Retourner à la version anglaise de la documentationRecommandations relatives au cache dans le cadre de la Data Virtualization
Dernière mise à jour : 26 nov. 2024
Recommandations relatives au cache dans le cadre de la Data Virtualization
À partir d'un ensemble de requêtes, Data Virtualization recommande une liste classée de caches de données susceptibles d'améliorer les performances des requêtes d'entrée et d'aider les charges de travail futures.
Les requêtes d'entrée sont des requêtes qui ont été exécutées n'importe où au cours de la dernière journée au cours des 15 derniers jours, et doivent avoir une durée d'exécution d'au moins une minute. Les recommandations sont considérées comme valides pendant 1 jour après lequel elles peuvent être modifiées à mesure que la charge de travail de la requête change.
Le moteur de recommandation de cache utilise deux modèles pour générer des recommandations.
Le modèle basé sur des règles utilise une heuristique sophistiquée pour déterminer quels candidats de cache aident la charge de travail de la requête d'entrée.
Le modèle basé sur l'apprentissage automatique utilise un modèle d'apprentissage automatique pré-entraîné qui détecte les modèles de requête sous-jacents et prédit les caches qui aident une future charge de travail potentielle de requête.
Les deux modèles produisent une liste classée de candidats de cache qui sont consolidés par le moteur pour générer un ensemble final de recommandations. Vous pouvez choisir d'activer ou de désactiver les recommandations de cache basées sur l'apprentissage automatique. Par défaut, les recommandations de cache basées sur l'apprentissage automatique sont activées.
Outre les recommandations de création de cache, le moteur recommande également la désactivation et la suppression de caches sur la base de l'utilisation passée et d'autres métriques. Ces recommandations apparaissent dans l'onglet des caches Actif et Inactif pour les caches existantes.
Les recommandations de caches basées sur l'apprentissage automatique prennent en compte les modèles de requêtes sous-jacents et prédisent des caches qui sont valables pendant un jour.
La Data Virtualization utilise un modèle pré-entraîné sur un ensemble de données standard de l'industrie.
Vous pouvez choisir d'activer ou de désactiver les recommandations de cache basées sur l'apprentissage automatique.
Le moteur de recommandation consolide et classe l'ensemble final de recommandations des deux modèles. Le gestionnaire peut ensuite ajouter des caches de données à partir de ces recommandations.
La Data Virtualization fournit un moteur permettant de générer une liste de recommandations classées. Le classement des recommandations de création de cache est déterminé par le temps d'exécution des requêtes, la fréquence de ces requêtes dans la charge de travail d'entrée et le poids des deux modèles. Le moteur est pleinement conscient et ne recommande pas la création de caches qui existent. En outre, le moteur ne recommande pas la création de caches dupliqués.
Le processus de génération des recommandations liées aux caches se compose de cinq étapes, comme illustré dans le graphique suivant :
Figure 1 : Présentation du processus de recommandations relatives aux caches
Collecter
Le moteur de recommandation de cache collecte des informations telles que le texte de requête, le temps d'exécution, la cardinalité, l'horodatage et la fréquence pour la période fournie.
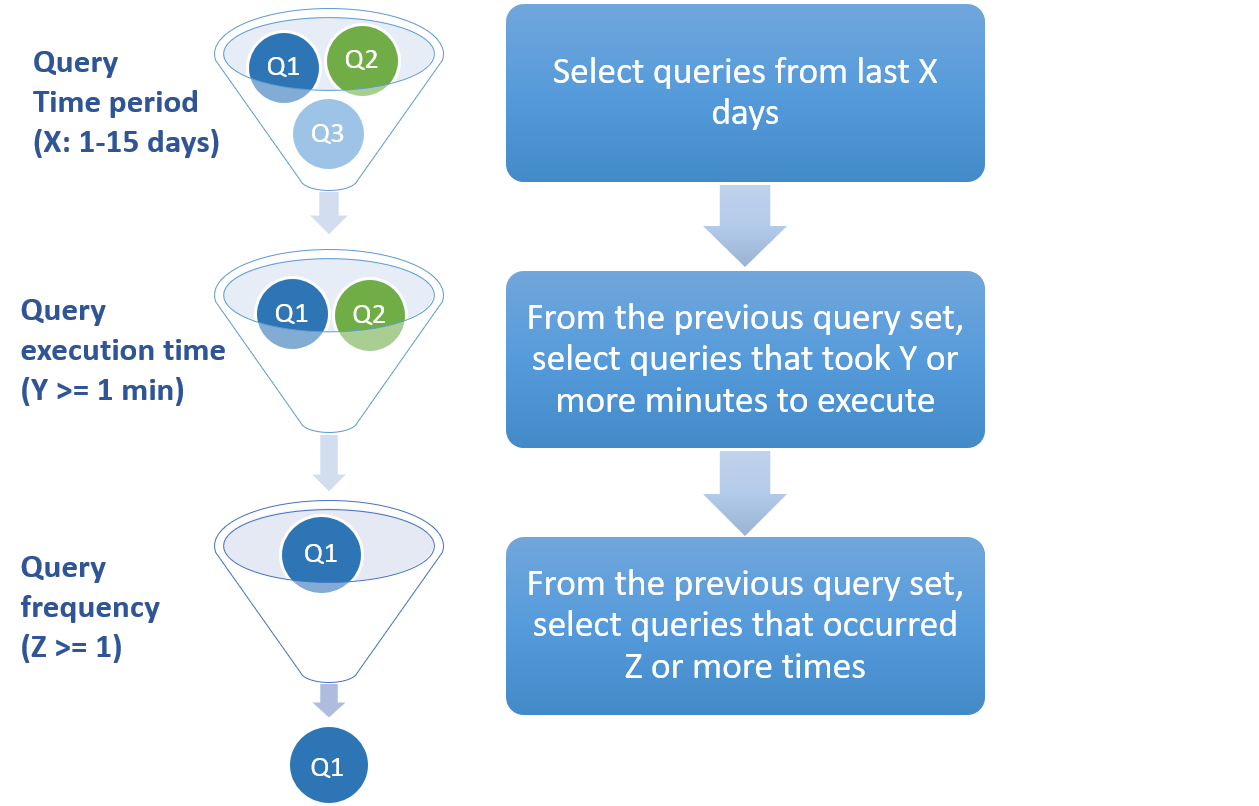
L'image suivante montre comment les requêtes provenant de la charge de travail historique sont filtrées pour arriver à l'ensemble d'entrées final des requêtes pour le moteur de recommandations :Figure 2. Étape de collecte dans le processus de recommandation du cache.
Les paramètres de configuration du cache sont définis par le gestionnaire deData Virtualization, voir Configurer les recommandations du cache pour plus de détails.
Extract
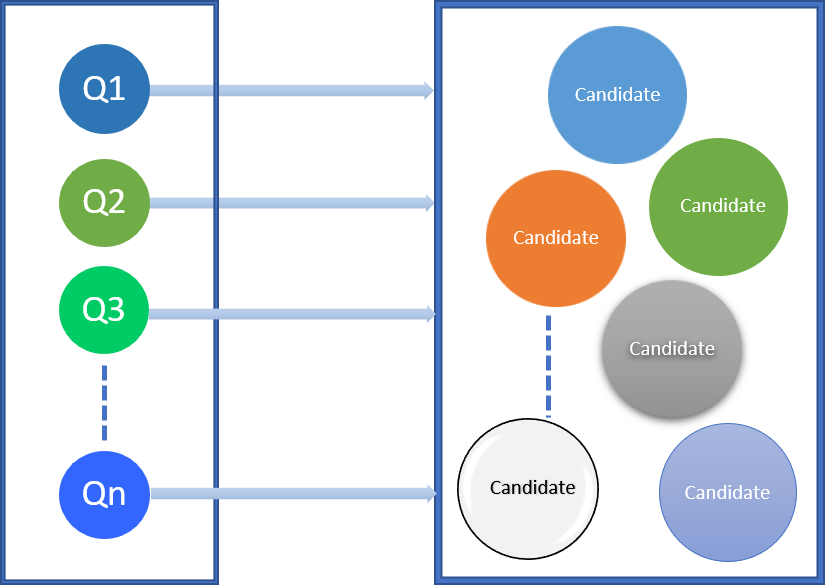
Le moteur de recommandation génère des candidats de cache potentiels pour la charge de travail de requête d'entrée.
Traduire
Le moteur de recommandation convertit et consolide les candidats pour s'assurer qu'ils sont syntaxiquement et sémantiquement corrects, uniques et qu'ils respectent toutes les restrictions Db2® .
Évaluer
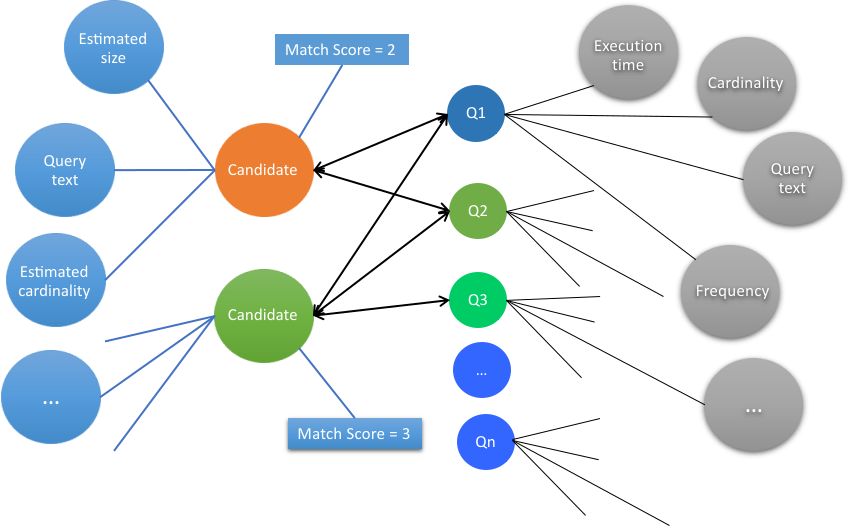
Le moteur évalue les définitions converties en comparant chaque candidat de cache à la charge de travail de requête d'entrée. De plus, pour marquer le modèle d'apprentissage automatique, un vecteur de fonction haute dimension est créé pour chaque candidat.Figure 3 Étape d'évaluation dans le processus de recommandation du cache.
A la suite de cette évaluation, le moteur de recommandations génère un score de correspondance pour chaque candidat de cache. L'évaluation de chaque candidat est fondée sur les critères suivants.
Correspondance Nombre de requêtes correspondant au candidat en cache.
Diversité Requêtes différentes correspondant au candidat en cache.
Cardinalité Taille du jeu de résultats que le candidat de cache a extrait.
Performances Temps d'exécution des requêtes correspondant au candidat de la mémoire cache.
Rang et tri
Le moteur de recommandations classe et trie les candidats de cache pour générer une liste finale de recommandations. La liste finale des recommandations est établie en fonction des critères suivants.
Tri des candidats à l'aide d'une mesure pondérée du temps et de la fréquence d'exécution des requêtes correspondantes.
Tout lien entre les candidats est rompu à l'aide de la fréquence et de la cardinalité des requêtes.
Figure 4 Classement et tri de l'étape dans le processus de recommandation du cache.
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Cloud Pak for Data relationship map
Use this interactive map to learn about the relationships between your tasks, the tools you need, the services that provide the tools, and where you use the tools.
Select any task, tool, service, or workspace
You'll learn what you need, how to get it, and where to use it.
Tasks you'll do
Some tasks have a choice of tools and services.
Tools you'll use
Some tools perform the same tasks but have different features and levels of automation.
Create a notebook in which you run Python, R, or Scala code to prepare, visualize, and analyze data, or build a model.
Automatically analyze your tabular data and generate candidate model pipelines customized for your predictive modeling problem.
Create a visual flow that uses modeling algorithms to prepare data and build and train a model, using a guided approach to machine learning that doesn’t require coding.
Create and manage scenarios to find the best solution to your optimization problem by comparing different combinations of your model, data, and solutions.
Create a flow of ordered operations to cleanse and shape data. Visualize data to identify problems and discover insights.
Automate the model lifecycle, including preparing data, training models, and creating deployments.
Work with R notebooks and scripts in an integrated development environment.
Create a federated learning experiment to train a common model on a set of remote data sources. Share training results without sharing data.
Deploy and run your data science and AI solutions in a test or production environment.
Find and share your data and other assets.
Import asset metadata from a connection into a project or a catalog.
Enrich imported asset metadata with business context, data profiling, and quality assessment.
Measure and monitor the quality of your data.
Create and run masking flows to prepare copies of data assets that are masked by advanced data protection rules.
Create your business vocabulary to enrich assets and rules to protect data.
Track data movement and usage for transparency and determining data accuracy.
Track AI models from request to production.
Create a flow with a set of connectors and stages to transform and integrate data. Provide enriched and tailored information for your enterprise.
Create a virtual table to segment or combine data from one or more tables.
Measure outcomes from your AI models and help ensure the fairness, explainability, and compliance of all your models.
Replicate data to target systems with low latency, transactional integrity and optimized data capture.
Consolidate data from the disparate sources that fuel your business and establish a single, trusted, 360-degree view of your customers.
Services you can use
Services add features and tools to the platform.
Develop powerful AI solutions with an integrated collaborative studio and industry-standard APIs and SDKs. Formerly known as Watson Studio.
Quickly build, run and manage generative AI and machine learning applications with built-in performance and scalability. Formerly known as Watson Machine Learning.
Discover, profile, catalog, and share trusted data in your organization.
Create ETL and data pipeline services for real-time, micro-batch, and batch data orchestration.
View, access, manipulate, and analyze your data without moving it.
Monitor your AI models for bias, fairness, and trust with added transparency on how your AI models make decisions.
Provide efficient change data capture and near real-time data delivery with transactional integrity.
Improve trust in AI pipelines by identifying duplicate records and providing reliable data about your customers, suppliers, or partners.
Increase data pipeline transparency so you can determine data accuracy throughout your models and systems.
Where you'll work
Collaborative workspaces contain tools for specific tasks.
Where you work with data.
> Projects > View all projects
Where you find and share assets.
> Catalogs > View all catalogs
Where you deploy and run assets that are ready for testing or production.
> Deployments
Where you manage governance artifacts.
> Governance > Categories
Where you virtualize data.
> Data > Data virtualization
Where you consolidate data into a 360 degree view.

 A la suite de cette évaluation, le moteur de recommandations génère un score de correspondance pour chaque candidat de cache. L'évaluation de chaque candidat est fondée sur les critères suivants.
A la suite de cette évaluation, le moteur de recommandations génère un score de correspondance pour chaque candidat de cache. L'évaluation de chaque candidat est fondée sur les critères suivants.