Using an input set of queries, Data Virtualization recommends a ranked list of data
caches that can improve the performance of the input queries and potentially help future query
workloads.
The input queries are queries that were run anywhere in the previous 1 day up to the previous 15
days, and must have an execution time of at least one minute. The recommendations are considered
valid for 1 day after which they can change as the query workload changes.
The cache recommendation engine uses two models to generate recommendations.
The rule-based model uses sophisticated heuristics to determine which cache candidates help the
input query workload.
The machine learning based model uses a pre-trained machine learning model that detects
underlying query patterns and predicts caches that help a potential future query workload.
Both models produce a ranked list of cache candidates that are consolidated by the engine to
generate a final set of recommendations. You can choose to enable or disable machine learning based
cache recommendations. By default, machine learning based cache recommendations are
enabled.
In addition to cache creation recommendations, the engine also recommends cache
disable and delete recommendations based on past usage and other metrics. These recommendations
appear in the Active and Inactive caches tab for
existing caches.
Machine learning based cache recommendations consider underlying query patterns and predict
caches that are valid for 1 day.
Data Virtualization uses a pre-trained model that was trained on
an industry standard data
set.
You can choose to enable or disable
machine learning based cache recommendations.
The recommendation engine consolidates and ranks the final set of recommendations from both
models. The Manager can then add data caches from these
recommendations.
Data Virtualization provides an engine to generate a ranked list of recommendations. Ranking of
cache creation recommendations is determined by the execution time of queries, the frequency of
those queries in the input workload, and the weight of the two models. The engine is fully aware and
does not recommend the creation of caches that exist. Additionally, the engine does not recommend
the creation of duplicated caches.
The process of generating cache recommendations consists of five stages, as depicted in the
following image:
Figure 1. Cache recommendation process overview
Collect
The cache recommendation engine collects information such as query text, execution time,
cardinality, timestamp, and frequency for the provided time period.
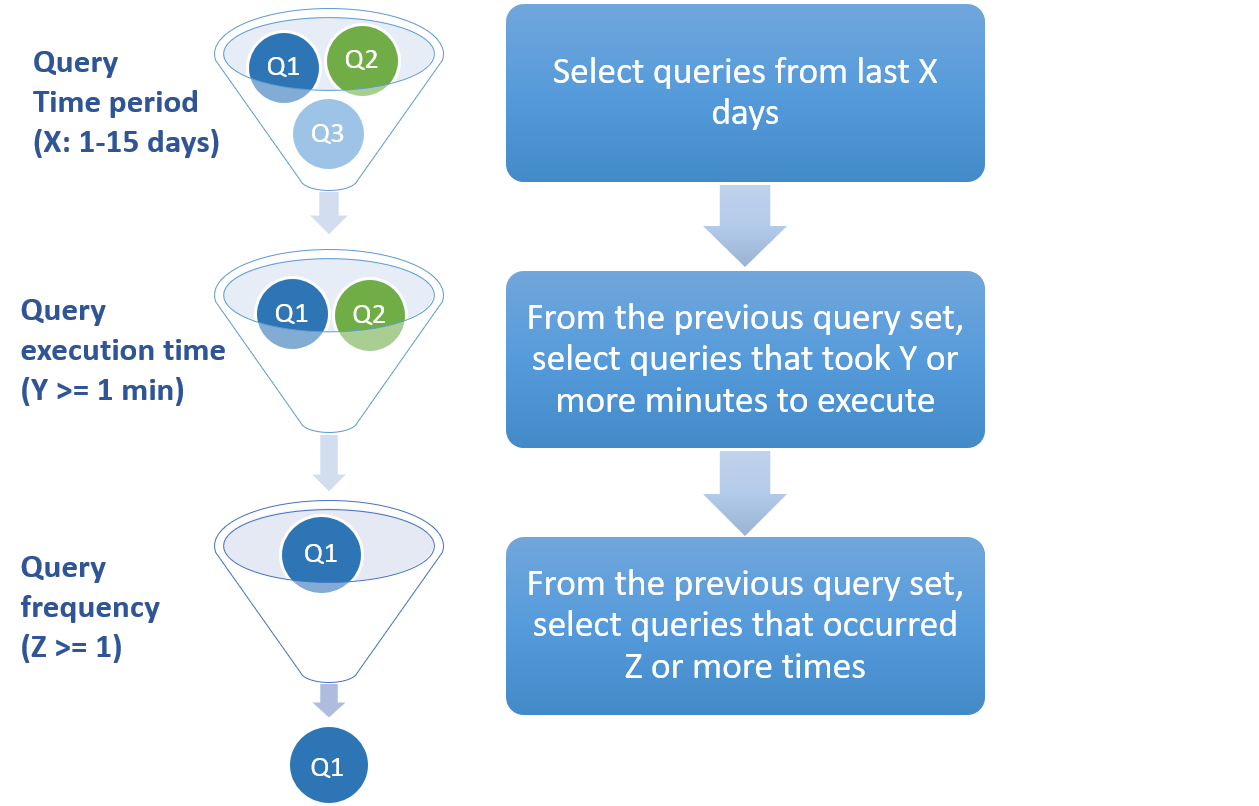
The following image shows how
queries from historical workload are filtered to arrive to the final input set of queries for the
recommendation engine:Figure 2. Collection stage in the cache recommendation
process.
Cache configuration settings are defined by the Data VirtualizationManager, see Configure cache recommendations for details.
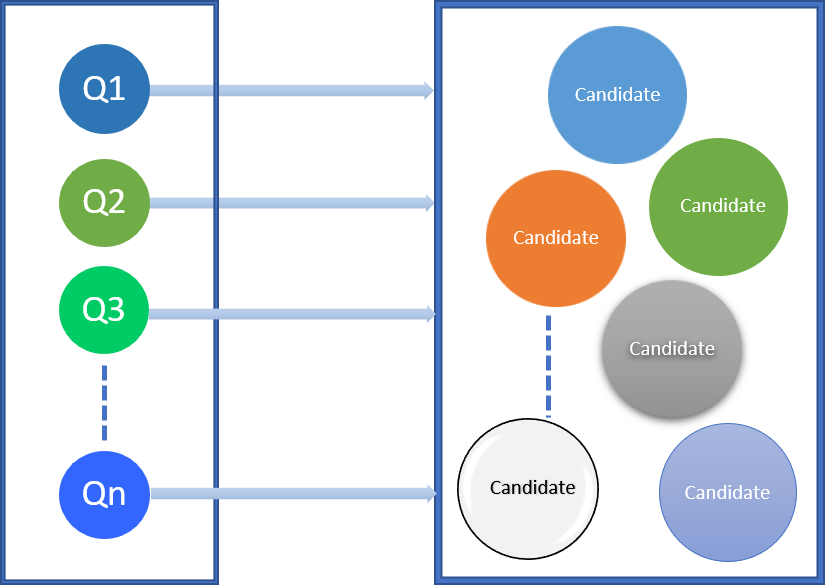
Extract
The recommendation engine generates potential cache candidates for the input query
workload.
Translate
The recommendation engine converts and consolidates the candidates to ensure
that they are syntactically and semantically correct, unique, and pass all Db2® restrictions.
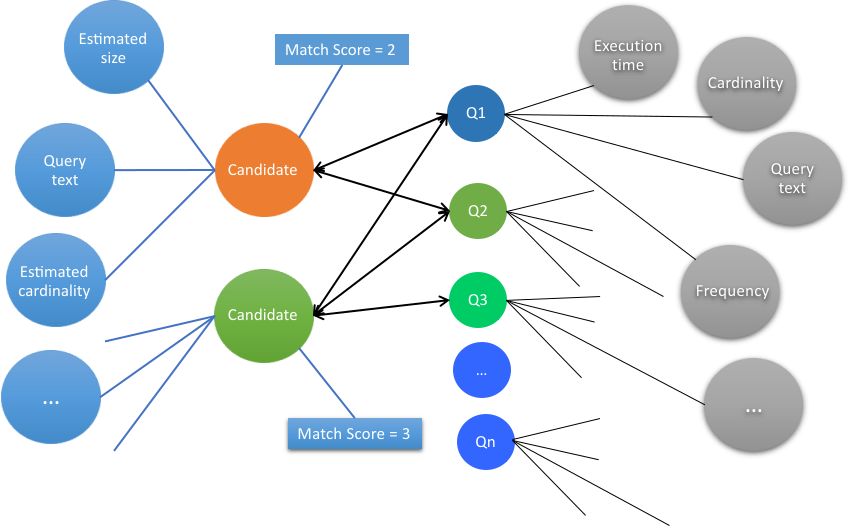
Evaluate
The engine evaluates the converted definitions by matching each cache candidate against the
input query workload. Also, for scoring the machine learning model, a high-dimensional feature
vector is created for each candidate.Figure 3. Evaluation stage in the cache
recommendation process.
As a result of this evaluation, the recommendation engine generates a match
score for each cache candidate. The evaluation of each candidate is based on the following criteria.
Matchability Number of queries that match the cache candidate.
Diversity Different queries that match the cache candidate.
Cardinality Size of result set that the cache candidate fetched.
Performance Execution time of queries that the cache candidate
matched.
Rank and sort
The recommendation engine ranks and sorts the cache candidates to generate a final list of
recommendations. The final list of recommendations is created based on the following criteria.
Sort candidates by using a weighted metric of matched query execution time and frequency.
Any tie between candidates is broken by using query frequency and cardinality.
Figure 4. Ranking and sorting stage in the cache recommendation
process.
About cookies on this siteOur websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising.For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.

 As a result of this evaluation, the recommendation engine generates a match score for each cache candidate. The evaluation of each candidate is based on the following criteria.
As a result of this evaluation, the recommendation engine generates a match score for each cache candidate. The evaluation of each candidate is based on the following criteria.