have different features and levels of automation.
Create a notebook in which you run Python, R, or Scala code to prepare, visualize, and analyze data, or build a model.
Automatically analyze your tabular data and generate candidate model pipelines customized for your predictive modeling problem.
Create a visual flow that uses modeling algorithms to prepare data and build and train a model, using a guided approach to machine learning that doesn’t require coding.
Create and manage scenarios to find the best solution to your optimization problem by comparing different combinations of your model, data, and solutions.
Create a flow of ordered operations to cleanse and shape data. Visualize data to identify problems and discover insights.
Automate the model lifecycle, including preparing data, training models, and creating deployments.
Work with R notebooks and scripts in an integrated development environment.
Create a federated learning experiment to train a common model on a set of remote data sources. Share training results without sharing data.
Deploy and run your data science and AI solutions in a test or production environment.
Find and share your data and other assets.
Import asset metadata from a connection into a project or a catalog.
Enrich imported asset metadata with business context, data profiling, and quality assessment.
Measure and monitor the quality of your data.
Create and run masking flows to prepare copies of data assets that are masked by advanced data protection rules.
Create your business vocabulary to enrich assets and rules to protect data.
Track data movement and usage for transparency and determining data accuracy.
Track AI models from request to production.
Create a flow with a set of connectors and stages to transform and integrate data. Provide enriched and tailored information for your enterprise.
Create a virtual table to segment or combine data from one or more tables.
Measure outcomes from your AI models and help ensure the fairness, explainability, and compliance of all your models.
Replicate data to target systems with low latency, transactional integrity and optimized data capture.
Consolidate data from the disparate sources that fuel your business and establish a single, trusted, 360-degree view of your customers.
Services you can use
Services add features and tools to the platform.
Develop powerful AI solutions with an integrated collaborative studio and industry-standard APIs and SDKs. Formerly known as Watson Studio.
Quickly build, run and manage generative AI and machine learning applications with built-in performance and scalability. Formerly known as Watson Machine Learning.
Discover, profile, catalog, and share trusted data in your organization.
Create ETL and data pipeline services for real-time, micro-batch, and batch data orchestration.
View, access, manipulate, and analyze your data without moving it.
Monitor your AI models for bias, fairness, and trust with added transparency on how your AI models make decisions.
Provide efficient change data capture and near real-time data delivery with transactional integrity.
Improve trust in AI pipelines by identifying duplicate records and providing reliable data about your customers, suppliers, or partners.
Increase data pipeline transparency so you can determine data accuracy throughout your models and systems.
Where you'll work
Collaborative workspaces contain tools for specific tasks.
Where you work with data.
> Projects > View all projects
Where you find and share assets.
> Catalogs > View all catalogs
Where you deploy and run assets that are ready for testing or production.
> Deployments
Where you manage governance artifacts.
> Governance > Categories
Where you virtualize data.
> Data > Data virtualization
Where you consolidate data into a 360 degree view.

 W wyniku tej oceny mechanizm rekomendacji generuje wynik zgodności dla każdego kandydata pamięci podręcznej. Ocena każdego kandydata opiera się na następujących kryteriach.
W wyniku tej oceny mechanizm rekomendacji generuje wynik zgodności dla każdego kandydata pamięci podręcznej. Ocena każdego kandydata opiera się na następujących kryteriach.