Recomendaciones sobre la caché en la Data Virtualization
Última actualización: 17 mar 2025
Recomendaciones sobre la caché en la Data Virtualization
Utilizando un conjunto de consultas de entrada, Data Virtualization recomienda una lista clasificada de cachés de datos que pueden mejorar el rendimiento de las consultas de entrada y ayudar potencialmente a futuras cargas de trabajo de consulta.
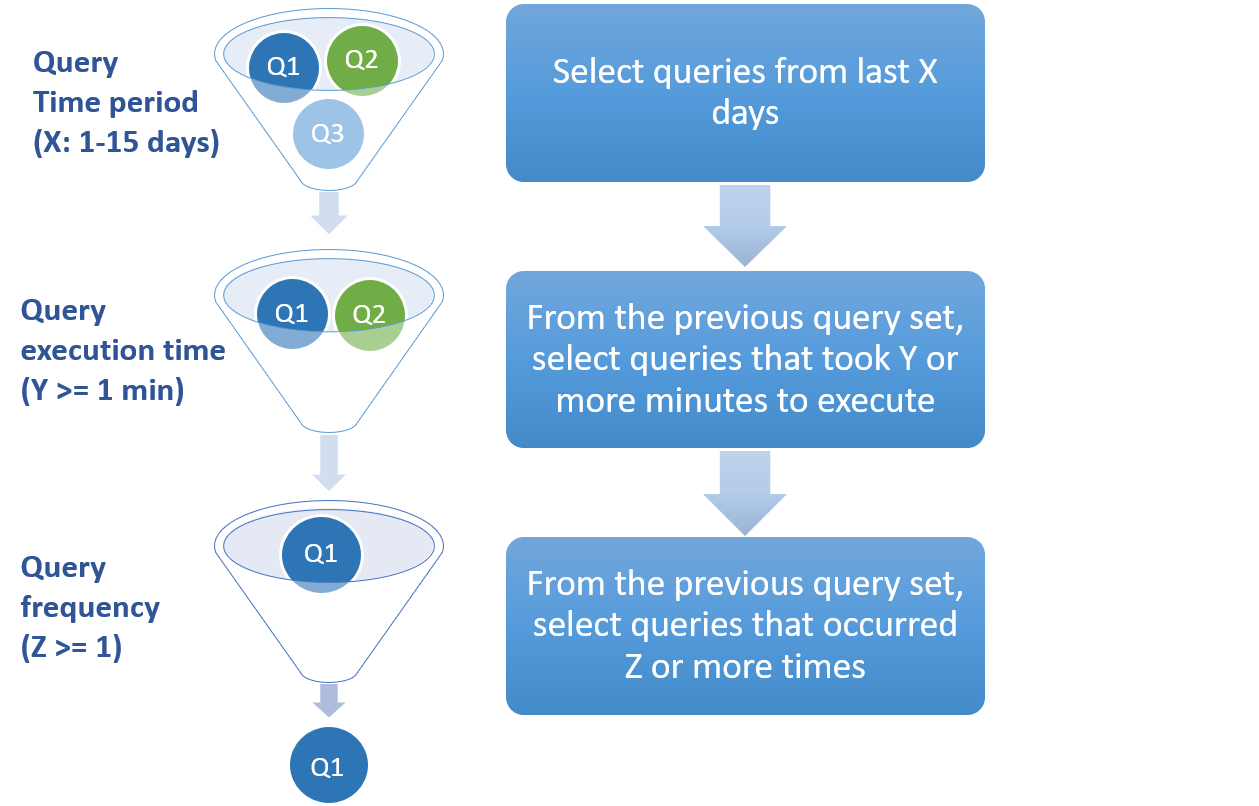
Las consultas de entrada son consultas que se han ejecutado en cualquier lugar, desde el día 1 anterior hasta los 15 días anteriores, y deben tener un tiempo de ejecución de al menos un minuto. Las recomendaciones se consideran válidas durante 1 día después del cual pueden cambiar a medida que cambia la carga de trabajo de la consulta.
El motor de recomendaciones de memoria caché utiliza dos modelos para generar recomendaciones.
El modelo basado en reglas utiliza sofisticados heurismos para determinar qué candidatos de memoria caché ayudan con la carga de trabajo de consultas de entrada.
El modelo basado en aprendizaje automático utiliza un modelo de aprendizaje automático entrenado previamente que detecta patrones de consulta subyacentes y prevé las memorias caché que ayudarían con una potencial carga de trabajo de consultas futura.
Ambos modelos generan una lista clasificada de candidatos de memoria caché que el motor consolida para generar un conjunto final de recomendaciones. Puede elegir habilitar o inhabilitar las recomendaciones de memoria caché basadas en aprendizaje automático. De forma predeterminada, las recomendaciones de memoria caché basadas en aprendizaje automático están habilitadas.
Además de las recomendaciones de creación de memoria caché, el motor también recomienda recomendaciones de inhabilitación y supresión de memoria caché según el uso en el pasado y otras métricas. Estas recomendaciones aparecen en la pestaña de memorias caché Activas e Inactivas para las memorias caché existentes.
Las recomendaciones de memoria caché basadas en aprendizaje automático consideran los patrones de consulta subyacentes y prevén memorias caché que son válidas durante 1 día.
Data Virtualization utiliza un modelo previamente entrenado con un conjunto de datos estándar del sector.
Puede elegir habilitar o inhabilitar las recomendaciones de memoria caché basadas en aprendizaje automático.
El motor de recomendaciones consolida y clasifica el conjunto final de recomendaciones de ambos modelos. A continuación, el Gestor puede añadir memorias caché de datos de estas recomendaciones.
Data Virtualization proporciona un motor para generar una lista clasificada de recomendaciones. La clasificación de las recomendaciones de creación de caché viene determinada por el tiempo de ejecución de las consultas, la frecuencia de dichas consultas en la carga de trabajo de entrada y el peso de los dos modelos. El motor tiene total constancia de ello y no recomienda la creación de memorias caché que ya existen. Además, el motorno recomienda la creación de memorias caché duplicadas.
El proceso de generar recomendaciones de memoria caché consiste en cuatro etapas, como se muestra en lasiguiente imagen:
Figura 1. Visión general del proceso de recomendaciones de memoria caché
Recolectar
El motor de recomendaciones selecciona un conjunto de consultas de clientes cuyo rendimiento debe mejorarse y para los que podrían recomendarse cachés. El motor de recomendaciones de memoria caché recopila información como, por ejemplo, el texto de la consulta, el tiempo de ejecución, la cardinalidad, la indicación de fecha y hora y la frecuencia correspondientes al periodo de tiempo proporcionado.
En la imagen siguiente se muestra cómo las consultas de la carga de trabajo históricase filtran para llegar al conjunto de consultas de entrada final para el motor de recomendación:Figura 2. Etapa de recopilación en el proceso de recomendaciones de memoria caché.
Los ajustes de configuración de la caché se definen mediante ' Data Virtualization ' Director, ver ' Configurar las recomendaciones de caché para más detalles.
Extraer
El motor de recomendaciones genera candidatos de memoria caché potenciales para la carga de trabajo de consultas de entrada.
Traducir
El motor de recomendaciones convierte y consolida los candidatos para asegurarse de que son sintáctica y semánticamente correctos, exclusivos y pasan todas las restricciones de Db2 .
Evaluar
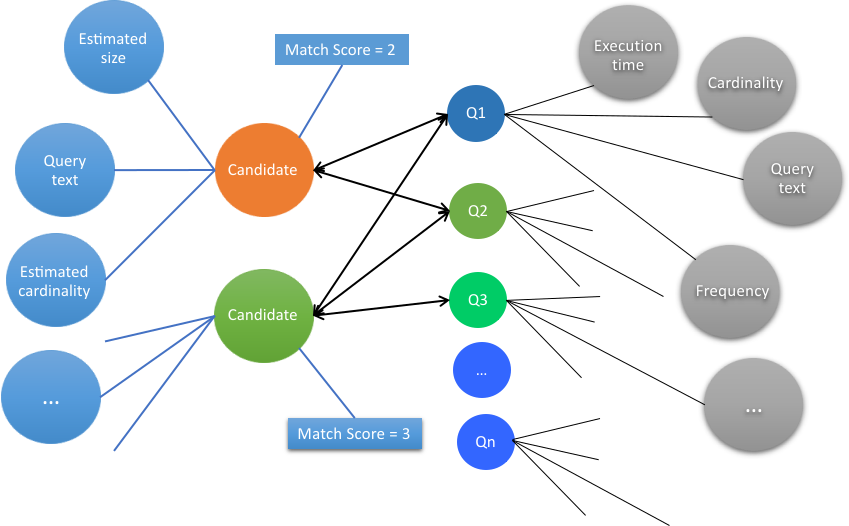
El motor evalúa las definiciones convertidas comparando cada candidato de caché con la carga de trabajo de la consulta de entrada para determinar su eficacia, rango y clasificación. Además, para puntuar el modelo de aprendizaje automático, se crea un vector de característica de alta dimensión para cada candidato.Figura 3. Etapa de evaluación en el proceso de recomendaciones de memoria caché.
Como resultado de esta evaluación, el motor de recomendaciones genera una puntuaciónde coincidencia para cada candidato a memoria caché. La evaluación de cada candidato se basa en los siguientes criterios.
Coincidencia : Número de consultas que coinciden con el candidato de la caché.
Diversidad : Diferentes consultas que coinciden con el candidato de caché.
Cardinalidad : tamaño del conjunto de resultados que el candidato de caché recuperó.
Rendimiento : Tiempo de ejecución de las consultas que el candidato de caché coincidió.
Clasificar y ordenar
El motor de recomendaciones clasifica y ordena los candidatos a memoria caché para generar una lista definitiva de recomendaciones. Se crea la lista final de recomendaciones basándose en los criterios siguientes.
Ordenar los candidatos utilizando una métrica ponderada de tiempo de ejecución y frecuencia de las consultas coincidentes.
Cualquier empate entre candidatos se desempata utilizando la frecuencia y la cardinalidad de las consultas.
Figura 4. Etapa de clasificación y ordenación en el proceso de recomendaciones de memoria caché
¿Fue útil el tema?
0/1000
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Cloud Pak for Data relationship map
Use this interactive map to learn about the relationships between your tasks, the tools you need, the services that provide the tools, and where you use the tools.
Select any task, tool, service, or workspace
You'll learn what you need, how to get it, and where to use it.
Tasks you'll do
Some tasks have a choice of tools and services.
Tools you'll use
Some tools perform the same tasks but have different features and levels of automation.
Create a notebook in which you run Python, R, or Scala code to prepare, visualize, and analyze data, or build a model.
Automatically analyze your tabular data and generate candidate model pipelines customized for your predictive modeling problem.
Create a visual flow that uses modeling algorithms to prepare data and build and train a model, using a guided approach to machine learning that doesn’t require coding.
Create and manage scenarios to find the best solution to your optimization problem by comparing different combinations of your model, data, and solutions.
Create a flow of ordered operations to cleanse and shape data. Visualize data to identify problems and discover insights.
Automate the model lifecycle, including preparing data, training models, and creating deployments.
Work with R notebooks and scripts in an integrated development environment.
Create a federated learning experiment to train a common model on a set of remote data sources. Share training results without sharing data.
Deploy and run your data science and AI solutions in a test or production environment.
Find and share your data and other assets.
Import asset metadata from a connection into a project or a catalog.
Enrich imported asset metadata with business context, data profiling, and quality assessment.
Measure and monitor the quality of your data.
Create and run masking flows to prepare copies of data assets that are masked by advanced data protection rules.
Create your business vocabulary to enrich assets and rules to protect data.
Track data movement and usage for transparency and determining data accuracy.
Track AI models from request to production.
Create a flow with a set of connectors and stages to transform and integrate data. Provide enriched and tailored information for your enterprise.
Create a virtual table to segment or combine data from one or more tables.
Measure outcomes from your AI models and help ensure the fairness, explainability, and compliance of all your models.
Replicate data to target systems with low latency, transactional integrity and optimized data capture.
Consolidate data from the disparate sources that fuel your business and establish a single, trusted, 360-degree view of your customers.
Services you can use
Services add features and tools to the platform.
Develop powerful AI solutions with an integrated collaborative studio and industry-standard APIs and SDKs. Formerly known as Watson Studio.
Quickly build, run and manage generative AI and machine learning applications with built-in performance and scalability. Formerly known as Watson Machine Learning.
Discover, profile, catalog, and share trusted data in your organization.
Create ETL and data pipeline services for real-time, micro-batch, and batch data orchestration.
View, access, manipulate, and analyze your data without moving it.
Monitor your AI models for bias, fairness, and trust with added transparency on how your AI models make decisions.
Provide efficient change data capture and near real-time data delivery with transactional integrity.
Improve trust in AI pipelines by identifying duplicate records and providing reliable data about your customers, suppliers, or partners.
Increase data pipeline transparency so you can determine data accuracy throughout your models and systems.
Where you'll work
Collaborative workspaces contain tools for specific tasks.
Where you work with data.
> Projects > View all projects
Where you find and share assets.
> Catalogs > View all catalogs
Where you deploy and run assets that are ready for testing or production.
> Deployments
Where you manage governance artifacts.
> Governance > Categories
Where you virtualize data.
> Data > Data virtualization
Where you consolidate data into a 360 degree view.

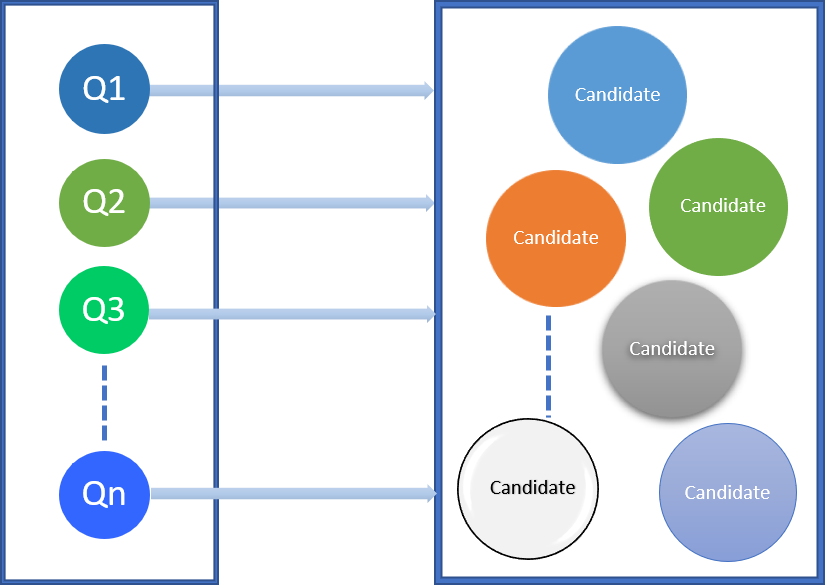 Como resultado de esta evaluación, el motor de recomendaciones genera una puntuaciónde coincidencia para cada candidato a memoria caché. La evaluación de cada candidato se basa en los siguientes criterios.
Como resultado de esta evaluación, el motor de recomendaciones genera una puntuaciónde coincidencia para cada candidato a memoria caché. La evaluación de cada candidato se basa en los siguientes criterios.